
1.1 実践編のはじまり
1.1.1 応用編を終えたあなたの現在地
応用編の全9回、おつかれさまでした。
あなたの手元には、Namespace分離、RBAC、StatefulSet、DaemonSet、Job、CronJob、Gateway API、NetworkPolicy、SecurityContext、HPA、Probe、Helm——本番環境で必要な武器が一通り揃っています。そしてTaskBoardは、これらの武器をすべて装備した「完全体」として、kindクラスタ上で稼働しています。
しかし、ひとつ振り返ってみてください。TaskBoardは「設計して作ったもの」でしょうか。
応用編では、第1回でNamespaceを作り、第2回でRBACを追加し、第3回でStatefulSetを導入し……と、毎回1つの武器を学びながらTaskBoardに部品を追加していきました。結果として動くシステムが出来上がりましたが、それは「部品を積み上げた結果」であり、「最初から全体像を描いて組み立てたもの」ではありません。
実際のプロジェクトでは、この順番で物事は進みません。まず要件があり、全体像を描き、設計書を書き、手順に沿って構築し、運用設計を整え、障害に対処する。このライフサイクルを回せるかどうかが、「K8sを動かせるエンジニア」と「K8sでシステムを回せるエンジニア」の分かれ目です。
1.1.2 実践編で何をするか — 「プロのプロセスで」設計し直す
実践編のコアコンセプトはシンプルです。
応用編であなたはTaskBoardを「結果的に」作り上げた。
実践編では、同じTaskBoardを「プロのプロセスで」設計し直す。
応用編と実践編の違いを整理しておきましょう。
| 応用編 | 実践編 | |
|---|---|---|
| テーマ | 「この武器はこう使う」 | 「この武器をいつ・なぜ選ぶか」 |
| 中心活動 | 手を動かす体験 | 設計書・手順書・報告書を書くプロセス |
| 1回の構造 | 1問題領域 × TaskBoardに部品追加 | 1フェーズ × TaskBoard全体で実践 |
| 成果物 | 動くK8sリソース + 判断力 | 設計書・手順書・報告書 |
応用編は「武器の使い方を覚える場」でした。実践編は「武器をいつ・なぜ選ぶかを判断し、その判断を文書として残す場」です。成果物が「動くリソース」から「設計書」に変わる。ここが根本的な違いです。
VMの世界で例えるなら、応用編はNSX、vSAN、DRSなどの個別製品トレーニングに相当します。実践編は、それらの知識を持った上で本番環境の設計・構築・運用プロジェクトに参画する段階です。
1.1.3 実践編の全体マップ — 10回で回すライフサイクル
実践編では、インフラのライフサイクルを4つのフェーズに分け、全10回で一周します。
【フェーズ1:設計】
第1回 ── 構成図:システム全体を「見える化」する ← 今回はここ
第2回 ── 基本設計:要件からK8sリソースへの変換
第3回 ── 詳細設計:マニフェストの全パラメータを根拠を持って決める
【フェーズ2:構築】
第4回 ── 環境構築:基盤整備とNamespace・RBAC・基盤コンポーネント
第5回 ── アプリケーション構築:設計書通りに段階デプロイ・検証
第6回 ── ネットワーク構築と結合テスト:外部公開・通信制御・E2E検証
【フェーズ3:運用】
第7回 ── 運用設計:監視・スケーリング・デプロイ戦略・バックアップ
第8回 ── 日常運用:変更管理・Helm運用・メンテナンスの実務
【フェーズ4:障害対応と発展】
第9回 ── 障害対応:切り分け・復旧・再発防止の実践 ★シリーズのクライマックス
第10回 ── 本番への道:マネージドK8sと、その先の展望第4回で、応用編のTaskBoardリソースを一度すべて削除します(kindクラスタは残します)。そして同じTaskBoardの要件を「白紙から」提示し、設計書に基づいて再構築します。応用編で手を動かして理解した部品を、今度は「設計の文脈で組み合わせる」体験をしてください。
第1回〜第3回は設計フェーズです。kubectlでリソースを作成する作業はありません。その代わり、構成図を描き、設計書を書く作業が中心になります。応用編で構築したTaskBoardは、設計フェーズの「参照」として活用します。
では、設計の最上流——構成図から始めましょう。
1.2 VMの構成図とK8sの構成図
1.2.1 VMの世界での構成図 — vSphere環境を例に
VMwareの世界で「構成図を描いてください」と言われたら、おそらく次のような情報を1枚の図にまとめるでしょう。
- 物理ホスト(ESXiサーバー)の台数と配置
- vCenterの管理構造(データセンター → クラスタ → リソースプール → フォルダ)
- 各VM(Webサーバー、APサーバー、DBサーバー)の配置先ホスト
- 仮想ネットワーク(vSwitch、ポートグループ、VLAN)
- データストア(共有ストレージ、ローカルストレージ)
- 外部ネットワークとの接続点(ファイアウォール、ロードバランサー)
多くの場合、この構成図は1枚ではなく複数枚に分かれます。「全体の物理構成」「ネットワーク構成」「VM配置」「ストレージ構成」など、目的別に図を描き分けるのが一般的です。上司やネットワークチームに見せる図と、ストレージチームに見せる図は粒度が異なります。
K8sの構成図でも、この考え方はまったく同じです。
1.2.2 K8sの構成図に必要な要素
K8sの構成図では、VMの構成図で描いていた要素が別の姿で登場します。物理ホストの代わりにNode、VMの代わりにPod、VLANの代わりにNamespaceとNetworkPolicy、データストアの代わりにPersistentVolume——概念は異なりますが、「何がどこで動き、どうつながっているかを可視化する」という目的は同じです。
K8sの構成図で描くべき要素を整理します。
- クラスタ構成: Node(Control Plane / Worker)の台数と役割
- Namespace構造: 環境分離の単位(app、db、monitoring等)
- ワークロード: Deployment、StatefulSet、DaemonSet、Job、CronJob
- Service / ネットワーク: ClusterIP、Headless Service、Gateway API
- 通信経路: 外部 → Gateway → Service → Pod、Pod間通信(クロスNamespace含む)
- 通信制御: NetworkPolicyによる許可/遮断
- 永続化: PVC / PV の接続関係
- セキュリティ: RBAC、SecurityContext、Pod Security Standards
- 基盤コンポーネント: CNI(Calico)、Metrics Server、Gateway APIコントローラー
1.2.3 VMの構成図とK8sの構成図の対応関係
VMの構成図で描き慣れた要素が、K8sの構成図ではどう対応するかを整理します。
| VMの構成図で描くもの | K8sの構成図で描くもの | 補足 |
|---|---|---|
| ESXiホスト | Node(Control Plane / Worker) | kindではDockerコンテナがNodeに相当 |
| VM | Pod | K8sの最小デプロイ単位 |
| vCenterクラスタ | Kubernetesクラスタ | 管理の最上位単位 |
| リソースプール / フォルダ | Namespace | リソース分離と管理の境界 |
| vSwitch / ポートグループ / VLAN | Namespace + NetworkPolicy | Namespaceが論理分離、NetworkPolicyが通信制御 |
| ファイアウォールルール | NetworkPolicy | Pod間通信のIngress/Egressルール |
| ロードバランサー(F5 / NSX LB) | Gateway API + Service | 外部→内部のL7ルーティング |
| データストア(VMFS / NFS) | PersistentVolume / PVC | Podに永続ストレージを提供 |
| VMテンプレート | Deployment / StatefulSetのマニフェスト | 宣言的にリソースの「あるべき姿」を定義 |
| vSphere権限モデル | RBAC(Role / RoleBinding) | 「誰が何をできるか」の制御 |
左の列を描いたことがある方は、右の列も描けます。技術は違いますが、構成図の構造と考え方は共通です。
1.3 構成図の3つの階層
VMの構成図が「全体物理構成」「ネットワーク構成」「VM配置」のように目的別に分かれるのと同じく、K8sの構成図も階層別に描き分けます。本シリーズでは3つの階層(Level)を定義します。
1.3.1 Level 1 — クラスタ全体図
Level 1は最も高い抽象度の図です。クラスタを1つの箱として捉え、その中にあるNamespace間の関係、外部からのアクセス経路、クラスタ基盤コンポーネントを描きます。
VMの世界で言えば「データセンター全体図」に相当します。ESXiホストの台数、クラスタ構成、外部ネットワーク接続を俯瞰する図です。
Level 1に含める情報:
- クラスタのNode構成(Control Plane × 1 + Worker × 3)
- Namespaceの一覧と役割
- Namespace間の通信関係(どのNamespaceからどのNamespaceへ通信があるか)
- 外部アクセスの入口(Gateway API)とそのルーティング先
- クラスタ基盤コンポーネント(CNI、Metrics Server、Gateway APIコントローラー)
Level 1に含めない情報:
- 個別Podのリソース値(requests / limits)
- SecurityContextの詳細パラメータ
- Probeの設定値
1.3.2 Level 2 — Namespace単位図
Level 2はNamespaceの中に入り込み、そこで動いているリソースの関係を描きます。Deployment、StatefulSet、Service、HPA、NetworkPolicyなどが対象です。
VMの世界で言えば「特定のリソースプール / フォルダ内のVM構成図」です。そのフォルダにどのVMがいて、どのポートグループに接続し、どのデータストアを使っているかを示す図です。
Level 2に含める情報:
- ワークロードリソース(Deployment / StatefulSet / DaemonSet / Job / CronJob)
- Service(ClusterIP / Headless)とポート番号
- HPA(スケーリング対象とレプリカ数の範囲)
- PVC / Secret / ConfigMap
- NetworkPolicy(許可される通信の方向と相手)
- RBAC(ServiceAccountとRole)
- ResourceQuota / LimitRange
Level 2に含めない情報:
- コンテナ内部の構成(ボリュームマウントの詳細、Probeの設定値)
- SecurityContextの個別パラメータ
1.3.3 Level 3 — Pod内部図
Level 3はPodの中に入り込み、コンテナの構成を描きます。コンテナイメージ、ポート番号、ボリュームマウント、Probe設定、SecurityContextが対象です。
VMの世界で言えば「VM1台の内部構成図」です。OS、ミドルウェア、ディスク構成、ネットワークインターフェース、監視エージェントの設定を1枚にまとめた図です。
Level 3に含める情報:
- コンテナイメージとバージョン
- 公開ポート番号
- ボリュームマウント(マウントパス、ボリューム種類)
- Probe設定(startup / liveness / readiness のエンドポイントとパラメータ)
- SecurityContext(実行ユーザー、権限設定)
- resources(requests / limits)
- 環境変数(Secret / ConfigMap参照を含む)
1.3.4 3階層を使い分ける場面
| 階層 | VMの比喩 | 主な読者・利用場面 |
|---|---|---|
| Level 1 クラスタ全体図 | データセンター全体図 | 上司・経営層への説明、プロジェクト概要の共有、セキュリティ監査 |
| Level 2 Namespace単位図 | リソースプール内のVM配置図 | 開発チーム・運用チームとの設計レビュー、変更管理 |
| Level 3 Pod内部図 | VM1台の内部構成図 | トラブルシュート、詳細設計レビュー、Probe/resources調整 |
すべての情報を1枚に詰め込む必要はありません。構成図の読み手が「何を知りたいか」に合わせて、適切な階層を選んでください。上司に見せるならLevel 1、開発チームと設計レビューするならLevel 2、Probeのパラメータを調整するならLevel 3です。
1.4 構成図に「何を載せ、何を載せないか」
1.4.1 構成図に載せるべき情報
構成図の目的は「システムの構造と関係を一目で把握できること」です。以下の情報は構成図に載せるべきです。
- リソース名: Deployment名、Service名、StatefulSet名など。「このリソースは何か」を特定できる名前
- ポート番号: Serviceのport / targetPort、コンテナのcontainerPort。通信経路の追跡に不可欠
- 通信経路と方向: 矢印で「誰が誰に通信するか」を示す。クロスNamespace通信は特に明示する
- 永続化ポイント: PVCの接続関係。「データがどこに保存されるか」は障害対応で最も重要な情報の1つ
- レプリカ数: 可用性設計の基本情報。HPAがある場合はmin〜maxの範囲
- 通信制御: NetworkPolicyによる許可/遮断。「何が通って何が通らないか」を視覚的に区別する
1.4.2 構成図に載せない方がよい情報
構成図に情報を詰め込みすぎると、かえって読みにくくなります。以下の情報は設計書に記載し、構成図からは省略するのが適切です。
- 設計根拠: 「なぜStatefulSetを選んだか」「なぜrequestsを200mにしたか」は基本設計書・詳細設計書の管轄(第2回・第3回で扱います)
- パラメータの詳細値: Probeの
initialDelaySecondsやperiodSeconds、resources.limits.memoryの具体値は詳細設計書の管轄 - マニフェストのYAML: 構成図はYAMLの代替ではない。図と文書は役割が異なる
- 手順: 「どの順番で適用するか」は構築手順書の管轄(第5回で扱います)
1.4.3 読者(利害関係者)によって粒度を変える
構成図は「誰に見せるか」で粒度を変えるべきです。VMの構成図でも同じことをしていたはずです。経営層にはVLAN IDやポートグループ名を見せず、ネットワークチームにはVM名の詳細は省略する。K8sの構成図でも同じ判断が必要です。
| 読者 | 適切な階層 | 重視する情報 | 省略してよい情報 |
|---|---|---|---|
| 上司・経営層 | Level 1 | 全体構成、外部アクセス経路、セキュリティ境界 | ポート番号、リソース値、Probe設定 |
| セキュリティチーム | Level 1 + Level 2(NetworkPolicy部分) | Namespace間通信、NetworkPolicy、RBAC | HPA、Probe、resources詳細 |
| 開発チーム | Level 2 | ワークロード構成、Service名、ポート番号 | Node配置、基盤コンポーネント詳細 |
| 運用チーム | Level 2 + Level 3 | Probe設定、resources、HPA、PVC | アプリケーション内部のビジネスロジック |
1.5 TaskBoardの構成図を描く
ここからは、応用編で構築したTaskBoardの構成図を実際に描いていきます。まずは、現在のTaskBoardの状態を棚卸しするところから始めましょう。
応用編で構築したTaskBoardがクラスタ上に残っている場合は、以下のコマンドでリソースの一覧を確認できます。構成図を描く際の情報源として活用してください。
[Execution User: developer]
# 全Namespaceのリソース一覧
kubectl get all --all-namespaces
# Namespace別の詳細確認
kubectl get all -n app
kubectl get all -n db
kubectl get all -n monitoring
# NetworkPolicy一覧
kubectl get networkpolicy -n app
kubectl get networkpolicy -n db
# HPA一覧
kubectl get hpa -n app
# PVC一覧
kubectl get pvc -n db
# Secret一覧
kubectl get secret -n db「応用編で作ったリソースを棚卸しして構成図に起こす」——このプロセス自体が設計作業の第一歩です。既存システムの構成図を描くには、まず「何があるか」を正確に把握する必要があります。
構成図はMermaidダイアグラムで記述します。以下の記号規約を統一的に使用します。
| リソース種別 | Mermaid記法 | 図での表現 |
|---|---|---|
| Deployment | [リソース名] | 角括弧(長方形) |
| StatefulSet | [[リソース名]] | 二重角括弧(二重枠長方形) |
| DaemonSet | [/リソース名/] | 平行四辺形 |
| Job / CronJob | ([リソース名]) | 角丸長方形 |
| Service | (リソース名) | 丸括弧(楕円風) |
| PVC / Secret | [(リソース名)] | 円筒形 |
| Gateway / HTTPRoute | {{リソース名}} | 六角形 |
通信経路は実線矢印(-->)で許可された通信を、破線矢印(-.->)でNetworkPolicyにより遮断される通信方向を表現します。
1.5.1 Level 1 — TaskBoardクラスタ全体図
まず、最も高い視点からTaskBoardの全体像を描きます。
graph TD
subgraph cluster["kindクラスタ(CP 1 + Worker 3)"]
subgraph infra["基盤コンポーネント"]
calico["Calico CNI"]
metrics["Metrics Server"]
egw["Envoy Gateway コントローラー"]
end
subgraph ns-app["app Namespace"]
app-nginx["Nginx\n(Deployment)"]
app-api["TaskBoard API\n(Deployment)"]
end
subgraph ns-db["db Namespace"]
db-mysql["MySQL\n(StatefulSet)"]
end
subgraph ns-mon["monitoring Namespace"]
mon-ds["ログ収集\n(DaemonSet)"]
end
gw{{"Gateway API\n(port: 80)"}}
end
client["外部クライアント"] --> gw
gw -- "/ → Nginx" --> app-nginx
gw -- "/api → API" --> app-api
app-api -- "TCP 3306" --> db-mysql
app-nginx -.- db-mysql
style cluster fill:#f0f4ff,stroke:#4a6fa5
style ns-app fill:#e8f5e9,stroke:#2e7d32
style ns-db fill:#fff3e0,stroke:#e65100
style ns-mon fill:#f3e5f5,stroke:#6a1b9a
style infra fill:#eceff1,stroke:#546e7aこの図が示していること:
TaskBoardはkindクラスタ(Control Plane 1台 + Worker 3台)上で稼働しています。アプリケーション層は3つのNamespace(app、db、monitoring)に分離されています。外部からのアクセスはGateway API(port 80)を経由し、パスベースで振り分けられます。/へのリクエストはNginxへ、/apiへのリクエストはTaskBoard APIへルーティングされます。TaskBoard APIからMySQLへはTCP 3306で通信します。NginxからMySQLへの直接通信はNetworkPolicyで遮断されています(破線)。基盤コンポーネントとして、Calico CNI、Metrics Server、Envoy Gatewayコントローラーが稼働しています。
1.5.2 Level 2 — app Namespace図
app Namespaceの中に入り、リソースの関係を描きます。
graph TD
subgraph ns-app["app Namespace(ResourceQuota / LimitRange 適用済み)"]
subgraph rbac-app["RBAC"]
sa-dev["SA: developer\n(参照権限)"]
sa-ops["SA: operator\n(管理権限)"]
end
subgraph workloads["ワークロード"]
nginx["Nginx\n(Deployment)\nreplicas: 2\nimage: nginx:1.27\ncontainerPort: 8080"]
api["TaskBoard API\n(Deployment)\nreplicas: 2\nimage: taskboard-api:3.0.0\ncontainerPort: 8080"]
end
subgraph scaling["スケーリング"]
hpa-nginx["nginx-hpa\n(HPA)\nCPU 70%\nmin:2 / max:6"]
hpa-api["taskboard-api-hpa\n(HPA)\nCPU 70%\nmin:2 / max:4"]
end
subgraph services["Service"]
svc-nginx("nginx\n(ClusterIP)\nport:80 → target:8080")
svc-api("taskboard-api\n(ClusterIP)\nport:8080 → target:8080")
end
subgraph netpol["NetworkPolicy"]
np-deny["default-deny\n(Ingress/Egress)"]
np-nginx["nginx-policy\n許可: Gateway→Nginx"]
np-api["api-policy\n許可: Gateway→API\n許可: API→MySQL(db)"]
end
gw{{"taskboard-gateway\n(Gateway)\nport: 80"}}
route{{"taskboard-route\n(HTTPRoute)"}}
end
gw --> route
route -- "/ " --> svc-nginx
route -- "/api" --> svc-api
svc-nginx --> nginx
svc-api --> api
hpa-nginx -. "スケール対象" .-> nginx
hpa-api -. "スケール対象" .-> api
api -- "TCP 3306\n(クロスNamespace)" --> db-mysql["MySQL\n(db Namespace)"]
style ns-app fill:#e8f5e9,stroke:#2e7d32
style workloads fill:#c8e6c9,stroke:#388e3c
style services fill:#dcedc8,stroke:#689f38
style scaling fill:#f1f8e9,stroke:#827717
style netpol fill:#ffecb3,stroke:#f57f17
style rbac-app fill:#e0f2f1,stroke:#00695c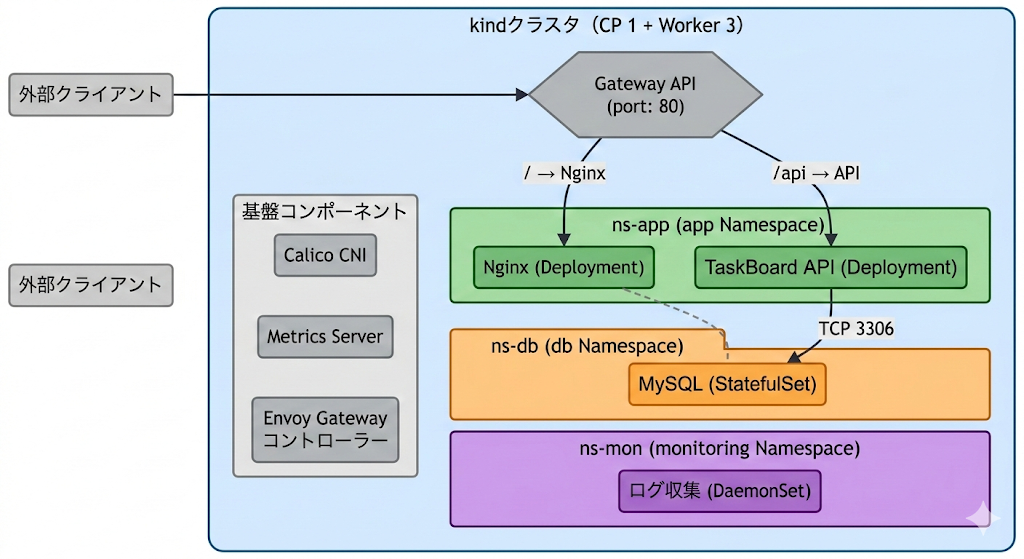
この図が示していること:
app Namespaceには2つのDeploymentがあります。Nginx(replicas: 2)とTaskBoard API(replicas: 2)です。どちらもcontainerPort 8080でリッスンしています(Nginxは応用第7回の非root化に伴い80→8080に変更済み)。それぞれにClusterIP Serviceが対応しており、Nginx Serviceはport 80でリクエストを受けてtargetPort 8080に転送、TaskBoard API Serviceはport 8080でリクエストを受けてtargetPort 8080に転送します。
Gateway API(taskboard-gateway、port 80)とHTTPRoute(taskboard-route)が外部アクセスの入口です。HPAが各Deploymentのスケーリングを制御し、NginxはCPU使用率70%の閾値でmin 2〜max 6、TaskBoard APIはmin 2〜max 4の範囲でスケールします。
NetworkPolicyはデフォルト拒否(Ingress/Egress)に設定されており、明示的に許可されたGateway→Nginx、Gateway→API、API→MySQL(db Namespace)の通信のみ通過します。RBAC用のServiceAccount(developer / operator)でNamespace内の操作権限が分離されています。ResourceQuotaとLimitRangeで、Namespace全体のリソース消費量に上限が設定されています。
1.5.3 Level 2 — db Namespace図
graph TD
subgraph ns-db["db Namespace(ResourceQuota / LimitRange 適用済み)"]
subgraph rbac-db["RBAC"]
sa-dev-db["SA: developer\n(参照権限)"]
sa-ops-db["SA: operator\n(管理権限)"]
end
subgraph workloads-db["ワークロード"]
mysql[["MySQL\n(StatefulSet)\nreplicas: 1\nimage: mysql:8.0\ncontainerPort: 3306"]]
job(["db-init-job\n(Job)\n状態: Completed"])
cronjob(["db-backup\n(CronJob)\nスケジュール実行"])
end
subgraph storage-db["ストレージ / 機密情報"]
pvc[("mysql-data\n(PVC)")]
secret[("mysql-secret\n(Secret)\nROOT_PASSWORD\nDATABASE\nUSER / PASSWORD")]
end
subgraph svc-db["Service"]
svc-mysql("mysql-headless\n(Headless Service)\nport:3306\nclusterIP: None")
end
subgraph netpol-db["NetworkPolicy"]
np-deny-db["default-deny\n(Ingress/Egress)"]
np-mysql["mysql-policy\n許可: API(app)→MySQL\n許可: CronJob(db)→MySQL"]
end
end
mysql --> pvc
mysql -. "環境変数参照" .-> secret
job -. "環境変数参照" .-> secret
cronjob -. "環境変数参照" .-> secret
svc-mysql --> mysql
api-ext["TaskBoard API\n(app Namespace)"] -- "TCP 3306" --> svc-mysql
cronjob -- "TCP 3306\nmysqldump" --> mysql
style ns-db fill:#fff3e0,stroke:#e65100
style workloads-db fill:#ffe0b2,stroke:#ef6c00
style storage-db fill:#ffecb3,stroke:#ff8f00
style svc-db fill:#fff8e1,stroke:#f9a825
style netpol-db fill:#ffecb3,stroke:#f57f17
style rbac-db fill:#e0f2f1,stroke:#00695c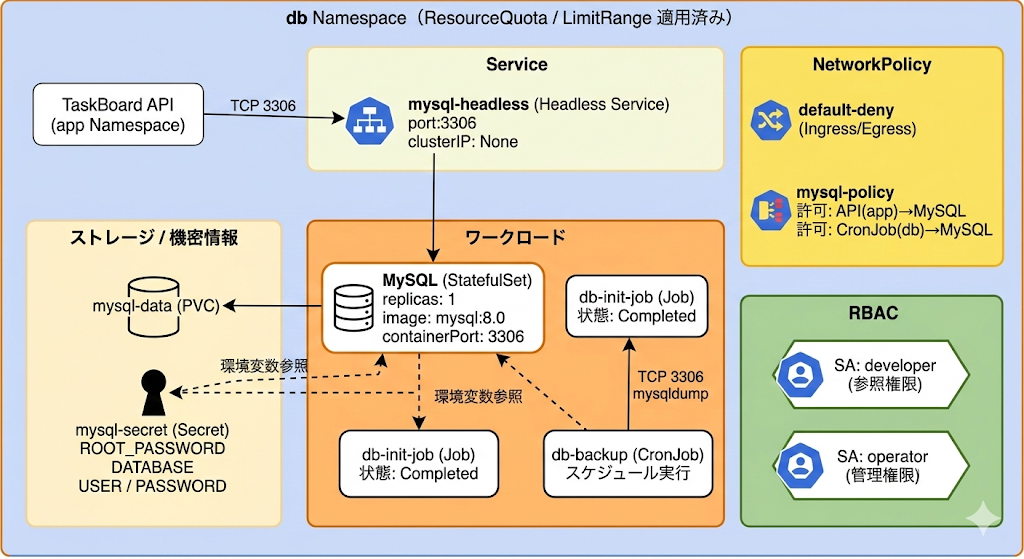
この図が示していること:
db NamespaceにはMySQL StatefulSet(replicas: 1)がHeadless Service(mysql-headless、clusterIP: None、port 3306)とともに配置されています。PVC(mysql-data)でデータを永続化し、Secret(mysql-secret)でMySQL認証情報(ROOT_PASSWORD、DATABASE、USER、PASSWORD)を管理しています。
DB初期化Job(db-init-job)はスキーマ作成と初期データ投入を完了しており、状態はCompletedです。DBバックアップCronJob(db-backup)がmysqldumpで定期的にバックアップを実行しています。
NetworkPolicyはデフォルト拒否に設定されています。許可されている通信は、app NamespaceのTaskBoard APIからMySQL(TCP 3306)へのアクセスと、同一Namespace内のバックアップCronJobからMySQLへのアクセスです。応用第6回で学んだとおり、CronJobのPodはバックアップ実行時にのみ生成されるため、NetworkPolicyで明示的に許可しておく必要があります。
1.5.4 Level 2 — monitoring Namespace図
graph TD
subgraph ns-mon["monitoring Namespace(ResourceQuota / LimitRange 適用済み)"]
subgraph rbac-mon["RBAC"]
sa-dev-mon["SA: developer\n(参照権限)"]
sa-ops-mon["SA: operator\n(管理権限)"]
end
subgraph workloads-mon["ワークロード"]
ds[/"log-collector\n(DaemonSet)\nimage: busybox\n全Worker Nodeに1つずつ配置"/]
end
end
subgraph nodes["Worker Nodes"]
w1["Worker 1\n└ log-collector Pod"]
w2["Worker 2\n└ log-collector Pod"]
w3["Worker 3\n└ log-collector Pod"]
end
ds -. "各Nodeに自動配置" .-> w1
ds -. "各Nodeに自動配置" .-> w2
ds -. "各Nodeに自動配置" .-> w3
style ns-mon fill:#f3e5f5,stroke:#6a1b9a
style workloads-mon fill:#e1bee7,stroke:#8e24aa
style rbac-mon fill:#e0f2f1,stroke:#00695c
style nodes fill:#eceff1,stroke:#546e7a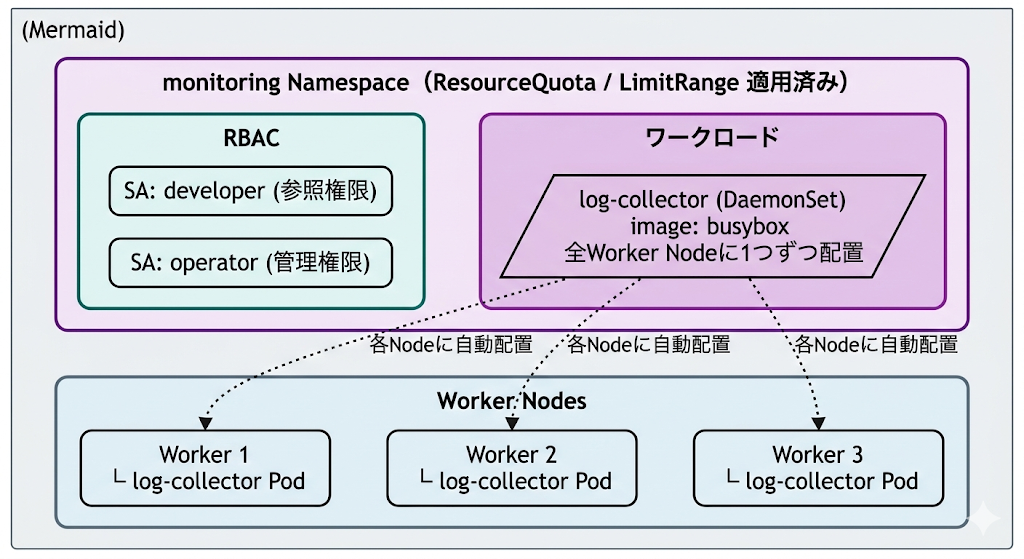
この図が示していること:
monitoring Namespaceにはログ収集DaemonSet(log-collector)が配置されています。DaemonSetの特性により、Worker Node 3台それぞれに1つずつlog-collector Podが自動配置されます。Control Planeにはデフォルトで配置されません(Taintのため)。
本番ではFluentdやFluent Bitを使用しますが、応用編ではbusyboxによる簡易実装です。ResourceQuotaとLimitRangeが適用され、RBACでServiceAccount(developer / operator)が設定されています。
monitoring Namespaceは他のNamespaceとのPod間通信を持たないため、NetworkPolicyの図は省略しています(応用編ではmonitoringにNetworkPolicyを適用していません)。
1.5.5 Level 3 — TaskBoard API Pod内部図
最も詳細な階層として、TaskBoard API PodのLevel 3図を描きます。Payara Microは起動時間が15〜20秒と長く、Probe設計が複雑になるため、Level 3で詳細を可視化する価値が高いコンポーネントです。
graph TD
subgraph pod["TaskBoard API Pod"]
subgraph container["コンテナ: taskboard-api"]
image["イメージ: taskboard-api:3.0.0\n(Payara Micro 7.2026.1)"]
port["containerPort: 8080"]
user["実行ユーザー: payara (uid=1000)\nrunAsNonRoot: true"]
noesc["allowPrivilegeEscalation: false"]
caps["capabilities:\n drop: [ALL]"]
ro["readOnlyRootFilesystem: true"]
seccomp["seccompProfile:\n type: RuntimeDefault"]
end
subgraph probes["Probe設定"]
startup["startupProbe\nHTTP GET /health/started\nport: 8080\nfailureThreshold: 30\nperiodSeconds: 2"]
liveness["livenessProbe\nHTTP GET /health/live\nport: 8080\nperiodSeconds: 10\nfailureThreshold: 3"]
readiness["readinessProbe\nHTTP GET /health/ready\nport: 8080\nperiodSeconds: 5\nfailureThreshold: 3"]
end
subgraph resources["resources"]
req["requests:\n cpu: 200m\n memory: 384Mi"]
lim["limits:\n cpu: 500m\n memory: 512Mi"]
end
subgraph env["環境変数"]
env-db-host["DB_HOST\n← mysql-0.mysql-headless.\ndb.svc.cluster.local"]
env-db-name["DB_NAME\n← value: taskboard"]
env-db-user["DB_USER\n← Secret: mysql-secret"]
env-db-pass["DB_PASSWORD\n← Secret: mysql-secret"]
end
end
startup -. "起動完了まで最大60秒待機\n(30回 × 2秒)" .-> container
liveness -. "起動後、定期的に生存確認" .-> container
readiness -. "トラフィック受入可否を判定\n(DB接続確認含む)" .-> container
style pod fill:#e3f2fd,stroke:#1565c0
style container fill:#bbdefb,stroke:#1976d2
style probes fill:#c8e6c9,stroke:#388e3c
style resources fill:#fff9c4,stroke:#f9a825
style env fill:#ffecb3,stroke:#ff8f00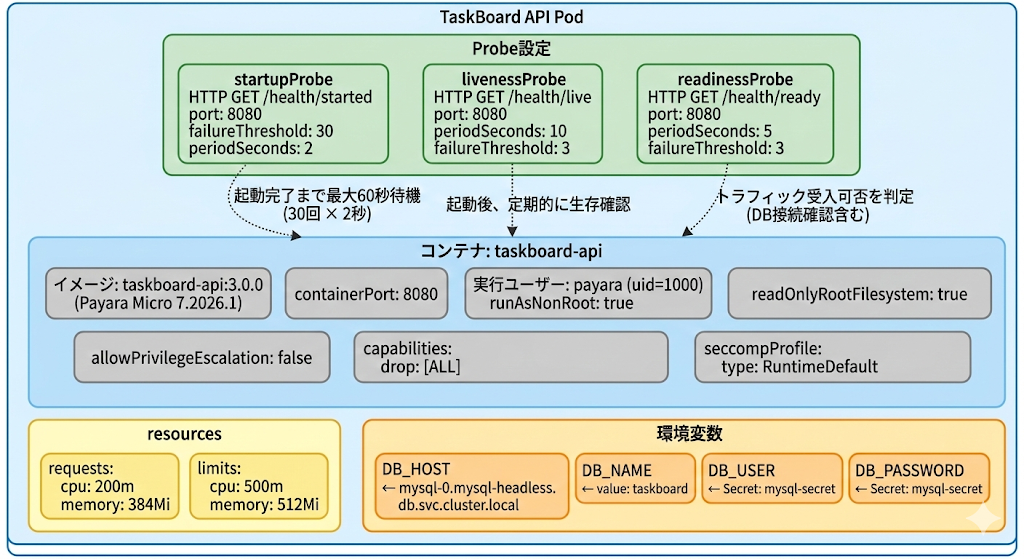
この図が示していること:
TaskBoard API PodはPayara Micro 7.2026.1ベースのコンテナを1つ含み、8080番ポートでリッスンします。実行ユーザーはpayara(uid=1000)で、非rootです。SecurityContextで権限昇格を禁止(allowPrivilegeEscalation: false)し、capabilitiesをすべて剥奪し、ルートファイルシステムを読み取り専用に設定し、seccompProfile(RuntimeDefault)でシステムコールを制限しています。
Probeは3種類すべて設定されています。startupProbeはMicroProfile Healthの/health/startedエンドポイントを使い、起動完了まで最大60秒(failureThreshold 30 × periodSeconds 2)待機します。Payara Microの起動時間(15〜20秒)を考慮した設定です。livenessProbeは/health/liveで生存確認、readinessProbeは/health/readyでトラフィック受入可否を判定します(カスタムHealthCheckでDB接続確認を含む)。
resourcesはrequests 200m CPU / 384Mi メモリ、limits 500m CPU / 512Mi メモリです。JVMヒープとMetaspaceの消費を考慮した値です。環境変数でMySQL接続先を指定しており、DB_HOSTはHeadless Service経由のPod直接指定(mysql-0.mysql-headless.db.svc.cluster.local)、DB_NAMEはプレーンな文字列値で設定しています。機密情報(ユーザー名、パスワード)はSecretから参照しています。
1.5.6 完成した構成図の読み合わせ
5枚の構成図が完成しました。最後に、この構成図をチームや上司に説明する場面を想定して、読み合わせをしてみましょう。
Level 1(クラスタ全体図)を使った説明の例:
「TaskBoardはkindクラスタ上で動いています。クラスタはControl Plane 1台とWorker 3台で構成されています。アプリケーションは3つのNamespaceに分離しています。appにはフロントエンドとAPIサーバー、dbにはMySQLデータベース、monitoringにはログ収集の仕組みがあります。外部からのアクセスはGateway APIの80番ポートに集約し、パスでフロントエンドとAPIに振り分けています。APIからDBへの通信はありますが、フロントエンドからDBへの直接通信はNetworkPolicyで遮断しています。」
Level 2(app Namespace図)を使った開発チームとのレビュー例:
「app Namespaceには2つのDeploymentがあります。NginxとTaskBoard APIです。どちらもreplicas 2で冗長化し、HPAで自動スケーリングが効いています。NginxはCPU 70%超でmax 6まで、APIはmax 4までスケールします。ServiceはどちらもClusterIPで、Gateway API経由でのみ外部アクセスを受けます。NetworkPolicyでデフォルト拒否にしており、許可している通信はGatewayからの流入と、APIからdb NamespaceのMySQLへの通信だけです。」
Level 3(Pod内部図)を使ったトラブルシュート場面の例:
「TaskBoard APIのPodが起動に失敗している場合、まずstartupProbeを確認してください。Payara Microの起動には15〜20秒かかるため、startupProbeで最大60秒の猶予を設けています。startupProbeが通過しないとlivenessProbeが開始されず、Podは永遠にNotReadyのままです。readinessProbeはDB接続確認を含んでいるので、MySQL側に問題がある場合もreadinessProbeが失敗し、Serviceのエンドポイントから外れます。」
構成図は描いて終わりではありません。チームに見せて説明し、質問を受けて修正し、システムの変更に合わせて更新する——その繰り返しの中で、構成図は「生きたドキュメント」になります。
1.6 この回のまとめ
1.6.1 成果物の確認 — TaskBoardの構成図
本回の成果物は、TaskBoardのK8s構成図(3階層・全5枚)です。
| 図 | 階層 | 概要 |
|---|---|---|
| クラスタ全体図 | Level 1 | Namespace構成、外部アクセス経路、基盤コンポーネント |
| app Namespace図 | Level 2 | Nginx / API のDeployment、Service、HPA、NetworkPolicy、RBAC |
| db Namespace図 | Level 2 | MySQL StatefulSet、Headless Service、PVC、Job、CronJob、Secret |
| monitoring Namespace図 | Level 2 | ログ収集DaemonSet、Worker Node配置 |
| TaskBoard API Pod内部図 | Level 3 | コンテナ構成、Probe設定、SecurityContext、resources、環境変数 |
この構成図は次回(第2回・基本設計)の入力情報になります。構成図で「何があるか」を可視化した上で、基本設計書で「なぜそれを選んだか」の判断根拠を文書化します。
フェーズの進捗:
【フェーズ1:設計】
✅ 第1回 ── 構成図(完了)
☐ 第2回 ── 基本設計
☐ 第3回 ── 詳細設計
【フェーズ2:構築】 ☐ 第4回〜第6回
【フェーズ3:運用】 ☐ 第7回〜第8回
【フェーズ4:障害対応と発展】 ☐ 第9回〜第10回1.6.2 構成図を描くときのチェックリスト
今回の内容を、実務で構成図を描くときのチェックリストとしてまとめます。
| チェック項目 | 確認内容 |
|---|---|
| 階層は適切か | 読者(利害関係者)に合わせたLevel(L1/L2/L3)を選んでいるか |
| リソース名は正確か | 実際のマニフェストのmetadata.nameと一致しているか |
| ポート番号は記載されているか | Service port、targetPort、containerPortの3つが追跡可能か |
| 通信経路は網羅されているか | 外部→Gateway→Service→Pod、クロスNamespace通信がすべて描かれているか |
| 通信制御は明示されているか | NetworkPolicyによる許可/遮断が視覚的に区別されているか |
| 永続化ポイントは示されているか | PVCの接続先が明確か。障害時に「データがどこにあるか」を即座に確認できるか |
| 情報の過不足はないか | 構成図に載せるべき情報と、設計書に委ねるべき情報を区別しているか |
| 最新の状態と一致しているか | kubectl getの結果と図の内容に矛盾がないか |
1.6.3 次回予告 — 構成図から基本設計書へ
構成図で「何があるか」を可視化しました。次回(第2回)では、この構成図をもとに「基本設計書」を書きます。
基本設計書では、構成図に描かれた各コンポーネントについて「なぜそのリソースを選んだか」「なぜそのNamespace構成にしたか」といった設計判断の根拠を文書化します。応用第3回で学んだStatefulSetの知識は「データベースにStatefulSetを選定した根拠」として、応用第6回で学んだNetworkPolicyの知識は「通信制御ポリシーの設計」として、設計書に落とし込まれます。
応用編で「この武器はこう使う」と学んだ知識が、実践編では「この武器をなぜ選んだか」の判断根拠に変わる。その転換を体験するのが次回です。
AIコラム — Mermaid構成図のドラフト生成
構成図のドラフトを一から描くのは手間がかかります。特にMermaid記法に慣れていない段階では、構文を調べながら書く時間が馬鹿になりません。この工程はAIの得意分野です。
AIに要件を伝えて、Mermaidコードのドラフトを出力させてみましょう。たとえば次のようなプロンプトが使えます。
以下のK8sシステムの構成図をMermaid記法(graph TD)で描いてください。
- クラスタ: kindクラスタ(CP 1 + Worker 3)
- Namespace: app, db, monitoring の3つ
- app: Nginx (Deployment, replicas:2), TaskBoard API (Deployment, replicas:2),
各ServiceはClusterIP, Gateway APIで外部アクセス
- db: MySQL (StatefulSet, replicas:1), Headless Service, PVC, CronJob(バックアップ)
- monitoring: log-collector (DaemonSet, 全Worker Nodeに配置)
- 通信: 外部→Gateway→Nginx/API, API→MySQL(TCP 3306), Nginx→MySQL は遮断
- subgraphでNamespaceを囲み、色分けしてくださいAIは数秒でMermaidコードを出力してくれます。ただし、そのまま使うのは避けてください。AIが出力するドラフトには、以下のような問題がしばしば含まれます。
- ポート番号の欠落や誤り(AIは具体的なポート設定を知らないため)
- NetworkPolicyの許可/遮断の表現が不正確(破線と実線の使い分けが曖昧)
- Mermaid構文のバージョン依存問題(AIが古い構文を出力する場合がある)
- リソース名がマニフェストと不一致(AIは推測で命名するため)
AIの出力は「構成図のたたき台」として扱い、必ず自分の手で修正・補完してください。構成図の正確性を担保するのは、AIではなく設計者であるあなた自身です。特にポート番号、通信経路、NetworkPolicyの制御ルールはkubectl getの実行結果やマニフェストと突き合わせて検証する必要があります。
AIに丸投げするのではなく、「ドラフト生成→自分で修正→完成版」というワークフローを意識してください。本文で作成した5枚の構成図も、同じワークフローで効率的に仕上げることができます。
