
Linuxエンジニア養成講座 第32回|全36回・フェーズ4「サーバー構築と運用」の5回目(5/9回目)です。
前回: 第31回で rsync・tar・mysqldump を使ったバックアップと、実際にデータを削除してから復元するリストア訓練を実践しました。
今回学ぶこと: サーバー監視の考え方から、Prometheus + node_exporter によるメトリクス収集の体験までを行います。
前回の予告で「監視の考え方から Prometheus + node_exporter による監視体験までを扱います。バックアップと合わせて、サーバー運用の両輪となる知識です」とお伝えしました。今回はその予告どおり、「なぜ監視が必要か」という本質から入り、手動確認 → 簡易スクリプト → Prometheus の三段階で監視を体験します。
この記事を読み終えると、以下のことができるようになります。
- 監視が必要な理由を「ユーザーより先に気づく」という設計思想で説明できる
- top、free、df、ss を使って CPU・メモリ・ディスク・ネットワークの4リソースを手動で確認できる
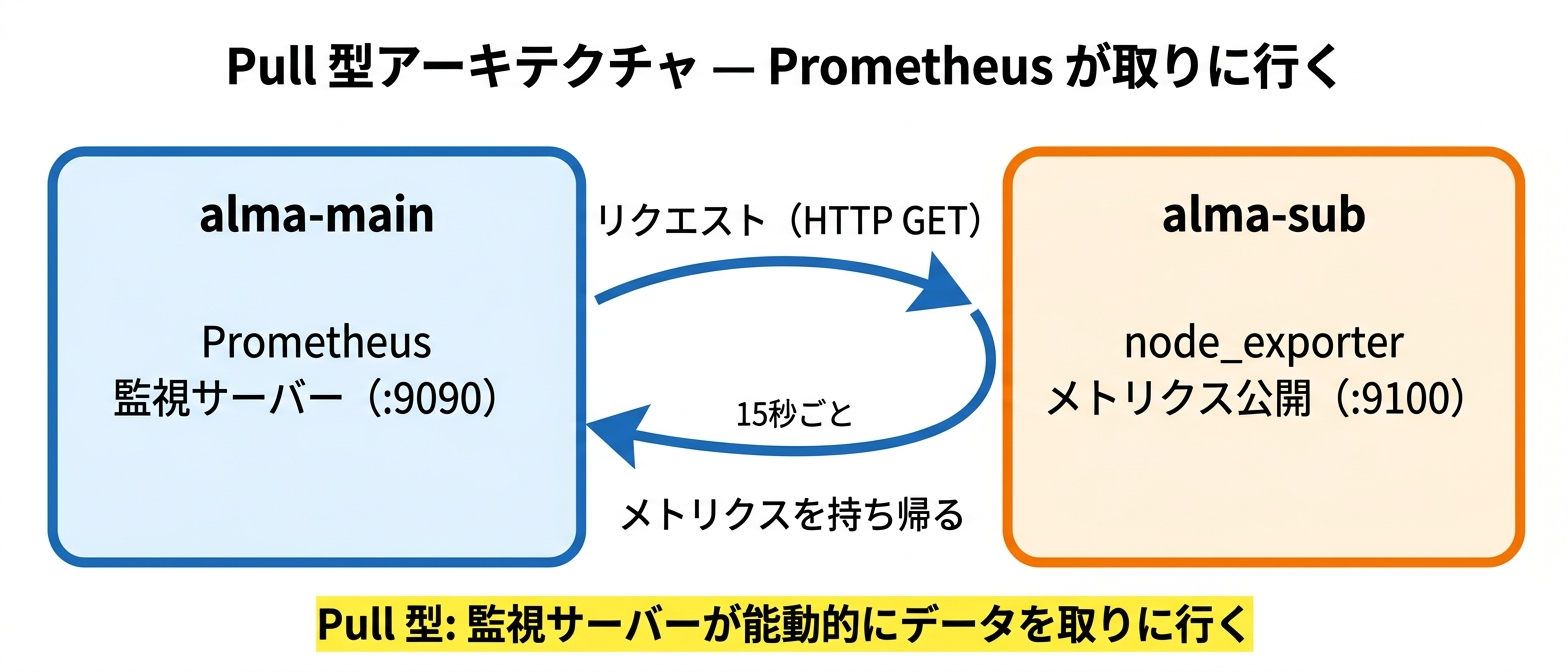
- Prometheus の Pull 型アーキテクチャの仕組みを説明できる
- node_exporter と Prometheus をバイナリ配置で導入し、メトリクス収集の動作を確認できる
- curl で Prometheus の API にクエリを投げてメトリクスを取得できる
なぜ監視が必要か
ここで1つ考えてみてください。もし監視の仕組みがなかったら、サーバーの障害に最初に気づくのは誰でしょうか。
答えは「ユーザー」です。Web サイトが表示されない、アプリが動かない、メールが届かない。そういった問い合わせや苦情が入ってから、エンジニアが「何か起きたらしい」と動き始める。これは、ユーザーに被害が出てから初めて気づいているということです。
監視の設計思想はこうです。ユーザーが気づく前に、エンジニアが検知する。CPU 使用率が急上昇している、ディスクの空き容量が減り続けている、プロセスが応答しなくなっている。こうした兆候を自動で検知し、問題が表面化する前に対処する。「ユーザーに言われて動くエンジニア」ではなく「監視で先に気づいて動くエンジニア」になる。それが監視の目的です。
監視で見る対象は多岐にわたりますが、まず押さえるべきは以下の4リソースです。
- CPU: 処理能力が足りているか。高負荷が続いていないか
- メモリ: メモリが枯渇していないか。スワップが発生していないか
- ディスク: 空き容量が十分にあるか。増加ペースは問題ないか
- ネットワーク: 通信が正常か。ポートがリッスンしているか
第12回で ps や top を使ってプロセスの状態を確認しました。あのとき「このプロセスがこのポートを使っている」という紐付けを体験しましたが、あれも監視の第一歩です。今回はそこから一歩進んで、4リソースを体系的に確認する方法と、それを自動化する仕組みを学びます。
まずは手動で確認する
監視ツールを導入する前に、手動でサーバーの状態を確認する方法を押さえておきます。ツールが何をやっているかを理解するためには、まず手で同じことをやってみるのが近道です。
CPU・メモリの概況(top)
alma-main で実行:
実行コマンド:
$ top -bn1 | head -5実行結果:
top - 16:53:25 up 45 min, 0 users, load average: 0.03, 0.02, 0.00
Tasks: 130 total, 1 running, 129 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3911.1 total, 2544.2 free, 720.2 used, 880.4 buff/cache
MiB Swap: 4040.0 total, 4040.0 free, 0.0 used. 3190.9 avail Mem-b はバッチモード(対話画面を開かずに結果を出力する)、-n1 は1回だけ実行して終了するオプションです。%Cpu(s) の行で id(アイドル)が 100.0 なら CPU はほぼ使われていません。MiB Mem の行で free と available(avail Mem)の値からメモリの空きがわかります。
メモリの詳細(free)
alma-main で実行:
実行コマンド:
$ free -h実行結果:
total used free shared buff/cache available
Mem: 3.8Gi 719Mi 2.5Gi 12Mi 880Mi 3.1Gi
Swap: 3.9Gi 0B 3.9Gi監視で注目すべきは available の値です。free ではなく available を見てください。Linux はメモリに余裕があるとき、ファイルの読み込みをキャッシュに使います(buff/cache)。このキャッシュは必要に応じて解放されるため、free が少なくても available が十分にあれば問題ありません。「free が少ない、大変だ」と慌てる前に available を確認する。これは現場でもよくある誤解です。
ディスクの空き容量(df)
alma-main で実行:
実行コマンド:
$ df -h | grep -v tmpfs | grep -v efivarfs実行結果:
ファイルシス サイズ 使用 残り 使用% マウント位置
/dev/mapper/almalinux-root 64G 2.6G 61G 5% /
/dev/sda2 960M 199M 762M 21% /boot
/dev/sda1 599M 7.1M 592M 2% /boot/efi
/dev/mapper/almalinux-home 31G 254M 31G 1% /home使用% が 80% を超えたら注意、90% を超えたら危険と考えてください。ディスクが 100% になると、ログが書けなくなったり、データベースが停止したり、あらゆるサービスに影響が波及します。第6回で df コマンドを初めて使いましたが、監視の文脈では「いま何%か」だけでなく「増加ペースがどうか」も重要です。これは後ほど Prometheus で継続的に記録する話につながります。
リッスンポートの確認(ss)
alma-main で実行:
実行コマンド:
$ sudo ss -tlnp実行結果(抜粋):
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=xxx,fd=3))このコマンドで、どのプロセスがどのポートで待ち受けているかを確認できます。サービスが起動しているはずなのにポートがリッスンしていなければ、何か問題が起きています。第12回で ss コマンドを紹介したとき「このプロセスがこのポートを使っている」という紐付けを体験しましたが、監視でもこの確認は基本中の基本です。
ここまでの4つのコマンドで、CPU・メモリ・ディスク・ネットワークの概況をひととおり確認できます。しかし、これを人間が24時間365日手動で実行し続けることは不可能です。だから自動化します。
簡易スクリプトによる監視
第26回でディスク使用率をチェックするシェルスクリプトを作り、第24回の cron と組み合わせて定期実行する方法を学びました。あの仕組みは立派な監視です。
スクリプト監視の強みは、仕組みが単純でわかりやすいことです。df の出力を解析して閾値を超えたらメールやログに書き出す。自分で作ったので中身が完全に理解できる。サーバーが1〜2台の規模なら、これで十分に運用できます。
しかし、サーバーが10台、50台、100台と増えていくとどうなるでしょうか。各サーバーにスクリプトを配布して、cron を設定して、結果をどこかに集約して、閾値を変えたければ全台に反映して。管理コストが台数に比例して増えていきます。さらに「過去30分のCPU使用率の推移を見たい」「1週間前のディスク使用量と比較したい」といった時系列データの記録・参照は、スクリプトだけでは対応が難しくなります。
そこで登場するのが、専用の監視ツールです。
Prometheus + node_exporter の仕組み
Prometheus(プロメテウス)は、オープンソースの監視ツールです。Cloud Native Computing Foundation(CNCF)のプロジェクトとして開発されており、Kubernetes 環境での監視で特に広く使われています。今回は Kubernetes は関係ありませんが、Linux サーバーの監視にも使えます。
Prometheus の特徴的な仕組みは Pull 型のメトリクス収集です。
- Push 型: 監視対象のサーバーが自分から監視サーバーにデータを送信する
- Pull 型: 監視サーバー(Prometheus)が定期的に監視対象からデータを取りに行く
なぜ Pull 型なのか。理由は2つあります。1つ目は、監視対象の追加・削除が柔軟にできること。新しいサーバーを追加するときは、Prometheus 側の設定ファイルに対象を追記するだけです。監視対象のサーバー側に「どこに送るか」の設定を入れる必要がありません。2つ目は、設定を監視サーバー側で一元管理できること。「何秒間隔で取得するか」「どのメトリクスを取るか」をすべて Prometheus 側でコントロールできます。
Prometheus がメトリクスを取りに行く先にいるのが node_exporter(ノード・エクスポーター)です。node_exporter は監視対象のサーバーで動くエージェントで、CPU使用率、メモリ使用量、ディスクI/O、ネットワークトラフィックなどのメトリクスを HTTP で公開します。Prometheus は定期的に node_exporter の HTTP エンドポイント(デフォルトはポート 9100)にアクセスして、メトリクスを取得・記録します。
今回の構成は以下のとおりです。
- alma-main(10.0.1.1): Prometheus を配置。15秒間隔で node_exporter からメトリクスを取得する
- alma-sub(10.0.1.3): node_exporter を配置。ポート 9100 でメトリクスを公開する
Prometheus と node_exporter はどちらも Go 言語で書かれたシングルバイナリです。AlmaLinux の標準リポジトリ(BaseOS / AppStream)にも EPEL にも含まれていないため、dnf ではインストールできません。GitHub のリリースページからバイナリをダウンロードして配置します。Go 製のシングルバイナリは依存ライブラリがなく、ファイルを置いて実行するだけで動きます。
なお、Prometheus にはアラート通知を担当する Alertmanager というコンポーネントもあります。メトリクスが閾値を超えたときにメールや Slack に通知を送る仕組みですが、今回はスコープ外とします。まずは「メトリクスを収集して記録する」という監視の基本部分を体験することに集中します。
前提準備
Prometheus と node_exporter のバイナリは GitHub からダウンロードします。検証環境では alma-proxy(Squid)経由でインターネットに接続しているため、GitHub のリリースファイル配信元をホワイトリストに追加する必要があります。
Squid ホワイトリストの更新(alma-proxy)
alma-main で実行(alma-proxy に接続):
実行コマンド:
$ ssh developer@192.168.1.123alma-proxy にログインしたら、ホワイトリストにドメインを追加します。
実行コマンド:
$ echo "release-assets.githubusercontent.com" | sudo tee -a /etc/squid/whitelist.txt追加したら Squid を再読み込みします。
実行コマンド:
$ sudo systemctl reload squidGitHub のリリースファイルは github.com から objects.githubusercontent.com や release-assets.githubusercontent.com にリダイレクトされます。github.com と objects.githubusercontent.com は既に登録済みですが、release-assets.githubusercontent.com が未登録だとダウンロードが失敗します。作業が終わったら alma-proxy からログアウトしてください。
alma-sub の firewalld 設定
Prometheus(alma-main)が node_exporter(alma-sub)のポート 9100 にアクセスできるよう、alma-sub 側の firewalld でポートを許可します。第20回で学んだ firewalld の復習です。
alma-main で実行(alma-sub に接続):
実行コマンド:
$ ssh developer@10.0.1.3alma-sub で以下を実行します。
実行コマンド:
$ sudo firewall-cmd --add-port=9100/tcp --permanent実行コマンド:
$ sudo firewall-cmd --reload実行コマンド:
$ sudo firewall-cmd --list-ports実行結果に 9100/tcp が含まれていれば設定完了です。--permanent で永続設定を追加し、--reload で反映する。この手順は第20回で学んだとおりです。確認が終わったら alma-sub からログアウトして alma-main に戻ります。
node_exporter をデプロイする(alma-sub)
まず監視対象である alma-sub に node_exporter を配置します。ダウンロードは alma-main で行い、scp で alma-sub に転送します。
ダウンロードと転送
alma-main で実行:
curl で GitHub からダウンロードするため、プロキシの環境変数を設定します。dnf は dnf.conf のプロキシ設定を参照しますが、curl は参照しないため、別途指定が必要です。
実行コマンド:
$ export https_proxy=http://10.0.1.254:3128実行コマンド:
$ curl -sL -o /tmp/node_exporter.tar.gz "https://github.com/prometheus/node_exporter/releases/download/v1.8.2/node_exporter-1.8.2.linux-amd64.tar.gz"-s は進捗表示を抑制、-L はリダイレクトに追従するオプションです。GitHub のリリースファイルはリダイレクトされるため、-L がないとダウンロードに失敗します。
実行コマンド:
$ tar xzf /tmp/node_exporter.tar.gz -C /tmp/展開されたディレクトリの中にバイナリがあります。これを scp で alma-sub に転送します。
実行コマンド:
$ scp /tmp/node_exporter-1.8.2.linux-amd64/node_exporter developer@10.0.1.3:/tmp/配置と起動
alma-sub にログインして、バイナリを配置します。
alma-main で実行(alma-sub に接続):
実行コマンド:
$ ssh developer@10.0.1.3実行コマンド:
$ sudo mkdir -p /opt/node_exporter実行コマンド:
$ sudo cp /tmp/node_exporter /opt/node_exporter/実行コマンド:
$ sudo chmod +x /opt/node_exporter/node_exporterバージョンを確認します。
実行コマンド:
$ /opt/node_exporter/node_exporter --version実行結果:
node_exporter, version 1.8.2node_exporter を起動します。ここで nohup を使います。
実行コマンド:
$ sudo nohup /opt/node_exporter/node_exporter > /tmp/node_exporter.log 2>&1 &&(バックグラウンド実行)だけでは、SSH セッションを切断するとプロセスが停止します。nohup を付けることで、セッション切断後もプロセスが動き続けます。標準出力と標準エラー出力をログファイルにリダイレクトしているのは、nohup のデフォルト出力先(nohup.out)を明示的に制御するためです。
ポートがリッスンしているか確認します。
実行コマンド:
$ sudo ss -tlnp | grep 9100実行結果:
LISTEN 0 4096 *:9100 *:* users:(("node_exporter",pid=xxxx,fd=3))ポート 9100 で node_exporter がリッスンしています。メトリクスが取得できるか確認します。
実行コマンド:
$ curl -s http://localhost:9100/metrics | head -3実行結果:
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0# HELP で始まる行がメトリクスの説明、# TYPE で始まる行がデータ型、そしてメトリクス名と値が続きます。これが node_exporter が公開しているメトリクスです。Prometheus はこの HTTP エンドポイントに定期的にアクセスして、すべてのメトリクスを収集します。
確認が終わったら、alma-sub からログアウトして alma-main に戻ります。
Prometheus をデプロイする(alma-main)
ダウンロードと配置
alma-main で実行:
プロキシの環境変数が未設定の場合は、先ほどと同じ export https_proxy=http://10.0.1.254:3128 を実行してください(同じターミナルセッションであれば設定済みです)。
実行コマンド:
$ curl -sL -o /tmp/prometheus.tar.gz "https://github.com/prometheus/prometheus/releases/download/v2.54.1/prometheus-2.54.1.linux-amd64.tar.gz"実行コマンド:
$ tar xzf /tmp/prometheus.tar.gz -C /tmp/実行コマンド:
$ sudo mkdir -p /opt/prometheus実行コマンド:
$ sudo cp /tmp/prometheus-2.54.1.linux-amd64/prometheus /opt/prometheus/実行コマンド:
$ sudo cp /tmp/prometheus-2.54.1.linux-amd64/promtool /opt/prometheus/promtool は設定ファイルの検証に使うツールです。一緒にコピーしておきます。実行権限を明示的に付与します。
実行コマンド:
$ sudo chmod +x /opt/prometheus/prometheus /opt/prometheus/promtoolバージョンを確認します。
実行コマンド:
$ /opt/prometheus/prometheus --version実行結果:
prometheus, version 2.54.1設定ファイルの作成
Prometheus の設定ファイルは YAML(ヤムル)形式です。YAML は設定ファイルでよく使われるフォーマットで、以下の2点だけ覚えてください。
- インデントはスペースで行う。タブ文字を使うとエラーになる
- コロンの後にスペースを入れる。
key: valueの形式で書く
vi で設定ファイルを作成します。
alma-main で実行:
実行コマンド:
$ sudo vi /opt/prometheus/prometheus.yml以下の内容を記述します。
global:
scrape_interval: 15s
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node"
static_configs:
- targets: ["10.0.1.3:9100"]設定の意味を整理します。
scrape_interval: 15s: 15秒ごとにメトリクスを取得するjob_name: "prometheus": Prometheus 自身のメトリクスを監視する設定。Prometheus も自分自身の状態をメトリクスとして公開しているjob_name: "node": alma-sub の node_exporter(10.0.1.3:9100)からメトリクスを取得する設定
設定ファイルの構文チェックができます。promtool を使います。
実行コマンド:
$ /opt/prometheus/promtool check config /opt/prometheus/prometheus.ymlSUCCESS と表示されれば構文に問題はありません。YAML のインデントを間違えた場合はここでエラーが出ます。エラーメッセージに行番号が表示されるので、該当行のインデントを確認してください。
Prometheus の起動
alma-main で実行:
実行コマンド:
$ sudo nohup /opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/tmp/prometheus-data > /tmp/prometheus.log 2>&1 &--config.file で設定ファイルを指定し、--storage.tsdb.path でメトリクスの保存先を指定します。TSDB は Time Series Database(時系列データベース)の略で、Prometheus が内部で持っているデータ保存の仕組みです。
ポートがリッスンしているか確認します。
実行コマンド:
$ sudo ss -tlnp | grep 9090実行結果:
LISTEN 0 4096 *:9090 *:* users:(("prometheus",pid=xxxx,fd=7))ポート 9090 で Prometheus がリッスンしています。正常に起動しました。
メトリクスを確認する
Prometheus が node_exporter からメトリクスを正常に取得できているか確認します。Prometheus は API を提供しており、curl でアクセスできます。
ターゲットの状態を確認する
alma-main で実行:
実行コマンド:
$ curl -s http://localhost:9090/api/v1/targets | python3 -m json.tool | head -30python3 -m json.tool は JSON を見やすく整形するコマンドです。出力の中で注目すべきは "health": "up" の部分です。これは Prometheus がそのターゲットからメトリクスを正常に取得できていることを意味します。"job": "node" のターゲットが "up" になっていれば、alma-sub の node_exporter との通信が成功しています。
もし "health": "down" と表示された場合は、以下を確認してください。
- alma-sub で node_exporter が起動しているか(
ssh developer@10.0.1.3 "ss -tlnp | grep 9100") - alma-sub の firewalld で 9100/tcp が許可されているか(
ssh developer@10.0.1.3 "sudo firewall-cmd --list-ports") - alma-main から alma-sub に疎通できるか(
ping -c 1 10.0.1.3)
メトリクスを眺めてみる
node_exporter がどんなメトリクスを公開しているか、alma-main から直接アクセスして眺めてみてください。
alma-main で実行:
実行コマンド:
$ ssh developer@10.0.1.3 "curl -s http://localhost:9100/metrics | grep -E '^node_' | head -20"node_ で始まるメトリクスが node_exporter 固有のメトリクスです。node_cpu_seconds_total、node_memory_MemTotal_bytes、node_filesystem_avail_bytes など、先ほど手動で確認した4リソースに対応するメトリクスが並んでいるのがわかります。手動で top や free を叩いて確認していた情報が、HTTP 経由で機械的に取得できる形になっている。これが監視ツールの強みです。
現場のヒヤリハット: firewalld でブロックされて target が down
ヒヤリハット: 監視ツールを入れたのにデータが取れない
ある現場で、監視対象のサーバーに node_exporter を導入し、Prometheus の設定も追加したのに、ターゲットがずっと down のまま。node_exporter 自体は正常に起動しており、監視対象のサーバー上で curl http://localhost:9100/metrics を叩くとメトリクスが返ってくる。原因は firewalld でした。9100/tcp を許可していなかったため、Prometheus サーバーからのアクセスがブロックされていたのです。
「localhost では動くのに外部からアクセスできない」というパターンは、firewalld が原因であることが多いです。新しいサービスをデプロイしたら、そのポートが firewalld で許可されているかを確認する。第20回で学んだこの習慣が、ここでも生きてきます。
やってみよう
Prometheus の API にクエリを投げて、alma-sub のメモリ総量を取得してみてください。
課題: curl で Prometheus の /api/v1/query エンドポイントにクエリを投げ、node_memory_MemTotal_bytes の値を確認する。
ヒント: Prometheus の API は以下の形式でクエリを受け付けます。
$ curl -s "http://localhost:9090/api/v1/query?query=メトリクス名" | python3 -m json.toolメトリクス名 の部分を node_memory_MemTotal_bytes に置き換えて実行してください。返ってくる JSON の "value" にバイト単位の値が入っています。alma-sub のメモリは 2GB なので、おおよそ 2,000,000,000(20億)前後の値になるはずです。
余裕があれば、node_filesystem_avail_bytes(ディスクの空き容量)や node_cpu_seconds_total(CPU使用時間の累積)なども試してみてください。--help の代わりに ssh developer@10.0.1.3 "curl -s http://localhost:9100/metrics | grep '# HELP node_'" でメトリクスの説明を調べることもできます。
クリーンアップ
今回起動した Prometheus と node_exporter は nohup で動かしているため、手動で停止する必要があります。
alma-main で実行:
実行コマンド:
$ sudo pkill prometheus実行コマンド:
$ sudo ss -tlnp | grep 9090何も表示されなければ停止しています。
alma-main で実行:
実行コマンド:
$ ssh developer@10.0.1.3 "sudo pkill node_exporter"配置したバイナリと一時ファイルも削除します。
実行コマンド:
$ sudo rm -rf /opt/prometheus /tmp/prometheus.tar.gz /tmp/prometheus-2.54.1.linux-amd64 /tmp/prometheus-data /tmp/prometheus.log実行コマンド:
$ ssh developer@10.0.1.3 "sudo rm -rf /opt/node_exporter /tmp/node_exporter /tmp/node_exporter.log"本番環境では systemd のユニットファイルを作成して管理するのが一般的ですが、今回は監視の仕組みを体験することが目的なので、nohup による手動起動としました。
まとめと次回予告
今回のポイントを3つにまとめます。
- 監視の本質は「ユーザーが気づく前にエンジニアが検知する」こと。CPU・メモリ・ディスク・ネットワークの4リソースが基本
- Prometheus は Pull 型で、監視対象の node_exporter から定期的にメトリクスを HTTP で取得する。設定を監視サーバー側で一元管理できるのが利点
- 手動確認 → スクリプト監視 → 監視ツールという段階を理解することで、ツールが何をやっているかの本質がわかる。ツールはあくまで手動作業の自動化・効率化
前回のバックアップと今回の監視は、サーバー運用の両輪です。バックアップは「障害が起きた後の復旧手段」、監視は「障害が起きる前の検知手段」。どちらが欠けても、安定した運用はできません。
次回は第33回「セキュリティ実践」です。CVE の読み方、dnf update --security によるセキュリティアップデート、fail2ban や aide を使ったセキュリティ対策を扱います。第3回で学んだセキュリティ意識の基本を、具体的なツールと手順で実践する回です。
理解度チェック
今回の内容を○×形式で確認します。
問1: 監視の仕組みがなければ、サーバー障害に最初に気づくのはユーザーである。
→ ○。監視がなければ、サービスの異常に気づくのは利用者からの問い合わせが最初になる。監視の目的は、ユーザーが気づく前にエンジニアが検知すること。
問2: free -h の出力で、メモリに余裕があるかを判断するには free 列ではなく available 列を見る。
→ ○。Linux はメモリに余裕があるときバッファ/キャッシュとして活用するため、free が少なくても available が十分にあれば問題ない。
問3: Prometheus は Push 型のアーキテクチャで、監視対象が自分からデータを送信する。
→ ×。Prometheus は Pull 型。Prometheus が定期的に監視対象(node_exporter)からメトリクスを取りに行く。設定を監視サーバー側で一元管理できるのが利点。
問4: Prometheus と node_exporter は AlmaLinux の標準リポジトリに含まれており、dnf install でインストールできる。
→ ×。Prometheus も node_exporter も標準リポジトリには含まれていない。GitHub からバイナリをダウンロードして配置する。Go 製のシングルバイナリで、依存ライブラリなしで動作する。
問5: node_exporter をサーバーに導入しても、firewalld でポート 9100 を許可していなければ、Prometheus はメトリクスを取得できない。
→ ○。Prometheus は HTTP でメトリクスを取得するため、firewalld でポートがブロックされていると通信できない。新しいサービスをデプロイしたら firewalld の設定を確認する習慣が重要。
問6: nohup を付けずに & だけでバックグラウンド実行したプロセスは、SSH セッションを切断しても動き続ける。
→ ×。& だけではセッション切断時に SIGHUP シグナルが送られてプロセスが停止する。nohup を付けることでセッション切断後もプロセスが動き続ける。
シリーズ一覧
フェーズ1: エンジニアのいろは
フェーズ2: Linux基礎
- 第4回 Linuxとは何か+環境確認
- 第5回 SSH接続とターミナル操作
- 第6回 ファイルシステムとディレクトリ構造
- 第7回 基本コマンド(ファイル操作)
- 第8回 基本コマンド(テキスト処理・パイプとリダイレクト)
- 第9回 viエディタ
- 第10回 ユーザーとグループ管理
- 第11回 パーミッションと所有権
- 第12回 プロセス管理
- 第13回 systemd
- 第14回 シェルスクリプト入門
- 第15回 フェーズ2まとめ演習
フェーズ3: ネットワークとインフラ基盤
- 第16回 ネットワーク基礎
- 第17回 ネットワーク設定と疎通確認
- 第18回 企業ネットワークの仕組み
- 第19回 パッケージ管理
- 第20回 ファイアウォール(firewalld)
- 第21回 ボンディング/チーミング
- 第22回 VLAN
- 第23回 ログ管理
- 第24回 cron / systemd timer
- 第25回 ストレージ管理(LVM)
- 第26回 シェルスクリプト実践
- 第27回 SSH応用
フェーズ4: サーバー構築と運用
