
- 第16回スコープ・学習目標・今ここマップ
- NetworkPolicy とは — Pod 間通信のホワイトリスト制御
- NetworkPolicy の YAML 構造
- default-deny-all ベースライン — ゼロトラストの起点
- やってみよう①: default-deny-all を適用して疎通断を観察する
- ingress ルールの設計 — podSelector / namespaceSelector / ipBlock
- やってみよう②: 段階的な allow ルールで通信を許可する
- Step 1: allow-backend-from-client を作成する
- Step 2: 適用して疎通復活を確認する
- Step 3: fanclub-backend → fanclub-db がまだ遮断されていることを確認する
- Step 4: allow-db-from-backend を作成する
- Step 5: 適用して fanclub-backend → fanclub-db の疎通復活を確認する
- Step 6: NetworkPolicy 一覧を確認する
- Step 7: 許可していない通信が遮断されたままであることを確認する
- Step 8: ポリシーの重ね合わせ(許可の加算)を整理する
- 演習②まとめ
- Egress ポリシーと DNS の落とし穴
- やってみよう③: Egress 制御と DNS 許可ルール
- fanclub-api の NetworkPolicy 全体設計(4 層モデル)
- CKAD 試験頻出パターン — NetworkPolicy の速攻設計
- 現場ヒヤリハット 2 件
- ep16 完了後の模擬アプリ状態と第5部完走 + ep17 への橋渡し
- 理解度チェック・第16回まとめ・次回予告・シリーズ一覧
第16回スコープ・学習目標・今ここマップ
動作確認バージョン: K8s v1.35 / kubectl v1.35.0 / kind v0.31.0 / kindest/node:v1.35.0 / kindnetd v20251212 / Docker CE 29.4.3 / containerd 2.2.3 / AlmaLinux 10.1(kernel 6.12.0-124.55.3.el10_1)(2026-05-16 時点・k8s-ops 実機検証済・SP_vol1-pre-25 起点)
本回は Kubernetes 実践教科書 第1巻(CKAD 対応・全 19 回)の第16回です。第5部「セキュリティ基礎」の第2回(最終回・2 回中の 2 回目)として、第15回で確立した RBAC(権限境界)と SecurityContext(実行境界)の上に NetworkPolicy(通信境界)を載せます。
NetworkPolicy は Pod 間の通信を L3 / L4(IP アドレス・ポート)レベルでホワイトリスト制御する Kubernetes ネイティブのリソースで、本回ではゼロトラストネットワークの起点となる default-deny-all ベースラインを作成し、そこに ingress / egress の許可ルールを段階的に重ねていく本番ベストプラクティスを実機で習得します。
CKAD ドメイン D5「Services and Networking」(出題比率 20%)の Competency「Demonstrate basic understanding of NetworkPolicies」を本回で完全網羅し、第5部「セキュリティ基礎」を完走します。
第15回からの継承状態確認(SP_vol1-pre-25 状態):
| 項目 | 状態 | 出典 |
|---|---|---|
| kind クラスタ | kind-control-plane Ready(v1.35.0) | Lead 実機観察 |
| CNI | kindnetd v20251212(kind v0.31.0 同梱・NetworkPolicy enforce 対応) | Lead 実機観察 |
| Namespace 一覧 | default / kube-node-lease / kube-public / kube-system / local-path-storage(合計 5 個) | ep14 完了状態 |
| fanclub-backend Deployment | replicas: 2 / 3 Probe 設定済 / RollingUpdate maxSurge:1 maxUnavailable:0 | ep12 完了状態を継続 |
| fanclub-backend Service | ClusterIP(port 8080) | ep8 から継続 |
| fanclub-db StatefulSet | fanclub-db-0 Pod Running(PostgreSQL 18・port 5432) | ep9 から継続 |
| fanclub-db Service | fanclub-db / fanclub-db-headless(継続) | ep9 から継続 |
| node-logger DaemonSet | 1 Pod Running | ep11 から継続 |
| Role / RoleBinding | pod-reader / fanclub-backend-pod-reader(default ns・ep15 で作成) | ep15 完了状態 |
| NetworkPolicy | 0 件(default ns・本回で初導入) | Lead 実機観察 |
| Allocated CPU | 1550m / 2000m(77 %) | Lead 実機観察 |
今ここマップ(第1巻 19 回中の現在位置):
第1部 コンテナとDocker
第1回〜第4回 [完了]
第2部 Kubernetes基礎
第5回〜第6回 [完了]
第3部 アプリリソース
第7回〜第11回 [完了]
第4部 ワークロード戦略
第12回〜第14回 [完了]
第5部 セキュリティ基礎(第15〜16回)
第15回 RBAC + SecurityContext + Admission Controller 概念 + CRD 利用 [完了]
★ 第16回 NetworkPolicy 基礎 ← 今ここ(第5部完走)
第6部 パッケージ管理 + HTTPS公開(第17〜19回)第16回を終えると、以下を習得した状態になります。
- NetworkPolicy の役割(Pod 間通信のホワイトリスト制御)と「NetworkPolicy が 1 つ適用されると未許可通信は全拒否」というホワイトリスト方式の挙動を説明できる。NetworkPolicy が 0 個の Pod はデフォルトで全通信可能というフラットネットワークの性質と、NetworkPolicy を 1 つでも適用したときの挙動の差を区別できる
- NetworkPolicy の YAML 構造(
podSelector/policyTypes/ingress/egress/from/to/ports)を理解し、podSelector: {}で Namespace 内全 Pod を対象にする default-deny-all ベースラインを作成できる。policyTypesの指定がないと該当方向の制御が効かない落とし穴を回避できる - ingress ルールを
podSelector/namespaceSelector/ipBlockの 3 種類の許可元指定で設計し、段階的に通信を許可できる。複数 from エントリの OR 条件、podSelector と namespaceSelector の併記による AND 条件の違いを説明できる - Egress ポリシーを設計でき、Egress を default-deny にすると DNS(53/UDP・53/TCP)への通信も切れて Service 名の名前解決が失敗する落とし穴を回避できる。Egress 制御は「DNS 許可ルール」と「宛先許可ルール」の 2 点セットが必須であることを説明できる
- CKAD 試験 D5 ドメイン「Demonstrate basic understanding of NetworkPolicies」Competency に対応できる。default-deny ベースライン + 段階的 allow という本番ベストプラクティスを説明でき、試験頻出パターン(全拒否 / Pod 許可 / Namespace 許可 / DNS 修復)を即座に書き起こせる
模擬アプリ進捗(第16回):本回の演習①では curl を備えた client Pod(fanclub-api の Frontend 役をシミュレート)を作成し、default ns に default-deny-all NetworkPolicy を適用して fanclub-backend への疎通が断たれる様子を実機観察します。
演習②では allow-backend-from-client と allow-db-from-backend の 2 つの ingress 許可ルールを段階的に適用し、ホワイトリストを 1 枚ずつ重ねて通信を復活させます。演習③では client Pod の Egress を default-deny にして DNS 名前解決が壊れる落とし穴を再現し、allow-dns と allow-egress-to-backend の 2 つの egress 許可ルールで復旧させます。
設計上の注意:fanclub-api の Frontend / Gateway 層は ep18(Gateway API + Traefik + cert-manager で HTTPS 公開)で実装するため、本回時点ではまだ存在しません。curriculum で示している 4 層モデル(Gateway → Frontend → Backend → DB)のうち、本回で実機実装するのは Backend / DB の 2 層 + 「Frontend 役を担う client Pod」です。
Gateway / Frontend を含む完成形の 4 層 NetworkPolicy 設計図は H2「fanclub-api の NetworkPolicy 全体設計」で「ep18 完了後に完成する設計図」として提示します。
第16回完了後の模擬アプリ状態:演習①〜③で作成した NetworkPolicy 群(default-deny-all / allow-backend-from-client / allow-db-from-backend / allow-dns / allow-egress-to-backend)は default ns に残ります。
演習用の client Pod も次回以降の通信確認用に残し、fanclub-backend / fanclub-db / node-logger は ep15 完了状態のまま影響を受けません。最終状態は「NetworkPolicy のホワイトリストが適用済で、fanclub-api の必要な通信経路のみが疎通する」状態になり、ep17(Helm v4 基礎 + fanclub-api Helm Chart 作成)にクリーンな状態で引き継ぎます。
NetworkPolicy とは — Pod 間通信のホワイトリスト制御
個別の YAML や演習に入る前に、本回の中心テーマである NetworkPolicy の役割と、それを支える「ホワイトリスト方式」という考え方を最初に押さえます。NetworkPolicy は CKAD 試験で誤解の多いリソースで、「ルールを書く = 通信を制限する」という直感が逆向きに作用する場面があるため、最初の概念整理が得点と本番運用の両方を分けるポイントになります。
デフォルトの Kubernetes ネットワークはフラット
Kubernetes のネットワークモデルでは、NetworkPolicy を 1 つも適用していない状態のクラスタは「フラットネットワーク」になります。フラットネットワークとは、すべての Pod が Namespace の境界を越えて相互に通信できる状態を指します。default ns の Pod から kube-system ns の Pod へも、別 ns のまったく無関係なアプリの Pod へも、IP アドレスが分かれば直接 TCP / UDP 接続できます。
第8回で Service を扱った際、fanclub-backend Service の ClusterIP に対して別の Pod から curl が通ったのは、このフラットネットワークの性質によるものでした。
フラットネットワークは「Pod 同士が疎通する」という Kubernetes の基本動作を保証するうえで都合がよい一方、セキュリティの観点では問題があります。たとえば外部からのリクエストを受ける Frontend Pod が侵害された場合、攻撃者はそこを起点に、フラットネットワークを通じて DB Pod の 5432 番ポートへ直接接続を試みられます。
本来 Frontend は Backend 経由でしか DB に触れないはずなのに、ネットワーク経路上は Frontend → DB の直通経路が常に開いている、という状態です。この「意図しない通信経路」を塞ぐのが NetworkPolicy の役割です。
NetworkPolicy = Pod 間通信のホワイトリスト
NetworkPolicy は networking.k8s.io/v1 API グループの Kubernetes リソースで、「どの Pod が、どの Pod / Namespace / IP レンジと、どのポート・プロトコルで通信してよいか」を宣言的に定義します。NetworkPolicy が制御する範囲は L3(IP アドレス)と L4(ポート・TCP/UDP/SCTP)であり、L7(HTTP のパスやヘッダ、メソッド)の制御はできません。
HTTP メソッドや URL パス単位の制御が必要な場合は Gateway API や Service Mesh の領域になります。
NetworkPolicy の動作を理解するうえで最も重要なのが「ホワイトリスト方式」という性質です。NetworkPolicy は「許可する通信を列挙する」リソースであり、「拒否する通信を列挙する」リソースではありません。具体的な挙動は次のように整理できます。
| Pod に適用された NetworkPolicy | その Pod の通信 |
|---|---|
| 0 個(NetworkPolicy なし) | すべての通信が許可される(フラットネットワークのデフォルト) |
| 1 個以上(ある方向の policyTypes が指定されている) | その方向について、NetworkPolicy で明示的に許可された通信のみが疎通し、それ以外は全拒否される |
言い換えると、ある Pod に対して ingress を制御する NetworkPolicy が 1 つでも適用された瞬間、その Pod への ingress 通信は「許可リストに載っていないものは全拒否」という状態に切り替わります。NetworkPolicy を適用する前は全通信が許可されていたのに、適用後は許可ルールに書いた通信だけが残り、書かなかった通信は遮断される、という動作です。
この「適用したら一気にホワイトリスト方式に切り替わる」性質が、後述する default-deny-all ベースラインや、ヒヤリハット①「適用順序ミスで全断」の根本にあります。
NetworkPolicy を enforce するのは CNI プラグイン
NetworkPolicy は API リソースとしては Kubernetes 標準ですが、実際にパケットを遮断する処理(enforce)は Kubernetes 本体ではなく、クラスタにインストールされた CNI(Container Network Interface)プラグインが担います。API Server は NetworkPolicy を etcd に保存しますが、その内容に従って iptables / eBPF などでパケットフィルタリングを実装するのは CNI 側です。
このため「CNI プラグインが NetworkPolicy に対応していないと、NetworkPolicy を作成しても何も起きない(ルールが無視される)」という性質があります。
CNI プラグインごとの NetworkPolicy 対応状況を整理します。
| CNI プラグイン | NetworkPolicy 対応 | 本シリーズでの扱い |
|---|---|---|
| kindnet(kindnetd) | 対応(v20250214 以降で enforce 実装) | 第1巻 kind 環境のデフォルト・本回で使用 |
| Calico | 対応(拡張ポリシーも提供) | 第2巻 CKA の kubeadm クラスタで採用 |
| Flannel(単体) | 非対応(NetworkPolicy を無視) | 第2巻で代替候補として言及 |
| Cilium | 対応(eBPF ベース・L7 ポリシーも可能) | 第3巻 CKS で mTLS と併せて採用 |
本回で使う kind v0.31.0 に同梱の CNI は kindnet(kindnetd v20251212)です。kindnet は以前のバージョンでは NetworkPolicy を enforce しませんでしたが、kindnetd v20250214 以降で NetworkPolicy の enforce が実装され、kind v0.31.0 同梱の v20251212 では default-deny / podSelector / namespaceSelector / ipBlock / ports / Egress を含む基本機能が動作します。
Lead の事前実機観察でも、検証用 Namespace で default-deny-all を適用すると Pod 間通信が実際に遮断され、allow ルールを足すと疎通が復活することが確認済です。このため、本回の演習①〜③は kind 環境の実機で完全に成立します。
CKAD 試験では「NetworkPolicy が効かないのはなぜか」という設問で「CNI が NetworkPolicy 非対応」が選択肢に入ることがあります。NetworkPolicy は Kubernetes 標準 API でありながら、enforce は CNI 依存である、という二段構えの構造を覚えておくと、トラブルシューティング系の設問に対応できます。
NetworkPolicy はゼロトラストネットワークの K8s ネイティブ実装
NetworkPolicy のホワイトリスト方式は、セキュリティ分野でいう「ゼロトラストネットワーク」の考え方を Kubernetes リソースとして実装したものです。ゼロトラストネットワークとは「ネットワーク内部だからといって無条件に信頼しない。すべての通信を、それが必要であると明示的に証明されたものだけに限定する」という設計原則です。従来の「境界防御(ファイアウォールの内側は信頼する)」モデルとは対照的に、クラスタ内部の Pod 同士の通信も「必要なものだけ許可、それ以外は拒否」で設計します。
第15回の RBAC が「API Server に対する操作の権限境界」をゼロトラストで設計する機構だったのに対し、本回の NetworkPolicy は「Pod 間のネットワーク通信の境界」をゼロトラストで設計する機構です。両者は責務が異なり、RBAC は「kubectl や SA が何を操作できるか」、NetworkPolicy は「Pod がどこと通信できるか」を制御します。
本番のセキュリティ設計では、RBAC(権限境界)・SecurityContext(実行境界)・NetworkPolicy(通信境界)の 3 つを組合せて多層防御を構成します。第5部「セキュリティ基礎」は、この 3 機構を ep15 と ep16 の 2 回で揃える構成になっています。
NetworkPolicy の YAML 構造
NetworkPolicy の概念を押さえたところで、実際の YAML 構造を整理します。NetworkPolicy の YAML は CKAD 試験でゼロから書き起こす場面が多いリソースで、フィールドの役割と階層を正確に覚えておくことが重要です。
NetworkPolicy の YAML 全体像
まず、ingress と egress の両方を持つ NetworkPolicy の YAML 全体像を示します。これは「app: fanclub-backend ラベルの Pod に対して、role: client ラベルの Pod から 8080/TCP の ingress を許可し、app: fanclub-db ラベルの Pod へ 5432/TCP の egress を許可する」という意味の例です。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: example-policy
namespace: default
spec:
podSelector:
matchLabels:
app: fanclub-backend
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
role: client
ports:
- protocol: TCP
port: 8080
egress:
- to:
- podSelector:
matchLabels:
app: fanclub-db
ports:
- protocol: TCP
port: 5432NetworkPolicy の YAML は、第15回までで扱った Deployment や Service と同様に apiVersion / kind / metadata / spec の 4 ブロックで構成されます。apiVersion は networking.k8s.io/v1 で安定版です。NetworkPolicy は Namespace スコープのリソースなので metadata.namespace を持ち、指定した Namespace 内の Pod にのみ作用します。
本回の演習はすべて default ns 内で完結します。
spec の主要フィールド早見表
| フィールド | 意味 | 注意点 |
|---|---|---|
spec.podSelector | この NetworkPolicy を適用する対象 Pod を Namespace 内のラベルで選択する | {}(空)を指定すると Namespace 内の全 Pod が対象になる |
spec.policyTypes | このポリシーが制御する方向。Ingress / Egress の配列 | 指定しなかった方向は一切制御されない。egress ルールを書いても policyTypes に Egress がないと無効 |
spec.ingress | 許可する受信通信ルールの配列。各要素は from(許可元)+ ports(許可ポート) | 空配列 [] またはフィールドなしで「ingress 全拒否」になる |
spec.egress | 許可する送信通信ルールの配列。各要素は to(許可先)+ ports(許可ポート) | 空配列 [] またはフィールドなしで「egress 全拒否」になる |
ingress[].from / egress[].to | 許可する相手の指定。podSelector / namespaceSelector / ipBlock の 3 種類 | from / to を省略すると「全送信元 / 全宛先を許可」になる |
ports | 許可するポートとプロトコル。protocol(TCP/UDP/SCTP)+ port | 省略すると「全ポートを許可」になる |
初学者がつまずきやすいのは「フィールドを省略したときの意味」です。NetworkPolicy のフィールドには「省略 = 全許可」と「空配列 = 全拒否」という、似て非なる挙動があります。次の表で整理します。
| 書き方 | 意味 |
|---|---|
ingress フィールド自体を書かない | ingress ルールが 0 個 = ingress 全拒否(policyTypes に Ingress がある場合) |
ingress: [](空配列) | 同上。ingress 全拒否 |
ingress: [{}](空オブジェクト 1 個) | from / ports なしのルール 1 個 = ingress 全許可 |
from を書かずに ports だけ書く | 全送信元から、指定ポートのみ許可 |
ports を書かずに from だけ書く | 指定した送信元から、全ポート許可 |
この「省略の意味」は CKAD 試験でも本番でも事故の温床になります。たとえば「ingress 全拒否」のつもりで ingress: [{}] と書くと、空オブジェクトが「from / ports 制限なしの許可ルール」と解釈され、意図と正反対の「全許可」になります。default-deny を書くときは ingress フィールド自体を書かないか ingress: [] にする、というのが定石です。次の H2 でこの default-deny-all を詳しく扱います。
許可元・許可先の 3 種類のセレクタ
ingress[].from と egress[].to で許可する相手を指定する方法は 3 種類あります。それぞれの使い分けを整理します。
| セレクタ | 選択対象 | 用途 |
|---|---|---|
podSelector | 同じ Namespace 内の、ラベルが一致する Pod | 「同じ ns の特定アプリの Pod からのみ許可」 |
namespaceSelector | ラベルが一致する Namespace に属する全 Pod | 「特定の ns 全体からの通信を許可」 |
ipBlock | 指定した CIDR レンジの IP アドレス | 「クラスタ外部の特定 IP レンジからの通信を許可」 |
3 種類のうち podSelector と namespaceSelector は併記すると意味が変わるため注意が必要です。次の YAML の違いを見てください。
# パターン A: from エントリを 2 つに分ける(OR 条件)
ingress:
- from:
- podSelector:
matchLabels:
role: client
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: monitoring
# → 同 ns の role=client Pod 「または」 monitoring ns の全 Pod を許可
# パターン B: 1 つの from エントリに併記(AND 条件)
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: monitoring
podSelector:
matchLabels:
role: client
# → monitoring ns に属し「かつ」role=client ラベルを持つ Pod を許可判断のポイントは「-(ハイフン)が付いているか」です。from 配列の中で、それぞれの要素が - podSelector: のようにハイフンで始まる別エントリになっていれば OR 条件(どれか 1 つにマッチすれば許可)です。1 つのハイフン配下に namespaceSelector と podSelector が両方並んでいれば AND 条件(両方にマッチした Pod のみ許可)です。
CKAD 試験では「monitoring Namespace の prometheus Pod からのみ許可」のような問題で AND 条件(パターン B)を要求されることがあるため、ハイフンの位置の違いを正確に押さえておきます。本回の演習では分かりやすさを優先して、まずは単一の podSelector または namespaceSelector を使うルールから扱います。
ipBlock の cidr と except
ipBlock は IP アドレスレンジ(CIDR 表記)で許可元・許可先を指定します。クラスタ外部のシステム(オンプレミスの DB、社内ネットワークの監視サーバー等)との通信を制御するときに使います。ipBlock は cidr(許可するレンジ)と except(その中で除外するレンジ)の 2 フィールドを持ちます。
ingress:
- from:
- ipBlock:
cidr: 192.168.1.0/24
except:
- 192.168.1.200/32
# → 192.168.1.0/24 のうち 192.168.1.200 を除いた全 IP からの通信を許可この例は「192.168.1.0/24 のレンジ全体を許可するが、その中の 192.168.1.200 だけは除外する」という意味です。本回の演習①〜③ではクラスタ内の Pod 間通信に集中するため ipBlock は使いませんが、CKAD 試験では「特定 CIDR からのみ許可」「特定 IP を除外」という設問が出るため、cidr + except の組合せは覚えておきます。
default-deny-all ベースライン — ゼロトラストの起点
NetworkPolicy の YAML 構造を理解したところで、本番のゼロトラストネットワーク設計の起点となる「default-deny-all ベースライン」を扱います。これは演習①で実際に適用する NetworkPolicy で、本回の中核となる概念です。
default-deny-all とは
default-deny-all とは、Namespace 内の全 Pod に対して「ingress / egress ともに、明示的に許可されたもの以外は全拒否」という基準線(ベースライン)を引く NetworkPolicy です。ゼロトラストネットワークの設計では、まずこの「何も通さない」状態を全 Pod に課し、そこに「この通信は必要」という許可ルールを 1 枚ずつ重ねていきます。
最初に全拒否を引いておくことで、許可ルールを書き忘れた通信は自動的に遮断され、「意図しない通信経路が開いたまま」という事故を構造的に防げます。
default-deny-all の YAML
default-deny-all は、制御したい方向を policyTypes で指定します。受信・送信の両方を全拒否する完全版なら policyTypes: [Ingress, Egress] ですが、本回は学習の段差をなだらかにするため、まず受信(Ingress)のみを全拒否するベースラインから始めます。送信(Egress)の全拒否は H2「Egress ポリシーと DNS の落とし穴」と演習③で、client Pod に対して別途適用して観察します。
本回演習①で使う ingress のみの default-deny-all NetworkPolicy の YAML を全量で示します。ファイル名は ~/fanclub-manifests/netpol-default-deny-all.yaml です。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
namespace: default
spec:
podSelector: {}
policyTypes:
- Ingressこの YAML はわずか 8 行ですが、ゼロトラストネットワークの起点として強力に作用します。各フィールドの意味を整理します。
| フィールド | 値 | 意味 |
|---|---|---|
spec.podSelector | {}(空オブジェクト) | default Namespace 内の全 Pod が適用対象になる。ラベルでの絞り込みをしない |
spec.policyTypes | [Ingress] | 受信方向のみを制御対象にする。送信(Egress)は本ポリシーでは制御しない |
spec.ingress | (フィールドなし) | ingress 許可ルールが 0 個 = 全 Pod への受信を全拒否 |
ポイントは 2 つです。第 1 に、podSelector: {} の空オブジェクトが「Namespace 内の全 Pod」を意味することです。前の H2 で見た「ingress: [{}] は全許可」と紛らわしいですが、podSelector の場合は「{} = 全 Pod を対象に選ぶ」という素直な意味です。第 2 に、policyTypes に Ingress と Egress を両方書いたうえで ingress / egress フィールドを 1 つも書かないことです。
これにより「両方向を制御対象にするが、許可ルールは 0 個」= 「両方向とも全拒否」が成立します。
Ingress のみの default-deny も存在する
default-deny には「Ingress のみ」「Egress のみ」「両方」のバリエーションがあります。policyTypes に書いた方向だけが全拒否になるため、たとえば「受信は全拒否したいが送信は制限しない」場合は次のように書きます。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
namespace: default
spec:
podSelector: {}
policyTypes:
- Ingress本回の演習①では、まず影響範囲を抑えるためこの「Ingress のみの default-deny」相当から始め、ingress の遮断を観察します。演習③で Egress を含む default-deny を扱い、DNS の落とし穴を再現する流れにします。「policyTypes に書いた方向のみ全拒否、書かなかった方向はノータッチ」というルールは、後述する「policyTypes 指定漏れ」の落とし穴の理解にも直結します。
default-deny を最後に適用する本番の鉄則
default-deny-all はゼロトラスト設計の「概念上の起点」ですが、本番環境への適用順序には注意が必要です。すでに稼働中のクラスタに default-deny-all を先に適用すると、許可ルールがまだ 1 つもないため、その瞬間にクラスタ内の全通信が遮断されます。アプリ間の通信も、DNS も、すべて止まります。
このため本番の鉄則は「allow ルールを先に全部適用し、最後に default-deny を適用する」です。allow ルールを先に入れておけば、default-deny を適用した瞬間に「許可済の通信は残り、未許可の通信だけが遮断される」という意図通りの状態に切り替わります。本回の演習は学習目的で「先に default-deny → 後から allow」の順で疎通断と復活を観察しますが、これは演習だからこその順序です。本番では逆順が正解であることを H2「現場ヒヤリハット」で具体的な事故事例とともに扱います。
やってみよう①: default-deny-all を適用して疎通断を観察する
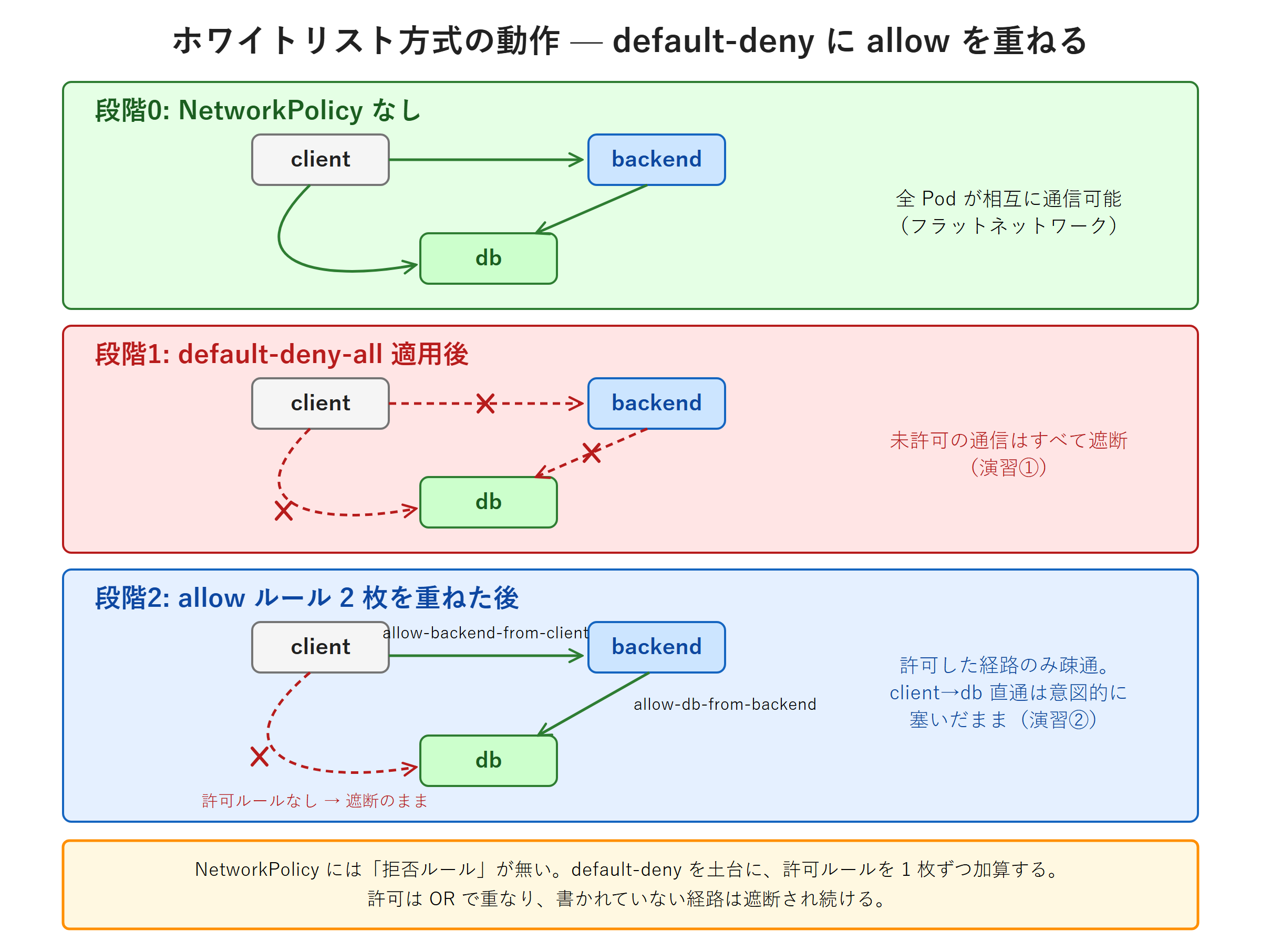
演習①では、NetworkPolicy がない状態の疎通を確認したうえで default-deny-all を適用し、Pod 間通信が遮断される様子を実機で観察します。所要時間は 20 分程度です。本演習で確認するのは「NetworkPolicy を 1 つ適用するとホワイトリスト方式に切り替わる」という本回最重要の挙動です。
Step 1: client Pod を作成する
fanclub-api の Frontend 役をシミュレートする client Pod を作成します。curl が使えるイメージとして curlimages/curl を使い、コンテナを起動したままにするため sleep でループさせます。後の NetworkPolicy で許可元として選択できるよう、role=client ラベルを付けます。マニフェストは ~/fanclub-manifests/client-pod.yaml として保存します。
apiVersion: v1
kind: Pod
metadata:
name: client
namespace: default
labels:
role: client
spec:
containers:
- name: curl
image: curlimages/curl:8.11.1
command: ["sleep", "infinity"]
resources:
requests:
cpu: 50m
memory: 32Mi
limits:
cpu: 100m
memory: 64Mi実行コマンド:
$ kubectl apply -f ~/fanclub-manifests/client-pod.yaml
$ kubectl wait --for=condition=Ready pod/client --timeout=60s期待される実行結果:
pod/client created
pod/client condition metclient Pod が Running になったことを確認します。
実行コマンド:
$ kubectl get pod client --show-labels期待される実行結果:
NAME READY STATUS RESTARTS AGE LABELS
client 1/1 Running 0 18s role=clientStep 2: NetworkPolicy なしで疎通を確認する
NetworkPolicy を適用する前の「フラットネットワーク」状態で、client Pod から fanclub-backend Service へ HTTP リクエストを送り、疎通することを確認します。fanclub-backend Service は ep8 で作成済の ClusterIP Service(port 8080)です。fanclub-backend の API はヘルスチェック用に /health エンドポイントを公開しています。
実行コマンド:
$ kubectl exec client -- curl -s -o /dev/null -w "%{http_code}\n" \
--max-time 5 http://fanclub-backend/health期待される実行結果:
200HTTP ステータス 200 が返り、client → fanclub-backend の疎通が成立しています。-w "%{http_code}" は curl のレスポンス HTTP ステータスコードのみを出力するオプション、--max-time 5 は 5 秒でタイムアウトさせるオプションです。NetworkPolicy がない状態では、このように Namespace 内の Pod 同士は自由に通信できます。
Step 3: default-deny-all を作成して適用する
演習用に、まず ingress のみを全拒否する default-deny-all NetworkPolicy を適用します。本演習では egress を含めず ingress のみに絞ることで、観察対象を「受信の遮断」に限定します。マニフェストは ~/fanclub-manifests/netpol-default-deny-all.yaml です。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
namespace: default
spec:
podSelector: {}
policyTypes:
- Ingress実行コマンド:
$ kubectl apply -f ~/fanclub-manifests/netpol-default-deny-all.yaml期待される実行結果:
networkpolicy.networking.k8s.io/default-deny-all createdこの瞬間、default ns の全 Pod の ingress が「ホワイトリスト方式」に切り替わりました。許可ルールが 0 個なので、すべての Pod への受信通信が遮断された状態です。
Step 4: 疎通が遮断されたことを観察する
Step 2 と同じ curl を再実行します。今度は fanclub-backend が ingress 全拒否になっているため、接続が確立できずタイムアウトします。
実行コマンド:
$ kubectl exec client -- curl -s -o /dev/null -w "%{http_code}\n" \
--max-time 5 http://fanclub-backend/health
$ echo "exit code: $?"期待される実行結果:
curl: (28) Connection timed out after 4002 milliseconds
000
exit code: 28curl が (28) Connection timed out を出力し、HTTP ステータスは 000(接続が確立しなかったことを示す)、exit code は 28 になりました。exit code 28 は curl の「Operation timeout(操作タイムアウト)」を意味します。NetworkPolicy が ingress を遮断すると、パケットは宛先 Pod に届かず、TCP の SYN に対する応答が返ってきません。
curl は応答を待ち続け、--max-time 5 の制限に達してタイムアウトします。「接続を試みたが応答がない → タイムアウト」というのが ingress 遮断の典型的なエラーパターンです。
NetworkPolicy 適用前は HTTP 200、適用後は exit code 28 のタイムアウト。1 つの NetworkPolicy を kubectl apply しただけで、default ns の通信状態が「全許可」から「全拒否」に切り替わったことが実機で確認できました。
Step 5: kubectl describe で適用状態を確認する
kubectl describe networkpolicy で、適用された NetworkPolicy の内容を確認します。CKAD 試験でも NetworkPolicy のトラブルシューティングで頻繁に使うコマンドです。
実行コマンド:
$ kubectl describe networkpolicy default-deny-all期待される実行結果:
Name: default-deny-all
Namespace: default
Created on: 2026-05-16 14:22:08 +0900 JST
Labels: <none>
Annotations: <none>
Spec:
PodSelector: <none> (Allowing the specific traffic to all pods in this namespace)
Allowing ingress traffic:
<none> (Selected pods are isolated for ingress connectivity)
Not affecting egress traffic
Policy Types: Ingressdescribe の出力で注目するのは 2 行です。PodSelector: <none> は「podSelector: {} により Namespace 内の全 Pod が対象」を意味します。Allowing ingress traffic: <none> (Selected pods are isolated for ingress connectivity) は「ingress の許可ルールが 0 個で、対象 Pod は ingress について隔離(isolated)されている」ことを示します。
Not affecting egress traffic は policyTypes に Egress を含めなかったため egress は制御していないことを示しています。「isolated for ingress connectivity」という表現が、ホワイトリスト方式に切り替わった状態を表しています。
Step 6: fanclub-backend Pod 自身も到達不可になったことを確認する
default-deny-all は podSelector: {} で全 Pod を対象にしているため、client Pod だけでなく fanclub-backend / fanclub-db を含む default ns の全 Pod が ingress 遮断されています。fanclub-backend Pod が他の Pod から到達不可になったことを、別の角度から確認します。fanclub-backend Pod 同士(replica 間)の疎通も遮断されているはずです。
fanclub-backend Pod の 1 つから、もう 1 つの fanclub-backend Pod の IP へ直接接続を試します。まず Pod の IP を確認します。
実行コマンド:
$ kubectl get pod -l app=fanclub-backend -o wide期待される実行結果:
NAME READY STATUS RESTARTS AGE IP NODE
fanclub-backend-deployment-86cf676cf7-g7h2z 1/1 Running 0 2d18h 10.244.0.64 kind-control-plane
fanclub-backend-deployment-86cf676cf7-gqt2j 1/1 Running 0 2d18h 10.244.0.65 kind-control-plane一方の Pod(10.244.0.64)から、もう一方の Pod の IP(10.244.0.65)の 8080 ポートへ接続を試します。fanclub-backend のコンテナイメージには curl も nc も含まれないため、演習②と同じく kubectl debug で busybox の Ephemeral Container を追加して nc を使います。
実行コマンド:
$ kubectl debug fanclub-backend-deployment-86cf676cf7-g7h2z -n default -it \
--image=busybox:1.36 --profile=general -- nc -z -v -w 5 10.244.0.65 8080期待される実行結果:
Defaulting debug container name to debugger-jv2h9.
nc: 10.244.0.65 (10.244.0.65:8080): Operation timed out
pod default/fanclub-backend-deployment-86cf676cf7-g7h2z terminated (Error)fanclub-backend Pod 同士の通信もタイムアウト(Ephemeral Container は終了コード 1 = Error)で遮断されています。default-deny-all が「default ns の全 Pod」に作用していることが、これで確認できました。NetworkPolicy が podSelector: {} を使うと例外なく全 Pod に効く、という事実を実機で確認しておくと、本番で default-deny を適用する際の影響範囲を見誤らずに済みます。
Step 7: deny 状態のまま演習②へ引き継ぐ
演習①では default-deny-all を適用した状態をそのまま残し、演習②で allow ルールを段階的に重ねて通信を復活させます。本番のゼロトラスト設計と同じく「全拒否のベースラインを引いてから、必要な通信だけを 1 枚ずつ許可していく」という流れを演習②でなぞります。現時点での default ns の NetworkPolicy 一覧を確認しておきます。
実行コマンド:
$ kubectl get networkpolicy期待される実行結果:
NAME POD-SELECTOR AGE
default-deny-all <none> 5mPOD-SELECTOR 列が <none> なのは podSelector: {}(全 Pod 対象)を示しています。default ns には現在 default-deny-all 1 つだけが適用され、全 Pod の ingress が遮断された状態です。
演習①まとめ
- curl を備えた
clientPod(role=clientラベル付き)を作成し、NetworkPolicy なしの状態で fanclub-backend への HTTP 疎通(200)を確認した podSelector: {}+policyTypes: [Ingress]のdefault-deny-allを適用し、client → fanclub-backend が exit code 28(タイムアウト)で遮断されることを実機検証したkubectl describe networkpolicyでSelected pods are isolated for ingress connectivityの出力を確認し、ホワイトリスト方式に切り替わったことを観察した- fanclub-backend Pod 同士の直接通信も exit code 28 で遮断され、
podSelector: {}が default ns の全 Pod に作用していることを確認した
ingress ルールの設計 — podSelector / namespaceSelector / ipBlock
演習①で「全拒否」のベースラインを引きました。次は、その上に「この通信は許可する」という ingress ルールを設計する方法を整理します。演習②で実際に書く allow ルールの設計指針を、ここで先に固めておきます。
ingress ルールの基本構造
ingress ルールは「どの Pod に対する(spec.podSelector)、どこからの(ingress[].from)、どのポートへの(ingress[].ports)受信を許可するか」を定義します。3 つの「どこ」を埋めることで 1 つの許可ルールが完成します。次の YAML は「app: fanclub-backend ラベルの Pod に対して、role: client ラベルの Pod から 8080/TCP の受信を許可する」ルールです。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-backend-from-client
namespace: default
spec:
podSelector:
matchLabels:
app: fanclub-backend
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
role: client
ports:
- protocol: TCP
port: 8080この YAML の各「どこ」を表で整理します。
| 「どこ」 | フィールド | この例での値 |
|---|---|---|
| どの Pod に対する受信か | spec.podSelector | app: fanclub-backend の Pod |
| どこからの受信を許可するか | ingress[].from | role: client ラベルの Pod |
| どのポートへの受信を許可するか | ingress[].ports | 8080/TCP |
許可元の指定方法 3 種類の使い分け
YAML 構造の H2 でも触れた podSelector / namespaceSelector / ipBlock の 3 種類を、ingress ルール設計の実務的な観点で使い分けます。
| 許可元 | 使う場面 | fanclub-api での例 |
|---|---|---|
podSelector | 同じ Namespace 内の特定アプリからのみ許可したいとき | fanclub-backend は同 ns の Frontend(client 役)からのみ受信 |
namespaceSelector | 別の Namespace 全体(監視・Ingress 用 ns 等)からの通信を許可したいとき | 監視用 ns の Prometheus から metrics エンドポイントへの受信を許可 |
ipBlock | クラスタ外部の特定 IP レンジからの通信を許可したいとき | 社内ネットワークの管理端末からの受信を許可 |
本回の演習②で実装するのは podSelector ベースのルールです。fanclub-backend / fanclub-db / client がすべて default ns 内に存在するため、同一 ns 内のラベルで許可元を指定する podSelector が最も素直です。namespaceSelector は演習③の DNS 許可ルール(kube-system ns の kube-dns を許可元/許可先に指定)で使います。
複数 from エントリは OR 条件
1 つの ingress ルールの from 配列に複数のエントリを並べると、それらは OR 条件(どれか 1 つにマッチすれば許可)になります。たとえば「client 役の Pod、または node-logger からの受信を許可」は次のように書きます。
ingress:
- from:
- podSelector:
matchLabels:
role: client
- podSelector:
matchLabels:
app: node-logger
ports:
- protocol: TCP
port: 8080さらに、ingress 配列自体を複数にすることもできます。ingress の各要素(各ルール)も OR で評価され、「いずれかのルールにマッチした通信は許可」になります。ホワイトリスト方式では「許可ルールが 1 つでもマッチすれば通す」ため、ルールを足せば足すほど許可される通信が増える(加算される)方向に働きます。この「許可の加算」という性質は演習②の Step 8 で整理します。
ports の指定とプロトコル
ports は許可するポートとプロトコルを指定します。protocol は TCP(デフォルト)/ UDP / SCTP のいずれかです。HTTP / PostgreSQL などのアプリ通信は TCP、DNS は UDP と TCP の両方を使います。port には数値(8080)のほか、Pod の containerPort に名前が付いている場合はその名前を指定することもできます。ports を省略すると「許可元からの全ポートへの通信を許可」になるため、本番では必要なポートだけを明示するのが定石です。
| 通信 | protocol | port |
|---|---|---|
| fanclub-backend の HTTP API | TCP | 8080 |
| fanclub-db の PostgreSQL | TCP | 5432 |
| DNS(名前解決) | UDP と TCP の両方 | 53 |
DNS が UDP と TCP の両方を使う点は、演習③の DNS 許可ルールで重要になります。通常の DNS クエリは UDP/53 を使いますが、レスポンスが大きい場合(DNS over TCP)には TCP/53 にフォールバックします。このため DNS を許可するときは UDP/53 と TCP/53 を両方書くのが鉄則です。
やってみよう②: 段階的な allow ルールで通信を許可する
演習②では、演習①で適用した default-deny-all(ingress 全拒否)の上に、allow ルールを 1 枚ずつ重ねて必要な通信を復活させます。所要時間は 25 分程度です。本番のゼロトラスト設計と同じ「全拒否のベースラインに許可を加算していく」流れを実機でなぞります。
Step 1: allow-backend-from-client を作成する
最初に「client → fanclub-backend:8080」を許可する allow-backend-from-client NetworkPolicy を作成します。マニフェストは ~/fanclub-manifests/netpol-allow-backend-from-client.yaml です。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-backend-from-client
namespace: default
spec:
podSelector:
matchLabels:
app: fanclub-backend
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
role: client
ports:
- protocol: TCP
port: 8080この NetworkPolicy は「app: fanclub-backend の Pod に対して、role: client の Pod から 8080/TCP の ingress を許可」します。default-deny-all が ingress を全拒否している状態でも、このルールにマッチした通信(client → fanclub-backend:8080)だけは穴が開きます。
Step 2: 適用して疎通復活を確認する
実行コマンド:
$ kubectl apply -f ~/fanclub-manifests/netpol-allow-backend-from-client.yaml期待される実行結果:
networkpolicy.networking.k8s.io/allow-backend-from-client created演習①の Step 4 と同じ curl を再実行し、疎通が復活したことを確認します。
実行コマンド:
$ kubectl exec client -- curl -s -o /dev/null -w "%{http_code}\n" \
--max-time 5 http://fanclub-backend/health期待される実行結果:
200exit code 28 のタイムアウトから HTTP 200 へ復活しました。default-deny-all で全拒否されていた fanclub-backend への受信に、allow-backend-from-client の許可ルールで「client から 8080/TCP のみ」という穴が開いたことになります。ホワイトリストに 1 枚目を重ねた状態です。
Step 3: fanclub-backend → fanclub-db がまだ遮断されていることを確認する
fanclub-backend は DB アクセスのため fanclub-db の 5432/TCP に接続します。しかし default-deny-all は fanclub-db への ingress も遮断しているため、現時点では fanclub-backend → fanclub-db の通信は断たれているはずです。これを確認したいのですが、fanclub-backend のコンテナイメージ(JDK 25 + Payara Micro ベース)には nc(netcat)も curl も含まれていません。
そこで ep12 で学んだ kubectl debug を使い、fanclub-backend Pod に busybox の Ephemeral Container を一時的に追加します。Ephemeral Container は対象 Pod のネットワーク namespace を共有するため、そこから出る通信は fanclub-backend Pod(app: fanclub-backend ラベル)からの通信として NetworkPolicy に評価されます。
実行コマンド:
$ BPOD=$(kubectl get pod -l app=fanclub-backend -n default -o jsonpath='{.items[0].metadata.name}')
$ kubectl debug $BPOD -n default -it --image=busybox:1.36 --profile=general -- nc -z -v -w 5 fanclub-db 5432期待される実行結果:
Defaulting debug container name to debugger-htss8.
nc: fanclub-db (10.96.131.167:5432): Operation timed out
pod default/fanclub-backend-deployment-86cf676cf7-g7h2z terminated (Error)fanclub-db の 5432 ポートへの接続がタイムアウトしました(nc の Ephemeral Container は終了コード 1 = Error で終了)。allow-backend-from-client は「fanclub-backend への受信」を許可しただけで、「fanclub-db への受信」は許可していません。fanclub-db には依然 default-deny-all の全拒否が効いているため、fanclub-backend → fanclub-db は遮断されたままです。
次の Step で fanclub-db への許可ルールを追加します。
Step 4: allow-db-from-backend を作成する
「fanclub-backend → fanclub-db:5432」を許可する allow-db-from-backend NetworkPolicy を作成します。マニフェストは ~/fanclub-manifests/netpol-allow-db-from-backend.yaml です。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-db-from-backend
namespace: default
spec:
podSelector:
matchLabels:
app: fanclub-db
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
app: fanclub-backend
ports:
- protocol: TCP
port: 5432このルールは「app: fanclub-db の Pod に対して、app: fanclub-backend の Pod から 5432/TCP の ingress を許可」します。fanclub-db StatefulSet の Pod には app: fanclub-db ラベルが付いている前提です(ep9 で作成済)。
Step 5: 適用して fanclub-backend → fanclub-db の疎通復活を確認する
実行コマンド:
$ kubectl apply -f ~/fanclub-manifests/netpol-allow-db-from-backend.yaml期待される実行結果:
networkpolicy.networking.k8s.io/allow-db-from-backend createdStep 3 と同じ kubectl debug + nc を再実行します。
実行コマンド:
$ kubectl debug $BPOD -n default -it --image=busybox:1.36 --profile=general -- nc -z -v -w 5 fanclub-db 5432期待される実行結果:
Defaulting debug container name to debugger-msbbr.
fanclub-db (10.96.131.167:5432) open
pod default/fanclub-backend-deployment-86cf676cf7-g7h2z terminated (Completed)fanclub-db (10.96.131.167:5432) open が返り、Ephemeral Container は終了コード 0(Completed)で終了しました。fanclub-backend → fanclub-db:5432 の疎通が復活しています。出力の IP 10.96.131.167 は fanclub-db Service の ClusterIP で、nc に Service 名を渡すと DNS 解決された ClusterIP が表示されます。ホワイトリストに 2 枚目を重ねた状態です。
これで fanclub-api の主要な通信経路(client → backend → db)が NetworkPolicy 適用下で疎通するようになりました。
Step 6: NetworkPolicy 一覧を確認する
現時点で default ns に適用されている NetworkPolicy を一覧で確認します。
実行コマンド:
$ kubectl get networkpolicy期待される実行結果:
NAME POD-SELECTOR AGE
allow-backend-from-client app=fanclub-backend 8m
allow-db-from-backend app=fanclub-db 3m
default-deny-all <none> 20m3 つの NetworkPolicy が表示されています。default-deny-all がベースライン(全拒否)、allow-backend-from-client と allow-db-from-backend が許可の穴です。POD-SELECTOR 列を見ると、ベースラインは <none>(全 Pod)、許可ルールはそれぞれ app=fanclub-backend / app=fanclub-db と、対象 Pod が明確に分かれています。
Step 7: 許可していない通信が遮断されたままであることを確認する
ここで重要な検証を行います。許可ルールを 2 枚重ねましたが、「client が fanclub-db に直接接続する」経路は許可していません。本来 client(Frontend 役)は backend 経由でしか DB に触れないはずなので、client → fanclub-db の直通経路は遮断されたままであるべきです。client Pod には nc が含まれているため、そのまま nc で fanclub-db:5432 へ接続を試します(-v で接続先と結果を表示します)。
実行コマンド:
$ kubectl exec client -- nc -v -z -w 5 fanclub-db 5432
$ echo "exit code: $?"期待される実行結果:
nc: fanclub-db (10.96.131.167:5432): Operation timed out
exit code: 1client → fanclub-db:5432 はタイムアウトで遮断されたままです。allow-db-from-backend は「fanclub-db への受信を app: fanclub-backend の Pod からのみ許可」しており、role: client の Pod はその許可元に含まれていません。このため client から fanclub-db への直接接続は default-deny-all の全拒否のまま遮断されます。
この「許可していない経路が遮断されたままであること」を確認する Step は、ホワイトリストに穴がないことを示す重要な検証です。本番の NetworkPolicy 設計でも、許可した通信が疎通することだけでなく「意図しない経路が開いていないか」を確かめるネガティブテストが必須で、設計レビューでも「Frontend が DB に直アクセスできないこと」のような遮断側の確認項目を必ず用意します。
許可ルールを書くと、つい「狙った通信が通った」だけで安心しがちですが、ホワイトリスト設計では「通ってはいけない通信が通っていないこと」の確認とセットで初めて検証が完了します。
Step 8: ポリシーの重ね合わせ(許可の加算)を整理する
演習②で確認した「複数の NetworkPolicy が同じ Namespace に共存したときの挙動」を整理します。NetworkPolicy は複数適用されても、それぞれが独立に「許可ルール」を提供します。ある Pod への通信は、適用されているいずれかの NetworkPolicy の許可ルールにマッチすれば疎通します(許可の OR・加算)。逆に、どの NetworkPolicy にもマッチしなければ遮断されます。
| 通信 | マッチする許可ルール | 結果 |
|---|---|---|
| client → fanclub-backend:8080 | allow-backend-from-client | 疎通 |
| fanclub-backend → fanclub-db:5432 | allow-db-from-backend | 疎通 |
| client → fanclub-db:5432 | なし | 遮断(default-deny-all のまま) |
| client → fanclub-backend:9090 | なし(8080 のみ許可) | 遮断 |
重要なのは「NetworkPolicy には『拒否ルール』が存在しない」という点です。NetworkPolicy は許可ルールしか書けず、複数のポリシーは許可を加算する方向にしか作用しません。「ある通信を後から禁止したい」場合は、その通信を許可しているルールを削除するか、許可元から外す形で対応します。default-deny-all をベースに置き、許可ルールを足し引きする設計が、ホワイトリスト方式における唯一の制御手段です。
演習②まとめ
allow-backend-from-client(client → fanclub-backend:8080)を適用し、演習①でタイムアウトしていた client → fanclub-backend が HTTP 200 で復活することを実機検証したallow-db-from-backend適用前は fanclub-backend → fanclub-db:5432 がncでタイムアウト(exit 1)、適用後はopen(exit 0)で復活することを確認したkubectl get networkpolicyで 3 ポリシー(ベースライン 1 + 許可 2)を一覧確認した- 許可していない client → fanclub-db 直接通信が遮断されたままであることを確認し、ネガティブテストが本番設計でも必須であることを整理した
- NetworkPolicy は許可ルールのみで構成され、複数ポリシーは許可を加算する方向にしか作用しないことを整理した
Egress ポリシーと DNS の落とし穴
演習①②では ingress(受信)の制御を扱いました。次は egress(送信)の制御です。Egress 制御には、ingress にはない「DNS の落とし穴」があり、これは CKAD 試験でも本番運用でも頻出のつまずきポイントです。演習③に入る前に、この落とし穴の構造を整理します。
Egress を default-deny にすると DNS が切れる
Kubernetes の Pod が http://fanclub-backend のような Service 名で通信するとき、内部では次の 2 段階が起きています。
- 名前解決:
fanclub-backendという Service 名を、クラスタ DNS(kube-dns / CoreDNS)に問い合わせて ClusterIP に変換する。この問い合わせは kube-system ns の DNS Pod に対する UDP/53(場合により TCP/53)の通信 - 接続:得られた ClusterIP に対して TCP 接続を確立し、HTTP リクエストを送る
Egress を default-deny にすると、この 2 段階のうち最初の「名前解決」の通信(DNS Pod への UDP/53)も遮断されます。すると Pod は Service 名を IP に変換できず、接続の段階に進む前に名前解決の段階で失敗します。「Egress 制御を入れたら、宛先を許可したはずなのに通信できない」というトラブルの大半は、この DNS の遮断が原因です。
名前解決の失敗は接続のタイムアウトと別物
ingress 遮断(演習①で見た exit code 28 のタイムアウト)と、egress 制御による DNS 遮断では、エラーの種類が異なります。違いを整理します。
| 遮断の種類 | どの段階で失敗するか | curl のエラー |
|---|---|---|
| ingress 遮断 | 名前解決は成功するが、接続の段階で宛先に届かない | Connection timed out(exit code 28) |
| egress で DNS 遮断 | 名前解決の段階で DNS Pod に届かず、応答待ちのままタイムアウト | Resolving timed out(exit code 28) |
このエラーの違いはトラブルシューティングの大きな手がかりになります。curl の exit code はどちらも 28(タイムアウト)ですが、メッセージが異なります。「Resolving timed out が出たら DNS(egress の 53 番)を疑う」「Connection timed out が出たら宛先 Pod への到達経路(ingress または egress の宛先)を疑う」と切り分けられます。この切り分け表は演習③でもう一度、curl の出力と並べて提示します。
kube-system Namespace の自動ラベル
DNS を許可する egress ルールでは、DNS Pod の所在を指定する必要があります。クラスタ DNS(kube-dns / CoreDNS)の Pod は kube-system Namespace に存在します。default ns の Pod から kube-system ns の DNS Pod への通信を許可するには、許可先(egress[].to)で別 Namespace を指定する namespaceSelector を使います。
ここで知っておくべきなのが「Kubernetes は v1.21 以降、すべての Namespace に kubernetes.io/metadata.name ラベルを自動付与する」という仕様です。kube-system Namespace には kubernetes.io/metadata.name=kube-system というラベルが、ユーザーが何もしなくても自動で付いています。default ns には kubernetes.io/metadata.name=default が付きます。
この自動ラベルがあるおかげで、namespaceSelector で Namespace を名前指定できます。実際にラベルを確認してみます。
実行コマンド:
$ kubectl get namespace kube-system --show-labels期待される実行結果:
NAME STATUS AGE LABELS
kube-system Active 3d kubernetes.io/metadata.name=kube-systemkubernetes.io/metadata.name=kube-system ラベルが確かに付いています。このラベルは Kubernetes が NamespaceLifecycle の Admission Controller を通じて自動的に付与・維持するもので、ユーザーが消しても再付与されます。namespaceSelector の matchLabels でこのラベルを参照すれば、kube-system ns を確実に指定できます。
演習③の allow-dns ルールはこの自動ラベルを根拠に kube-system ns を指定します。
allow-dns ルールの構造
DNS を許可する allow-dns NetworkPolicy の構造を先に示します。演習③の Step 4 で実際に適用するものです。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-dns
namespace: default
spec:
podSelector:
matchLabels:
role: client
policyTypes:
- Egress
egress:
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
podSelector:
matchLabels:
k8s-app: kube-dns
ports:
- protocol: UDP
port: 53
- protocol: TCP
port: 53このルールのポイントを 3 つ整理します。第 1 に、egress[].to で namespaceSelector(kube-system ns)と podSelector(k8s-app: kube-dns ラベルの Pod)を 1 つのハイフン配下に併記している点です。これは AND 条件、つまり「kube-system ns に属し、かつ k8s-app: kube-dns ラベルを持つ Pod」のみを許可先とします。
CoreDNS の Pod には k8s-app: kube-dns ラベルが付いているため、これで DNS Pod を狙い撃ちできます。第 2 に、ports に UDP/53 と TCP/53 を両方書いている点です。DNS は通常 UDP を使い、レスポンスが大きい場合に TCP にフォールバックするため、両方を許可します。第 3 に、podSelector を role: client に絞っている点です。これにより、この egress 許可は client Pod だけに適用されます。
Egress 制御は DNS 許可 + 宛先許可の 2 点セット
allow-dns だけでは Pod の通信は完成しません。allow-dns は「Service 名を IP に変換する」名前解決の段階を通すだけで、変換後の IP への接続(HTTP リクエスト本体の送信)は依然 egress の default-deny で遮断されています。Egress 制御を入れた Pod が正常に通信するには、次の 2 つの許可ルールが両方必要です。
| 許可ルール | 通す通信 | これがないと |
|---|---|---|
allow-dns | kube-dns への UDP/TCP 53 | Service 名を解決できない(Resolving timed out) |
宛先許可(allow-egress-to-backend 等) | 解決後の宛先 Pod への接続 | 名前は解決できるが接続できない(Connection timed out) |
「Egress 制御は DNS 許可と宛先許可の 2 点セット」というのが本回の egress 設計の鉄則です。演習③ではこの 2 段階を分けて適用し、それぞれの段階で何が起きるかを実機で確認します。
やってみよう③: Egress 制御と DNS 許可ルール
演習③では、client Pod に egress の default-deny を適用して DNS 名前解決が壊れる落とし穴を再現し、allow-dns と allow-egress-to-backend の 2 段階で復旧させます。所要時間は 20 分程度です。Egress 制御の「DNS 許可 + 宛先許可の 2 点セット」を実機でなぞります。
Step 1: client Pod に Egress 込みの default-deny を適用する
client Pod の egress を全拒否する default-deny-egress-client NetworkPolicy を作成します。演習②までの default-deny-all(ingress のみ・全 Pod 対象)とは別物で、podSelector を role: client に絞り、policyTypes を Egress にします。マニフェストは ~/fanclub-manifests/netpol-default-deny-egress-client.yaml です。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress-client
namespace: default
spec:
podSelector:
matchLabels:
role: client
policyTypes:
- Egress実行コマンド:
$ kubectl apply -f ~/fanclub-manifests/netpol-default-deny-egress-client.yaml期待される実行結果:
networkpolicy.networking.k8s.io/default-deny-egress-client createdこの瞬間、client Pod の egress(送信)が全拒否になりました。client から外向きのすべての通信が遮断され、DNS への問い合わせも止まっています。
Step 2: Service 名での名前解決が失敗することを観察する
client Pod から fanclub-backend Service へ Service 名で curl を試します。egress の default-deny で DNS への通信が切れているため、名前解決の段階で失敗するはずです。
実行コマンド:
$ kubectl exec client -- curl -s -o /dev/null -w "%{http_code}\n" \
--max-time 5 http://fanclub-backend/health
$ echo "exit code: $?"期待される実行結果:
curl: (28) Resolving timed out after 5001 milliseconds
000
exit code: 28curl のエラーが (28) Resolving timed out になりました。演習①の ingress 遮断でも exit code は 28 でしたが、メッセージが異なります。演習①は Connection timed out(接続のタイムアウト)でしたが、今回は Resolving timed out(名前解決のタイムアウト)です。egress が全拒否のため client から kube-dns への DNS クエリのパケットが遮断され、応答が返ってきません。
client は名前解決の応答を待ち続け、--max-time 5 の制限に達してタイムアウトします。fanclub-backend という名前を ClusterIP に変換できず、接続(HTTP リクエスト送信)の段階に進む前に、名前解決の段階で止まっています。NetworkPolicy で DNS パケットが破棄される場合、resolver は「ホストが存在しない」と即答されるわけではなく、応答待ちのままタイムアウトする点が重要です。
Step 3: IP 直接指定の curl も遮断されることを観察する
「名前解決が問題なら、IP を直接指定すれば通るのでは」と考えるかもしれません。これを実機で確認します。fanclub-backend Service の ClusterIP を取得し、IP 直指定で curl を試します。
実行コマンド:
$ BACKEND_IP=$(kubectl get svc fanclub-backend -o jsonpath='{.spec.clusterIP}')
$ echo $BACKEND_IP
$ kubectl exec client -- curl -s -o /dev/null -w "%{http_code}\n" \
--max-time 5 http://$BACKEND_IP/health
$ echo "exit code: $?"期待される実行結果:
10.96.150.60
curl: (28) Connection timed out after 5001 milliseconds
000
exit code: 28IP 直指定では名前解決の段階を飛ばすため Resolving timed out は出ませんが、今度は接続の段階で Connection timed out(exit code 28)になります。egress の default-deny は DNS だけでなく「すべての外向き通信」を遮断しているため、ClusterIP への接続そのものも遮断されているからです。
同じ exit code 28 でもメッセージが Resolving timed out(名前解決の段階)から Connection timed out(接続の段階)に変わっており、名前解決の問題と接続経路の問題が別個に存在することが、このメッセージの違いから確認できます。
エラー切り分け表
ここまでの演習で観察した 3 種類のエラーを切り分け表として整理します。NetworkPolicy のトラブルシューティングでは、curl / nc が出すエラーから「どこが遮断されているか」を逆算するのが定石です。
| 観察したエラー | 失敗した段階 | 遮断されている通信 | 確認すべきルール |
|---|---|---|---|
curl: (28) Resolving timed out(exit 28) | 名前解決(DNS) | Egress の DNS(kube-dns への UDP/TCP 53)が遮断 | egress に allow-dns 相当のルールがあるか |
curl: (28) Connection timed out(exit 28) | 接続(TCP 確立) | 宛先 Pod への到達経路が遮断 | 送信側の egress 宛先許可、または受信側の ingress 許可があるか |
nc: ... timed out(exit 1) | 接続(TCP 確立) | 同上(nc 版) | 同上 |
覚え方は「Egress 断は名前解決で失敗 → Resolving timed out / Ingress 断は接続で失敗 → Connection timed out」です。curl の exit code はどちらも 28 で同じため、メッセージの文言で切り分けるのがポイントです。
Resolving timed out が出たら真っ先に egress の 53 番(DNS 許可)を疑い、Connection timed out が出たら宛先への到達経路(egress の宛先許可か ingress 許可)を疑う、という順序でトラブルシューティングを進めます。なお、IP 直指定の場合は名前解決の段階を飛ばすため、egress が遮断されていても Resolving timed out ではなく Connection timed out になる点に注意します。
Step 4: allow-dns を作成して適用する
名前解決を復旧させる allow-dns NetworkPolicy を適用します。マニフェストは ~/fanclub-manifests/netpol-allow-dns.yaml で、内容は前 H2 で示したものです。再掲します。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-dns
namespace: default
spec:
podSelector:
matchLabels:
role: client
policyTypes:
- Egress
egress:
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
podSelector:
matchLabels:
k8s-app: kube-dns
ports:
- protocol: UDP
port: 53
- protocol: TCP
port: 53実行コマンド:
$ kubectl apply -f ~/fanclub-manifests/netpol-allow-dns.yaml期待される実行結果:
networkpolicy.networking.k8s.io/allow-dns createdStep 5: 名前解決は復活するが HTTP はまだ遮断されることを観察する
Step 2 と同じ Service 名 curl を再実行します。DNS は復活しますが、HTTP 接続は宛先許可がまだないため遮断されたままのはずです。
実行コマンド:
$ kubectl exec client -- curl -s -o /dev/null -w "%{http_code}\n" \
--max-time 5 http://fanclub-backend/health
$ echo "exit code: $?"期待される実行結果:
curl: (28) Connection timed out after 5001 milliseconds
000
exit code: 28エラーメッセージが Resolving timed out(名前解決失敗)から Connection timed out(接続タイムアウト)に変わりました。これは前進です。allow-dns によって名前解決の段階は通過できるようになり、curl は fanclub-backend を ClusterIP に変換できています。しかし egress の宛先許可がまだないため、変換後の ClusterIP への接続の段階で遮断され、タイムアウトしています。
exit code はどちらも 28 で変わりませんが、メッセージの変化(Resolving timed out → Connection timed out)が、復旧が「名前解決」と「接続」の 2 段階であることを示しています。
Step 6: allow-egress-to-backend を追加して完全復旧する
最後に、client から fanclub-backend への egress を許可する allow-egress-to-backend NetworkPolicy を適用します。マニフェストは ~/fanclub-manifests/netpol-allow-egress-to-backend.yaml です。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-egress-to-backend
namespace: default
spec:
podSelector:
matchLabels:
role: client
policyTypes:
- Egress
egress:
- to:
- podSelector:
matchLabels:
app: fanclub-backend
ports:
- protocol: TCP
port: 8080このルールは「role: client の Pod から、app: fanclub-backend の Pod への 8080/TCP の egress を許可」します。
実行コマンド:
$ kubectl apply -f ~/fanclub-manifests/netpol-allow-egress-to-backend.yaml期待される実行結果:
networkpolicy.networking.k8s.io/allow-egress-to-backend createdService 名 curl を再実行します。
実行コマンド:
$ kubectl exec client -- curl -s -o /dev/null -w "%{http_code}\n" \
--max-time 5 http://fanclub-backend/health
$ echo "exit code: $?"期待される実行結果:
200
exit code: 0HTTP 200 が返り、client → fanclub-backend の通信が完全復旧しました。allow-dns(名前解決)と allow-egress-to-backend(宛先接続)の 2 つが揃って初めて、egress 制御下の Pod が Service 名で正常に通信できます。
なお、この通信が成立するには client 側の egress 許可(本 Step)に加えて、fanclub-backend 側の ingress 許可(演習② の allow-backend-from-client)も必要です。NetworkPolicy は送信側・受信側の両方で許可が揃って初めて通信が成立する点に注意します。
Step 7: Egress 制御は DNS 許可 + 宛先許可の 2 点セットと整理する
演習③で観察したエラーコードの変化を時系列で整理します。
| 状態 | 適用済の egress 許可 | Service 名 curl の結果 |
|---|---|---|
| Step 2 | なし(egress 全拒否) | exit 6(Could not resolve host) |
| Step 5 | allow-dns のみ | exit 28(接続タイムアウト) |
| Step 6 | allow-dns + allow-egress-to-backend | HTTP 200(完全復旧) |
「Egress 制御を入れたら DNS 許可と宛先許可をセットで書く」というのが、本回の egress 設計で最も重要な鉄則です。DNS 許可を忘れると Could not resolve host、宛先許可を忘れると接続タイムアウトになります。本番で Pod に egress 制御を入れるときは、allow-dns を必ず最初の許可ルールとして組み込み、そのうえで各 Pod が通信する宛先(DB、外部 API、他の Service 等)を 1 つずつ許可していく形になります。
この落とし穴は H2「現場ヒヤリハット」の②でも本番事例として扱います。
演習③まとめ
- client Pod に egress の default-deny を適用し、Service 名 curl が exit 6(
Could not resolve host)で名前解決失敗することを実機検証した - IP 直指定の curl は名前解決を飛ばすため
Could not resolve hostではなく exit 28(接続タイムアウト)になることを確認し、名前解決と接続が別段階であることを観察した - 3 種類のエラー(exit 6 / exit 28 / nc タイムアウト)の切り分け表を整理し、「
Could not resolve hostは DNS を疑う、タイムアウトは到達経路を疑う」というトラブルシューティング指針を確立した allow-dns適用で名前解決が復活し、エラーが exit 6 から exit 28 に変化(前進)することを確認したallow-egress-to-backend追加で HTTP 200 まで完全復旧し、「Egress 制御は DNS 許可 + 宛先許可の 2 点セット」を整理した
fanclub-api の NetworkPolicy 全体設計(4 層モデル)
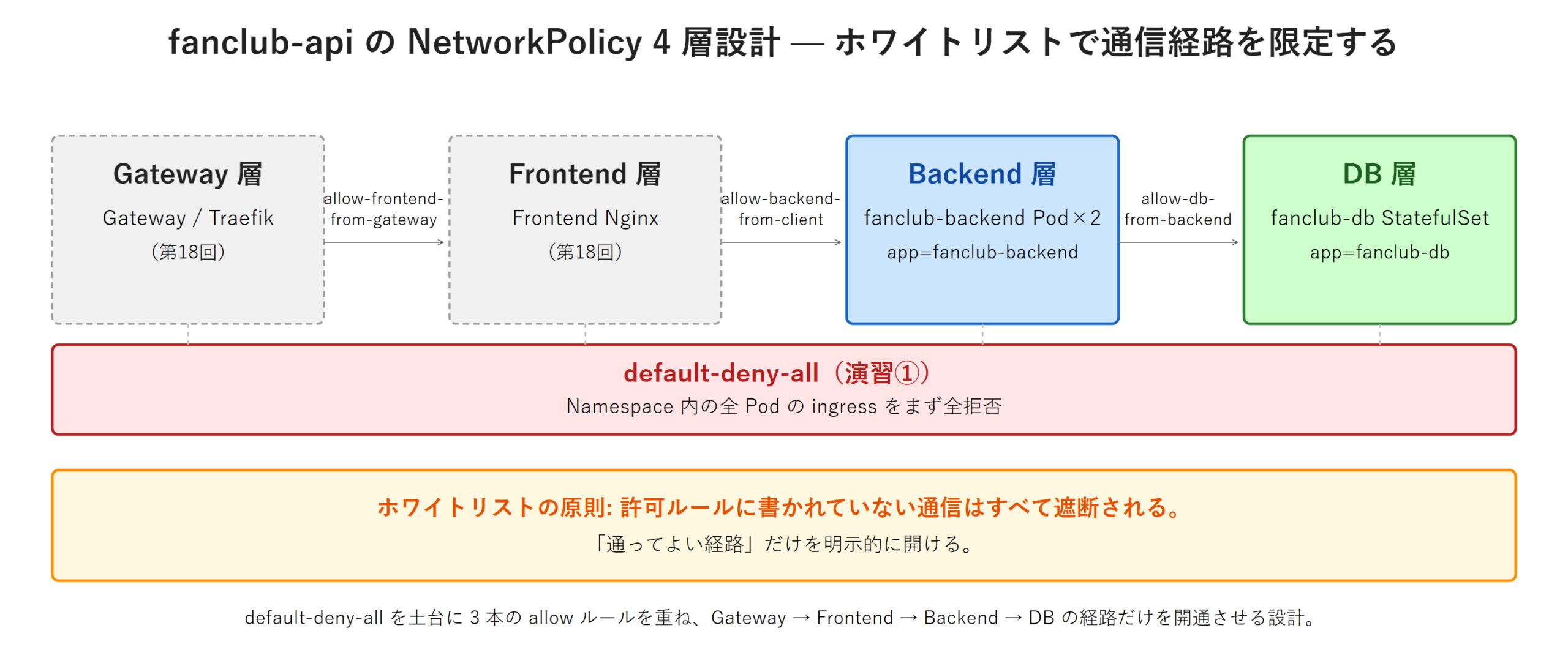
演習①〜③で実装した NetworkPolicy 群は、fanclub-api 全体のネットワーク設計の一部です。本 H2 では、ep18 で Frontend / Gateway を実装した後に完成する「4 層モデル」の全体設計図を提示し、本回で実装した部分がその中でどこに位置するかを整理します。
fanclub-api の 4 層ネットワーク構造
fanclub-api は最終的に Gateway → Frontend → Backend → DB の 4 層構造になります。各層は「直前の層からのみ受信を許可」というホワイトリストで連結され、外部からのリクエストが層を 1 つずつ通過して DB に到達する設計です。
4 層それぞれの NetworkPolicy
4 層モデルが完成したときに必要な NetworkPolicy を一覧で整理します。本回で実装したものと、ep18 で実装するものを区別します。
| NetworkPolicy | 許可する通信 | 実装回 |
|---|---|---|
default-deny-all | ベースライン(全拒否) | 本回(演習①) |
allow-gateway-from-external | 外部 → Gateway:443 | ep18 |
allow-frontend-from-gateway | Gateway → Frontend:80 | ep18 |
allow-backend-from-frontend | Frontend → Backend:8080 | ep18(本回の allow-backend-from-client を Frontend 向けに置換) |
allow-db-from-backend | Backend → DB:5432 | 本回(演習②) |
allow-dns | 全層 → kube-dns:53 | 本回(演習③・全層に拡張予定) |
本回で実装したのは表のうち default-deny-all / allow-db-from-backend / allow-dns と、Frontend 役の client Pod を使った allow-backend-from-client / allow-egress-to-backend です。
fanclub-api の Frontend / Gateway 層は ep18(Gateway API + Traefik + cert-manager で HTTPS 公開)で実装するため、本回の client Pod は「ep18 で Frontend Pod が担う役割」を先取りでシミュレートしたものです。
ep18 で実際の Frontend Pod が登場した時点で、allow-backend-from-client の from を role: client から実際の Frontend ラベルへ置き換えれば、本回の設計がそのまま本番の 4 層モデルに発展します。
4 層モデルが実現するセキュリティ
4 層を「直前の層からのみ受信」で連結すると、各層は飛び越し通信ができなくなります。Gateway が侵害されても攻撃者は Frontend にしか進めず、Backend や DB へ直接到達できません。Frontend が侵害されても Backend どまり、DB には触れません。「侵害された層から先へ進めない」という段階的な封じ込めが、4 層 NetworkPolicy のセキュリティ上の意味です。
第15回の RBAC(権限境界)・SecurityContext(実行境界)と組合せることで、fanclub-api は「権限・実行・通信」の 3 軸で多層防御された状態になります。
CKAD 試験頻出パターン — NetworkPolicy の速攻設計
CKAD 試験 D5「Services and Networking」では NetworkPolicy をゼロから書き起こす設問が出題されます。試験では 1 問あたり数分で解く必要があるため、頻出パターンを「キーワード → 解答テンプレート」の形で暗記しておくことが得点に直結します。
頻出パターン 4 選
| # | 設問のキーワード | 解答パターン |
|---|---|---|
| 1 | 「Pod 間通信を全拒否」「Namespace を隔離」 | default-deny-all:podSelector: {} + policyTypes: [Ingress, Egress](ingress/egress フィールドは書かない) |
| 2 | 「特定 Pod からのみ許可」 | ingress[].from に podSelector でラベル指定 + ports でポート指定 |
| 3 | 「特定 Namespace からのみ許可」 | ingress[].from に namespaceSelector で kubernetes.io/metadata.name 等のラベル指定 |
| 4 | 「Egress 制御を入れたら DNS / 名前解決が壊れた」 | egress に kube-dns 向けの UDP/53 + TCP/53 許可ルールを追加 |
YAML を素早く書き起こす起点テンプレート
NetworkPolicy には kubectl create networkpolicy のような生成コマンドがないため、YAML を手書きするか、既存リソースをコピーして編集します。試験では次の「起点テンプレート」を暗記しておき、これを書いてから設問に合わせて埋める方法が速いです。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: NAME
namespace: NS
spec:
podSelector:
matchLabels:
KEY: VALUE
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
KEY: VALUE
ports:
- protocol: TCP
port: PORTこのテンプレートの NAME / NS / KEY: VALUE / PORT を設問に合わせて置き換え、egress が必要なら policyTypes に Egress を足して egress: ブロックを追記します。describe で確認するときは kubectl describe networkpolicy NAME、一覧は kubectl get netpol(networkpolicy の短縮名は netpol)です。
速攻コマンド早見表
| 操作 | コマンド |
|---|---|
| NetworkPolicy 一覧 | kubectl get netpol |
| 適用内容の確認 | kubectl describe netpol NAME |
| 対象 Pod のラベル確認 | kubectl get pod --show-labels |
| Namespace のラベル確認 | kubectl get ns --show-labels |
| 疎通テスト(HTTP) | kubectl exec POD -- curl -s -m 5 -o /dev/null -w "%{http_code}" URL |
| 疎通テスト(ポート単位) | kubectl exec POD -- nc -z -w 5 HOST PORT |
CKAD 試験で間違えやすい落とし穴 3 選
- policyTypes の指定漏れ:
egress:ブロックを書いてもpolicyTypesにEgressを含めないと egress 制御は一切効きません。逆にpolicyTypes: [Ingress]だけのとき、誤ってegress:を書いても無視されます。「制御したい方向は必ずpolicyTypesに書く」が鉄則です - DNS 許可の書き忘れ:egress を制御する NetworkPolicy で kube-dns への UDP/TCP 53 許可を忘れると、Service 名の名前解決が壊れます。
Could not resolve hostが出たら DNS 許可を疑います。egress を制御するときはallow-dnsを必ず添える、と覚えます - 適用順序のミス(本番):稼働中のクラスタに
default-deny-allを先に適用すると、許可ルールがまだない瞬間に全通信が遮断されます。本番では allow ルールを先に適用し、最後に default-deny を入れます。試験の演習では学習目的で逆順にする場合がありますが、本番の運用とは区別します
現場ヒヤリハット 2 件
本回で扱った NetworkPolicy が、本番運用中にどのような事故を引き起こすかを 2 件取り上げます。それぞれ「背景・事故・根本原因・解決策・本番ガードレール」の 5 点セットで整理します。どちらも NetworkPolicy 運用で頻発する事故で、適用順序と DNS の落とし穴という本回の鉄則がそのまま事故防止策になります。
ヒヤリハット ①: default-deny を allow より先に本番適用して全断
背景:本番運用中の Kubernetes クラスタで「ゼロトラストネットワーク化」の施策として、各 Namespace に NetworkPolicy を導入することになった。担当者は「まず default-deny-all を全 Namespace に適用し、そこから必要な通信を許可していく」という設計を立てた。設計自体は本回でも扱った正しいゼロトラストの考え方だったが、実際の適用作業で「default-deny-all を先に apply し、allow ルールは後から順次追加する」という手順で進めてしまった。
検証環境(staging)では Pod 数が少なく、default-deny 適用後すぐに allow ルールを足したため数十秒で復旧し、問題が表面化しなかった。
事故:本番(prod)で同じ手順を実行したところ、default-deny-all(Ingress + Egress)を apply した瞬間に、その Namespace の全アプリ間通信が遮断された。アプリ A → アプリ B の API 呼び出し、アプリ → DB の接続、さらに Egress を含めたため DNS の名前解決まで全停止した。allow ルールを 1 つずつ apply していったが、prod では許可すべき通信経路が数十本あり、すべて適用し終えるまで数分かかった。
その間、サービスは外形監視でダウン判定となり、リトライ不能なリクエストがエラーになった。Egress も切れたため、許可ルール適用中にアプリが kube-dns を引けず、Pod の readinessProbe が失敗して一部 Pod が NotReady に落ちる二次被害も発生した。
根本原因:NetworkPolicy のホワイトリスト方式では「default-deny-all を適用した瞬間に、許可ルールに載っていない通信はすべて遮断される」という性質がある。default-deny-all を先に入れると、allow ルールがまだ存在しない時間帯が必ず生じ、その間は全断になる。staging では Pod 数が少なく allow ルールの本数も少なかったため全断時間が短く、事故に見えなかった。
「順序が逆でも結果は同じ」という誤解が、staging での見かけ上の成功によって補強されてしまった。
解決策:緊急対応として default-deny-all を kubectl delete networkpolicy default-deny-all で一旦削除し、全通信を復旧させた。その後、改めて「allow ルールを全部先に適用 → 最後に default-deny を適用」という正しい順序で再実施した。allow ルールを先に入れておけば、それらは default-deny がない状態では単に「許可ルールが存在するだけで何も遮断しない」状態で待機する。
最後に default-deny を入れた瞬間に「許可済の通信は残り、未許可の通信だけが遮断される」という意図通りの切り替わりが起き、全断の時間帯が生じない。
本番ガードレール:
- NetworkPolicy 導入は「allow ルールを全件先に apply → 最後に default-deny を apply」の順序を手順書に明記し、逆順を禁止する
- すべての allow ルールと default-deny を 1 つのマニフェストディレクトリにまとめ、
kubectl apply -f DIR/で一括適用する。kubectl は同一 apply 内でリソースをまとめて反映するため、allow と deny が同時に揃った状態になり全断時間帯を最小化できる - staging での検証は「prod と同じ本数の allow ルール」「prod と同程度の Pod 数」で行う。Pod 数が少ない staging での見かけ上の成功を本番適用の根拠にしない
- NetworkPolicy 適用は段階リリース(1 Namespace ずつ・トラフィックの少ない時間帯)で進め、各 Namespace 適用後に疎通監視を確認してから次へ進む
- Egress を含む default-deny を入れる Namespace では、
allow-dnsを allow ルール群の先頭に必ず含める。DNS が切れると readinessProbe / livenessProbe まで巻き込まれることを手順書に注記する
ヒヤリハット ②: Egress 制御で DNS を許可せず名前解決が全滅
背景:本番クラスタのあるアプリ Namespace で、セキュリティ監査の指摘を受けて「外向き通信(Egress)を制限する」NetworkPolicy を追加することになった。担当者は「このアプリは Backend Pod と DB Pod にしか通信しない」と整理し、Egress の許可ルールとして「Backend → DB:5432」と「Frontend → Backend:8080」の 2 本を用意した。それぞれの宛先 Pod は podSelector で正しく指定されており、ルール自体に誤りはなかった。
担当者はこの 2 本の allow ルールと、Egress を含む default-deny を同時に apply した。
事故:apply 直後、その Namespace の全 Pod が相互に通信できなくなった。Backend → DB も、Frontend → Backend も、許可ルールを書いたはずなのに疎通しない。アプリのログには java.net.UnknownHostException や could not translate host name といった名前解決エラーが大量に出力された。
curl で確認すると curl: (28) Resolving timed out が返り、Pod は Service 名を IP に変換できない状態だった。ヘルスチェックも Service 名で実装されていたため readinessProbe が失敗し、Pod が次々と NotReady に落ちてサービスが停止した。
根本原因:用意した Egress 許可ルール 2 本は「アプリ間通信」の宛先しか許可しておらず、「DNS(kube-dns への UDP/TCP 53)」の許可が抜けていた。Pod は Service 名で通信する際、まず kube-dns に名前解決を問い合わせるが、Egress の default-deny がその DNS 通信を遮断していた。
アプリ間通信のルールは正しかったが、その通信が成立する前提である「Service 名 → IP の変換」の経路を許可していなかったため、すべての通信が名前解決の段階で失敗した。「アプリが通信する宛先」だけを考え、「名前解決という見えないインフラ通信」を見落としたことが原因。
解決策:緊急対応として、kube-dns への UDP/53 と TCP/53 を許可する allow-dns NetworkPolicy を追加 apply した。kube-system ns の自動ラベル kubernetes.io/metadata.name=kube-system と CoreDNS Pod の k8s-app: kube-dns ラベルを併記した namespaceSelector + podSelector で DNS Pod を許可先に指定した。
apply 後、Pod の名前解決が復旧し、用意済だったアプリ間通信ルールが本来の意図通りに機能した。事後改善として、Egress 制御を入れるすべての Namespace で allow-dns をテンプレート化し、Egress 系 NetworkPolicy の必須コンポーネントとして手順書に組み込んだ。
本番ガードレール:
- Egress 制御を入れる NetworkPolicy には必ず
allow-dnsをセットで含める。「Egress 制御 = DNS 許可 + 宛先許可の 2 点セット」を手順書とレビューチェックリストに明記する allow-dnsを全 Namespace 共通のテンプレート YAML として用意し、Egress 系 NetworkPolicy を新規作成するときの起点にする。担当者ごとに DNS 許可ルールを書き起こさせない- Egress 制御を入れた Namespace では、apply 直後に Pod 内から Service 名での疎通テスト(
curl/nslookup)を実施し、Resolving timed outのような名前解決エラーが出ないことを確認してから次の作業に進む - ヘルスチェック(readinessProbe / livenessProbe)が Service 名や外部ホスト名を使っている場合、DNS 遮断が Probe 失敗に直結することをレビュー時に確認する。Egress 制御と Probe 設定はセットでレビューする
- NetworkPolicy の CI 検証で「Egress を制御する NetworkPolicy には DNS(53 番)許可が存在するか」を機械的にチェックする lint ルールを導入する
2 件のヒヤリハットに共通するのは「NetworkPolicy はホワイトリスト方式であるがゆえに、書き忘れた通信は静かに全遮断される」という性質です。RBAC のような権限エラー(403)は kubectl のレスポンスに明示されますが、NetworkPolicy による遮断はタイムアウトや名前解決失敗として現れ、原因の特定に時間がかかります。
本番では「適用順序(allow 先・deny 後)」と「Egress 制御時の DNS 許可」の 2 つの鉄則を手順書に組み込み、機構の表面的な適用ではなく段階適用と前提通信の考慮までセットで設計することが、NetworkPolicy 運用の肝になります。
ep16 完了後の模擬アプリ状態と第5部完走 + ep17 への橋渡し
本回で第5部「セキュリティ基礎」の最後の機構である NetworkPolicy を扱い、第5部を完走しました。ep15 の RBAC(権限境界)・SecurityContext(実行境界)に NetworkPolicy(通信境界)が加わり、fanclub-api は「権限・実行・通信」の 3 軸で多層防御された状態になります。
ep16 完了後のクラスタ状態
| リソース | 状態 |
|---|---|
| kind クラスタ | kind-control-plane Ready(v1.35.0・kindnetd v20251212) |
| Namespace 一覧 | default / kube-node-lease / kube-public / kube-system / local-path-storage(合計 5 個・ep15 完了状態と同一) |
NetworkPolicy default-deny-all | 新規追加(default ns・演習①・ingress 全拒否ベースライン) |
NetworkPolicy allow-backend-from-client | 新規追加(default ns・演習②・client → backend:8080) |
NetworkPolicy allow-db-from-backend | 新規追加(default ns・演習②・backend → db:5432) |
NetworkPolicy default-deny-egress-client | 新規追加(default ns・演習③・client の egress 全拒否) |
NetworkPolicy allow-dns | 新規追加(default ns・演習③・client → kube-dns:53) |
NetworkPolicy allow-egress-to-backend | 新規追加(default ns・演習③・client → backend:8080 の egress) |
| client Pod | 新規追加(default ns・role=client ラベル・次回以降の疎通確認用に残す) |
| fanclub-backend Deployment | replicas: 2 / 3 Probe 設定済 / RollingUpdate(継続・NetworkPolicy 適用下で正常疎通) |
| fanclub-backend Service | ClusterIP(継続) |
| fanclub-db StatefulSet | fanclub-db-0 Pod Running(PostgreSQL 18・継続・NetworkPolicy 適用下で backend から疎通可) |
| Role / RoleBinding | pod-reader / fanclub-backend-pod-reader(ep15 から継続) |
| node-logger DaemonSet | 1 Pod Running 継続 |
第5部「セキュリティ基礎」の完走
第5部はセキュリティ基礎の 2 回構成で、ep15 と ep16 で次の 3 機構を揃えました。
| 機構 | 境界 | 制御対象 | 扱った回 |
|---|---|---|---|
| RBAC | 権限境界 | SA / User が API Server に対して何を操作できるか | ep15 |
| SecurityContext | 実行境界 | コンテナプロセスの uid / FS / capabilities | ep15 |
| NetworkPolicy | 通信境界 | Pod がどこと通信できるか | ep16(本回) |
この 3 機構は CKAD ドメイン D4「Application Environment, Configuration and Security」と D5「Services and Networking」の主要 Competency をカバーします。本番では 3 機構を組合せて「侵害されても被害を 1 つの境界内に封じ込める」多層防御を構成します。
第3巻 CKS では本回の NetworkPolicy をさらに発展させ、Cilium による Pod 間 mTLS 暗号化や、L7 レベルのネットワークポリシーを扱います(次のシリーズで扱う内容のため、本巻内のリンクはありません)。
ep17 への橋渡し
第5部の完走で、第1部から第5部までの 16 回が完了しました。残るは第6部「パッケージ管理 + HTTPS 公開」の 3 回(ep17〜ep19)です。ここまでで fanclub-api は Deployment / Service / StatefulSet / ConfigMap / Secret / Probe / ResourceQuota / RBAC / SecurityContext / NetworkPolicy という多数の Kubernetes リソースで構成されるようになりました。
これらのマニフェストは現在、個別の YAML ファイルとして ~/fanclub-manifests/ に散在しています。
次の ep17「Helm v4 基礎 + fanclub-api Helm Chart 作成」では、これら散在したマニフェストを Helm Chart という 1 つのパッケージにまとめます。Helm はマニフェストをテンプレート化し、環境ごとの値(replica 数、イメージタグ、リソース量等)を values.yaml で切り替えられるパッケージマネージャです。
本回で作成した NetworkPolicy 群も含めて、fanclub-api 全体を helm install 一発でデプロイできる状態に再構成し、第6部の HTTPS 公開(ep18)と総合演習(ep19)の土台を整えます。
理解度チェック・第16回まとめ・次回予告・シリーズ一覧
理解度チェック(○×形式・9 問)
問 1:NetworkPolicy が 1 つも適用されていない Pod は、すべての通信が拒否される。
問 2:default-deny-all は podSelector: {} を指定することで、その Namespace 内の全 Pod を対象にする。
問 3:NetworkPolicy の ingress ルールは「許可」を意味し、ルールに書いていない通信は拒否される。
問 4:policyTypes に Egress を含めずに egress ルールを書いても、Egress 制御は効かない。
問 5:Egress を default-deny にすると、DNS の名前解決も切れる。
問 6:NetworkPolicy は CNI プラグインに依存せず、Kubernetes 単独でパケットを遮断(enforce)できる。
問 7:namespaceSelector を使うと、別の Namespace に属する Pod を許可元として指定できる。
問 8:複数の NetworkPolicy が同じ Pod に適用されると、許可ルールは加算(OR)され、いずれかのルールにマッチした通信が疎通する。
問 9:NetworkPolicy は L7(HTTP のパスやヘッダ等)レベルの通信制御ができる。
解答:
| 問 | 解答 | 解説 |
|---|---|---|
| 問 1 | × | NetworkPolicy が 0 個の Pod はデフォルトで全通信が許可される(フラットネットワーク)。全拒否になるのは NetworkPolicy が 1 つでも適用され、その方向の許可ルールにマッチしない場合 |
| 問 2 | ○ | podSelector: {}(空オブジェクト)は「Namespace 内の全 Pod を対象に選ぶ」を意味する。default-deny-all はこれと policyTypes の組合せで全 Pod の全拒否を実現する |
| 問 3 | ○ | NetworkPolicy はホワイトリスト方式で、ingress / egress ルールはすべて「許可」を表す。ルールに書かれていない通信は拒否される。拒否ルールという概念は存在しない |
| 問 4 | ○ | policyTypes に書いた方向だけが制御対象になる。egress ブロックを書いても policyTypes に Egress がなければ無視される。本回演習③で policyTypes: [Egress] を明示した理由 |
| 問 5 | ○ | Pod は Service 名で通信するとき kube-dns に名前解決を問い合わせる。Egress を default-deny にするとこの DNS 通信(UDP/TCP 53)も遮断され、Could not resolve host で名前解決が失敗する。本回演習③ Step 2 で実機検証した事象 |
| 問 6 | × | NetworkPolicy は Kubernetes 標準 API だが、実際にパケットを遮断する enforce は CNI プラグインが担う。CNI が NetworkPolicy 非対応(Flannel 単体等)だとルールが無視される。kindnet v20251212 は対応している |
| 問 7 | ○ | namespaceSelector は別 Namespace の Pod を許可元・許可先に指定できる。kubernetes.io/metadata.name 自動ラベルで Namespace を名前指定するのが定石。本回演習③の allow-dns で kube-system ns を指定した |
| 問 8 | ○ | NetworkPolicy は許可ルールのみで構成され、複数ポリシーは許可を加算(OR)する。いずれかのポリシーの許可ルールにマッチすれば疎通する。拒否を加算する仕組みはない |
| 問 9 | × | NetworkPolicy は L3(IP)/ L4(ポート・プロトコル)レベルの制御のみ。HTTP のパスやヘッダ、メソッド単位の L7 制御はできない。L7 制御は Gateway API や Cilium / Service Mesh の領域 |
第16回まとめ
第16回では以下を実施しました。
- NetworkPolicy の役割(Pod 間通信のホワイトリスト制御)と、デフォルトの Kubernetes ネットワークがフラット(全 Pod が相互通信可能)であることを整理した。NetworkPolicy が 0 個の Pod は全通信可、1 つでも適用されると「許可ルールに載らない通信は全拒否」というホワイトリスト方式に切り替わる挙動を明確にした。NetworkPolicy の enforce は Kubernetes 本体ではなく CNI プラグインが担い、kindnet v20251212 が NetworkPolicy 対応であることを確認した
- NetworkPolicy の YAML 構造(
podSelector/policyTypes/ingress/egress/from/to/ports)を全量で示し、「フィールド省略は全許可、空配列は全拒否」という紛らわしい挙動を表で整理した。許可元・許可先の 3 種類(podSelector/namespaceSelector/ipBlock)と、複数 from エントリの OR 条件・1 エントリ内併記の AND 条件の違いをハイフン位置で見分ける方法を整理した - ゼロトラストの起点となる
default-deny-allベースライン(podSelector: {}+policyTypes・ingress/egress フィールドなし)の YAML 構造と意味を整理し、本番では allow ルールを先に適用し最後に default-deny を入れる鉄則を確認した - 演習①で curl を備えた
clientPod を作成し、NetworkPolicy なしの HTTP 200 から、default-deny-all適用後の exit code 28(接続タイムアウト)への切り替わりを実機検証した。kubectl describe networkpolicyのSelected pods are isolated for ingress connectivity出力を確認し、fanclub-backend Pod 同士の直接通信も遮断されることでpodSelector: {}が全 Pod に作用することを確認した - 演習②で
allow-backend-from-client(client → backend:8080)とallow-db-from-backend(backend → db:5432)を段階的に適用し、ホワイトリストを 1 枚ずつ重ねて疎通を復活させた。許可していない client → fanclub-db 直接通信が遮断されたままであるネガティブテストを実施し、本番設計でも「意図しない経路が開いていないか」の確認が必須であることを整理した - Egress 制御の DNS 落とし穴を整理した。Pod が Service 名で通信するときの「名前解決(DNS への UDP/TCP 53)→ 接続」の 2 段階を示し、Egress の
default-denyが名前解決の段階を遮断する構造を明確にした。kube-system ns の自動ラベルkubernetes.io/metadata.name=kube-systemを実機で確認し、namespaceSelectorでの DNS Pod 指定の根拠を整理した - 演習③で client Pod に egress の
default-denyを適用し、Service 名 curl が exit 6(Could not resolve host)で名前解決失敗することを実機検証した。IP 直指定では exit 28(接続タイムアウト)になることを確認し、「Egress 断は名前解決で失敗・Ingress 断は接続で失敗」のエラー切り分け表を整理した。allow-dnsで名前解決を復旧(exit 6 → 28)し、allow-egress-to-backendで接続を復旧(28 → HTTP 200)して「Egress 制御は DNS 許可 + 宛先許可の 2 点セット」を確立した - fanclub-api の 4 層 NetworkPolicy 設計図(Gateway → Frontend → Backend → DB)を提示し、本回で実装した Backend / DB 層 + client(Frontend 役)と、ep18 で実装する Gateway / Frontend 層を区別した。4 層を「直前の層からのみ受信」で連結することによる段階的な封じ込めのセキュリティ意義を整理した
- CKAD 試験 D5 の頻出パターン 4 選(全拒否 / Pod 許可 / Namespace 許可 / DNS 修復)を解答テンプレートとともに整理し、NetworkPolicy の起点 YAML テンプレートと速攻コマンド早見表を試験対策として示した。間違えやすい落とし穴 3 選(
policyTypes指定漏れ / DNS 許可の書き忘れ / 適用順序ミス)を整理した - 現場ヒヤリハットを 2 件扱った。
default-deny-allを allow より先に本番適用して全断した事例、Egress 制御で DNS を許可せず名前解決が全滅した事例を、5 点セット(背景・事故・根本原因・解決策・本番ガードレール)で整理した。NetworkPolicy はホワイトリスト方式ゆえに書き忘れた通信が静かに全遮断される性質を持ち、適用順序と DNS 許可の 2 鉄則を手順書に組み込む重要性を再確認した - 第5部「セキュリティ基礎」を完走した。ep15 の RBAC(権限境界)・SecurityContext(実行境界)と本回の NetworkPolicy(通信境界)で、fanclub-api を「権限・実行・通信」の 3 軸で多層防御された状態にした
次回予告
第17回「Helm v4 基礎 + fanclub-api Helm Chart 作成」では、ここまで個別の YAML ファイルとして ~/fanclub-manifests/ に散在していた fanclub-api のマニフェスト群を、Helm Chart という 1 つのパッケージにまとめます。
Helm v4.1.4 をインストールし、Chart の基本構造(Chart.yaml / values.yaml / templates/)を整理したうえで、Deployment / Service / StatefulSet / ConfigMap / Secret / NetworkPolicy を含む fanclub-api 全体をテンプレート化します。
環境ごとに replica 数やイメージタグを切り替えられる values.yaml 設計、helm install / helm upgrade / helm rollback のリリース管理、Chart のバージョニングを扱い、第6部「パッケージ管理 + HTTPS 公開」の起点とします。CKAD ドメインで頻出する Helm の基本操作も本回でカバーします。
シリーズ一覧
第1部:コンテナと Docker
- 第1回 コンテナ技術概念 + Docker 環境準備
- 第2回 Docker 基本操作
- 第3回 Dockerfile + マルチステージビルド + JDK 25 / Payara Micro イメージビルド
- 第4回 コンテナレジストリ + イメージタグ戦略 + Trivy スキャン
第2部:Kubernetes 基礎
第3部:アプリリソース
- 第7回 Pod + Multi-container パターン
- 第8回 Service とネットワーキング
- 第9回 ストレージ(PVC + StatefulSet)+ PostgreSQL DB 追加
- 第10回 ConfigMap + Secret + ServiceAccount 基礎
- 第11回 Job + CronJob + DaemonSet
第4部:ワークロード戦略
- 第12回 Deployment + 3 Probe + Rolling Update + Probe デバッグ実践
- 第13回 Deployment 戦略補完(Blue/Green + Canary + Recreate)
- 第14回 ResourceQuota + LimitRange + Multi-tenant Namespace
第5部:セキュリティ基礎
- 第15回 RBAC + SecurityContext + Admission Controller 概念 + CRD 利用
- 第16回 NetworkPolicy 基礎 ← 今ここ
第6部:パッケージ管理 + HTTPS 公開
- 第17回 Helm v4 基礎 + fanclub-api Helm Chart 作成
- 第18回 Gateway API + Traefik + cert-manager で HTTPS 公開
- 第19回 総合演習 — fanclub-api 全機構デプロイ + CKAD 対策まとめ
