
Linuxエンジニア養成講座 第1回|全36回・フェーズ1「エンジニアのいろは」の初回です。
前回までに学んだこと: なし(シリーズ第1回)。
今回学ぶこと: インフラエンジニアの全体像と、伸びるエンジニアの学び方。
この記事は座学回です。仮想マシン(VM)の準備がまだでも問題ありません。実機操作は第4回から始まります。
この回の学習目標
- インフラエンジニアの仕事内容と担当領域を説明できる
- キャリアパス(技術軸・マネジメント軸)の選択肢を把握している
- 本講座全36回の構成とゴールイメージを理解している
- 伸びるエンジニアの4つの学習習慣を実践できる
なぜ「仕事の理解」が最初なのか
Linuxの学習というと、最初にコマンドを覚えるところから始めたくなるかもしれません。しかし、この講座では「コマンドの使い方」より先に「自分がこれからどんな仕事をする人間なのか」を知ることから始めます。
理由は単純です。目的地を知らずに歩き始めると、遠回りするからです。そしてもう一つ、もっと大事な理由があります。インフラエンジニアが学ぶ技術の多くは、サービスの利用者やチームメンバーを守るために存在します。その目的を理解しているかどうかで、同じコマンドを打っても判断の質が変わります。
たとえば chmod 755 というコマンドを丸暗記するだけでは、なぜその数字なのかがわかりません。インフラエンジニアの仕事とセキュリティの考え方を理解していれば、「このファイルは誰が読み書き実行するのか」という視点からパーミッション(ファイルへのアクセス権限)を設定できるようになります。
全36回の最初に仕事の全体像を把握しておくことで、今後学ぶ個々の技術が「何のために必要なのか」とつながります。
インフラエンジニアとは何をする人か
「見えないけど止まったら全員困る」仕事
ITインフラとは、ITサービスの基盤のことです。建物に例えると、電気・ガス・水道にあたる部分です。Webサイトや業務システムが動くための土台を構築し、維持するのがインフラエンジニアの仕事です。
具体的には以下の要素を扱います。
- サーバー — 物理サーバー・仮想サーバー・クラウドインスタンスの構築と管理
- ネットワーク — ルーター・スイッチ・ファイアウォールの設計と運用
- ストレージ — データの保存先の設計と管理
- OS — Linux や Windows Server のインストール・設定・パッチ適用
- ミドルウェア — Webサーバー(Apache/Nginx)、DB(MariaDB/PostgreSQL)などのソフトウェア
インフラが正常に動いているとき、利用者は何も気づきません。止まったときだけ注目される。「何も起きていない」状態を維持するのが仕事です。地味ですが、極めて重要な役割です。
インフラエンジニアの1日(構築フェーズ/運用フェーズ)
インフラエンジニアの仕事は、大きく「構築」と「運用」の2つのフェーズに分かれます。1日の過ごし方も異なります。
構築フェーズの1日(例)
- 09:00 — チームの朝会で進捗と今日の作業を共有
- 09:30 — 設計書をもとにサーバーのOS設定を進める
- 12:00 — 昼休憩
- 13:00 — ミドルウェア(Apacheなど)のインストールと設定
- 15:00 — テスト環境で動作確認。手順書との差異があれば修正
- 17:00 — 作業記録を整理して、翌日の作業を確認
運用フェーズの1日(例)
- 09:00 — 夜間の監視アラートを確認。異常がなければ「異常なし」の記録を残す
- 09:30 — 定期メンテナンス作業(セキュリティパッチ適用の検証)
- 11:00 — 障害チケットの対応。ログを確認し、原因を切り分ける
- 13:00 — バックアップの取得状況を確認
- 14:00 — 手順書の更新、改善提案の作成
- 16:00 — 翌月のメンテナンス計画の打ち合わせ
構築フェーズでは「作る」作業が中心で、達成感を得やすい時期です。一方、運用フェーズでは「守る」作業が中心です。どちらも現場では欠かせないものであり、新人のうちは運用フェーズからスタートすることが多いです。
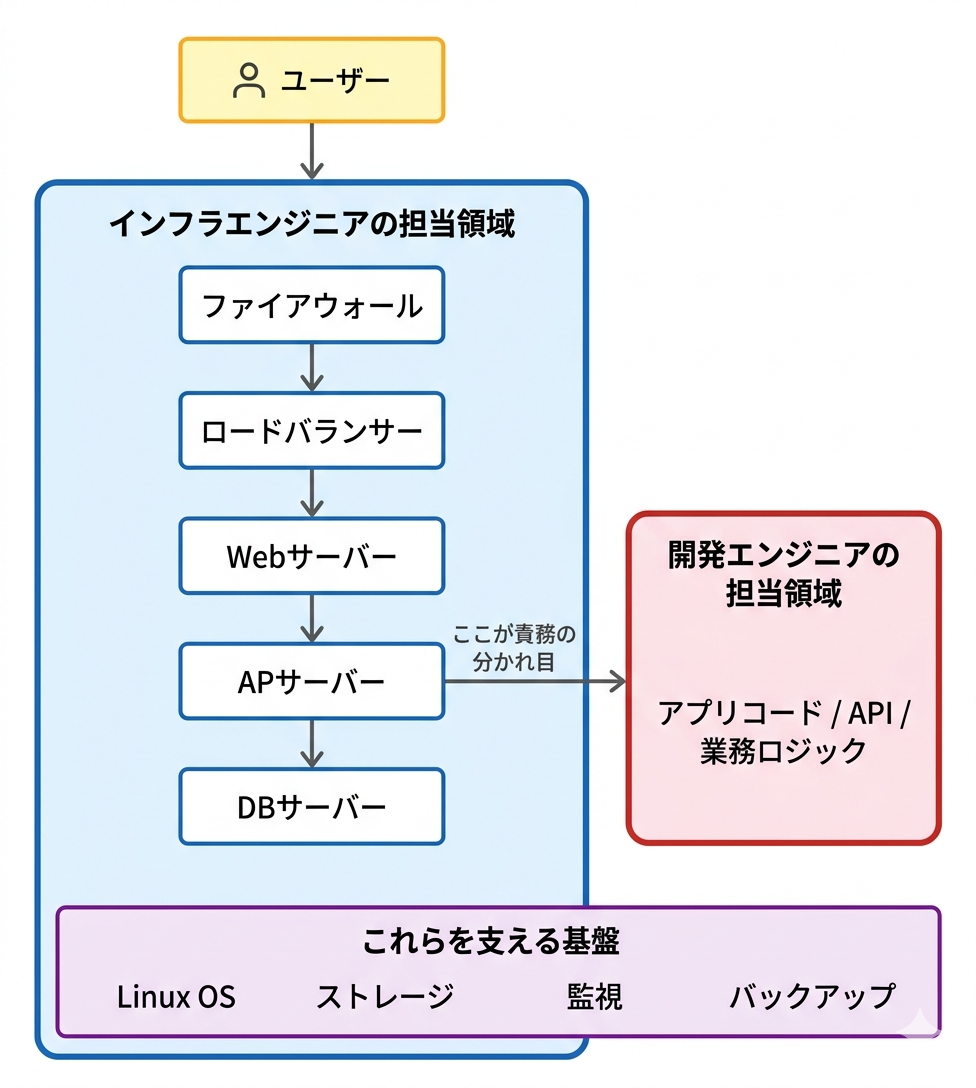
図: Webサービスを支えるインフラの全体像。青い枠内がインフラエンジニアの担当領域です。この講座では、OS(Linux)を中心に、サーバー構築・ネットワーク・ストレージ・監視・バックアップまでを一通り学びます。
開発エンジニアとの違い
「エンジニア」と聞くと、プログラミングでアプリを作る姿を思い浮かべる方も多いでしょう。開発エンジニア(アプリケーションエンジニア)とインフラエンジニアでは、役割が異なります。
どちらが上、どちらが下ということはありません。たとえるなら、開発エンジニアは「建物の中身(部屋や内装)を作る人」、インフラエンジニアは「建物の基礎や電気・水道を整える人」です。
- 主な成果物 — インフラ: サーバー環境・ネットワーク構成・設定ファイル・手順書 / 開発: アプリケーションコード・API・画面
- 使う言語 — インフラ: シェルスクリプト、Python(自動化用)、YAML(Ansible等) / 開発: Java, Python, JavaScript, Go など
- 意識する品質 — インフラ: 可用性(止まらないこと)・性能・セキュリティ / 開発: 機能の正しさ・ユーザー体験・開発速度
- 失敗の影響範囲 — インフラ: サービス全体が停止する可能性あり / 開発: 特定機能のバグに留まることが多い
- やりがい — インフラ: 「何事もなく安定稼働した」が最大の成果 / 開発: 「新機能が使われている」が成果
近年は DevOps(開発と運用の協業)や SRE(Site Reliability Engineering: サイト信頼性エンジニアリング)の考え方が広まり、両者の境界は曖昧になりつつあります。ただし、この講座ではまず「インフラの基礎」を固めることを優先します。
インフラエンジニアのキャリアパス
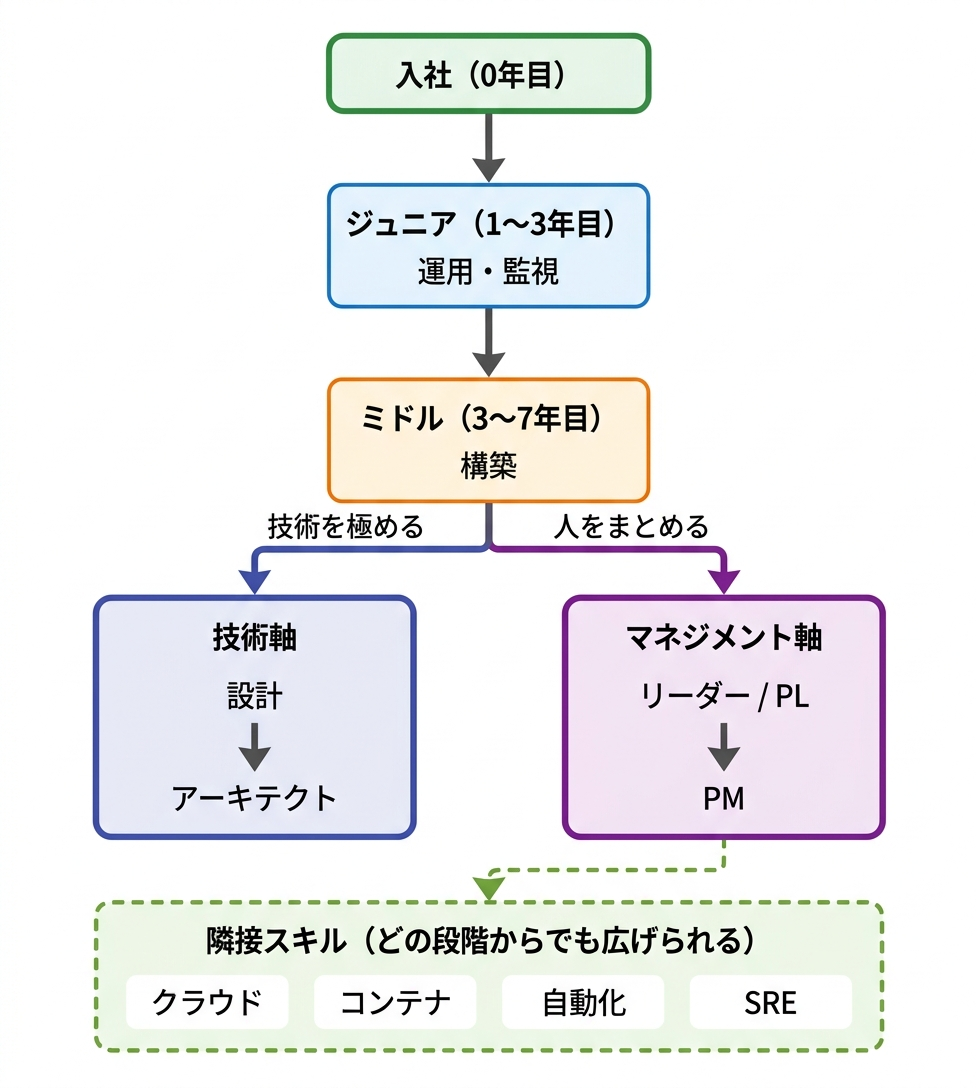
図: インフラエンジニアのキャリアパス。ミドル以降で技術軸とマネジメント軸に分岐しますが、どちらを選んでもLinuxの基礎知識は共通の土台になります。
技術軸(運用→構築→設計→アーキテクト)
インフラエンジニアの技術的な成長は、おおむね次のような段階を踏みます。
ジュニア(1〜3年目): 運用・監視からスタート
- 監視アラートの確認と一次対応
- 手順書に沿った定型作業(バックアップ取得、パッチ適用)
- 先輩の指示のもとでのサーバー構築作業
- ログの確認、上位者への報告判断
ミドル(3〜7年目): 構築・設計へステップアップ
- サーバー構築を1人で完遂できる
- 障害の根本原因分析を主導できる
- 後輩やチームメンバーへの指導
- 自動化・効率化の提案と実装
シニア(7年目〜): アーキテクチャ設計・技術選定
- システム全体のアーキテクチャ設計
- 技術選定(オンプレミス vs クラウド、ツール選定)
- 大規模障害時の指揮・判断
- 組織の技術力向上への貢献(勉強会、標準化)
年収の目安(2026年時点)
- 新卒〜ジュニア(0〜3年): 300〜400万円
- ミドル(3〜7年): 450〜650万円
- シニア(7年〜): 600〜900万円
- スペシャリスト(SRE・クラウドアーキテクト等): 800〜1,500万円
年収は企業規模・地域・保有スキルによって大きく変動します。ここに示したのはあくまで目安です。共通して言えるのは、「設計ができる」「自動化ができる」「クラウドを扱える」といったスキルが加わると、年収レンジが大きく上がるということです。
マネジメント軸(リーダー→PM)
技術を極めるだけがキャリアではありません。ミドル以降は、マネジメント方向に進む選択肢もあります。
- チームリーダー — 数名のチームをまとめ、作業の割り振りや進捗管理を担う
- プロジェクトリーダー(PL) — プロジェクト全体の技術面をリードする
- プロジェクトマネージャー(PM) — スケジュール・コスト・リスクを含むプロジェクト全体の管理
マネジメントに進んでも、インフラの技術知識は武器になります。技術がわかるリーダーは、メンバーからの信頼を得やすいですし、問題の見積もりや判断の精度が高くなります。
隣接スキル(クラウド・コンテナ・自動化)
Linuxの基礎を固めた先には、いくつかの専門領域が広がっています。
- クラウド(AWS / Azure / GCP) — オンプレミス(自社サーバー)とクラウドの両方を扱えるエンジニアは需要が高い
- コンテナ(Docker / Kubernetes) — アプリの実行環境をパッケージ化する技術。Linux の知識が前提になる
- 自動化(Ansible / Terraform) — 手作業を排除し、再現性のある構築を実現する。本講座でも第35回でAnsibleを扱う
- SRE(Site Reliability Engineering) — インフラと開発の中間領域。サービスの信頼性を定量的に管理する
どの方向に進むにしても、Linuxの基礎操作は共通の土台です。この講座で学ぶ内容は、すべてのキャリアパスにつながっています。
関連する資格としては、LPIC / LinuC(Linux技術者認定)、AWS認定資格、CCNAなどがあります。資格はゴールではなく「学習のペースメーカー」として活用するのがおすすめです。本講座を完走すれば、LPIC-1 / LinuC レベル1 の合格圏内の知識量に到達します。
この講座で目指すゴール — 36回後のあなた
全36回の4フェーズ構成
本講座は、全36回を4つのフェーズに分けて進めます。
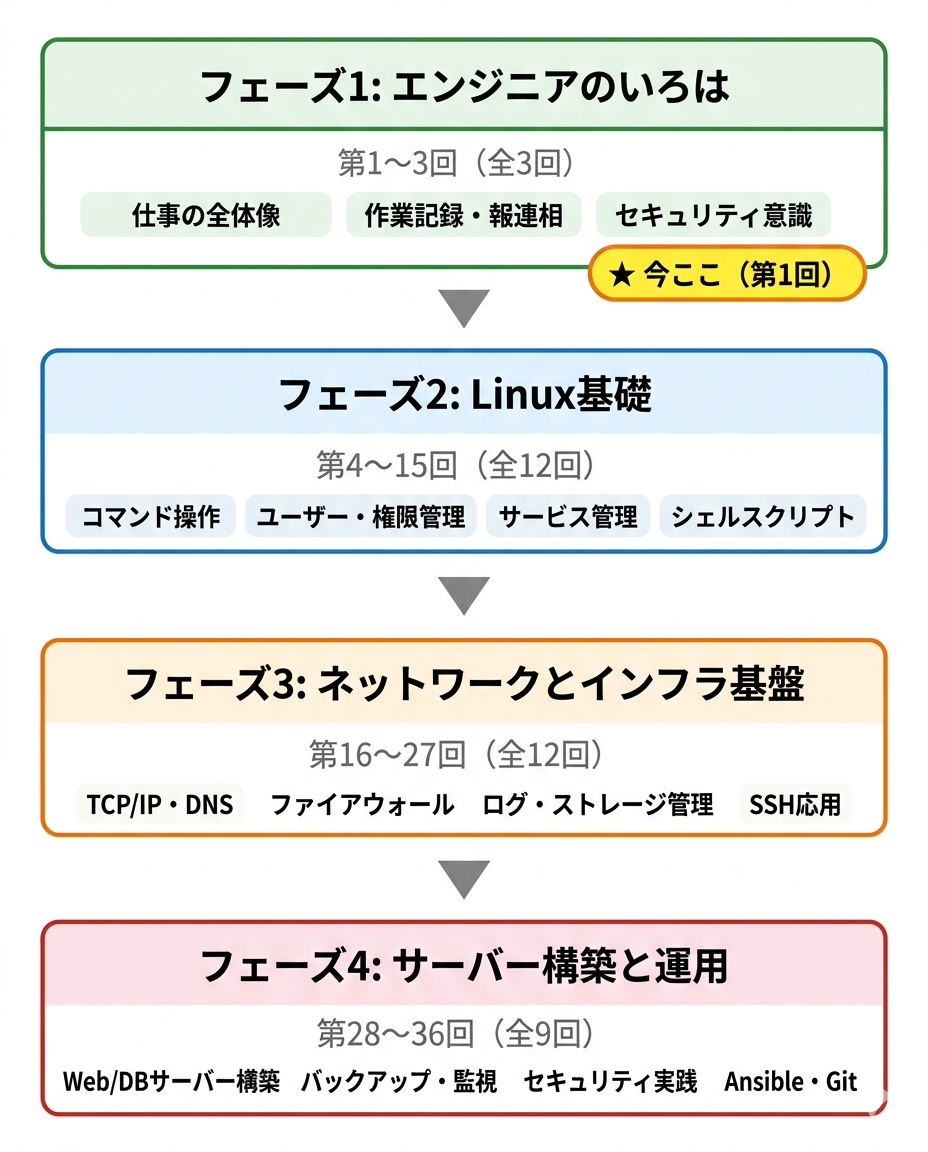
図: 本講座の4フェーズ構成。全36回を段階的に進め、最終的にサーバーの構築・運用・トラブルシューティングができるレベルを目指します。
フェーズ1: エンジニアのいろは(第1〜3回)
座学中心です。エンジニアとしての心構え、作業記録の残し方、セキュリティの基本意識を学びます。PCは必要ですが、仮想マシンは不要です。
フェーズ2: Linux基礎(第4〜15回)
仮想マシン1台(alma-main)を使い、Linuxの基本操作を身につけます。コマンド操作、ファイル管理、ユーザー管理、サービス管理、シェルスクリプトまでカバーします。
フェーズ3: ネットワークとインフラ基盤(第16〜27回)
複数の仮想マシンを使い、サーバー間の通信やネットワーク設定を学びます。ファイアウォール、ログ管理、ストレージ管理なども扱います。
フェーズ4: サーバー構築と運用(第28〜36回)
Webサーバーやデータベースの構築、バックアップ、監視、セキュリティ対策、Ansibleによる自動化まで学びます。最終回は「壊れた環境を直す」総合演習です。
ゴールイメージ
全36回を終えたとき、あなたは次のことができるようになっています。
- Linuxサーバーの初期構築を手順書なしで実施できる
- Apache + MariaDB の環境を1人で構築・設定できる
- ファイアウォール(firewalld)を要件に合わせて設定できる
- 障害発生時に「CPU → メモリ → ディスク → ネットワーク」の4リソースを確認し、原因を切り分けられる
- バックアップの設計・取得・リストア(復元)を一通り実行できる
- Ansibleで基本的な構成管理ができる
- Gitで設定ファイルの変更履歴を管理できる
実務でいうと、「先輩の指導のもと、サーバー構築プロジェクトに参画できるレベル」「夜間の監視アラート対応を1人で判断・実施できるレベル」に相当します。
もちろん、大規模環境の設計やクラウド環境の構築・運用、コンテナ技術(Docker/Kubernetes)など、この講座だけではカバーしきれない領域もあります。それでも、ここで身につける基礎があれば、どの方向にも進める土台ができあがります。
現場のヒヤリハット — 「知らなかった」では済まない話
ここで、実際の現場で起きたヒヤリハットを1つ紹介します。
ある新人エンジニアが、テスト環境で設定ファイルを変更する作業を任されました。しかし、ターミナルのタブを間違えて、本番サーバーで設定を変更してしまいました。その結果、Webサービスが数分間停止。影響を受けたユーザーは数千人でした。
原因は「ターミナルのタブを確認しなかった」というシンプルなミスです。しかし、インフラの現場では小さなミスが全体に波及します。開発でのバグが1つの機能に留まることが多いのに対し、インフラの障害はサービス全体を止めかねません。
このミスを防ぐには、どんな習慣があれば良かったと思いますか。少し考えてみてください。
インフラエンジニアの現場には「手順書を作る」「変更前にバックアップを取る」「テスト環境で検証する」「作業対象のホスト名を声に出して確認する」といった習慣が根付いています。これらは面倒に見えるかもしれませんが、自分とチームを守るための文化です。
この講座では、第2回で作業記録の残し方、第3回でセキュリティ意識の基本を学びます。技術スキルの前に、こうした「プロとしての振る舞い」を身につけることが、長く活躍するための土台になります。
エンジニアの学び方 — 伸びる人と伸びない人の違い
技術は日々進化します。新しいツール、新しいバージョン、新しいセキュリティ脅威。エンジニアの学びに「完了」はありません。ここでは、現場で伸びるエンジニアに共通する4つの習慣を紹介します。
「なぜ」を問う習慣
「このコマンドを打ってください」と言われたときに、ただ打つだけの人と、「なぜこのコマンドなのか」と考える人がいます。後者のほうが成長速度は段違いに速いです。
例を挙げます。先輩に「systemctl restart httpd を実行して」と頼まれたとします。あなたならどうしますか。少し考えてから読み進めてください。
- 言われた通りにコマンドを打って終わり — これでは半年経っても「言われたことしかできない人」のままです
- 「systemctl とは何か」「restart と reload の違いは何か」「httpd は何のサービスか」を調べる — この10分の寄り道が、半年後に知識の厚みとして返ってきます
すぐには差がつきません。しかし、半年後には知識の厚みに大きな差が生まれます。「なぜ」を問う癖をつけてください。
手を動かす>読むだけ
技術書やWebの記事を読むだけでは、知識は定着しません。「読んだ → わかった気がする → 実際にやったらできない」という経験は、誰もが通る道です。
本講座が検証環境(Hyper-V + AlmaLinux)を用意しているのは、このためです。壊しても大丈夫な環境で手を動かすことが、最も確実な学習法です。スナップショット(VMの状態を丸ごと保存する機能)を使えば、壊す前の状態にいつでも戻せます。
コマンドを打つときも、コピー&ペーストではなく、手で入力することをおすすめします。タイプミスをして、エラーを見て、直す。その繰り返しが記憶を定着させます。
エラーメッセージは宝の山
エラーが出ると焦る気持ちはわかります。しかし、エラーメッセージはシステムが「何が問題か」を教えてくれている情報源です。
たとえば、次のようなエラーが表示されたとします。
エラーメッセージ例:
Failed to start httpd.service: Unit httpd.service not found.このメッセージは「httpd.service が見つからない」と明確に伝えています。つまり、Apache(httpd)がインストールされていない可能性が高いとわかります。
エラーが出たときの行動指針は次のとおりです。
- エラーメッセージを最後まで読む(途中で諦めない)
- エラーメッセージをそのまま検索エンジンに貼り付けて検索する
- 自分の言葉で言い換えず、原文のまま検索する(関係ない情報がヒットするのを防ぐ)
- バージョン番号を検索語に含める(例: 「AlmaLinux 9 httpd not found」)
エラーは敵ではありません。原因を特定するための手がかりです。
作業ログを残す(第2回への橋渡し)
「あのとき何をやったか思い出せない」は、現場で頻繁に起きる問題です。1週間前に自分が実行したコマンドを正確に思い出せる人はほとんどいません。
だからこそ、作業ログを残す習慣が重要です。Linuxには script コマンドというターミナルの入出力を丸ごと記録するツールがあります。また、Windowsから接続する場合は、TeraTermのログ機能も使えます。
作業ログの具体的な残し方は、次回の第2回「作業記録と報連相」で詳しく扱います。今の時点では「記録を残すことが大事」ということだけ覚えておいてください。
やってみよう — 自分のキャリアマップを描く
座学回ですが、1つだけ手を動かすワークをやってみてください。紙でもテキストファイルでもかまいません。
ワーク: 3年後の自分をイメージする
以下の4つの質問に、今の正直な気持ちで答えてください。正解はありません。
- Q1. インフラエンジニアの仕事で、一番興味を持った部分はどこか(構築/運用/障害対応/設計 など)
- Q2. 技術を極めたいか、チームをまとめる側に進みたいか
- Q3. 3年後に「これができるようになりたい」と思うスキルは何か
- Q4. 今の自分に足りないと感じることは何か
このワークの目的は、答えを出すことではなく、「自分がどこに向かいたいか」を考える習慣をつけることです。半年後、1年後に同じ質問に答えると、自分の成長を実感できます。
ワーク2: インフラエンジニアを説明してみる
この記事で学んだ内容を使って、エンジニアではない友人や家族に「インフラエンジニアってどんな仕事?」と聞かれたつもりで、3〜5文で説明してみてください。専門用語を使わずに、自分の言葉で伝えることがポイントです。「学んだことを人に説明できるかどうか」は、理解度の良いバロメーターになります。
理解度チェック
以下の文が正しければ ○、間違っていれば × で答えてください。
Q1. インフラエンジニアの主な仕事は、アプリケーションのコードを書くことである。
Q2. インフラの障害は、特定の1機能だけでなくサービス全体に影響する可能性がある。
Q3. エラーメッセージが出たら、自分の言葉で要約してから検索するのが良い。
Q4. インフラエンジニアのキャリアは、技術を極める方向だけでなくマネジメント方向にも進める。
Q5. 本講座の全36回を完了すると、大規模クラウド環境の設計まで1人でできるようになる。
Q6. コマンドを実行するとき、コピー&ペーストで素早く入力するのが最も効率的な学習法である。
Q7. 先輩に頼まれたコマンドは、理由がわからなくても正確に実行できれば十分である。
答え: Q1. × / Q2. ○ / Q3. × / Q4. ○ / Q5. × / Q6. × / Q7. ×
- Q1: インフラエンジニアの主な仕事は、サーバー・ネットワーク・ストレージなどITサービスの基盤を構築・運用することです。
- Q2: インフラ障害は、そのインフラ上で動くすべてのサービスに影響する可能性があります。
- Q3: エラーメッセージは原文のまま検索するのが基本です。自分の言葉に言い換えると、関係ない情報がヒットしやすくなります。
- Q4: 技術を極めるスペシャリスト方向と、リーダー・PM方向の両方があります。
- Q5: 本講座で身につくのは「先輩の指導のもとでサーバー構築プロジェクトに参画できるレベル」です。大規模環境やクラウドは次のステップです。
- Q6: 手入力でタイプミスをして、エラーを見て、直す。その繰り返しが記憶を定着させます。コピー&ペーストでは手が覚えません。
- Q7: 「なぜ」を問う習慣が成長速度を左右します。言われた通りに打つだけでは、半年経っても応用が利きません。
まとめ
- インフラエンジニアは、ITサービスの基盤(サーバー・ネットワーク・ストレージ)を構築・運用する仕事
- 「動いて当たり前」を支える仕事であり、小さなミスが全体に波及するため、手順書・バックアップ・検証の文化が根付いている
- キャリアパスは技術軸(運用→構築→設計→アーキテクト)とマネジメント軸(リーダー→PM)に分岐する
- この講座は全36回・4フェーズ構成で、完了時には「先輩の指導のもとでサーバー構築に参画できるレベル」を目指す
- 伸びるエンジニアは「なぜ」を問い、手を動かし、エラーメッセージを読み、作業ログを残す
次回の第2回「作業記録と報連相」では、作業ログの残し方とエンジニアに求められる報連相の基本を学びます。
シリーズ一覧
フェーズ1: エンジニアのいろは(第1〜3回)
- 第1回 エンジニアの仕事と学び方
- 第2回 作業記録と報連相
- 第3回 セキュリティ意識の基本
フェーズ2: Linux基礎(第4〜15回)
- 第4回 Linuxとは何か+環境確認
- 第5回 SSH接続とターミナル操作
- 第6回 ファイルシステムとディレクトリ構造
- 第7回 基本コマンド(ファイル操作)
- 第8回 基本コマンド(テキスト処理・パイプとリダイレクト)
- 第9回 viエディタ
- 第10回 ユーザーとグループ管理
- 第11回 パーミッションと所有権
- 第12回 プロセス管理
- 第13回 systemd
- 第14回 シェルスクリプト入門
- 第15回 フェーズ2まとめ演習
フェーズ3: ネットワークとインフラ基盤(第16〜27回)
- 第16回 ネットワーク基礎
- 第17回 ネットワーク設定と疎通確認
- 第18回 企業ネットワークの仕組み
- 第19回 パッケージ管理
- 第20回 ファイアウォール(firewalld)
- 第21回 ボンディング/チーミング
- 第22回 VLAN
- 第23回 ログ管理
- 第24回 cron / systemd timer
- 第25回 ストレージ管理(LVM)
- 第26回 シェルスクリプト実践
- 第27回 SSH応用
フェーズ4: サーバー構築と運用(第28〜36回)
