
AlmaLinux 10 総合ガイド
第8章: ログ管理とトラブルシューティング
サーバー運用において、問題は必ず発生します。サービスが起動しない、ネットワークに繋がらない、ディスクが満杯になる。これらの問題に直面したとき、あなたはどこから調査を始めますか?
答えは明確です。まずログを見る。これがインフラエンジニアの基本中の基本です。
ログには「いつ」「何が」「どうなったか」が記録されています。エラーメッセージを読めば、多くの場合、問題の原因と解決策のヒントが得られます。逆に言えば、ログを見ずに原因を推測して対処しようとすると、無駄な時間を浪費することになります。
この章では、ログファイルの構成と読み方、journalctlの実践的な使い方、そして3つのケーススタディを通じてトラブルシューティングの思考プロセスを身につけます。
8.1 ログファイルの基礎
まず、Linuxシステムでログがどのように管理されているかを理解しましょう。
8.1.1 なぜログが重要なのか
ログが重要な理由は主に3つあります。
1. 問題の原因特定
サービスが動かないとき、ログには具体的なエラーメッセージが記録されています。「設定ファイルの42行目に構文エラーがあります」といった情報があれば、すぐに対処できます。
2. セキュリティ監視
不正アクセスの試みや、異常な動作はログに記録されます。「192.168.1.100から100回のSSHログイン失敗」という記録があれば、攻撃を受けていることがわかります。
3. 監査証跡
「いつ、誰が、何をしたか」を後から確認できます。トラブル発生時の原因究明や、コンプライアンス対応に不可欠です。
💡 実務のヒント: 「問題が起きたら、まずログを見る」を習慣にしてください。この習慣があるかないかで、トラブルシューティングの効率は10倍変わります。
8.1.2 /var/logディレクトリの構成
Linuxのログファイルは、/var/log/ディレクトリに集約されています。どのようなファイルがあるか確認してみましょう。
[実行ユーザー: 一般ユーザー]
$ ls -la /var/log/
total 2048
drwxr-xr-x. 10 root root 4096 Jan 15 10:00 .
drwxr-xr-x. 22 root root 4096 Jan 10 12:00 ..
drwxr-x---. 2 root root 4096 Jan 15 00:00 audit
-rw-------. 1 root root 12345 Jan 15 14:30 boot.log
-rw-------. 1 root root 8765 Jan 15 10:00 cron
drwxr-xr-x. 2 root root 4096 Jan 15 00:00 httpd
drwx------. 2 root root 4096 Jan 10 12:00 journal
-rw-r--r--. 1 root root 123456 Jan 15 14:30 messages
drwxr-xr-x. 2 root root 4096 Jan 10 12:00 nginx
-rw-------. 1 root root 56789 Jan 15 14:30 secure
-rw-------. 1 root root 12345 Jan 15 14:30 dnf.log
/var/log/には、システム全体のログとアプリケーション固有のログが混在しています。ディレクトリ構造を理解しておくと、必要なログをすぐに見つけられます。
8.1.3 主要なログファイル
AlmaLinux 10で重要なログファイルを紹介します。
| ファイル | 内容 | 用途 |
|---|---|---|
| /var/log/messages | システム全般のログ | 一般的なトラブルシューティング |
| /var/log/secure | 認証関連のログ | ログイン試行、sudo実行の確認 |
| /var/log/audit/audit.log | SELinux監査ログ | SELinux拒否の原因特定 |
| /var/log/cron | cronの実行ログ | 定期実行ジョブの確認 |
| /var/log/dnf.log | パッケージ管理のログ | インストール・更新履歴 |
| /var/log/boot.log | 起動時のログ | 起動時の問題調査 |
/var/log/messages – システム全般のログ
最も汎用的なログファイルです。カーネルメッセージ、サービスの状態変化、ハードウェアの検出など、さまざまな情報が記録されます。
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo tail -20 /var/log/messages
Jan 15 14:25:00 server1 systemd[1]: Starting httpd.service - The Apache HTTP Server...
Jan 15 14:25:01 server1 httpd[12345]: AH00558: httpd: Could not reliably determine the server's fully qualified domain name
Jan 15 14:25:01 server1 systemd[1]: Started httpd.service - The Apache HTTP Server.
Jan 15 14:30:00 server1 NetworkManager[789]: <info> [1705296600] device (enp0s3): state change: activated -> unavailable
Jan 15 14:30:05 server1 kernel: enp0s3: link down
/var/log/secure – 認証関連のログ
SSHログイン、sudo実行、ユーザー切り替えなど、認証に関するイベントが記録されます。セキュリティ監視の要となるログです。
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo tail -10 /var/log/secure
Jan 15 14:20:00 server1 sshd[5678]: Accepted publickey for developer from 192.168.1.50 port 52345 ssh2
Jan 15 14:20:00 server1 sshd[5678]: pam_unix(sshd:session): session opened for user developer
Jan 15 14:25:30 server1 sudo[6789]: developer : TTY=pts/0 ; PWD=/home/developer ; USER=root ; COMMAND=/bin/systemctl restart httpd
Jan 15 14:28:00 server1 sshd[9999]: Failed password for invalid user admin from 203.0.113.50 port 54321 ssh2
Jan 15 14:28:05 server1 sshd[9999]: Failed password for invalid user admin from 203.0.113.50 port 54321 ssh2
上記の例では、正常なログインと、不正なログイン試行(存在しないユーザー「admin」へのパスワード攻撃)の両方が記録されています。
/var/log/audit/audit.log – SELinux監査ログ
SELinuxがアクセスを拒否した記録が残ります。第7章で学んだSELinux問題の調査に使用します。
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo tail -5 /var/log/audit/audit.log
type=AVC msg=audit(1705296600.123:456): avc: denied { read } for pid=12345 comm="httpd" name="custom.conf" dev="sda1" ino=67890 scontext=system_u:system_r:httpd_t:s0 tcontext=unconfined_u:object_r:user_home_t:s0 tclass=file permissive=0
このログは「httpdがcustom.confを読もうとしたが、SELinuxに拒否された」ことを示しています。
8.1.4 ログの世代管理(logrotate)
ログファイルは放置すると際限なく大きくなり、ディスク容量を圧迫します。logrotateは、ログファイルを定期的にローテーション(世代管理)するツールです。
[実行ユーザー: 一般ユーザー]
$ ls -la /var/log/messages*
-rw-r--r--. 1 root root 123456 Jan 15 14:30 /var/log/messages
-rw-r--r--. 1 root root 234567 Jan 14 23:59 /var/log/messages-20260114
-rw-r--r--. 1 root root 345678 Jan 13 23:59 /var/log/messages-20260113
logrotateの動作により、古いログは日付付きのファイル名で保存され、一定期間後に削除されます。設定は/etc/logrotate.confと/etc/logrotate.d/で管理されています。
[実行ユーザー: 一般ユーザー]
# メイン設定ファイルの確認
$ cat /etc/logrotate.conf
# rotate log files weekly
weekly
# keep 4 weeks worth of backlogs
rotate 4
# create new (empty) log files after rotating old ones
create
# use date as a suffix of the rotated file
dateext
# uncomment this if you want your log files compressed
compress
# packages drop log rotation information into this directory
include /etc/logrotate.d
主な設定項目は以下の通りです。
- weekly: 毎週ローテーション
- rotate 4: 4世代保持(それより古いものは削除)
- compress: 古いログをgzip圧縮
- dateext: ローテーション時に日付をファイル名に付加
8.1.5 ログのタイムスタンプの読み方
ログのタイムスタンプを正確に読むことは、問題発生時刻の特定に不可欠です。
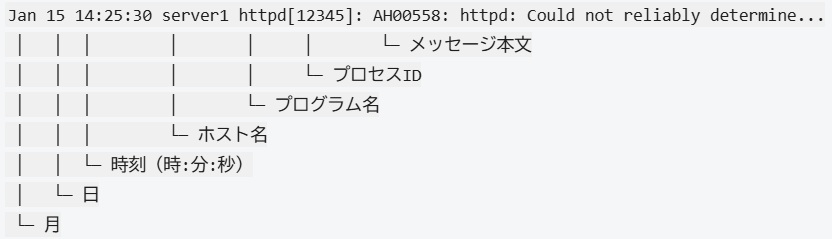
年が記録されていないことに注意してください。年をまたぐ問題の調査では、ファイルの更新日時も確認する必要があります。
💡 実務のヒント: journalctlを使えば年も含めたタイムスタンプで確認できます。複雑な調査ではjournalctlを優先的に使いましょう。
8.2 journalctlによる詳細なログ確認
第5章でjournalctlの基本を学びました。この節では、より実践的なオプションと組み合わせテクニックを習得します。
8.2.1 journaldとrsyslogの関係
AlmaLinux 10では、2つのログシステムが併存しています。
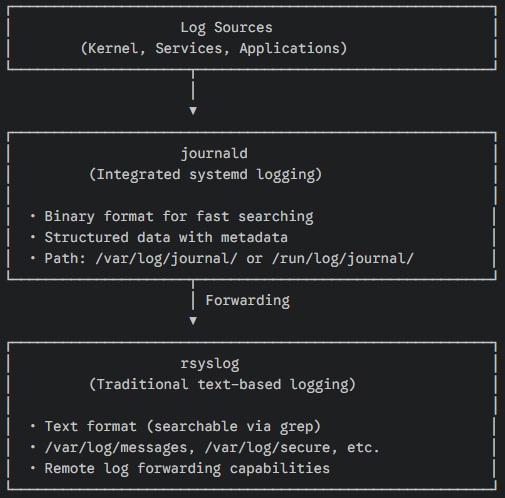
journaldが中心となりログを収集し、rsyslogに転送することで従来のテキストログも生成されます。
| 項目 | journalctl | 従来のログファイル |
|---|---|---|
| 検索 | 高速(インデックス付き) | grep依存(大きいと遅い) |
| フィルタ | 多彩(時間、優先度、サービス等) | grepで工夫が必要 |
| 可読性 | コマンドが必要 | 直接読める |
| 転送 | 設定が複雑 | rsyslogで容易 |
| スクリプト連携 | JSON出力で可能 | テキスト処理が容易 |
実務では状況に応じて使い分けますが、トラブルシューティングではjournalctlを優先的に使うことを推奨します。
8.2.2 journalctlの基本オプション(復習)
第5章で学んだ基本オプションを簡単に復習します。
[実行ユーザー: 一般ユーザー]
# 特定サービスのログ
$ journalctl -u httpd
# リアルタイム監視
$ journalctl -f
# 最新のn行を表示
$ journalctl -n 50
# 末尾から表示(ページャーで最後に移動)
$ journalctl -e
8.2.3 時間範囲でのフィルタリング
トラブルシューティングでは、問題発生時刻の前後に絞ってログを確認することが重要です。
–since オプション(開始時刻)
[実行ユーザー: 一般ユーザー]
# 特定の日時以降
$ journalctl --since "2026-01-15 14:00:00"
# 相対指定(1時間前から)
$ journalctl --since "1 hour ago"
# 相対指定(30分前から)
$ journalctl --since "30 minutes ago"
# 昨日から
$ journalctl --since yesterday
# 今日の0時から
$ journalctl --since today
–until オプション(終了時刻)
[実行ユーザー: 一般ユーザー]
# 特定の日時まで
$ journalctl --until "2026-01-15 15:00:00"
# 相対指定(10分前まで)
$ journalctl --until "10 minutes ago"
範囲指定の組み合わせ
[実行ユーザー: 一般ユーザー]
# 14:00から15:00までの1時間
$ journalctl --since "2026-01-15 14:00:00" --until "2026-01-15 15:00:00"
# 1時間前から30分前までの30分間
$ journalctl --since "1 hour ago" --until "30 minutes ago"
# 特定サービスの直近1時間
$ journalctl -u httpd --since "1 hour ago"
8.2.4 優先度でのフィルタリング
-pオプションで、ログの重要度(優先度)をフィルタリングできます。
| 優先度 | 数値 | 意味 | 対処 |
|---|---|---|---|
| emerg | 0 | システム使用不能 | 即座に対処 |
| alert | 1 | 即座にアクション必要 | 即座に対処 |
| crit | 2 | 危機的な状態 | 早急に対処 |
| err | 3 | エラー状態 | 対処が必要 |
| warning | 4 | 警告状態 | 注意が必要 |
| notice | 5 | 正常だが重要な状態 | 参考情報 |
| info | 6 | 情報メッセージ | 参考情報 |
| debug | 7 | デバッグメッセージ | 開発時のみ |
[実行ユーザー: 一般ユーザー]
# エラー以上(emerg, alert, crit, err)を表示
$ journalctl -p err
# 警告以上を表示
$ journalctl -p warning
# 特定サービスのエラーのみ
$ journalctl -u httpd -p err
# 直近1時間のエラー
$ journalctl -p err --since "1 hour ago"
トラブルシューティングでは、まず-p errでエラーを確認し、必要に応じて-p warningに範囲を広げるのが効率的です。
8.2.5 ユニット単位でのフィルタリング(-u)
特定のサービス(ユニット)のログだけを表示します。複数のサービスを同時に指定することもできます。
[実行ユーザー: 一般ユーザー]
# 単一サービス
$ journalctl -u httpd
# 複数サービス
$ journalctl -u httpd -u mariadb
# サービスの直近のエラー
$ journalctl -u sshd -p err --since "1 hour ago"
8.2.6 カーネルメッセージ(-k)
カーネルが出力するメッセージのみを表示します。ハードウェアの問題やドライバの問題を調査するときに使います。
[実行ユーザー: 一般ユーザー]
$ journalctl -k
-- Logs begin at Wed 2026-01-01 00:00:00 JST, end at Wed 2026-01-15 14:30:00 JST. --
Jan 15 10:00:00 server1 kernel: Linux version 6.12.0-1.el10.x86_64 ...
Jan 15 10:00:01 server1 kernel: Command line: BOOT_IMAGE=(hd0,gpt2)/vmlinuz-6.12.0-1.el10.x86_64 ...
Jan 15 10:00:02 server1 kernel: Memory: 3936MB available
Jan 15 14:25:00 server1 kernel: enp0s3: link down
Jan 15 14:25:05 server1 kernel: enp0s3: link up, 1000Mbps full-duplex
ネットワークインターフェースの状態変化(link down/up)もカーネルメッセージとして記録されます。
8.2.7 ブート単位でのログ表示(-b)
システムの起動(ブート)単位でログを絞り込めます。「再起動してから問題が発生した」という状況で有用です。
[実行ユーザー: 一般ユーザー]
# 現在のブートのログ
$ journalctl -b
# 前回のブートのログ
$ journalctl -b -1
# 2回前のブートのログ
$ journalctl -b -2
# 利用可能なブート一覧
$ journalctl --list-boots
-2 abc123def456 Wed 2026-01-13 10:00:00 JST—Wed 2026-01-13 23:59:59 JST
-1 789xyz012345 Thu 2026-01-14 10:00:00 JST—Thu 2026-01-14 23:59:59 JST
0 456abc789def Fri 2026-01-15 10:00:00 JST—Fri 2026-01-15 14:30:00 JST
⚠️ 注意: 過去のブートログを確認するには、ログの永続化設定が必要です(第5章参照)。永続化されていない場合、現在のブートのログしか表示できません。
8.2.8 ログのエクスポート(-o)
ログを様々な形式で出力できます。スクリプトでの処理や、他の人との共有に便利です。
[実行ユーザー: 一般ユーザー]
# JSON形式(スクリプト処理向け)
$ journalctl -u httpd -o json-pretty --since "1 hour ago"
{
"__CURSOR" : "s=abc123...",
"PRIORITY" : "6",
"_HOSTNAME" : "server1",
"MESSAGE" : "AH00558: httpd: Could not reliably determine...",
"_SYSTEMD_UNIT" : "httpd.service",
...
}
# 短縮形式(1行1メッセージ)
$ journalctl -u httpd -o short
# 詳細形式(全フィールド表示)
$ journalctl -u httpd -o verbose
# cat形式(メッセージのみ)
$ journalctl -u httpd -o cat
主な出力フォーマットは以下の通りです。
| フォーマット | 説明 | 用途 |
|---|---|---|
| short | デフォルト(syslog風) | 通常の確認 |
| short-precise | マイクロ秒単位の時刻 | 精密な時刻確認 |
| json | JSON形式(1行1オブジェクト) | スクリプト処理 |
| json-pretty | JSON形式(整形済み) | 人間が読む場合 |
| verbose | 全メタデータ表示 | 詳細調査 |
| cat | メッセージ本文のみ | テキスト処理 |
8.2.9 リアルタイム監視(-f)とgrepの組み合わせ
実務では、journalctlとgrepを組み合わせて使うことが多くあります。
[実行ユーザー: 一般ユーザー]
# 特定キーワードを含むログをリアルタイム監視
$ journalctl -f | grep -i error
# 特定サービスのエラーをリアルタイム監視
$ journalctl -u httpd -f | grep -i "failed\|error"
# IPアドレスを含むログを抽出
$ journalctl -u sshd --since "1 hour ago" | grep "192.168.1"
# 特定のエラーコードを検索
$ journalctl -u httpd --since today | grep "AH00"
複数条件の組み合わせ例
[実行ユーザー: 一般ユーザー]
# 直近1時間のhttpdのエラーで、"permission"を含むもの
$ journalctl -u httpd -p err --since "1 hour ago" | grep -i permission
# 今日のSSHログイン失敗
$ journalctl -u sshd --since today | grep -i "failed\|invalid"
# カーネルのネットワーク関連メッセージ
$ journalctl -k --since "30 minutes ago" | grep -i "link\|network\|eth\|enp"
💡 実務のヒント: journalctlで大まかに絞り込み、grepで細かく検索するのが効率的です。journalctlのフィルタだけで十分な場合も多いですが、複雑な検索にはgrepを組み合わせましょう。
8.3 トラブルシューティングの基本手順
ツールの使い方を学んだところで、トラブルシューティングの「考え方」を身につけましょう。
8.3.1 問題の切り分けプロセス
トラブルシューティングは、以下の流れで進めます。
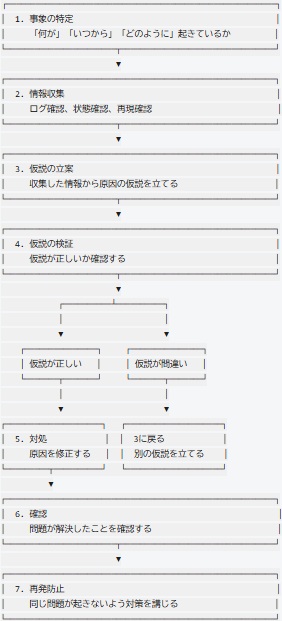
この流れを意識することで、闇雲に対処して時間を浪費することを防げます。
8.3.2 「5W1H」でログを読む
ログを読むときは、以下の観点で情報を整理します。
- When(いつ): 問題が発生した時刻
- Where(どこで): どのサーバー、どのサービス
- Who(誰が): どのユーザー、どのプロセス
- What(何が): 何が起きたか(エラーの内容)
- Why(なぜ): なぜ起きたか(原因)
- How(どのように): どのように対処すべきか
例: ログメッセージの分析
Jan 15 14:25:30 server1 httpd[12345]: AH00526: Syntax error on line 42 of /etc/httpd/conf/httpd.conf:
- When: 1月15日 14:25:30
- Where: server1のhttpdサービス
- Who: プロセスID 12345
- What: 構文エラー(Syntax error)
- Why: /etc/httpd/conf/httpd.confの42行目に問題がある
- How: 設定ファイルの42行目を確認・修正する
このように整理すると、次に何をすべきかが明確になります。
8.3.3 エラーメッセージのGoogle検索テクニック
エラーメッセージをそのままGoogle検索するのは有効なテクニックです。ただし、いくつかのコツがあります。
効果的な検索方法
- エラーコードを含める: 「AH00526」「error code 1」など
- ホスト名やパスを除外: 固有の情報は検索ノイズになる
- 引用符で囲む: 完全一致で検索できる
- OS名を追加: 「AlmaLinux」「RHEL」を追加すると精度が上がる
検索例
元のエラーメッセージ:
AH00526: Syntax error on line 42 of /etc/httpd/conf/httpd.conf: Invalid command 'ServerNam'
検索クエリ:
"AH00526" "Invalid command" httpd AlmaLinux
検索結果から、同じ問題に遭遇した人の解決策を見つけられることが多いです。Stack Overflow、Red Hat Knowledge Base、各種技術ブログなどが参考になります。
⚠️ 注意: 検索で見つけた解決策をそのまま適用するのは危険です。自分の環境に適しているか、副作用はないかを確認してから実行しましょう。特にchmod 777やsetenforce 0などの「とりあえず動く」解決策は、セキュリティリスクを伴います。
8.4 ケーススタディ1: サービスが起動しない
ここからは、実際のトラブル事例を通じてトラブルシューティングの流れを体験します。
8.4.1 症状の確認
状況: httpdサービスを起動しようとしたが、失敗する。
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo systemctl start httpd
Job for httpd.service failed because the control process exited with error code.
See "systemctl status httpd.service" and "journalctl -xeu httpd.service" for details.
エラーメッセージが親切にも「systemctl status」と「journalctl -xe」を見るよう指示してくれています。この指示に従いましょう。
8.4.2 systemctl statusでステータス確認
[実行ユーザー: 一般ユーザー]
$ systemctl status httpd
× httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; preset: disabled)
Active: failed (Result: exit-code) since Wed 2026-01-15 14:30:00 JST; 1min ago
Docs: man:httpd.service(8)
Process: 12345 ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND (code=exited, status=1/FAILURE)
Main PID: 12345 (code=exited, status=1/FAILURE)
CPU: 15ms
Jan 15 14:30:00 server1 systemd[1]: Starting httpd.service - The Apache HTTP Server...
Jan 15 14:30:00 server1 httpd[12345]: AH00526: Syntax error on line 42 of /etc/httpd/conf/httpd.conf:
Jan 15 14:30:00 server1 httpd[12345]: Invalid command 'ServerNam', perhaps misspelled or defined by a module not included in the server configuration
Jan 15 14:30:00 server1 systemd[1]: httpd.service: Main process exited, code=exited, status=1/FAILURE
Jan 15 14:30:00 server1 systemd[1]: httpd.service: Failed with result 'exit-code'.
Jan 15 14:30:00 server1 systemd[1]: Failed to start httpd.service - The Apache HTTP Server.
ログから以下のことがわかります。
- サービスは「failed」状態
- 原因は「Syntax error on line 42」(構文エラー)
- 具体的には「Invalid command ‘ServerNam’」(無効なコマンド)
「ServerNam」は「ServerName」のタイプミス(typo)だと推測できます。
8.4.3 journalctl -xeでログ確認
より詳しい情報を得るため、journalctlも確認します。
[実行ユーザー: 一般ユーザー]
$ journalctl -xeu httpd
Jan 15 14:30:00 server1 systemd[1]: Starting httpd.service - The Apache HTTP Server...
░░ Subject: A start job for unit httpd.service has begun execution
░░ Defined-By: systemd
░░ Support: https://wiki.almalinux.org
░░
░░ A start job for unit httpd.service has begun execution.
░░
░░ The job identifier is 1234.
Jan 15 14:30:00 server1 httpd[12345]: AH00526: Syntax error on line 42 of /etc/httpd/conf/httpd.conf:
Jan 15 14:30:00 server1 httpd[12345]: Invalid command 'ServerNam', perhaps misspelled or defined by a module not included in the server configuration
Jan 15 14:30:00 server1 systemd[1]: httpd.service: Main process exited, code=exited, status=1/FAILURE
░░ Subject: Unit process exited
...-xオプションにより、追加の説明(░░で始まる行)が表示されています。
8.4.4 設定ファイルの構文チェック
問題箇所がわかったので、設定ファイルを確認します。
[実行ユーザー: 一般ユーザー(sudo使用)]
# 42行目付近を確認
$ sudo sed -n '40,45p' /etc/httpd/conf/httpd.conf
# ServerName gives the name and port that the server uses to identify itself.
#
ServerNam www.example.com:80
#
# Deny access to the entirety of your server's filesystem.
42行目に「ServerNam」と書かれています。「e」が抜けています。
Apacheには構文チェックコマンドがあるので、それも使ってみましょう。
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo apachectl configtest
AH00526: Syntax error on line 42 of /etc/httpd/conf/httpd.conf:
Invalid command 'ServerNam', perhaps misspelled or defined by a module not included in the server configuration
構文チェックでも同じエラーが報告されます。
8.4.5 パーミッション問題の確認
構文エラーが原因でしたが、パーミッション問題の可能性も確認しておきましょう。パーミッション問題の場合は、以下のようなエラーになります。
# パーミッション問題の例
$ journalctl -u httpd -p err
Jan 15 14:35:00 server1 httpd[12346]: (13)Permission denied: AH00091: httpd: could not open error log file /var/log/httpd/error_log
このような場合は、ファイルやディレクトリの権限を確認します。
[実行ユーザー: 一般ユーザー]
$ ls -la /var/log/httpd/
total 8
drwx------. 2 root root 4096 Jan 15 10:00 .
drwxr-xr-x. 10 root root 4096 Jan 15 10:00 ..
-rw-r--r--. 1 root root 0 Jan 15 10:00 access_log
-rw-r--r--. 1 root root 0 Jan 15 10:00 error_log
8.4.6 SELinuxの確認
第7章で学んだSELinuxが原因の場合もあります。SELinux拒否のログを確認します。
[実行ユーザー: 一般ユーザー(sudo使用)]
# 直近のSELinux拒否を確認
$ sudo ausearch -m AVC -ts recent
<no matches>
# または audit.log を直接確認
$ sudo grep "denied" /var/log/audit/audit.log | tail -5
今回はSELinuxの拒否はありませんでした。SELinuxが原因の場合は、以下のようなログが記録されます。
# SELinux拒否の例
type=AVC msg=audit(1705296600.123:456): avc: denied { read } for pid=12345 comm="httpd" name="custom.conf" ...
8.4.7 ポート競合の確認
別のプロセスが同じポートを使っている場合も起動に失敗します。
[実行ユーザー: 一般ユーザー(sudo使用)]
# ポート80を使用しているプロセスを確認
$ sudo ss -tlnp | grep :80
LISTEN 0 128 *:80 *:* users:(("nginx",pid=9876,fd=6))
もしnginxなど別のWebサーバーがポート80を使っている場合、httpdは起動できません。
ポート競合時のエラーは以下のようになります。
# ポート競合の例
Jan 15 14:40:00 server1 httpd[12347]: (98)Address already in use: AH00072: make_sock: could not bind to address [::]:80
8.4.8 段階的な問題解決
今回のケースでは、原因は設定ファイルのタイプミスでした。修正しましょう。
[実行ユーザー: 一般ユーザー(sudo使用)]
# 設定ファイルを修正
$ sudo vi /etc/httpd/conf/httpd.conf
# 42行目の "ServerNam" を "ServerName" に修正
# 構文チェック
$ sudo apachectl configtest
Syntax OK
# サービス起動
$ sudo systemctl start httpd
# 状態確認
$ systemctl status httpd
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; preset: disabled)
Active: active (running) since Wed 2026-01-15 14:45:00 JST; 5s ago
...
問題が解決しました。
💡 学んだこと:
- エラーメッセージを読めば、多くの場合原因がわかる
systemctl statusとjournalctl -xeはセットで使う- 設定変更後は必ず構文チェックを行う
- 問題の切り分けは段階的に行う(構文→パーミッション→SELinux→ポート競合)
8.5 ケーススタディ2: ネットワークに繋がらない
次は、ネットワーク接続の問題を解決します。
8.5.1 症状の確認(どこまで通るか)
状況: サーバーからインターネットに接続できない。
まず、「どこまで通信できているか」を確認することが重要です。
[実行ユーザー: 一般ユーザー]
$ ping 8.8.8.8
ping: connect: Network is unreachable
「Network is unreachable」は、ネットワーク自体に到達できない状態です。レイヤーの低いところから順に確認していきます。
8.5.2 インターフェース状態確認(ip link)
まず、ネットワークインターフェースが有効になっているか確認します。
[実行ユーザー: 一般ユーザー]
$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000
link/ether 08:00:27:xx:xx:xx brd ff:ff:ff:ff:ff:ff
enp0s3のstateが「DOWN」になっています。これが原因です。
- UP: インターフェースが有効
- DOWN: インターフェースが無効
8.5.3 IPアドレス確認(ip addr)
IPアドレスが割り当てられているかも確認します。
[実行ユーザー: 一般ユーザー]
$ ip addr show enp0s3
2: enp0s3: <BROADCAST,MULTICAST> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
link/ether 08:00:27:xx:xx:xx brd ff:ff:ff:ff:ff:ff
「inet」の行がありません。IPアドレスが設定されていません。
正常な場合は以下のように表示されます。
$ ip addr show enp0s3
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:xx:xx:xx brd ff:ff:ff:ff:ff:ff
inet 192.168.1.100/24 brd 192.168.1.255 scope global dynamic noprefixroute enp0s3
valid_lft 86400sec preferred_lft 86400sec
8.5.4 ゲートウェイへのping
インターフェースが有効でIPアドレスが設定されている場合は、ゲートウェイへの到達性を確認します。
[実行ユーザー: 一般ユーザー]
# ルーティングテーブルでゲートウェイを確認
$ ip route
default via 192.168.1.1 dev enp0s3 proto dhcp metric 100
192.168.1.0/24 dev enp0s3 proto kernel scope link src 192.168.1.100 metric 100
# ゲートウェイにping
$ ping -c 3 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=0.5 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=64 time=0.4 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=64 time=0.4 ms
ゲートウェイに到達できれば、ローカルネットワークは正常です。
8.5.5 DNS解決確認(dig, nslookup)
ゲートウェイまで到達でき、外部へのpingも通る場合は、DNS解決を確認します。
[実行ユーザー: 一般ユーザー]
# digコマンドでDNS解決を確認
$ dig google.com +short
142.250.196.110
# nslookupでも確認可能
$ nslookup google.com
Server: 192.168.1.1
Address: 192.168.1.1#53
Non-authoritative answer:
Name: google.com
Address: 142.250.196.110
DNS解決ができない場合は、/etc/resolv.confを確認します。
[実行ユーザー: 一般ユーザー]
$ cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 192.168.1.1
8.5.6 ファイアウォール確認
内部からの通信がブロックされていないか確認します。
[実行ユーザー: 一般ユーザー(sudo使用)]
# 現在のファイアウォール設定
$ sudo firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: enp0s3
sources:
services: cockpit dhcpv6-client ssh
ports:
protocols:
forward: yes
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
outgoing(外向き)の通信は通常ブロックされませんが、incoming(内向き)の通信で問題が発生することがあります。
8.5.7 ルーティング確認(ip route)
ルーティングテーブルに問題がないか確認します。
[実行ユーザー: 一般ユーザー]
$ ip route
default via 192.168.1.1 dev enp0s3 proto dhcp metric 100
192.168.1.0/24 dev enp0s3 proto kernel scope link src 192.168.1.100 metric 100
「default via」の行がなければ、デフォルトゲートウェイが設定されていません。
8.5.8 段階的な問題解決
今回のケースでは、インターフェースがDOWNになっていました。NetworkManagerで有効化します。
[実行ユーザー: 一般ユーザー(sudo使用)]
# 接続プロファイルを確認
$ nmcli connection show
NAME UUID TYPE DEVICE
enp0s3 12345678-1234-1234-1234-123456789012 ethernet --
# 接続を有効化
$ sudo nmcli connection up enp0s3
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/1)
# 状態を確認
$ ip addr show enp0s3
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:xx:xx:xx brd ff:ff:ff:ff:ff:ff
inet 192.168.1.100/24 brd 192.168.1.255 scope global dynamic noprefixroute enp0s3
valid_lft 86399sec preferred_lft 86399sec
# 疎通確認
$ ping -c 3 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=117 time=10.5 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=117 time=9.8 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=117 time=10.1 ms
問題が解決しました。
💡 ネットワーク問題の切り分け順序:
- 物理層: ケーブルは繋がっているか、インターフェースはUPか
- ネットワーク層: IPアドレスは設定されているか
- ルーティング: デフォルトゲートウェイは設定されているか、到達できるか
- 外部接続: 外部ホスト(8.8.8.8等)にpingが通るか
- DNS: 名前解決ができるか
- アプリケーション: 特定のポートがファイアウォールでブロックされていないか
8.6 ケーススタディ3: ディスク容量不足
最後に、ディスク容量不足の問題を解決します。
8.6.1 df -hで容量確認
状況: サービスが動作しなくなり、ログに「No space left on device」と記録されている。
[実行ユーザー: 一般ユーザー]
$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 783M 9.5M 773M 2% /run
/dev/sda3 50G 50G 0 100% /
/dev/sda2 960M 224M 736M 24% /boot
/dev/sda1 599M 7.0M 592M 2% /boot/efi
tmpfs 392M 0 392M 0% /run/user/1000
ルートパーティション(/)が100%使用になっています。これが問題です。
8.6.2 容量を消費している場所の特定
「何が」ディスクを消費しているかを特定します。
8.6.3 du -sh /*で大まかな把握
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo du -sh /* 2>/dev/null | sort -rh | head -10
35G /var
8.5G /usr
2.1G /home
1.2G /opt
512M /boot
128M /etc
64M /root
32M /tmp
...
/varが35GB消費しています。さらに掘り下げます。
8.6.4 du -ah /var | sort -rh | head -20で詳細特定
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo du -sh /var/* 2>/dev/null | sort -rh | head -10
32G /var/log
1.5G /var/cache
800M /var/lib
256M /var/tmp
...
$ sudo du -sh /var/log/* 2>/dev/null | sort -rh | head -10
30G /var/log/httpd
1.2G /var/log/messages
512M /var/log/secure
256M /var/log/audit
...
$ sudo ls -lh /var/log/httpd/
total 30G
-rw-r--r--. 1 root root 28G Jan 15 14:30 access_log
-rw-r--r--. 1 root root 2.0G Jan 15 14:30 error_log
Apache(httpd)のaccess_logが28GBになっています。これが原因です。
8.6.5 ログファイルの肥大化対応
巨大なログファイルを確認してから、対処を決めます。
[実行ユーザー: 一般ユーザー(sudo使用)]
# ログの末尾を確認(何が大量に記録されているか)
$ sudo tail -20 /var/log/httpd/access_log
192.168.1.50 - - [15/Jan/2026:14:30:00 +0900] "GET /health HTTP/1.1" 200 2
192.168.1.50 - - [15/Jan/2026:14:30:01 +0900] "GET /health HTTP/1.1" 200 2
192.168.1.50 - - [15/Jan/2026:14:30:02 +0900] "GET /health HTTP/1.1" 200 2
...
ヘルスチェックが1秒ごとに記録されており、これが大量のログの原因でした。
応急処置: ログファイルのトランケート(切り詰め)
[実行ユーザー: 一般ユーザー(sudo使用)]
# 削除ではなくトランケート(ファイルを空にする)
# 削除するとhttpdがログを書けなくなる可能性がある
$ sudo truncate -s 0 /var/log/httpd/access_log
# 容量を確認
$ df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 50G 22G 28G 44% /
🚨 注意: rmでログファイルを削除すると、サービスが開いているファイルハンドルが残り、ディスク容量が解放されないことがあります。truncateでファイルを空にするか、サービスを再起動してからファイルを削除してください。
8.6.6 tmpファイルの削除
一時ファイルが溜まっている場合もあります。
[実行ユーザー: 一般ユーザー(sudo使用)]
# tmpディレクトリの確認
$ sudo du -sh /tmp /var/tmp
256M /tmp
128M /var/tmp
# 古いtmpファイルの削除(7日以上前のファイル)
$ sudo find /tmp -type f -mtime +7 -delete
$ sudo find /var/tmp -type f -mtime +7 -delete
8.6.7 パッケージキャッシュのクリア
dnfのキャッシュも容量を消費します。
[実行ユーザー: 一般ユーザー(sudo使用)]
# キャッシュのサイズ確認
$ sudo du -sh /var/cache/dnf
1.5G /var/cache/dnf
# キャッシュのクリア
$ sudo dnf clean all
45 files removed
# 確認
$ sudo du -sh /var/cache/dnf
12K /var/cache/dnf
8.6.8 恒久対応(ログローテーション設定等)
応急処置だけでは、また同じ問題が発生します。恒久対策を講じましょう。
httpdのログローテーション設定
[実行ユーザー: 一般ユーザー(sudo使用)]
# 現在の設定を確認
$ cat /etc/logrotate.d/httpd
/var/log/httpd/*log {
missingok
notifempty
sharedscripts
delaycompress
postrotate
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
endscript
}
設定を改善します。
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo vi /etc/logrotate.d/httpd
/var/log/httpd/*log {
daily # 毎日ローテーション
rotate 7 # 7世代保持
compress # 古いログを圧縮
delaycompress # 1世代前から圧縮
missingok # ファイルがなくてもエラーにしない
notifempty # 空ファイルはローテーションしない
size 100M # 100MB超えたらローテーション
sharedscripts
postrotate
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
endscript
}
主な設定項目は以下の通りです。
- daily: 毎日ローテーション(weekly、monthlyも可)
- rotate 7: 7世代保持(それより古いものは削除)
- compress: gzipで圧縮
- size 100M: 100MBを超えたらローテーション(時間に関係なく)
ディスク容量監視の設定
第7章で学んだシェルスクリプトを使って、ディスク容量を監視するスクリプトを作成することも有効です。これについては第9章でも詳しく扱います。
💡 学んだこと:
df -hでディスク全体の使用状況を把握du -shで原因となるディレクトリを特定- ログファイルはrmではなくtruncateで空にする
- 恒久対策としてログローテーションを適切に設定
8.7 システムリソースの監視
トラブルシューティングでは、システムリソース(CPU、メモリ、ディスクI/O)の状態確認も重要です。
8.7.1 なぜ監視が必要か
システムリソースの監視は、以下の目的で行います。
- 問題の早期発見: 異常を検知して障害を未然に防ぐ
- 原因の特定: パフォーマンス低下の原因を把握する
- キャパシティプランニング: リソースの増強時期を判断する
- 異常検知: 通常とは異なる動作(攻撃など)を検知する
8.7.2 topコマンドでプロセス監視
topは、リアルタイムでシステムの状態を表示するコマンドです。
[実行ユーザー: 一般ユーザー]
$ top
top - 14:30:00 up 2 days, 3:45, 2 users, load average: 0.15, 0.10, 0.05
Tasks: 128 total, 1 running, 127 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.3 us, 1.0 sy, 0.0 ni, 96.5 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3936.0 total, 1234.5 free, 1456.7 used, 1244.8 buff/cache
MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 2156.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1234 root 20 0 456789 12345 6789 S 2.0 0.3 0:15.67 httpd
5678 mysql 20 0 987654 56789 12345 S 1.5 1.4 5:23.45 mysqld
9012 root 20 0 12345 3456 2345 R 0.5 0.1 0:00.12 top
1 root 20 0 171234 9876 6543 S 0.0 0.2 0:05.67 systemd
...
ヘッダー部分の読み方
top - 14:30:00 up 2 days, 3:45, 2 users, load average: 0.15, 0.10, 0.05
│ │ │ └─ ロードアベレージ(1分、5分、15分平均)
│ │ └─ ログインユーザー数
│ └─ システム稼働時間
└─ 現在時刻
%Cpu(s): 2.3 us, 1.0 sy, 0.0 ni, 96.5 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
│ │ │ │ │ │ │ └─ steal(仮想化オーバーヘッド)
│ │ │ │ │ │ └─ softirq(ソフト割込み)
│ │ │ │ │ └─ hardirq(ハード割込み)
│ │ │ │ └─ iowait(I/O待ち)
│ │ │ └─ idle(アイドル)
│ │ └─ nice(優先度変更プロセス)
│ └─ system(カーネル)
└─ user(ユーザープロセス)
topの操作方法
| キー | 動作 |
|---|---|
| q | 終了 |
| M | メモリ使用量でソート |
| P | CPU使用率でソート |
| k | プロセスをkill(PIDを入力) |
| 1 | CPU別の使用率表示 |
| h | ヘルプ表示 |
8.7.3 htopによる視覚的な監視(推奨)
htopは、topの機能強化版です。カラフルで見やすく、マウス操作にも対応しています。
インストール
[実行ユーザー: 一般ユーザー(sudo使用)]
# EPELリポジトリからインストール
$ sudo dnf install epel-release
$ sudo dnf install htop
実行
[実行ユーザー: 一般ユーザー]
$ htop
htopの特徴は以下の通りです。
- カラー表示: CPU、メモリがバーグラフで視覚的に表示される
- ツリー表示: プロセスの親子関係をツリー形式で表示(F5キー)
- スクロール: 矢印キーでプロセス一覧をスクロールできる
- 検索: F3キーでプロセス名を検索できる
- フィルタ: F4キーでフィルタリングできる
| 項目 | top | htop |
|---|---|---|
| 表示 | モノクロ | カラフル |
| 操作性 | キーボードのみ | マウス対応 |
| ツリー表示 | なし | あり |
| スクロール | 限定的 | 自由 |
| 標準搭載 | はい | いいえ(要インストール) |
8.7.4 freeでメモリ使用量確認
[実行ユーザー: 一般ユーザー]
$ free -h
total used free shared buff/cache available
Mem: 3.8Gi 1.4Gi 1.2Gi 9.0Mi 1.2Gi 2.1Gi
Swap: 2.0Gi 0B 2.0Gi
各項目の意味
- total: 物理メモリの総量
- used: 使用中のメモリ
- free: 完全に未使用のメモリ
- shared: 共有メモリ
- buff/cache: バッファ/キャッシュとして使用中
- available: 実際に利用可能なメモリ
💡 重要: Linuxはメモリを積極的にキャッシュとして使います。freeが小さくても、availableが十分にあれば問題ありません。availableを見ることが重要です。
8.7.5 dfでディスク使用量確認
第4章でも学んだdfコマンドの復習です。
[実行ユーザー: 一般ユーザー]
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 50G 22G 28G 44% /
/dev/sda2 960M 224M 736M 24% /boot
/dev/sda1 599M 7.0M 592M 2% /boot/efi
# ファイルシステムタイプも表示
$ df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda3 xfs 50G 22G 28G 44% /
/dev/sda2 xfs 960M 224M 736M 24% /boot
/dev/sda1 vfat 599M 7.0M 592M 2% /boot/efi
8.7.6 uptimeでシステム負荷確認
uptimeは、システムの稼働時間とロードアベレージを表示します。
[実行ユーザー: 一般ユーザー]
$ uptime
14:30:00 up 2 days, 3:45, 2 users, load average: 0.15, 0.10, 0.05
ロードアベレージの読み方
ロードアベレージは、実行待ちのプロセス数の平均値です。3つの数値は、1分間、5分間、15分間の平均を表します。
- ロードアベレージ < CPUコア数: 余裕がある
- ロードアベレージ = CPUコア数: ちょうど100%使用
- ロードアベレージ > CPUコア数: 過負荷(処理待ちが発生)
CPUコア数の確認方法は以下の通りです。
[実行ユーザー: 一般ユーザー]
$ nproc
2
# または
$ grep -c processor /proc/cpuinfo
2
2コアのサーバーでロードアベレージが2.0なら「ちょうど100%使用」、4.0なら「200%の過負荷」となります。
8.8 プロセス管理
問題のあるプロセスを特定し、必要に応じて終了させる方法を学びます。
8.8.1 プロセスとは
プロセスとは、実行中のプログラムのことです。各プロセスには一意のPID(Process ID)が割り当てられます。
- プログラムをメモリに読み込んで実行したものがプロセス
- 1つのプログラムから複数のプロセスが起動することもある
- プロセスには親子関係がある(親プロセスが子プロセスを生成)
8.8.2 psコマンドでプロセス一覧
psは、現在実行中のプロセスを表示するコマンドです。
ps aux(BSD形式)
[実行ユーザー: 一般ユーザー]
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 171234 9876 ? Ss Jan13 0:05 /usr/lib/systemd/systemd
root 2 0.0 0.0 0 0 ? S Jan13 0:00 [kthreadd]
...
root 1234 2.0 0.3 456789 12345 ? Ss 14:25 0:15 /usr/sbin/httpd -DFOREGROUND
apache 1235 0.5 0.2 458901 10234 ? S 14:25 0:03 /usr/sbin/httpd -DFOREGROUND
developer 5678 0.0 0.1 12345 3456 pts/0 R+ 14:30 0:00 ps aux
ps -ef(System V形式)
[実行ユーザー: 一般ユーザー]
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Jan13 ? 00:00:05 /usr/lib/systemd/systemd
root 2 0 0 Jan13 ? 00:00:00 [kthreadd]
...
root 1234 1 2 14:25 ? 00:00:15 /usr/sbin/httpd -DFOREGROUND
apache 1235 1234 0 14:25 ? 00:00:03 /usr/sbin/httpd -DFOREGROUND
各列の意味(ps aux)
| 列 | 意味 |
|---|---|
| USER | プロセスの所有者 |
| PID | プロセスID |
| %CPU | CPU使用率 |
| %MEM | メモリ使用率 |
| VSZ | 仮想メモリサイズ |
| RSS | 実際のメモリ使用量 |
| TTY | 端末(?はデーモン) |
| STAT | プロセスの状態 |
| START | 開始時刻 |
| TIME | CPU時間 |
| COMMAND | 実行コマンド |
よく使うパターン
[実行ユーザー: 一般ユーザー]
# 特定のプロセスを検索
$ ps aux | grep httpd
root 1234 2.0 0.3 456789 12345 ? Ss 14:25 0:15 /usr/sbin/httpd -DFOREGROUND
apache 1235 0.5 0.2 458901 10234 ? S 14:25 0:03 /usr/sbin/httpd -DFOREGROUND
developer 5679 0.0 0.0 12345 1234 pts/0 S+ 14:31 0:00 grep --color=auto httpd
# grepコマンド自身を除外
$ ps aux | grep [h]ttpd
root 1234 2.0 0.3 456789 12345 ? Ss 14:25 0:15 /usr/sbin/httpd -DFOREGROUND
apache 1235 0.5 0.2 458901 10234 ? S 14:25 0:03 /usr/sbin/httpd -DFOREGROUND
8.8.3 pgrepで名前からプロセス検索
pgrepは、プロセス名からPIDを検索するコマンドです。
[実行ユーザー: 一般ユーザー]
# プロセス名でPIDを検索
$ pgrep httpd
1234
1235
1236
1237
1238
# 詳細情報付きで表示
$ pgrep -a httpd
1234 /usr/sbin/httpd -DFOREGROUND
1235 /usr/sbin/httpd -DFOREGROUND
...
# ユーザー指定
$ pgrep -u apache httpd
1235
1236
1237
1238
8.8.4 killでプロセス終了
killは、プロセスにシグナルを送信するコマンドです。
主なシグナル
| シグナル | 番号 | 意味 | 用途 |
|---|---|---|---|
| SIGTERM | 15 | 終了要求 | 通常の終了(デフォルト) |
| SIGKILL | 9 | 強制終了 | 最終手段 |
| SIGHUP | 1 | ハングアップ | 設定再読み込み |
| SIGINT | 2 | 割込み | Ctrl+Cと同等 |
[実行ユーザー: 一般ユーザー(sudo使用)]
# 通常の終了(SIGTERM、デフォルト)
$ sudo kill 1234
# または明示的に
$ sudo kill -15 1234
$ sudo kill -SIGTERM 1234
# 強制終了(SIGKILL、最終手段)
$ sudo kill -9 1234
$ sudo kill -SIGKILL 1234
SIGTERMとSIGKILLの違い
- SIGTERM(-15): プロセスに「終了してください」と依頼する。プロセスは終了処理(ファイルのクローズ、一時ファイルの削除など)を行ってから終了できる
- SIGKILL(-9): プロセスを即座に強制終了する。プロセスは終了処理を行えない。データ損失やリソースリークの可能性がある
🚨 注意: kill -9は最終手段です。まずkill(SIGTERM)を試し、それでも終了しない場合にのみkill -9を使ってください。特にデータベースなどは、強制終了するとデータが壊れる可能性があります。
8.8.5 killall, pkillの使い方
プロセス名を指定して終了させることもできます。
killall – 名前でプロセスを終了
[実行ユーザー: 一般ユーザー(sudo使用)]
# httpdという名前のプロセスをすべて終了
$ sudo killall httpd
# 強制終了
$ sudo killall -9 httpd
pkill – パターンマッチでプロセスを終了
[実行ユーザー: 一般ユーザー(sudo使用)]
# httpdを含むプロセスを終了
$ sudo pkill httpd
# 特定ユーザーのプロセスを終了
$ sudo pkill -u apache
# 強制終了
$ sudo pkill -9 httpd
⚠️ 注意: killallやpkillは、意図しないプロセスまで終了させてしまう可能性があります。本番環境では、まずpgrepで対象を確認してから実行しましょう。
8.9 高度なトラブルシューティングツール
より深い調査が必要な場合に使うツールを紹介します。これらは「存在を知っておく」レベルで構いません。
8.9.1 lsof – ファイルを開いているプロセスを特定
lsof(List Open Files)は、開いているファイルとそのプロセスを表示します。
インストール
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo dnf install lsof
使用例
[実行ユーザー: 一般ユーザー(sudo使用)]
# 特定のポートを使っているプロセスを特定
$ sudo lsof -i :80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
httpd 1234 root 4u IPv6 12345 0t0 TCP *:http (LISTEN)
httpd 1235 apache 4u IPv6 12345 0t0 TCP *:http (LISTEN)
# 特定のファイルを開いているプロセスを特定
$ sudo lsof /var/log/messages
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rsyslogd 1234 root 5w REG 253,0 123456 123456 /var/log/messages
# 特定のプロセスが開いているファイル一覧
$ sudo lsof -p 1234
よくある使用場面
- 「Address already in use」エラーの原因特定
- 削除できないファイルの調査(プロセスが開いている)
- ネットワーク接続の調査
8.9.2 strace – システムコールのトレース
straceは、プロセスが実行するシステムコール(OSへの呼び出し)を追跡します。
インストール
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo dnf install strace
使用例
[実行ユーザー: 一般ユーザー(sudo使用)]
# コマンドの実行をトレース
$ strace ls /tmp
execve("/usr/bin/ls", ["ls", "/tmp"], 0x7fff... /* 23 vars */) = 0
...
openat(AT_FDCWD, "/tmp", O_RDONLY|O_NONBLOCK|O_CLOEXEC|O_DIRECTORY) = 3
...
# 実行中のプロセスにアタッチ
$ sudo strace -p 1234
# ファイルアクセスのみ表示
$ strace -e open,openat,read,write ls /tmp
straceは非常に強力ですが、出力が大量になるため、フィルタリングオプションを使いこなす必要があります。「プログラムがどのファイルを読んでいるか」「なぜエラーになるか」を調査するときに有用です。
8.9.3 tcpdump – ネットワークパケットキャプチャ
tcpdumpは、ネットワークパケットをキャプチャして表示します。
インストール
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo dnf install tcpdump
使用例
[実行ユーザー: 一般ユーザー(sudo使用)]
# 特定インターフェースのトラフィックをキャプチャ
$ sudo tcpdump -i enp0s3
# 特定ポートのトラフィック
$ sudo tcpdump -i enp0s3 port 80
# 特定ホストとの通信
$ sudo tcpdump -i enp0s3 host 192.168.1.50
# ファイルに保存(後でWiresharkで分析可能)
$ sudo tcpdump -i enp0s3 -w /tmp/capture.pcap
tcpdumpは、ネットワーク通信の詳細な調査に使います。「パケットは届いているか」「何が送受信されているか」を確認できます。
8.9.4 dmesg – カーネルメッセージ
dmesgは、カーネルのリングバッファに記録されたメッセージを表示します。
[実行ユーザー: 一般ユーザー(sudo使用)]
# 全メッセージ表示
$ sudo dmesg
# 人間が読みやすい時刻形式で表示
$ sudo dmesg -T
# エラーと警告のみ
$ sudo dmesg -T --level=err,warn
# リアルタイム監視
$ sudo dmesg -Tw
ハードウェア関連の問題(ディスクエラー、ネットワークインターフェースの問題など)を調査するときに使います。
8.9.5 パフォーマンス分析ツール
より詳細なパフォーマンス分析には、sysstatパッケージのツール群が使えます。
インストール
[実行ユーザー: 一般ユーザー(sudo使用)]
$ sudo dnf install sysstat
$ sudo systemctl enable --now sysstat
sar – システム活動レポート
[実行ユーザー: 一般ユーザー]
# CPU使用率の履歴
$ sar -u
# メモリ使用率の履歴
$ sar -r
# ディスクI/Oの履歴
$ sar -d
iostat – ディスクI/O統計
[実行ユーザー: 一般ユーザー]
$ iostat -x 1
Linux 6.12.0-1.el10.x86_64 (server1) 01/15/2026 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
2.34 0.00 1.02 0.15 0.00 96.49
Device r/s w/s rkB/s wkB/s await %util
sda 5.23 12.45 84.56 198.76 2.34 1.23
vmstat – 仮想メモリ統計
[実行ユーザー: 一般ユーザー]
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1234567 12345 567890 0 0 12 34 123 456 2 1 97 0 0
0 0 0 1234567 12345 567890 0 0 0 12 100 234 1 0 99 0 0
これらのツールは、パフォーマンス問題の詳細な分析に使います。本ガイドでは紹介にとどめますが、「こういうツールがある」と覚えておくと、必要なときに調べて使えます。
8.10 実践的なトラブルシューティング演習
学んだ内容を実践してみましょう。
8.10.1 意図的に問題を起こして解決する
学習環境(VPS)で、意図的に問題を起こして解決する練習をしましょう。
演習1: サービス起動失敗
[実行ユーザー: 一般ユーザー(sudo使用)]
# 1. httpdの設定ファイルを意図的に壊す
$ sudo cp /etc/httpd/conf/httpd.conf /etc/httpd/conf/httpd.conf.bak
$ echo "InvalidDirective" | sudo tee -a /etc/httpd/conf/httpd.conf
# 2. 起動を試みる
$ sudo systemctl restart httpd
# → 失敗する
# 3. ログを確認して原因を特定
$ journalctl -u httpd -e
# 4. 設定を修復
$ sudo cp /etc/httpd/conf/httpd.conf.bak /etc/httpd/conf/httpd.conf
# 5. 起動確認
$ sudo systemctl start httpd
$ systemctl status httpd
演習2: ディスク容量不足のシミュレーション
[実行ユーザー: 一般ユーザー]
# 1. 大きなファイルを作成(学習環境でのみ実行)
$ dd if=/dev/zero of=~/bigfile bs=1M count=500
# 2. ディスク容量を確認
$ df -h
# 3. 原因を特定
$ du -sh ~/*
# 4. ファイルを削除
$ rm ~/bigfile
# 5. 容量を確認
$ df -h
8.10.2 ログから原因を特定する思考プロセス
以下のログを見て、何が起きているか考えてみましょう。
Jan 15 14:30:00 server1 sshd[5678]: Failed password for invalid user admin from 203.0.113.50 port 54321 ssh2
Jan 15 14:30:05 server1 sshd[5679]: Failed password for invalid user admin from 203.0.113.50 port 54322 ssh2
Jan 15 14:30:10 server1 sshd[5680]: Failed password for invalid user admin from 203.0.113.50 port 54323 ssh2
Jan 15 14:30:15 server1 sshd[5681]: Failed password for invalid user root from 203.0.113.50 port 54324 ssh2
Jan 15 14:30:20 server1 sshd[5682]: Failed password for invalid user test from 203.0.113.50 port 54325 ssh2
分析
- 同じIPアドレス(203.0.113.50)から5秒間隔でアクセス
- 存在しないユーザー(admin, root, test)でログイン試行
- すべて「Failed password」(パスワード認証失敗)
結論
これはブルートフォース攻撃(総当たり攻撃)の兆候です。対策としては、fail2banの導入、パスワード認証の無効化(公開鍵認証のみ)、IPアドレスのブロックなどが考えられます。
8.10.3 問題解決後の検証方法
問題を解決したら、必ず以下を確認します。
- サービスの状態:
systemctl statusでactive (running)を確認 - ログのエラー:
journalctl -p errでエラーがないことを確認 - 機能テスト: 実際にサービスが動作することを確認(curlでアクセスなど)
- リソース: CPU、メモリ、ディスクが正常範囲内であることを確認
8.10.4 再発防止策の検討
問題が解決したら、同じ問題が再発しないよう対策を講じます。
- 設定ミス: 変更前のバックアップ、構文チェックの習慣化
- ディスク容量: ログローテーション設定、監視の追加
- ネットワーク: 冗長化、監視の追加
- セキュリティ: fail2banの導入、定期的なログ監視
8.10.5 ドキュメント化の重要性
発生した問題と解決策は必ず記録しておきましょう。
記録すべき内容
- 発生日時
- 症状(何が起きたか)
- 影響範囲(どのサービスに影響したか)
- 原因
- 解決手順
- 再発防止策
この記録は、将来同じ問題が発生したときに役立ちます。また、チームでの知識共有にも重要です。
【コラム7】ログを読まずに5時間無駄にした話
入社2年目の頃の話です。
ある日の午後、先輩から「開発環境のWebアプリが動かないんだけど、見てくれない?」と頼まれました。
「任せてください!」と意気込んで調査を開始。まず、アプリケーションのソースコードを確認しました。設定ファイルも見直しました。データベースへの接続も試しました。
2時間経過。原因がわかりません。
「もしかしてフレームワークのバグかも」と思い、GitHubのIssuesを検索。似たような問題を探しましたが、見つかりません。
4時間経過。焦りが出てきました。
「ネットワークの問題かも」と思い、ping、traceroute、curlを駆使して調査。問題は見つかりません。
5時間が過ぎた頃、たまたま通りかかった先輩が「どう?」と声をかけてきました。
「全然わからないんです。コードも設定も問題なさそうなのに…」
先輩は一言。「ログ見た?」
…見てませんでした。
$ journalctl -u myapp -e
Jan 15 10:00:00 devserver myapp[1234]: ERROR: Configuration file not found: /etc/myapp/config.yml
Jan 15 10:00:00 devserver myapp[1234]: Please create the configuration file or set MYAPP_CONFIG environment variable.
設定ファイルのパスが変わっていて、ファイルが見つからなかったのです。
設定ファイルを正しい場所にコピーして、サービスを再起動。1分で解決しました。
5時間かけて調べたことは、すべてログの1行目に書いてあったのです。
先輩は笑いながら言いました。「困ったら、まずログ。これ、鉄則だから」
それ以来、私は何か問題が起きたら、まずjournalctlを叩くようになりました。この習慣のおかげで、無駄な時間を過ごすことは激減しました。
教訓:
- 問題が起きたら、まずログを見る
- 思い込みで調査しない(「コードの問題だ」と決めつけない)
- 基本に立ち返る(複雑に考えすぎない)
5時間という「授業料」は高くつきましたが、二度と忘れない教訓になりました。
章末まとめ
この章では、ログ管理とトラブルシューティングの基礎を学びました。
学んだこと
- ログの重要性: 障害対応の90%はログから始まる。「まずログを見る」を習慣に
- ログファイルの構成: /var/log/配下の主要なログファイルと用途
- journalctlの実践的な使い方: 時間範囲、優先度、サービスでのフィルタリング、grepとの組み合わせ
- トラブルシューティングの流れ: 事象の特定 → 情報収集 → 仮説 → 検証 → 対処 → 確認 → 再発防止
- ケーススタディ: サービス起動失敗、ネットワーク問題、ディスク容量不足の解決方法
- システム監視: top/htop、free、df、uptimeの使い方
- プロセス管理: ps、pgrep、kill、killall、pkillの使い方
- 高度なツール: lsof、strace、tcpdump、dmesg、sysstatの存在
重要なコマンド
| 用途 | コマンド |
|---|---|
| ログ確認(基本) | journalctl -u サービス名 -e |
| ログ確認(時間指定) | journalctl --since "1 hour ago" |
| ログ確認(エラーのみ) | journalctl -p err |
| リアルタイム監視 | journalctl -f |
| システム負荷 | top、htop、uptime |
| メモリ確認 | free -h |
| ディスク確認 | df -h、du -sh |
| プロセス一覧 | ps aux、pgrep |
| プロセス終了 | kill PID、kill -9 PID |
練習問題
問題1: journalctlで、httpdサービスの直近1時間のエラー以上のログを確認するコマンドを書いてください。
解答を表示
$ journalctl -u httpd --since "1 hour ago" -p err-u httpdでサービス指定、--since "1 hour ago"で時間範囲指定、-p errでエラー以上を指定します。
問題2: topコマンドの出力で「load average: 4.50, 3.20, 2.10」と表示されています。このサーバーは2コアCPUです。現在の負荷状況を説明してください。
解答を表示
ロードアベレージが4.50(直近1分平均)で、CPUコア数(2)の2倍以上あるため、過負荷状態です。実行待ちのプロセスが常に存在し、処理が遅延している状態です。5分平均(3.20)、15分平均(2.10)を見ると、負荷が増加傾向にあることもわかります。
問題3: ディスク容量不足が発生しました。原因を特定するためのコマンドを、実行順に3つ挙げてください。
解答を表示
# 1. ディスク全体の使用状況を確認
$ df -h
# 2. どのディレクトリが容量を使っているか確認
$ sudo du -sh /* | sort -rh | head -10
# 3. さらに詳細を特定(例: /varが大きい場合)
$ sudo du -sh /var/* | sort -rh | head -10問題4: プロセスを安全に終了させる場合、まず何のシグナルを送るべきですか?また、それでも終了しない場合に使うシグナルは何ですか?理由も含めて説明してください。
解答を表示
最初に送るシグナル: SIGTERM(15)
理由: プロセスに終了を依頼し、正常な終了処理(ファイルのクローズ、一時ファイルの削除など)を行う機会を与えるため。
$ kill 1234 # または
$ kill -15 1234それでも終了しない場合: SIGKILL(9)
理由: SIGTERMを無視するプロセスを強制終了するため。ただし、終了処理が行われないため、データ損失やリソースリークの可能性がある。最終手段として使用する。
$ kill -9 1234問題5: サービスが起動しないというトラブルが発生しました。調査手順を5つのステップで説明してください。
解答を表示
- サービスの状態確認:
$ systemctl status サービス名 - ログでエラー内容を確認:
$ journalctl -u サービス名 -xe - 設定ファイルの構文チェック:(サービスによる)
$ sudo apachectl configtest # Apacheの場合 $ sudo nginx -t # Nginxの場合 - パーミッションとSELinuxの確認:
$ ls -la /path/to/config $ sudo ausearch -m AVC -ts recent - ポート競合の確認:
$ sudo ss -tlnp | grep :ポート番号
問題6: 以下のfreeコマンドの出力を見て、このサーバーのメモリ状態を評価してください。追加のメモリが必要かどうかも判断してください。
total used free shared buff/cache available
Mem: 3.8Gi 3.2Gi 100Mi 50Mi 500Mi 400Mi
Swap: 2.0Gi 1.5Gi 500Mi
解答を表示
状態: メモリが逼迫しています。
- 物理メモリ3.8GBのうち、availableが400MBしかない
- スワップが1.5GB使用されている(物理メモリが足りず、ディスクに退避している)
評価:
- availableが総メモリの10%程度しかなく、余裕がない
- スワップが大量に使用されているため、パフォーマンスが低下している可能性が高い
判断: メモリの増設を検討すべき状態です。または、メモリを大量に消費しているプロセスを特定し、チューニングや分散を検討します。
次章への橋渡し
この章では、問題が発生したときの対処方法を学びました。しかし、本当に重要なのは問題が発生しないように予防することです。
次の第9章「バックアップと運用の基礎」では、以下を学びます。
- バックアップの重要性: データ損失からの復旧
- バックアップ戦略: フルバックアップ、増分バックアップ
- tarとrsync: バックアップツールの使い方
- ログローテーション: ログファイルの適切な管理
- システムメンテナンス: 定期的な運用作業
- ドキュメンテーション: 運用手順書の作成
トラブルシューティングができるようになった今、次は「トラブルを予防する運用」を学びましょう。
