
プロジェクトには「必ず」想定外の問題が発生します。それがスケジュール遅延なのか、予算超過なのか、技術的な問題なのかは事前には分かりません。しかし、どのような問題であっても、事前に準備していれば影響を最小限に抑えることができます。
「プロジェクト中盤で想定外の仕様変更が発生した」「外部ベンダーの納品が遅れ、開発スケジュールが崩壊した」「システムテストの段階で重大な性能問題が発覚した」――こうしたトラブルが発生したとき、リスク管理ができているかどうかでプロジェクトの結果は大きく変わります。
本記事では、「リスクの特定」「評価」「対応」「継続的な監視」という流れに沿って、ITプロジェクトで通用するリスクマネジメントの実践方法を解説します。
目次
1. なぜリスクマネジメントが重要なのか?
1-1. 「想定外は必ず起こる」— だからこそ準備が必要
プロジェクトの進行中に「想定外の問題」が発生することは避けられません。特にITプロジェクトでは、以下のようなリスクが発生します。
- 技術的リスク
- 採用した技術が予想通りに動作しない
- 予期せぬバグやパフォーマンス問題が発生
- 依存している外部APIやライブラリの仕様変更
- 人的リスク
- キーエンジニアが急に退職する
- チーム間のコミュニケーション不足による認識ズレ
- スキル不足による生産性の低下
- スコープリスク
- クライアントからの仕様変更が相次ぐ
- 必要な要件が曖昧なまま開発が進んでしまう
- 要件追加によるスコープクリープ(膨張)
- スケジュールリスク
- 予測よりも開発に時間がかかる
- テスト工程の遅延により、リリース日が迫る
- 外部ベンダーの納期遅れ
- 外部依存リスク
- クラウドサービスや外部システムの障害
- 仕入先やパートナー企業のトラブル
- 法律や規制の変更
プロジェクトを計画するとき、多くの人は「すべてが予定通りに進む」ことを前提にしてしまいます。しかし、現実にはリスクが顕在化しないプロジェクトは存在しません。リスクを想定し、それに備えることが求められます。
1-2. リスクを甘く見たプロジェクトの失敗事例
リスクマネジメントを怠った結果、プロジェクトが失敗するケースは後を絶ちません。以下は、典型的な失敗事例です。
ケース1:仕様変更リスクを見落とし、手戻りが頻発
あるシステム開発プロジェクトで、要件定義が不十分なまま開発がスタートしました。開発途中でクライアントから「この機能を追加してほしい」と次々に仕様変更が発生しました。
- 設計を何度も変更することになり、手戻りが頻発
- 開発コストが当初の2倍に膨れ上がる
- 納期が半年遅れ、プロジェクトは失敗
「変更は起こる」と想定し、スコープを厳密に管理する必要がありました。クライアントと変更管理プロセス(CCB:Change Control Board)を合意しておくべきだったケースです。
ケース2:キーパーソンが突然退職し、計画が崩壊
ある企業の社内システム刷新プロジェクトでは、全体の設計をリードするシニアエンジニア1名に大きく依存していました。そのエンジニアが急遽、別の会社に転職することが決定しました。
- 引き継ぎが不十分で、設計の意図が分からなくなる
- 残されたメンバーのスキルが不足しており、開発スピードが激減
- プロジェクトは6か月以上の遅延が発生
属人化を防ぎ、ナレッジをチームで共有する仕組みが必要でした。「この人がいなくなったら終わり」という状態を作らないことが教訓です。
1-3. 成功するプロジェクトはリスクをコントロールしている
失敗プロジェクトの共通点は、「リスクを軽視していたこと」です。一方で、成功するプロジェクトはリスクを適切に管理し、対策を講じています。
成功するプロジェクトに共通する特徴は次の3つです。
- リスクを先回りして特定し、対策を立てている。開発開始前に「このプロジェクトで発生し得るリスクは何か」を徹底的に洗い出します。
- リスクの影響度を評価し、重要なものから優先して対応している。すべてのリスクを解消するのは不可能なので、「どのリスクが最もクリティカルか」を見極めます。
- リスクが顕在化したときにすぐ対応できる体制を整えている。リスクが発生した際の「リカバリープラン」を事前に準備しておきます。
例えば、リスクマネジメントが成功したプロジェクトでは、以下のような施策が取られています。
技術リスクへの対応策
- 技術検証(PoC)を事前に実施し、採用技術の問題を早期発見
- 依存する外部ライブラリのバージョンアップ計画を明確にする
人的リスクへの対応策
- チームメンバーのタスクを分散し、特定の個人に依存しない仕組みを作る
- 「退職リスク」の高い人を事前に把握し、代替メンバーを確保
スケジュールリスクへの対応策
- クリティカルなタスクにはバッファ期間を設ける
- マイルストーンごとに進捗を評価し、遅延を早期発見
成功するプロジェクトは「リスクをゼロにしよう」とするのではなく、リスクを見える化し、適切にコントロールしています。
2. リスク管理の基本プロセス
リスクマネジメントは、以下の4つのプロセスで構成されます。「リスクの特定」→「リスクの分析」→「リスク対応戦略」→「リスクのモニタリング」というサイクルを適切に回すことで、リスクの影響を最小限に抑え、プロジェクトを安定させることができます。
【図:リスク管理の4ステップ】
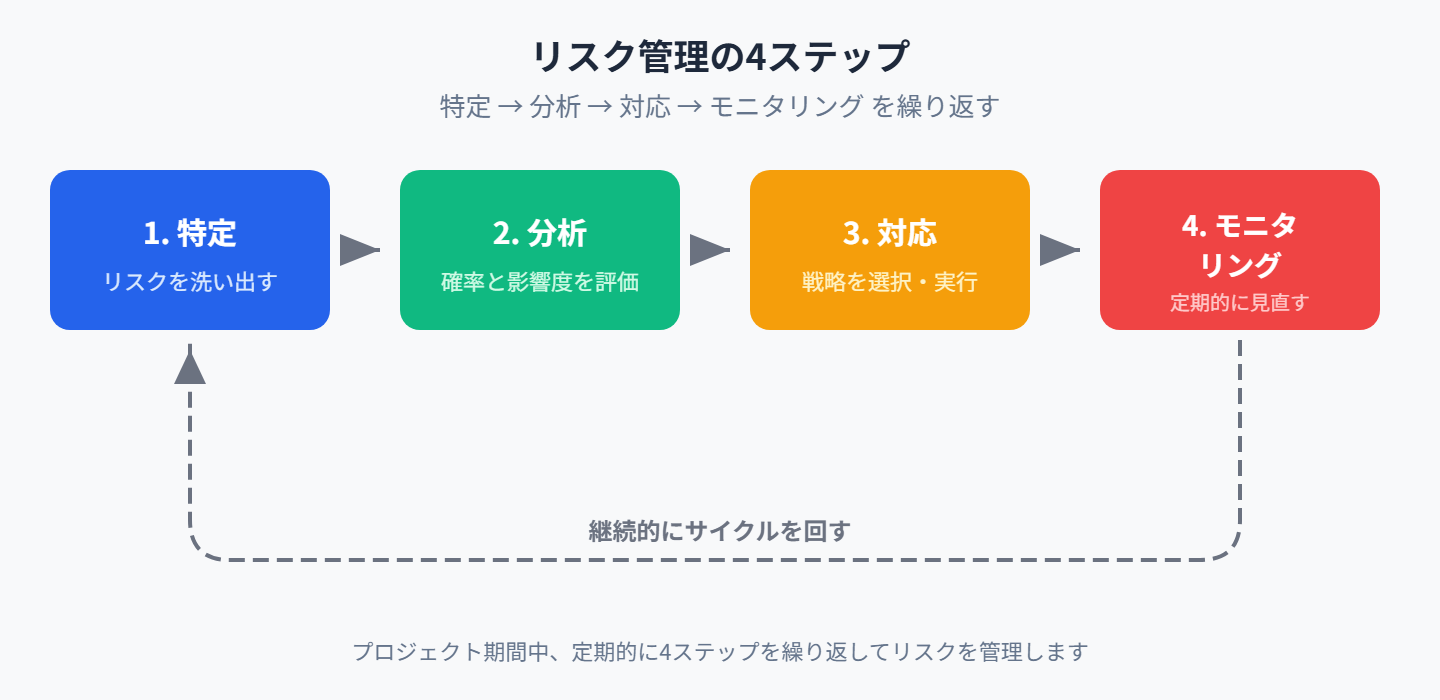
2-1. リスクの特定 – どんなリスクがあり得るのか?
リスクマネジメントの第一歩は、プロジェクトに潜むリスクを特定することです。この段階では、可能な限りすべてのリスクを洗い出すことが求められます。
リスクを特定するには、以下の手法を活用します。
過去プロジェクトの教訓を活かす
- 過去の類似プロジェクトで発生したリスクを分析する
- プロジェクト失敗事例のナレッジベースを参照する
過去に発生したトラブルの例として、仕様変更が多発してスケジュールが遅延したケース、クラウドサービスの障害でシステムがダウンしたケース、主要メンバーが退職し知識が属人化していたケースなどがあります。
チームブレインストーミング
- プロジェクトメンバー全員でリスクブレストを実施
- 「最悪のシナリオは何か?」という視点でディスカッション
具体的な質問例としては、「このプロジェクトの技術的な課題は何か?」「クライアントの要求変更が発生した場合、どんな影響があるか?」「チームメンバーのスキル不足やリソース不足はないか?」などが挙げられます。
チェックリストの活用
- ITプロジェクトのリスク一覧をもとにチェック
- 「技術リスク」「人的リスク」「スケジュールリスク」「外部依存リスク」のカテゴリごとに整理
チェックリストの例(スコープリスク)として、要件が曖昧なまま進行していないか、変更管理プロセスは明確か、クライアントと合意済みのドキュメントがあるか、などを確認します。
このように、あらゆる角度からリスクを洗い出すことが、リスク特定の基本です。
2-2. リスクの分析 – 発生確率と影響度を評価する
リスクを特定したら、次に「どのリスクがどれくらいの影響を持つのか」を評価します。このプロセスでは、リスクの発生確率と影響度を定量的に分析し、優先順位をつけます。
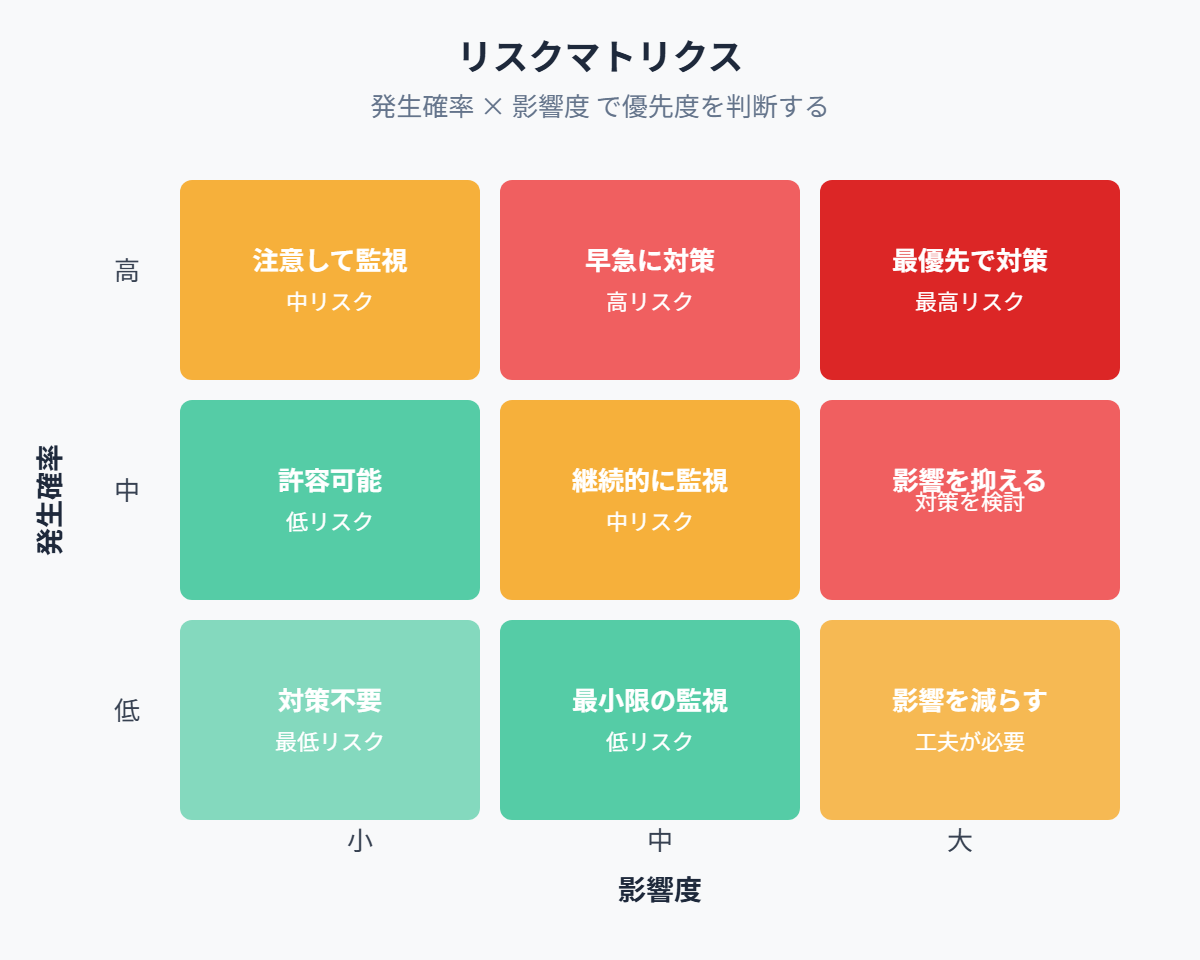
リスクマトリクスの活用
リスクの重要度を分類するために、リスクマトリクス(Risk Matrix)を使用します。
| 影響度:大 | 影響度:中 | 影響度:小 | |
|---|---|---|---|
| 発生確率:高 | 最優先で対策 | 早急に対策 | 注意して監視 |
| 発生確率:中 | 影響を抑える対策を検討 | 継続的に監視 | 許容可能(最低限の対策) |
| 発生確率:低 | 影響を減らす工夫 | 最小限の監視 | 特に対策不要 |
具体例として、「クラウドサービスの障害発生」は影響度:大、発生確率:中で最優先の対策が必要です。「主要メンバーの退職」は影響度:中、発生確率:高で早急に対策すべきです。「開発環境のマシンスペック不足」は影響度:小、発生確率:中で継続的に監視する対象です。
リスクの分析を通じて、「今すぐ対応すべきリスク」と「監視すればよいリスク」を明確にすることが、この工程の目的です。
【図:リスクマトリクス(発生確率×影響度)】
2-3. リスク対応戦略 – 回避・軽減・転嫁・受容の使い分け
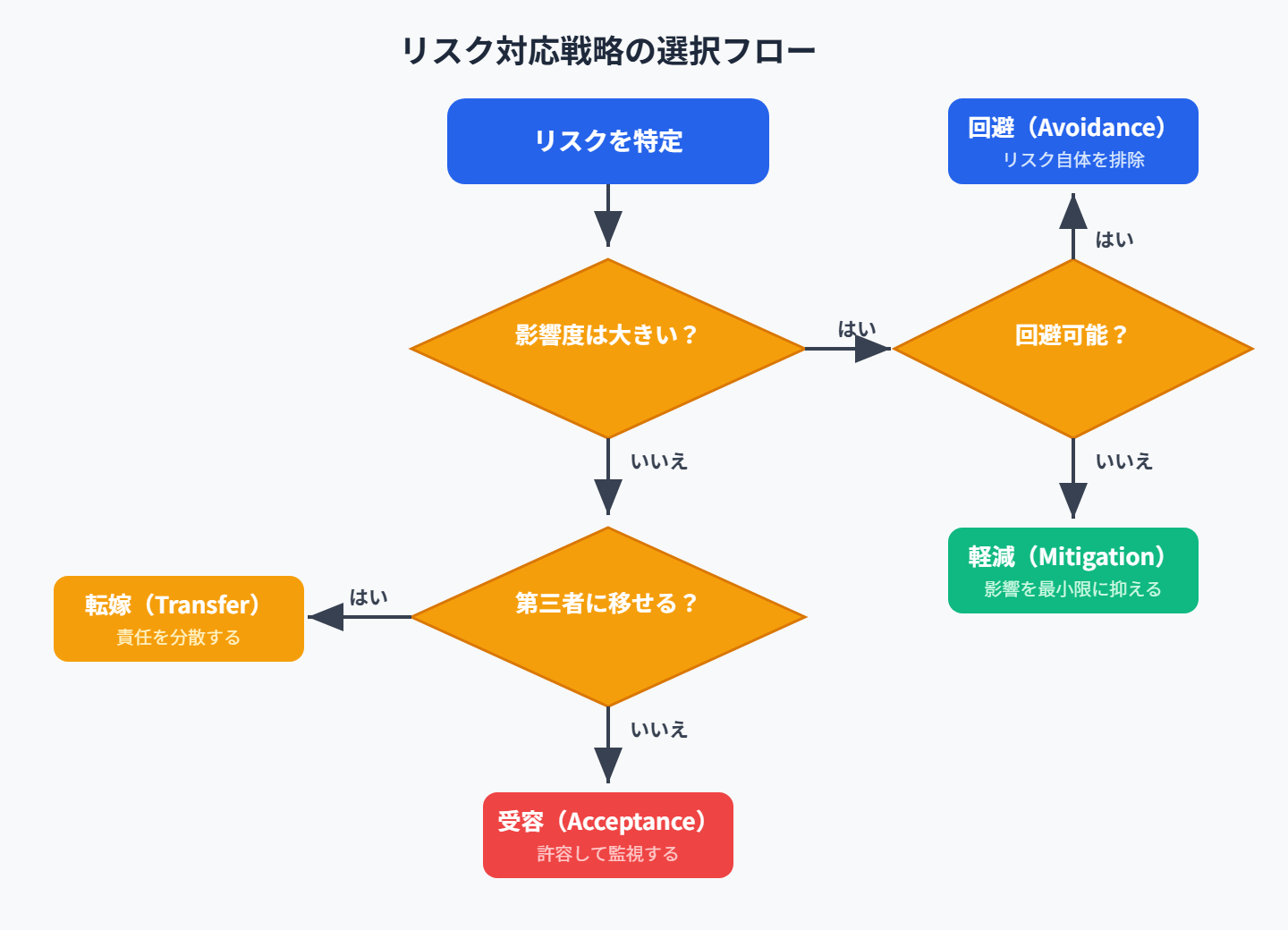
リスク分析の結果に基づき、適切なリスク対応戦略を選択します。リスク対応の基本は、「回避」「軽減」「転嫁」「受容」の4つです。
1. 回避(Avoidance)
- リスク自体を排除する方法
- 最も効果的だが、完全に回避するのは難しい
例:不確実な技術を採用しない。不明確な要件のタスクを進めず、事前に定義を明確化する。
2. 軽減(Mitigation)
- リスクの発生確率や影響を減らす
- 多くのプロジェクトで採用される戦略
例:重要な機能の技術検証(PoC)を事前に実施する。主要エンジニアにナレッジ共有を徹底する。
3. 転嫁(Transfer)
- リスクを第三者に移す(アウトソーシング、契約)
- 契約やSLAを活用して、責任を分散
例:クラウドサービスを利用し、運用リスクをベンダーに委託する。外部パートナーに開発の一部を委託する。
4. 受容(Acceptance)
- リスクを許容し、対策はせずに進める
- 影響が小さい場合に適用
例:仕様変更のリスクはあるが、必要な場合は追加工数として対処する。低リスクのバグはリリース後に修正対応する。
リスクの性質に応じて、最適な対応策を選ぶことがポイントです。
【図:リスク対応戦略の選択フロー】
2-4. リスクのモニタリング – 定期的な見直しと対応のアップデート
リスクマネジメントは一度やったら終わりではなく、継続的に見直す必要があります。プロジェクトの状況が変われば、新たなリスクが発生し、優先度も変化します。
定期的なリスクレビューの実施
- 週次または月次でリスクリストを更新
- 主要リスクの発生状況をモニタリング
リスクの発生を早期に察知する仕組み
- KPIやアラートを設定し、異常を検知
- 進捗遅延やエラー増加のトレンドを把握
リスクのモニタリングを怠ると、問題が発生してからの対応が後手に回り、手遅れになる可能性があります。
3. 「想定外」を想定するためのリスク洗い出し手法
プロジェクトのリスク管理において、最も危険なのは「想定外の問題」に対する準備がないことです。どれほど綿密な計画を立てても、何かしらの問題は発生します。
しかし、「想定外」と言われる問題の多くは、実は事前に予測できるリスクであることがほとんどです。「仕様変更が繰り返されて開発が終わらない」「主要メンバーが突然辞めて誰もコードを理解していない」「サーバーの負荷が想定以上で本番環境がダウン」といったトラブルは、過去のプロジェクトで何度も発生しています。
こうした問題を「想定外だった」と片付けるのではなく、事前に想定し、対策を準備することがリスクマネジメントの核心です。
3-1. 過去のプロジェクトの失敗から学ぶリスクのパターン
リスクをゼロから洗い出すのは大変ですが、多くのリスクにはパターンがあります。過去のプロジェクトを分析することで、よくある失敗の兆候を特定し、次のプロジェクトで活かすことができます。
プロジェクト終了後に、「どんな問題が発生し、それがどう影響したのか」を記録し、リスク管理に役立てるべきです。
失敗ナレッジの記録例
- プロジェクトのスコープが曖昧だったため、仕様変更が頻発し、納期が遅延
- 開発環境と本番環境のスペックが異なり、本番でパフォーマンス問題が発生
- 主要メンバーの退職に備えた引き継ぎがなかったため、緊急対応が難航
こうしたナレッジを「チェックリスト」や「ケーススタディ」として共有すれば、次回のプロジェクトで同じ失敗を防ぐことができます。
3-2. チェックリスト・リスクシナリオの作成方法
リスクを体系的に整理し、漏れを防ぐには、チェックリストを活用するのが効果的です。カテゴリごとにリスクを整理すると、効率的にリスクを特定できます。
スコープリスクのチェックリスト
要件が明確に定義されているか。仕様変更の影響を評価するプロセスがあるか。クライアントの期待と認識がズレていないか。
技術リスクのチェックリスト
採用する技術の動作検証(PoC)は実施済みか。主要なシステムのパフォーマンス試験は行ったか。外部APIやライブラリの仕様変更リスクは確認したか。
人的リスクのチェックリスト
キーパーソンが辞めた場合のバックアップはあるか。チーム内で知識が属人化していないか。コミュニケーションの課題が発生していないか。
こうしたチェックリストを活用すると、リスクの見落としを防ぐことができます。
3-3. チーム全員でリスクを洗い出す「リスクブレインストーミング」の実践
個人でリスクを洗い出すだけでなく、チーム全員でディスカッションすることで、より多くのリスクを特定できます。そのために有効なのが「リスクブレインストーミング」です。
リスクブレインストーミングの進め方
- 全員で「最悪のシナリオ」を考える。「このプロジェクトが失敗するとしたら、どんな原因が考えられるか」を議論します。
- リスクをカテゴリごとに整理する。「技術」「スコープ」「スケジュール」「人的」「外部依存」などのカテゴリに分類します。
- リスクの優先度を評価する。影響度と発生確率を考慮して、対応すべきリスクを決定します。
具体例:Webアプリ開発プロジェクトの場合
「最悪のシナリオは何か」という問いに対して、あるチームでは次のような意見が出ました。「リリース直前で重大なバグが見つかり、スケジュールが大幅に遅れる」「想定以上のトラフィックでサーバーがダウンする」「クライアントから突然の仕様変更が入り、大量の修正が発生する」。
これらのリスクを具体的な対応策に落とし込むことが大切です。
「リリース直前で重大なバグが発生するリスク」に対しては、事前に徹底したテスト計画を策定し、機能ごとに早期にリリースして継続的に品質を検証します。
「サーバー負荷増大でダウンするリスク」に対しては、負荷テストを事前に実施してスケーラビリティを確認し、オートスケール機能を導入してトラフィック急増に対応します。
このように、「最悪のシナリオ」を考え、具体的な対策を講じることで、リスクを大幅に軽減できます。
リスクマネジメントにおいて、「想定外」は言い訳になりません。過去の失敗から学び、チェックリストを活用し、チーム全員でリスクを洗い出すことで、多くのトラブルは事前に予測し、対策を講じることができます。
4. 実務で役立つリスク回避・軽減・転嫁の戦略
リスクマネジメントにおいて最も大切なのは、「リスクはゼロにはならない」という前提でプロジェクトを設計することです。「このプロジェクトでは問題が起きないようにしよう」と考えるのは現実的ではありません。
- リスクは「管理するもの」であり、「完全に消すもの」ではない
- 問題が発生することを前提にし、発生した際にどのように対応するかを決めておく
- 「問題をなくす」よりも「影響を最小限に抑える」ことにフォーカスする
こうした考え方のもと、実務で役立つリスク対応戦略を「回避」「軽減」「転嫁」に分けて解説します。
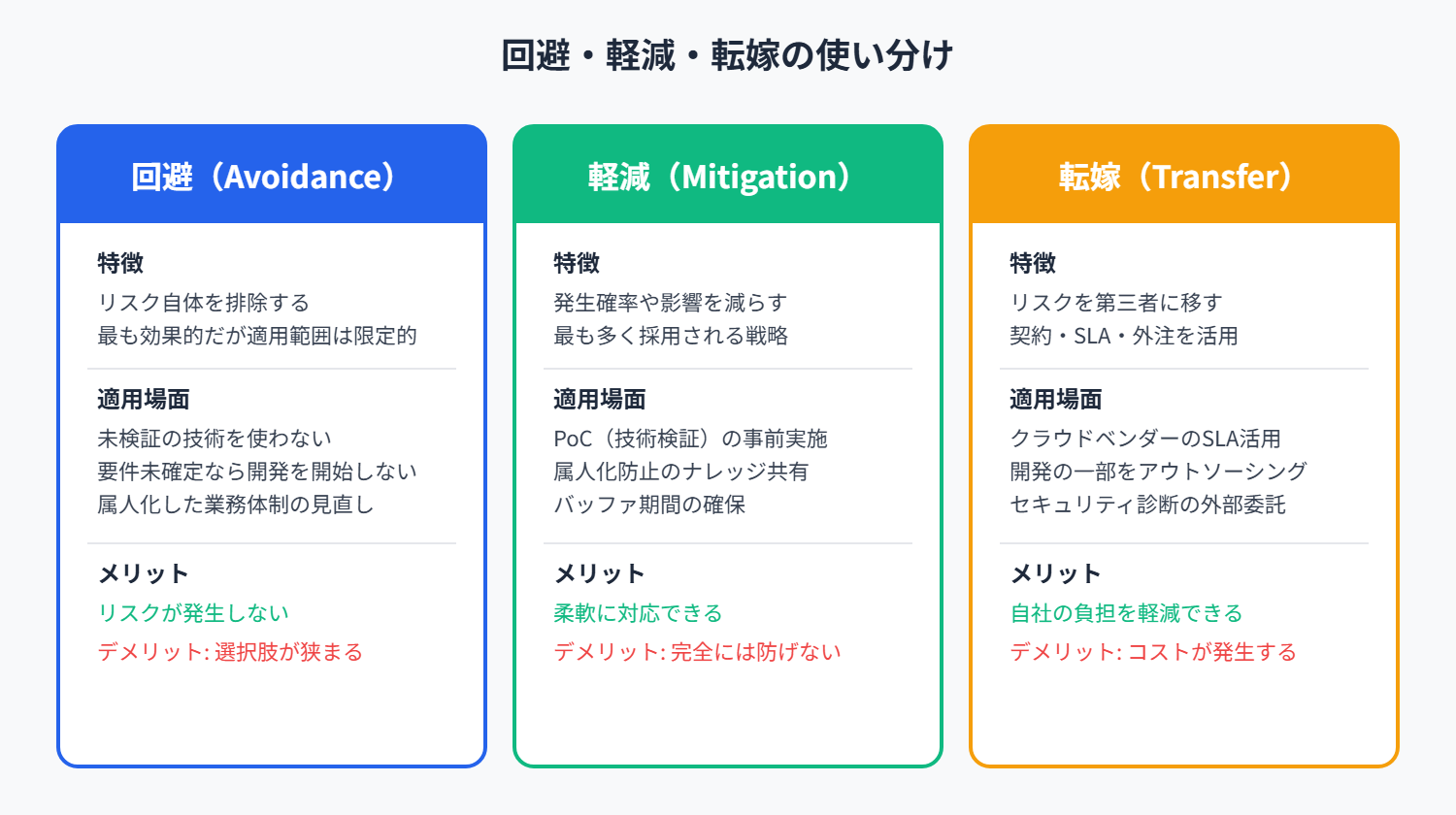
4-1. リスク回避(Avoidance)— 問題を根本からなくす
「回避」戦略とは、リスクそのものを排除するための手段を講じることです。最も理想的な対応策ですが、完全なリスク回避は難しいため、実行可能な範囲で適用する必要があります。
具体的なリスク回避策
| リスクの種類 | 回避策 |
|---|---|
| 技術的リスク | 実績のない技術は採用せず、実績のある技術を選択する。事前にPoC(概念実証)を実施し、動作検証する。 |
| スコープリスク | 要件が曖昧な場合は、契約前にスコープを厳密に定義する。クライアントとの要件合意が取れるまで、開発を開始しない。 |
| 人的リスク | 重要なポジションに属人化した業務を持たせない。キーパーソンが退職した場合の対応策を事前に用意する。 |
| スケジュールリスク | 過密なスケジュールを避け、十分なバッファを確保する。マイルストーンごとにフェーズを区切り、段階的に進める。 |
技術的リスクが高いプロジェクトでは、安定した技術を選ぶことでリスクを回避できます。クライアントの要件変更が頻発する場合は、契約時点でスコープを明確にし、変更管理プロセスを定義することでリスクを減らせます。
4-2. リスク軽減(Mitigation)— 影響を最小限に抑える
「回避」が難しい場合は、次善策として「リスクの発生確率を減らす」または「リスク発生時の影響を小さくする」ことが必要です。これが「リスク軽減」戦略です。
具体的なリスク軽減策
| リスクの種類 | 軽減策 |
|---|---|
| 技術的リスク | 段階的な開発・リリース(アジャイル開発)を採用し、早期に問題を発見する。開発環境と本番環境を統一し、環境差異をなくす。 |
| スコープリスク | 仕様変更が想定される場合、変更管理プロセス(CCB)を確立する。プロトタイピングを活用し、早い段階でフィードバックを得る。 |
| 人的リスク | 重要な業務を複数人で担当し、属人化を防ぐ。ドキュメントを充実させ、業務継続性を確保する。 |
| スケジュールリスク | 重要なタスクにバッファを設け、遅延の影響を最小限にする。クリティカルパスを特定し、優先順位を明確にする。 |
クラウドの負荷対策では、負荷テストを事前に実施し、スケールアップの準備をします。仕様変更のリスクに対しては、プロトタイプを早めに作成し、フィードバックを得ることで仕様確定を促進できます。
4-3. リスク転嫁(Transfer)— 責任を分散する
リスクの影響を減らすために、リスクの一部を他の組織や契約によって分散させる方法が「リスク転嫁」です。特に、契約・SLA(サービスレベル契約)・アウトソーシングを活用して、リスクを別の主体に移すことが有効です。
具体的なリスク転嫁策
| リスクの種類 | 転嫁策 |
|---|---|
| 技術的リスク | クラウドベンダーのSLAを活用し、障害時の対応責任を明確化する。外部のセキュリティ専門企業に脆弱性診断を委託する。 |
| スコープリスク | 仕様変更リスクを契約書で明確にし、追加費用のルールを定める。 |
| 人的リスク | 開発の一部をアウトソーシングし、人材不足リスクを軽減する。 |
| スケジュールリスク | 外部の開発パートナーと連携し、納期遅延リスクを分散する。 |
サーバーダウンのリスクに対しては、クラウドベンダーのSLAを活用して復旧時間を保証してもらいます。開発リソース不足のリスクに対しては、外部ベンダーと契約して人的リソースを確保します。
4-4. 実務では回避・軽減・転嫁を組み合わせるのが鍵
実際のプロジェクトでは、単独の戦略ではなく、これらの戦略を組み合わせることが効果的です。
例:クラウド基盤の構築プロジェクト
- 「技術リスク回避」→ 実績のあるクラウドプロバイダーを採用
- 「リスク軽減」→ 負荷テストを実施し、スケール戦略を確立
- 「リスク転嫁」→ クラウドベンダーのSLAを活用し、可用性保証を明文化
リスクマネジメントの目的は「リスクゼロを目指す」ことではなく、適切にコントロールし、プロジェクトを安定運営することです。
【図:回避・軽減・転嫁の使い分け】
5. 事例で学ぶリスクマネジメント(成功例・失敗例)
リスクマネジメントの効果を理解するには、実際のプロジェクトでリスク対応が成功したケースと失敗したケースを比較することが効果的です。以下では、成功したリスク対応のケースと失敗したリスク管理のケースを具体的に紹介し、どのような違いがあったのかを分析します。
5-1. 成功したリスク対応のケース
ケース1:開発遅延リスクを早期発見し、リカバリープランを実行
A社のITシステム開発プロジェクトでは、アジャイル手法を採用していました。スプリントごとに進捗を評価していたところ、3スプリント目で機能開発の進捗が著しく遅れていることが判明しました。原因を調査した結果、以下のリスクが影響していました。
- 技術的リスク:採用したフレームワークの学習コストが高く、開発スピードが低下
- 人的リスク:チームメンバーのスキルが想定より不足しており、コードレビューで指摘が頻発
取った対応策
リスク軽減策(Mitigation)として、フレームワークのトレーニングセッションを実施し、チームのスキルを底上げしました。経験豊富なエンジニアをサポート役としてペアプログラミングを導入し、開発速度を向上させました。
リスク転嫁策(Transfer)として、一部の開発を外部パートナーに委託し、リソースを強化しました。
リカバリープランとして、影響の大きい機能を優先順位付けし、リリーススケジュールを再調整しました。
その結果、開発速度が向上し、最終的にリリース日は予定通りに達成できました。スキル不足のメンバーも成長し、プロジェクト終了後も技術力を活かして活躍しています。
成功のポイントは、遅れを早期に察知してすぐに対策を実行したこと、チームのスキルギャップに対応する教育施策を導入したことです。
ケース2:クラウド移行リスクを事前に特定し、影響を回避
B社では、既存のオンプレミスシステムをクラウドに移行するプロジェクトを進めていました。プロジェクト開始前に、リスクマネジメントチームが「移行に伴うリスク」を洗い出しました。
- 技術的リスク:現在のアプリケーションがクラウド環境で正常に動作するか不明
- スケジュールリスク:既存システムのダウンタイムを最小限に抑える必要がある
取った対応策
リスク回避策(Avoidance)として、事前にPoC(概念実証)を実施し、クラウド環境での動作確認を徹底しました。既存システムとの互換性をチェックし、問題が発生しそうな箇所を特定しました。
リスク軽減策(Mitigation)として、本番環境移行をフェーズごとに分割し、段階的な移行を実施しました。ダウンタイムを最小限にするため、ローリングデプロイを採用しました。
リスク転嫁策(Transfer)として、クラウドベンダーのSLAを活用し、障害発生時の復旧時間を保証してもらいました。
その結果、クラウド移行は計画通りに成功し、ダウンタイムも最小限に抑えられました。移行後のパフォーマンス問題も発生せず、運用がスムーズに移行できました。
成功のポイントは、PoCを事前に実施して技術的なリスクを排除したこと、クラウド移行をフェーズ分けしてリスクを分散したことです。
5-2. 失敗したリスク管理のケース
ケース3:仕様変更リスクを見落とし、大幅な手戻り発生
C社の新規システム開発プロジェクトでは、クライアントの要求を満たすために開発を進めていましたが、途中でクライアントの要件が大きく変更されました。
- スコープリスク:仕様が確定しないまま開発が進み、変更要求が頻発
- スケジュールリスク:変更に対応するための工数が膨大になり、納期が延びた
スコープ管理を徹底せず、変更管理プロセスがありませんでした。事前に要件を確定する仕組みがなく、変更リスクが増大しました。
その結果、大量の仕様変更により開発が6か月以上遅延しました。クライアントとの関係も悪化し、プロジェクトは頓挫しました。
失敗のポイントは、スコープリスクを事前に管理できていなかったこと、変更管理プロセスがなく要件変更が歯止めなく続いたことです。
ケース4:主要メンバーの退職リスクを無視し、開発がストップ
D社では、社内システムの開発を1人のリードエンジニアに依存していました。プロジェクトの進行中、そのエンジニアが突然退職しました。
- 人的リスク:主要な設計を担当するエンジニアが不在になり、他のメンバーはコードを理解していなかった
- 技術的リスク:設計資料や技術文書がほとんどなく、引き継ぎが困難
知識の属人化を防ぐドキュメント管理がされていませんでした。エンジニアの退職リスクを想定せず、バックアップ体制がありませんでした。
その結果、開発が2か月間ストップしました。残ったメンバーで開発を進めるも、品質が低下し、追加の手戻りが発生しました。
失敗のポイントは、リスクの洗い出しが不十分で退職リスクを想定していなかったこと、ナレッジ共有がされておらず属人化した開発体制だったことです。
成功と失敗の違いは、リスクを事前に管理できているかどうかに尽きます。
6. 今日からできるアクション
- プロジェクトのリスクを「技術・人的・ビジネス・組織」の4カテゴリで整理する
- リスクマトリクスを作成し、優先度を明確にする
- 各リスクに対して「回避・軽減・転嫁・受容」のどれを適用するか決定する
- リスク監視のルールを設定し、定期的に見直す仕組みを作る
次回の記事
次回の第4回では、「進捗管理のコツ」をテーマに解説します。
第4回:プロジェクト進捗管理のコツ|「順調です」に潜むリスクを見抜く実践手法
プロジェクトマネジメントシリーズ 記事一覧
- 第1回:プロジェクト管理の本質とは?スケジュール管理を超えた「価値を生むPM」の考え方
- 第2回:プロジェクト計画の立て方|WBS・スコープ定義・マイルストーンの実務テクニック
- 第3回:リスクマネジメントの実践|「想定外を想定する」ITプロジェクトのリスク管理プロセス(この記事)
- 第4回:プロジェクト進捗管理のコツ|「順調です」に潜むリスクを見抜く実践手法
- 第5回:プロジェクトのチームマネジメントとリーダーシップ|フェーズごとに変わるPMの役割
- 第6回:ステークホルダーマネジメント|期待値管理・影響度分析・対立解決の実践ガイド
- 第7回:プロジェクトトラブル対応(火消しスキル)|炎上の兆候発見から収束まで
- 第8回:品質管理とデリバリー|「動けばOK」ではない、PMが押さえるべき品質の作り込み方
- 第9回:プロジェクト終了と振り返り|クロージングから学びを次につなげる仕組みづくり
- 第10回:プロジェクトマネジメントスキルの継続的向上|エンジニアからPMへのキャリアパスと学習戦略