
Linuxエンジニア養成講座 第8回|全36回・フェーズ2「Linux基礎」の5回目です。
前回までに学んだこと: ファイルの作成・コピー・移動・削除、find による検索、tar による圧縮・展開(第7回)。
今回学ぶこと: パイプとリダイレクト、grep によるテキスト検索、sort・uniq・cut によるデータ加工、sed・awk の基本。
この記事を読み終えると、以下のことができるようになります。
- パイプ(
|)を使って複数のコマンドを連結し、目的の情報を抽出できる - リダイレクト(
>、>>、2>&1、tee)を使ってコマンドの出力をファイルに保存できる grepでファイル内の特定の文字列を検索できるsort、uniq、cutを使ってテキストデータを加工できるsedで文字列の置換ができるawkで区切り文字付きデータから特定のフィールドを抽出できる
alma-mainにSSH接続した状態で進めます。以降のコマンドはすべてalma-main上で実行します。
なぜテキスト処理が重要なのか
Linuxでは、設定ファイルもログもコマンドの出力結果も、ほとんどが「テキスト」です。サーバーに異常が起きたとき、原因調査の第一歩はログファイルを検索することです。設定を変更するときは、テキストファイルの特定の行を書き換えます。テキストを読み取り、検索し、加工する技術は、Linuxエンジニアにとって日常的に使う基本スキルです。
現場では、たとえば「このサーバーのログに error という文字列が何回出ているか」「特定のユーザーがいつログインしたか」といった調査を、コマンド数行で即座に答えることが求められます。今回学ぶパイプとテキスト処理コマンドは、その土台となる技術です。
前回の第7回では、find | head -10 や find | xargs wc -l でパイプを使いました。あのとき「おまじない」として使った | の仕組みを、今回は正式に学びます。
なお、今回は扱うコマンドの数が多めです。すべてを暗記する必要はありません。grep とパイプの組み合わせだけ今日使えるようになれば合格です。残りのコマンドは「こういうことができる」と知っておき、必要になったときに man コマンド名 で調べて使えれば十分です。
パイプ — コマンドをつなげる仕組み
パイプとは何か
パイプ(|)は、あるコマンドの標準出力を、次のコマンドの標準入力に渡す仕組みです。ここで「標準出力」「標準入力」という新しい用語が出てきたので、まず整理します。
Linuxのコマンドには、3つのデータの流れがあります。
- 標準入力(stdin): コマンドにデータを渡す入口。キーボードからの入力がデフォルト
- 標準出力(stdout): コマンドの実行結果が流れる出口。画面に表示されるのがデフォルト
- 標準エラー出力(stderr): エラーメッセージが流れる出口。こちらも画面に表示されるのがデフォルト
標準出力と標準エラー出力は、どちらも画面に表示されるため一見区別がつきません。しかし内部では別の経路を通っています。この違いが、後ほど学ぶリダイレクトで重要になります。
以下は標準入力・標準出力・標準エラー出力の関係を図にしたものです。
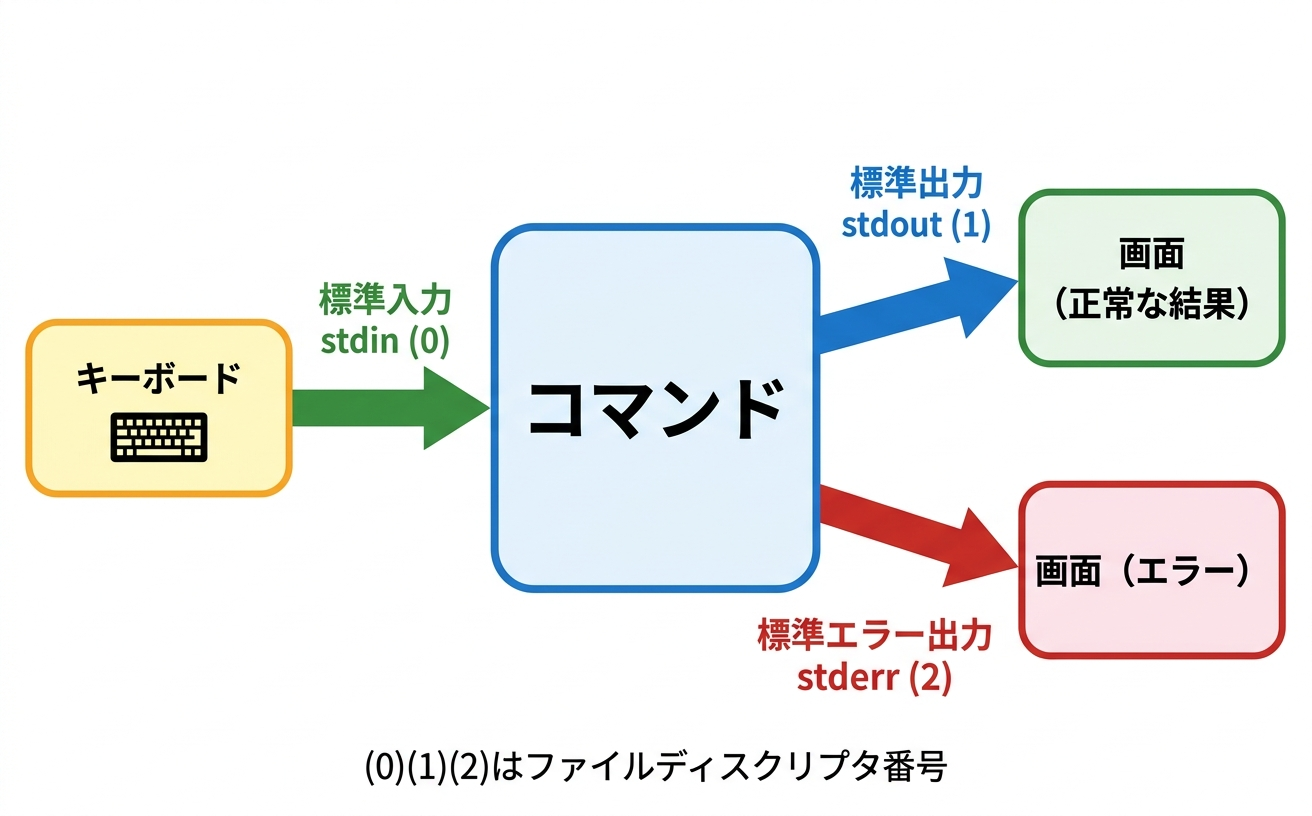
図: コマンドの3つの入出力チャネル。標準出力と標準エラー出力はどちらも画面に表示されますが、内部では別の経路です。パイプやリダイレクトで振り分けられるのはこの仕組みがあるからです。
パイプは、左側のコマンドの標準出力を右側のコマンドの標準入力に接続します。つまり、1つ目のコマンドの出力結果が、2つ目のコマンドの入力データになります。
パイプの基本例
/etc/passwd はユーザー情報が記録されたファイルです。各フィールドの意味は第10回で詳しく学びます。今は「コロン区切りのテキストデータ」として扱います。
まず、cat の出力をパイプで wc -l に渡して行数を数えます。
実行コマンド:
$ cat /etc/passwd | wc -l実行結果:
21cat /etc/passwd の出力(21行分のテキスト)が、パイプを通じて wc -l に渡されました。wc -l は受け取った行数を数えて表示します。
次に、出力をアルファベット順に並べ替えて先頭5行を表示してみます。
実行コマンド:
$ cat /etc/passwd | sort | head -5実行結果:
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chrony:x:996:996:chrony system user:/var/lib/chrony:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologincat → sort → head と、2つのパイプで3つのコマンドをつなげました。データが左から右へと順番に加工されていく流れが見えるでしょうか。
3段以上つなげる
パイプは何段でもつなげられます。/etc/passwd からユーザー名(1番目のフィールド)だけを取り出してソートしてみます。
実行コマンド:
$ cat /etc/passwd | cut -d: -f1 | sort実行結果:
adm
bin
chrony
daemon
dbus
developer
ftp
games
halt
lp
mail
nobody
operator
polkitd
root
shutdown
sshd
sssd
sync
systemd-coredump
tsscut -d: -f1 は「コロンで区切った1番目のフィールドを取り出す」という意味です。cut の詳細は後ほど解説します。ここでは「パイプを複数つなげることで、小さなコマンドを組み合わせて大きな仕事ができる」という点を押さえてください。これはUNIXの設計思想そのものです。
リダイレクト — 出力先を変える仕組み
パイプが「コマンド間のデータの橋渡し」だとすると、リダイレクトは「データの出力先を画面からファイルに切り替える」仕組みです。
>(上書き)と >>(追記)
> は標準出力をファイルに書き込みます。ファイルが既にある場合は中身を上書きします。
実行コマンド:
$ echo test > /tmp/test.txt実行コマンド:
$ cat /tmp/test.txt実行結果:
testecho test の出力(「test」という文字列)が画面ではなくファイルに書き込まれました。
>> は追記です。既存のファイルの末尾に追加します。
実行コマンド:
$ echo test2 >> /tmp/test.txt実行コマンド:
$ cat /tmp/test.txt実行結果:
test
test2「test」の下に「test2」が追記されました。> と >> の違いは、この「上書き」か「追記」かの1点です。
2> と 2>&1 — エラー出力のリダイレクト
先ほど、標準出力と標準エラー出力は別の経路だと説明しました。Linux内部では、標準入力に番号 0、標準出力に番号 1、標準エラー出力に番号 2 が割り当てられています。この番号をファイルディスクリプタと呼びます。
2> は標準エラー出力(番号2)だけをファイルにリダイレクトします。存在しないファイルを ls して、エラーを /dev/null(どこにも保存しない特殊なファイル)に捨ててみます。
実行コマンド:
$ ls /tmp/nonexistent 2>/dev/null画面には何も表示されません。本来表示されるはずのエラーメッセージが /dev/null に送られ、捨てられたためです。
次に、2>&1 を見てみます。これは「標準エラー出力を標準出力と同じ場所に合流させる」という意味です。パイプは標準出力しか次のコマンドに渡さないため、エラーメッセージもパイプで処理したい場合に使います。
実行コマンド:
$ ls /tmp/nonexistent 2>&1 | head -1実行結果:
ls: '/tmp/nonexistent' にアクセスできません: そのようなファイルやディレクトリはありません2>&1 がなければ、エラーメッセージはパイプを通らず直接画面に表示されます。2>&1 を付けることで、エラーも標準出力に合流し、パイプの先の head に渡されました。
tee — 画面にも表示しつつファイルにも保存
tee は、標準入力を受け取り、画面(標準出力)とファイルの両方に同時に書き出すコマンドです。コマンドの結果を画面で確認しながら、同時にファイルにも記録したいときに使います。
実行コマンド:
$ echo "hello world" | tee /tmp/tee_test.txt実行結果:
hello world画面に「hello world」と表示されると同時に、/tmp/tee_test.txt にも同じ内容が書き込まれています。確認してみます。
実行コマンド:
$ cat /tmp/tee_test.txt実行結果:
hello world第2回で学んだ script コマンドと同様に、作業の記録を残す場面で tee は活用されます。たとえば sudo dnf update 2>&1 | tee /tmp/update.log のように使えば、アップデートの実行結果を画面で確認しつつログにも残せます。
grep — テキストを検索する
grep は、指定した文字列を含む行を検索して表示するコマンドです。テキスト処理コマンドの中で最も使用頻度が高く、現場ではログ調査や設定ファイルの確認に毎日のように使われます。
grepの基本
/etc/passwd から「root」を含む行を検索します。
実行コマンド:
$ grep root /etc/passwd実行結果:
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin「root」という文字列を含む2行が表示されました。grep の基本構文は grep 検索文字列 ファイル名 です。
よく使うオプションをいくつか紹介します。
-i: 大文字・小文字を区別しない-n: 一致した行の行番号を表示する-c: 一致した行数だけを表示する-v: 一致しない行を表示する(除外フィルタ)-r: ディレクトリ内を再帰的に検索する
grep のオプションはここで紹介した以外にも多数あります。必要になったときに man grep で詳細を確認できます。すべてを覚える必要はなく、調べて使えることが大切です。
パイプとの組み合わせ
grep が真価を発揮するのは、パイプとの組み合わせです。他のコマンドの出力から特定の行だけを抜き出せます。
/etc/passwd からログインシェルが bash のユーザーだけを抽出してみます。
実行コマンド:
$ cat /etc/passwd | grep bash実行結果:
root:x:0:0:root:/root:/bin/bash
developer:x:1000:1000:developer:/home/developer:/bin/bashログインシェルが /bin/bash に設定されているのは root と developer の2ユーザーだけです。
次に、ログファイルの調査を体験します。/var/log/secure はSSHログインなどの認証に関するログファイルです。このファイルの閲覧には管理者権限が必要なため、sudo を付けます。
実行コマンド:
$ sudo grep "session opened" /var/log/secure | head -5実行結果:
Mar 29 00:02:17 alma-main systemd[1614]: pam_unix(systemd-user:session): session opened for user developer(uid=1000) by developer(uid=0)
Mar 29 00:02:17 alma-main sshd[1610]: pam_unix(sshd:session): session opened for user developer(uid=1000) by developer(uid=0)
Mar 29 00:02:25 alma-main sshd[1644]: pam_unix(sshd:session): session opened for user developer(uid=1000) by developer(uid=0)
Mar 29 00:02:25 alma-main sudo[1648]: pam_unix(sudo:session): session opened for user root(uid=0) by developer(uid=1000)
Mar 29 00:03:23 alma-main systemd[1675]: pam_unix(systemd-user:session): session opened for user developer(uid=1000) by developer(uid=0)「session opened」を含む行、つまりログインが成功した記録が抽出されました。grep で絞り込み、head -5 で先頭5件だけに絞る。この2段のパイプが、ログ調査の基本パターンです。
grep -c を使えば、一致した行数だけをすばやく確認できます。
実行コマンド:
$ sudo grep -c "session opened" /var/log/secure実行結果:
99「session opened」を含む行が99行あることがわかりました。ログ管理の全体像は第23回で扱います。ここでは「grep でログの中から必要な情報を探し出せる」という感覚をつかんでおいてください。
sort, uniq, cut — データを整理する
sort — 並べ替え
sort はテキストを行単位で並べ替えるコマンドです。デフォルトではアルファベット順(辞書順)にソートします。
よく使うオプションは以下の3つです。
-r: 逆順(降順)で並べ替え-n: 数値として並べ替え(文字列としての比較ではなく数値の大小で比較する)-tと-k: 区切り文字とソートキーの指定
-n がないと、「9」は「10」より後ろに来ます。辞書順では「1」の次が「10」だからです。数値で正しく並べたいときは必ず -n を付けてください。
uniq — 重複を除く
uniq は隣接する重複行を除くコマンドです。ここで注意点があります。uniq は隣り合った行同士を比較するため、事前に sort でデータを並べ替えておかないと、離れた位置にある重複が検出されません。sort と uniq はセットで使うと覚えてください。
-c オプションを付けると、各行が何回出現したかのカウントも表示します。
cut — フィールドを切り出す
cut は、区切り文字で分割されたデータから特定のフィールドを取り出すコマンドです。
-d: 区切り文字を指定する(デフォルトはタブ)-f: 取り出すフィールド番号を指定する
/etc/passwd はコロン(:)区切りのテキストです。1番目のフィールドがユーザー名なので、cut -d: -f1 でユーザー名だけを取り出せます。パイプの基本例で既に使いました。
組み合わせ実例
ここまで学んだコマンドを組み合わせて、/etc/passwd に登録されているログインシェルの使用数ランキングを作ります。
実行コマンド:
$ cat /etc/passwd | cut -d: -f7 | sort | uniq -c | sort -rn実行結果:
14 /sbin/nologin
2 /usr/sbin/nologin
2 /bin/bash
1 /sbin/shutdown
1 /sbin/halt
1 /bin/syncこのパイプラインが何をしているか、段階ごとに見てみます。
cat /etc/passwd— ファイルの全行を出力するcut -d: -f7— コロン区切りの7番目(ログインシェル)を取り出すsort— アルファベット順に並べる(uniq のために必要)uniq -c— 同じ行をまとめて出現回数を付けるsort -rn— 数値の降順(多い順)に並べ替える
/sbin/nologin が14件と最多です。これはログインが許可されていないシステム用アカウントです。/bin/bash でログインできるのは root と developer の2ユーザーだけだとわかります。小さなコマンドをパイプでつなぐだけで、このような集計ができるのがLinuxのテキスト処理の強みです。
sed — テキストを置換する
sed(stream editor)は、テキストを加工するコマンドです。最もよく使うのは文字列の置換です。
基本構文は sed 's/検索文字列/置換文字列/' です。
実行コマンド:
$ echo "hello world" | sed 's/hello/goodbye/'実行結果:
goodbye world「hello」が「goodbye」に置換されました。末尾に g を付けると(s/old/new/g)、1行の中に複数ある一致箇所をすべて置換します。g なしの場合は各行の最初の1箇所だけが対象です。
-i オプションを使うと、ファイルを直接書き換えられます。現場では、設定ファイルの値を一括で変更する場面で使われます。
実行コマンド:
$ echo "port=8080" > /tmp/sed_test.txt実行コマンド:
$ sed -i 's/8080/80/' /tmp/sed_test.txt実行コマンド:
$ cat /tmp/sed_test.txt実行結果:
port=80-i オプションによる変更は取り消せません。重要なファイルを編集する前は cp ファイル名 ファイル名.bak でバックアップを作る習慣を付けてください。sed -i.bak 's/old/new/' ファイル名 と書けば、変更前のファイルを .bak 付きのファイル名で自動的に残してくれます。
sed には他にも多くの機能がありますが、この s/old/new/ と -i を知っていれば現場の基本的な作業はこなせます。オプションの詳細は man sed で確認できます。
awk — フィールド単位で処理する
awk は、テキストをフィールド(列)単位で処理するコマンドです。cut と似ていますが、条件付きの抽出や計算もできる、より高機能なツールです。ここでは基本パターンだけを紹介します。発展的な使い方は第26回「シェルスクリプト実践」で扱います。
-F オプションで区切り文字を指定し、$1、$2 のようにフィールド番号で値を取り出します。
実行コマンド:
$ awk -F: '{print $1, $7}' /etc/passwd | head -5実行結果:
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin-F: で区切り文字をコロンに指定し、$1(ユーザー名)と $7(ログインシェル)を表示しています。cut では -f1,7 のように指定しますが、awk はフィールドをスペース区切りで自由に並べたり、条件を付けたりできる点が異なります。
条件を付けた例も見てみます。UID(3番目のフィールド)が1000以上のユーザーだけを抽出します。
実行コマンド:
$ awk -F: '$3 >= 1000 {print $1}' /etc/passwd実行結果:
nobody
developer$3 >= 1000 が条件部分で、「3番目のフィールドが1000以上」という意味です。条件に一致した行に対してだけ {print $1} が実行されます。nobody(UID 65534)と developer(UID 1000)が該当しました。
awk は奥が深いコマンドですが、今の段階では -F で区切り文字を指定して {print} でフィールドを取り出すパターンを覚えておけば十分です。オプションの詳細は man awk で確認できます。
現場のヒヤリハット — リダイレクト事故
リダイレクトの > と >> を間違えると、取り返しのつかない事故になることがあります。
ある現場で、設定ファイルの内容を確認するつもりで次のコマンドを実行した人がいました。
$ echo "確認用" > /etc/some-app/config.conf意図したのは >>(追記)でメモを追加することでしたが、>(上書き)にしてしまい、設定ファイルの中身がすべて消えて「確認用」の1行だけになりました。バックアップがなかったため、設定の復元に数時間を費やすことになりました。
防止策: 重要なファイルを操作する前は、必ず cp ファイル名 ファイル名.bak でバックアップを取る。リダイレクト先のファイルパスを打ち込む前に、そのパスが正しいか指差し確認する。この習慣が身を守ります。
やってみよう — テキスト処理の実践演習
ここまで学んだコマンドを使って、5つの演習に取り組んでみてください。すべて /tmp ディレクトリの下で作業します。
演習1: /etc/passwd からログインシェルが /bin/bash のユーザー名だけを一覧表示してください。
ヒント: grep で /bin/bash の行を絞り込み、cut でユーザー名を取り出します。
解答例
実行コマンド:
$ grep "/bin/bash" /etc/passwd | cut -d: -f1実行結果:
root
developer演習2: /var/log/secure から「session opened」を含む行数をカウントしてください。
ヒント: sudo が必要です。grep -c を使います。
解答例
実行コマンド:
$ sudo grep -c "session opened" /var/log/secure数値が表示されれば成功です。環境によって数値は異なります。
演習3: date コマンドの出力を /tmp/date_log.txt に保存してください。その後、もう一度 date の出力を同じファイルに追記し、cat で中身を確認してください。
ヒント: 1回目は >、2回目は >> を使います。
解答例
実行コマンド:
$ date > /tmp/date_log.txt
$ date >> /tmp/date_log.txt
$ cat /tmp/date_log.txt日時が2行表示されれば成功です。
演習4: /etc/passwd のユーザー名一覧をアルファベット順にソートして、/tmp/users_sorted.txt に保存してください。
ヒント: パイプとリダイレクトの組み合わせです。
解答例
実行コマンド:
$ cat /etc/passwd | cut -d: -f1 | sort > /tmp/users_sorted.txt
$ cat /tmp/users_sorted.txtアルファベット順のユーザー名一覧が表示されれば成功です。
演習5(チャレンジ): /etc/passwd の各ログインシェルの使用数を、多い順に表示してください。
ヒント: 「組み合わせ実例」で紹介したパイプラインを思い出してください。
解答例
実行コマンド:
$ cat /etc/passwd | cut -d: -f7 | sort | uniq -c | sort -rn実行結果:
14 /sbin/nologin
2 /usr/sbin/nologin
2 /bin/bash
1 /sbin/shutdown
1 /sbin/halt
1 /bin/syncクリーンアップ: 演習で作成したファイルを削除します。
実行コマンド:
$ rm /tmp/test.txt /tmp/tee_test.txt /tmp/sed_test.txt /tmp/date_log.txt /tmp/users_sorted.txt理解度チェック
以下の文が正しければ○、間違っていれば×と答えてください。
- パイプ(
|)は、左側のコマンドの標準出力を右側のコマンドの標準入力に渡す >はファイルに追記し、>>はファイルを上書きする2>&1は、標準エラー出力を標準出力と同じ場所に合流させるgrep -vは、指定した文字列を含む行だけを表示するuniqコマンドは、事前にsortしなくても離れた位置の重複行を検出できるsed 's/old/new/'は、各行の最初に一致した箇所だけを置換するawk -F: '{print $1}'は、コロン区切りの1番目のフィールドを出力する
解答
- ○ ―― パイプは左側コマンドの標準出力を右側コマンドの標準入力に接続する仕組み
- × ―― 逆。
>が上書き、>>が追記 - ○ ――
2>&1は標準エラー出力(番号2)を標準出力(番号1)にリダイレクトする - × ――
grep -vは指定した文字列を含まない行を表示する(除外フィルタ) - × ――
uniqは隣接する行の重複しか検出しない。事前のsortが必要 - ○ ――
gフラグなしでは各行の最初の一致箇所のみが置換対象 - ○ ――
-F:で区切り文字をコロンに指定し、$1で1番目のフィールドを取り出す
まとめ
今回は、テキスト処理の基本となるパイプ・リダイレクト・各種コマンドを学びました。
- パイプ(
|)で複数のコマンドをつなぎ、データを段階的に加工できる >で上書き、>>で追記。2>&1で標準エラー出力を標準出力に合流させるteeで画面表示とファイル保存を同時に行えるgrepはテキスト検索の基本。パイプと組み合わせてログ調査や設定確認に使うsort、uniq、cutでデータの並べ替え・集計・フィールド抽出ができるsedのs/old/new/でテキストの置換、-iでファイルの直接編集ができるawkの-Fと{print}でフィールド単位の抽出ができる。発展は第26回- リダイレクト事故を防ぐため、重要なファイルの操作前にはバックアップを取る
今回は「テキストを読む・検索する・加工する」を学びました。次回の第9回「viエディタ」では、テキストを「書く・編集する」ためのエディタ操作を学びます。sed -i でも一括置換はできますが、設定ファイルを対話的に編集するにはエディタが必要です。
シリーズ一覧
フェーズ1: エンジニアのいろは(第1回〜第3回)
フェーズ2: Linux基礎(第4回〜第15回)
- 第4回 Linuxとは何か+環境確認
- 第5回 SSH接続とターミナル操作
- 第6回 ファイルシステムとディレクトリ構造
- 第7回 基本コマンド(ファイル操作)
- 第8回 基本コマンド(テキスト処理・パイプとリダイレクト)(この記事)
- 第9回 viエディタ
- 第10回 ユーザーとグループ管理
- 第11回 パーミッションと所有権
- 第12回 プロセス管理
- 第13回 systemd
- 第14回 シェルスクリプト入門
- 第15回 フェーズ2まとめ演習
フェーズ3: ネットワークとインフラ基盤(第16回〜第27回)
- 第16回 ネットワーク基礎
- 第17回 ネットワーク設定と疎通確認
- 第18回 企業ネットワークの仕組み
- 第19回 パッケージ管理
- 第20回 ファイアウォール(firewalld)
- 第21回 ボンディング/チーミング
- 第22回 VLAN
- 第23回 ログ管理
- 第24回 cron / systemd timer
- 第25回 ストレージ管理(LVM)
- 第26回 シェルスクリプト実践
- 第27回 SSH応用
フェーズ4: サーバー構築と運用(第28回〜第36回)
