
プロジェクトが成功するかどうかは、品質管理の徹底度にかかっています。納期に間に合わせることは重要ですが、品質を犠牲にすると後で大きなトラブルに発展するケースは少なくありません。
「リリース後に重大なバグが発覚し、炎上した」「開発中に品質チェックが不十分で、テストフェーズで大量の手戻りが発生した」「システムは動くが、ユーザーからは使いにくいと不満が出る」――このような問題を防ぐには、品質を開発プロセスの初期段階から確保する仕組みが必要です。
本記事では、「品質の種類と管理手法」「PMの品質管理の役割」「リリース判断の基準」という3つの視点から、品質管理とデリバリーの実践的な手法を解説します。
目次
1. 「動くものを納品すればOK」ではない
多くのITプロジェクトで、「とりあえず動けばOK」「納期優先で後から直せばいい」という考えが見られます。しかし、この姿勢は納品後のトラブル増加や運用コストの膨大化につながります。クライアントやユーザーの信頼喪失にも直結するため、品質の重要性を正しく理解する必要があります。
1-1. 品質とは「バグがないこと」だけではない
「品質=バグの少なさ」は誤解です。実際にはソフトウェアの品質には以下のような要素が含まれます。
機能品質(Functional Quality)
- 仕様通りに動作するか(バグがないか)
- 期待した結果を正確に出力するか
パフォーマンス品質(Performance Quality)
- レスポンスタイムが許容範囲内であるか
- 高負荷時にも安定した動作を維持できるか
ユーザビリティ(Usability)
- 直感的に使いやすいか
- UI/UXが分かりやすく、ストレスなく操作できるか
セキュリティ品質(Security Quality)
- 想定される脅威から適切に防御されているか
- データの機密性・完全性・可用性が確保されているか
拡張性・保守性(Maintainability & Scalability)
- 今後の機能追加や変更が容易にできる設計になっているか
- ソースコードが適切に整理されており、第三者が理解しやすいか
単に「エラーが出ない」だけでは、品質が高いとは言えません。
「動くけど使いにくい」「仕様通りだけど遅い」は問題です。たとえば、以下のようなケースがあります。
ケース1:レスポンスが遅すぎるシステム
- ユーザーがボタンをクリックしてから画面更新まで10秒かかる。
- バグはないが、遅くて使いものにならない状態です。
ケース2:UI/UXが不親切なシステム
- エラーメッセージが適切に表示されず、ユーザーが対処法を判断できない。
- 機能は実装されているが、直感的に使えない状態です。
ケース3:セキュリティが考慮されていないシステム
- 入力フォームでSQLインジェクション対策が施されておらず、攻撃者がデータを盗める。
- 表面的には正常に動いているが、脆弱性がある状態です。
これらはすべて、「とりあえず動けばOK」と考えた結果として発生します。
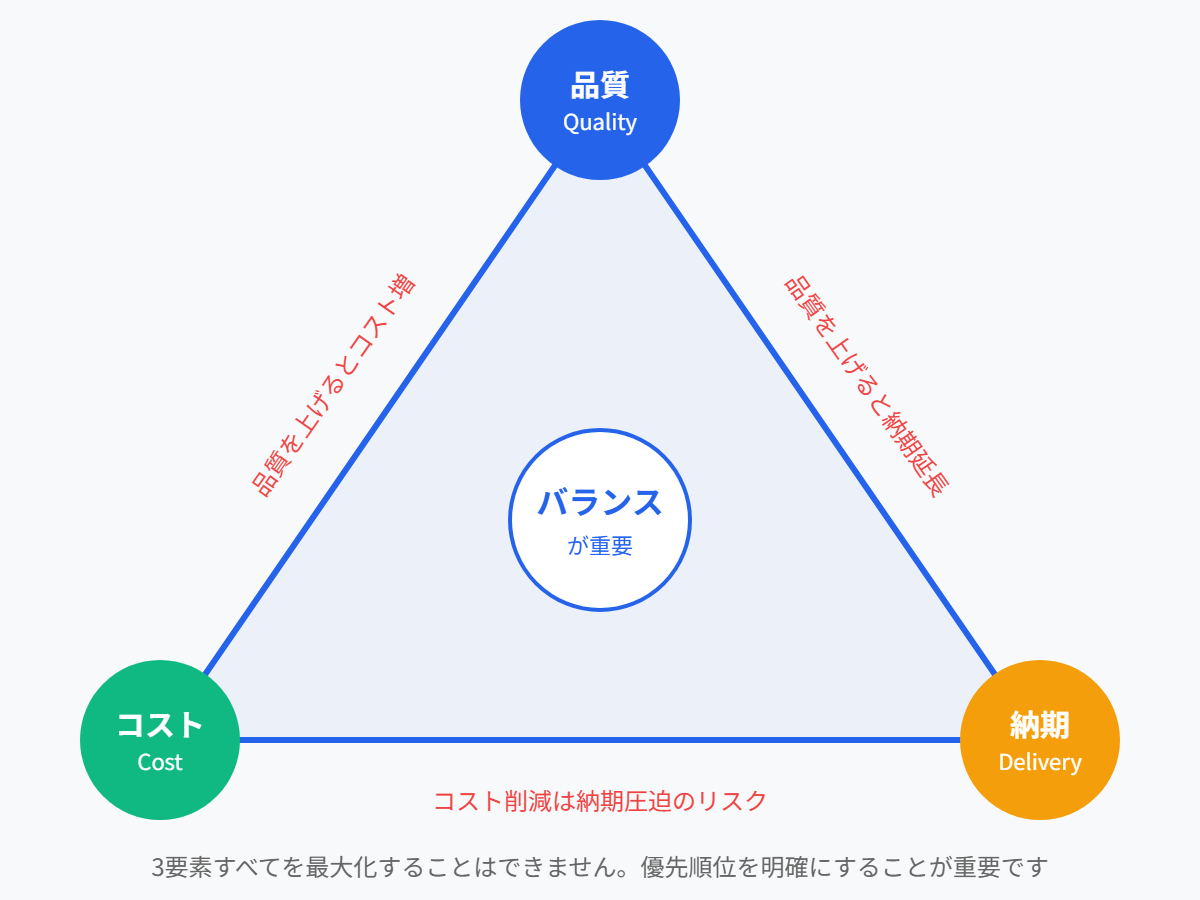
1-2. プロジェクト成功の鍵は「品質」×「納期」×「コスト」のバランス
ITプロジェクトでは、以下の3要素のバランスが求められます。
- 品質(Quality) → 高い品質を確保する
- 納期(Delivery) → 期限内にリリースする
- コスト(Cost) → 予算内で収める
この3要素の関係は「プロジェクトマネジメントの鉄の三角形」として知られています。
品質を犠牲にして納期やコストを優先すると、以下のような問題が起こります。
「とりあえず動くものを納品」→ 運用コストが膨れ上がる
- 早期リリースを優先した結果、納品後に不具合が頻発する。
- 修正のために追加予算が必要になり、結局コストが増大します。
「動くけど品質が低い」→ ユーザーからのクレームが殺到する
- 「仕様通りに動くはずなのに使いづらい」とユーザーが不満を抱く。
- クライアントの信頼を失い、プロジェクトの評価が下がります。
バランスを取るための戦略は次の3点です。
- 「品質基準」を明確に設定し、最低ラインを守る
- 開発初期から品質を考慮し、後から手直しが不要な設計をする
- リリース前にユーザー視点でのテスト(UAT)を実施し、問題点を洗い出す
品質・納期・コストのバランスを適切に管理することで、長期的にも成功するプロジェクトが実現できます。
【図:品質・納期・コストのトレードオフ三角形】
1-3. 品質管理を怠ると、後から何倍ものコストがかかる
「納期を優先して品質は後回し」とすると、後から発生する修正コストが膨大になります。
低品質が引き起こすリスクは主に3つです。
バグ対応に追われ、開発チームが疲弊する
- リリース後に多数のバグ報告が上がり、緊急対応が常態化する。
- 本来取り組むべき新機能開発が進まなくなります。
顧客対応コストの増加
- 品質が悪いシステムは、ユーザーからの問い合わせが急増する。
- サポートコストが想定以上に膨れ上がります。
信用の喪失
- 企業の評判が悪化し、「この会社のシステムは信用できない」と思われる。
- 次の案件受注が難しくなります。
2. 品質の作り込み(QA、レビュー、テスト計画)
品質の高いプロダクトを作るためには、納品前の最終チェックだけでは不十分です。品質は開発プロセス全体を通じて作り込むものであり、設計・実装・テストの各段階で品質管理を徹底する必要があります。ここでは、QA・レビュー・テスト計画の観点から品質の作り込み方を解説します。
2-1. テストは「納品前にやるもの」ではなく、プロジェクト開始時から考えるべき
「テスト=最終チェック」という誤解があります。多くのプロジェクトで、テストは「開発が終わった後に実施するもの」と考えられています。しかし、このアプローチでは以下の問題が発生しやすくなります。
バグが後になって大量に見つかり、納期が遅れる
- 開発完了後にテストを行うと、不具合の修正に多くの時間がかかる。
- 根本的な設計ミスが発覚すると、大幅な手戻りが発生します。
要件の抜け漏れが発覚し、追加開発が必要になる
- 「テスト時に初めて仕様を確認する」と、要件定義段階での不備が見落とされる。
- UATで「想定していた動作と違う」と指摘され、修正対応が発生します。
これらのリスクを防ぐためには、テスト計画をプロジェクト開始時から設計し、開発プロセスと並行して品質管理を行うことが不可欠です。
シフトレフト・テスト戦略を取り入れることが有効です。シフトレフトとは、「開発後のテスト」から「設計・要件定義時点での品質管理」へとテストを前倒しする考え方です。
シフトレフトの具体的な取り組みは以下の4つです。
- 要件定義時点で受け入れ基準を明確化する(テストケースを事前に作成)
- 設計段階でレビューを実施し、仕様の整合性を確認する
- 開発中にユニットテスト・自動テストを活用する(CI/CDパイプラインに組み込む)
- 統合テストを並行して実施し、段階的に品質を高める
テストを後回しにせず、最初から品質を意識した開発プロセスを構築することが重要です。
【図:シフトレフト・テスト戦略】

2-2. レビューの4つのレイヤー
品質を確保するためには、単にテストを実施するだけでなく、開発プロセスの各段階でレビューを徹底することが必要です。ここでは、品質を高めるための4つのレビューを解説します。
1. コードレビュー(Code Review)
目的:開発者が書いたコードの品質を向上させるためのレビューです。実施者は開発チームのメンバーです。
チェックポイント:
- コーディング規約に準拠しているか
- 可読性が高く、メンテナンスしやすいコードになっているか
- セキュリティ上の問題(SQLインジェクション、XSSなど)がないか
- 不要な処理やパフォーマンス上のボトルネックがないか
ベストプラクティス:
- Gitのプルリクエストを活用し、他のメンバーにレビューを依頼する
- ペアプログラミングやモブプログラミングでリアルタイムのフィードバックを得る
- 自動コード解析ツール(SonarQube、ESLintなど)で静的解析を行う
2. 設計レビュー(Design Review)
目的:システム設計やアーキテクチャの品質をチェックし、大規模な手戻りを防ぎます。実施者はアーキテクト、シニアエンジニア、PMです。
チェックポイント:
- 設計が要件に適合しているか
- スケーラビリティ(拡張性)が考慮されているか
- データベース設計やAPI設計が適切か
- 依存関係や統合ポイントに潜在的なリスクがないか
ベストプラクティス:
- 設計ドキュメントを作成し、レビューのたびに更新する
- アーキテクチャの検討段階で技術的負債を排除する
- 非機能要件を意識した設計を行う
3. 受入テスト(UAT:User Acceptance Test)
目的:エンドユーザーが期待する動作を満たしているか確認します。実施者はクライアント、ビジネスチーム、QAチームです。
チェックポイント:
- 仕様通りの動作をするか
- 業務フローに適合しているか
- ユーザーが直感的に使えるか
ベストプラクティス:
- 実際のユーザーにテストを実施してもらい、フィードバックを収集する
- 業務シナリオを考慮したテストケースを作成する
4. 運用テスト(Operational Testing)
目的:本番環境でのパフォーマンスや運用負荷をチェックします。実施者は運用チーム、SREです。
チェックポイント:
- システムの監視・ログ収集が適切に設定されているか
- 負荷試験を実施し、ピーク時の挙動を確認する
- 障害時の対応フローが整備されているか
ベストプラクティス:
- 本番環境と同じ条件で負荷テストを行う
- エラーログを監視し、異常検知の仕組みを導入する
【図:品質レビューの4レイヤー】

2-3. 品質基準の定義方法
品質を「なんとなく良さそう」と判断するのは危険です。明確な品質基準を定め、数値化・文書化することが重要です。
品質基準の例:
- レスポンスタイム:画面遷移は1秒以内
- エラーハンドリング:全てのAPIエラーレスポンスに適切なメッセージを含める
- コードのテストカバレッジ:ユニットテストカバレッジ80%以上
開発プロセス全体で品質を作り込むことで、後のトラブルを最小限に抑えられます。
3. 品質管理のフレームワークとベストプラクティス
品質管理を適切に行うためには、組織全体で統一されたフレームワークを活用することが不可欠です。個々の開発チームの属人的な品質管理ではなく、標準化されたプロセスで一貫性のある品質を維持できます。
3-1. ISO・CMMI・ITILなどの品質管理フレームワークの活用方法
品質管理にはさまざまなフレームワークが存在します。プロジェクトの特性や組織の方針に応じて、適切なフレームワークを採用することが重要です。
ISO 9001:品質管理の基本指針
ISO 9001は、国際標準化機構(ISO)が定めた品質マネジメントシステム(QMS)の規格です。企業が一定の品質を維持するための管理体制を確立することを目的としています。
適用シーン:
- ソフトウェア開発プロジェクト全般
- 品質保証(QA)を重視する企業向け
- 顧客に対して品質の証明が必要な場面
ISO 9001のポイントは、PDCAサイクル(Plan-Do-Check-Act)の徹底です。
- Plan(計画):品質目標を設定し、品質管理計画を策定する
- Do(実行):計画に基づき開発を進め、品質管理活動を実施する
- Check(評価):プロジェクトの品質指標を評価し、問題点を特定する
- Act(改善):フィードバックを基に、次回プロジェクトに向けた改善を行う
品質マネジメントに関するドキュメント作成も必須であり、品質マニュアル・作業手順書・品質記録の作成が求められます。定期的な品質監査を実施し、改善点を洗い出すことで、継続的な品質向上を目指します。
CMMI:開発プロセスの成熟度向上
CMMIは、開発組織の成熟度を測定し、品質向上のためのプロセスを標準化するモデルです。5つの成熟度レベルがあり、レベルが高いほど品質が安定します。
適用シーン:
- ソフトウェア開発のプロセス改善を図りたい企業
- プロジェクトの属人性を排除し、標準化したい場合
5つの成熟度レベルは次のとおりです。
- 初期(Initial):管理が行き届いておらず、品質が不安定
- 管理(Managed):基本的なプロジェクト管理が確立される
- 定義(Defined):標準化されたプロセスが適用される
- 定量管理(Quantitatively Managed):数値データに基づいた品質管理を実施
- 最適化(Optimizing):継続的な改善が行われる
レビュー・テスト・リリース管理などの品質管理プロセスを確立し、KPIを用いた品質の可視化を行うことが求められます。
ITIL:運用・保守における品質管理
ITILは、ITサービス管理(ITSM)のベストプラクティスを体系化したフレームワークです。運用フェーズにおける品質管理を目的としています。
適用シーン:
- システム運用やITサービス管理における品質向上
- クラウドサービスやSaaSの運用を行う企業
ITILのポイントは、インシデント管理と問題管理の徹底です。システム障害時の対応フローを標準化し、迅速な復旧を可能にします。変更管理の最適化により、バージョンアップや構成変更によるリスクを最小限に抑えます。サービスレベル管理(SLM)により、運用フェーズでの品質目標を定め、ユーザー満足度を向上させます。
3-2. アジャイル開発における継続的インテグレーション(CI)と自動テスト
アジャイル開発では、頻繁なリリースが求められるため、継続的インテグレーション(CI)と自動テストの導入が不可欠です。
CI(Continuous Integration)とは、開発中のコードを頻繁に統合し、バグを早期に発見する手法です。
CIのポイント:
- 開発者がコードをコミットするたびに自動テストを実行する
- ビルドエラーやバグをリアルタイムで検出し、迅速に修正できる
- テストが成功したコードのみが統合され、品質が安定する
CIの代表的なツール:
- Jenkins(オープンソースのCI/CDツール)
- GitHub Actions(GitHubのCI/CD機能)
- CircleCI(クラウドベースのCI/CDツール)
3-3. ウォーターフォール型プロジェクトでの品質保証
ウォーターフォール開発では、各フェーズの終わりに品質ゲート(Quality Gate)を設けることが重要です。
品質ゲートのポイント:
- 要件定義のレビューを徹底し、不明確な部分を排除する
- 設計フェーズでテストケースを作成し、開発後の手戻りを削減する
- 単体テスト・結合テスト・システムテストを厳格に実施する
ウォーターフォール開発での品質管理ツール:
- TestRail(テストケース管理)
- JIRA(テスト管理とバグトラッキング)
4. 開発と運用の橋渡し(SRE、DevOpsの視点)
開発チームと運用チームの間に存在する「壁」は、多くのITプロジェクトで問題を引き起こします。「開発が完了すれば仕事は終わり」ではなく、システムが安定して稼働し続けることが本当の成功です。運用フェーズで発生する障害やパフォーマンス問題を未然に防ぐためには、SREやDevOpsの考え方を導入し、開発と運用の橋渡しを強化する必要があります。
4-1. 開発と運用の「溝」をなくすために必要なこと
開発チームと運用チームの連携が不十分だと、以下のような問題が発生します。
| 課題 | 開発チームの視点 | 運用チームの視点 |
|---|---|---|
| システム障害 | 「コードは仕様通り動いている」 | 「リリース後に障害が多発している」 |
| 変更管理 | 「新機能をすぐにリリースしたい」 | 「安定運用のために変更を最小限にしたい」 |
| パフォーマンス | 「開発環境では問題ない」 | 「本番環境では負荷がかかりすぎている」 |
| 障害対応 | 「リリース後は運用チームの仕事」 | 「バグの原因は開発チームで対応すべき」 |
このような対立を防ぐためには、開発と運用が協力してシステムの品質を維持する仕組みを構築する必要があります。そのための有効なアプローチが、SREとDevOpsです。
4-2. SRE(サイトリライアビリティエンジニアリング)の考え方
SRE(Site Reliability Engineering)は、Googleが提唱した運用と開発の統合アプローチです。運用の信頼性を確保しながら、新機能のリリース速度を向上させることを目的としています。
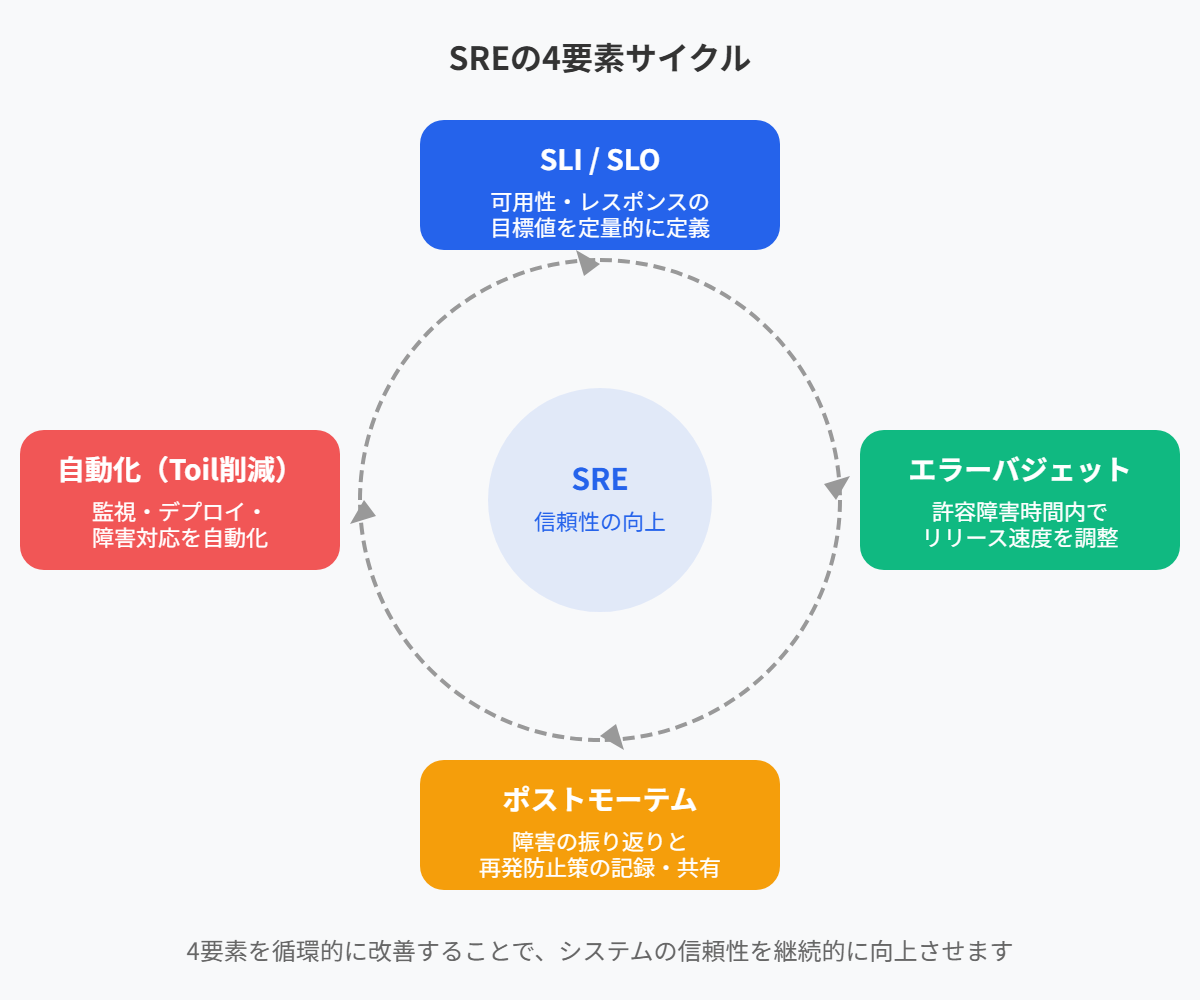
SREの基本原則は次の4つです。
サービスレベル目標(SLO)の定義
「システムがどの程度の可用性・パフォーマンスを維持すべきか」を定量的に測定します。例として、APIのレスポンスタイムは500ms以下、稼働率は99.9%以上といった基準があります。
エラーバジェットの活用
システムの許容できる障害時間を定め、それを超えない範囲で新機能をリリースします。例として、月間で43.2分以内のダウンタイムは許容する(99.9%の稼働率を維持)という基準があります。
自動化の推進(Toilの削減)
手作業による運用業務(Toil)を最小限に抑えるため、監視・デプロイ・障害対応を自動化します。例として、Terraform、Ansibleなどのインフラ管理自動化ツールを活用します。
ポストモーテム文化(障害の振り返り)
障害が発生した場合、責任追及ではなく、再発防止策を記録し学びを共有します。
SREを実践するための具体的な取り組み:
- 運用負荷を可視化し、定量的な目標を設定する
- エラーバジェットを導入し、適切なペースでリリースを行う
- 運用の自動化を推進し、手作業の負担を軽減する
【図:SREの基本原則】
4-3. DevOpsによる開発・運用の連携強化
DevOps(Development + Operations)は、開発と運用の垣根をなくし、継続的なデリバリーを実現するための文化・プラクティス・ツールの総称です。
DevOpsの主なプラクティスは次の4つです。
CI/CD(継続的インテグレーション / 継続的デリバリー)
- CI(Continuous Integration):コードの変更を頻繁に統合し、バグを早期に発見する。
- CD(Continuous Delivery):テストが成功すれば、自動的に本番環境へデプロイする。
Infrastructure as Code(IaC)
サーバーやネットワーク設定をコードで管理し、手作業の構成ミスを防ぎます。例として、Terraform、Ansible、CloudFormationがあります。
モニタリングとロギングの強化
システムの状態をリアルタイムで監視し、異常を検知したら即座に対応します。例として、Prometheus(監視)、ELK Stack(ログ管理)があります。
フィードバックループの短縮
開発者が運用の課題を直接知ることで、ユーザー視点の改善を迅速に行います。例として、エラーログのリアルタイム共有や運用ダッシュボードの整備があります。
DevOpsを導入するための具体的な取り組み:
- CI/CDパイプラインを構築し、自動デプロイを実現する
- Infrastructure as Codeを活用し、環境構築を自動化する
- 監視・ログ分析ツールを導入し、障害を未然に防ぐ
4-4. デリバリー後の障害対応を最小限にするための事前対策
「開発が完了したら終了」ではなく、運用フェーズのトラブルを未然に防ぐための仕組み作りが重要です。
事前に実施すべき対策:
- 本番環境と同等のステージング環境で負荷テストを実施する
- ロールバックプラン(障害時の切り戻し手順)を用意する
- 障害時のエスカレーションルールを明確にする
- オンコール体制を整備し、迅速な対応を可能にする
代表的なモニタリングツール:
- 監視ツール:Datadog / Prometheus / Zabbix
- ログ管理ツール:ELK Stack / Splunk
- アラート通知:PagerDuty / OpsGenie
5. ユーザー視点の品質チェック(UATの活用)
システムの品質を確保するうえで、技術的なテストだけでは不十分です。最終的にシステムを評価するのはユーザーであり、ユーザーの期待を満たしていなければ「品質が高い」とは言えません。
この視点を反映するために欠かせないのが、ユーザー受入テスト(UAT:User Acceptance Testing)です。UATは、実際のエンドユーザーがシステムを試用し、要件通りに動作するか、実業務で問題なく使えるかを確認するテストフェーズです。
5-1. 最終的な品質の判断はユーザーが行う
開発チームは、要件定義に基づいてシステムを実装し、バグのない状態で納品しようとします。しかし、以下のような問題が発生することがあります。
| 課題 | 開発者の視点 | ユーザーの視点 |
|---|---|---|
| UI/UX | 「仕様通りに作った」 | 「直感的に使いにくい」 |
| パフォーマンス | 「システムの処理は高速」 | 「操作フローが複雑で時間がかかる」 |
| エラーハンドリング | 「ログにエラー情報が出る」 | 「エラーメッセージがわかりにくい」 |
| 使い勝手 | 「マニュアルを読めばわかる」 | 「業務の流れに合わない」 |
このようなズレを防ぐためには、実際の業務で利用するユーザーにシステムを評価してもらい、実運用に即した改善を行う必要があります。
5-2. ユーザー受入テスト(UAT)とは
ユーザー受入テスト(UAT)とは、開発が完了し、技術的なテストもクリアしたシステムが、エンドユーザーにとって使いやすいかどうかを検証するテストプロセスです。
UATの目的:
- ユーザーが業務でスムーズに使えるかを確認する
- 仕様と実際の運用が合致しているかをチェックする
- システムの直感的な使いやすさ(UX)を評価する
- リリース前に重大な問題を発見し、修正する
| テスト種別 | 目的 | 実施者 |
|---|---|---|
| 単体テスト | モジュール単位のバグチェック | 開発者 |
| 結合テスト | システム間の連携確認 | QAチーム |
| システムテスト | システム全体の動作確認 | QAチーム |
| ユーザー受入テスト(UAT) | ユーザー視点での業務適合性チェック | 実際のユーザー |
UATは、「開発者が動作を保証するテスト」ではなく、「ユーザーが使い勝手を確認するテスト」であることがポイントです。
5-3. UATを有効に機能させるための進め方
UATを効果的に実施するためには、計画的な進行が不可欠です。以下の5ステップで進めます。
ステップ1:UATのスコープと目標を明確にする
どの業務プロセスをテストするのか決めます。すべての機能をテストするのではなく、業務に影響の大きい機能を重点的に確認します。テストの成功基準(合格条件)も設定します。例として、主要な業務フローをエラーなしで実行できること、操作手順が直感的であること(マニュアルを見ずに操作可能)などがあります。
ステップ2:UAT用のテストケースを作成する
UATでは、ユーザーが実際に行う操作を想定したテストケースを作成します。
| テスト項目 | 期待される結果 |
|---|---|
| 注文の登録 | 商品が正しく登録され、確認画面が表示される |
| 決済処理 | クレジットカード決済が成功し、領収書が発行される |
| エラー処理 | 不正なデータ入力時に適切なエラーメッセージが表示される |
| 業務フロー | 既存の業務とスムーズに統合できる |
テストケースは、技術的な視点ではなく、業務の流れを基準に作成することが重要です。
ステップ3:UATの環境を整備する
UATは、本番環境にできるだけ近い環境で行うことが理想です。
UAT環境のチェックリスト:
- 本番データに近いテストデータを準備する
- ユーザーが使いやすいUI/UXであるか確認する
- テスト実施のためのアカウントを発行する
- 本番と同じパフォーマンス条件でテストできるか確認する
ステップ4:UATを実施し、ユーザーのフィードバックを収集する
UAT実施時には、ユーザーのフィードバックをリアルタイムで記録し、改善点を洗い出すことが重要です。
フィードバック収集のポイント:
- ユーザーに「どこで迷ったか」「使いにくかった点」をヒアリングする
- フォームやアンケートを活用し、意見を集める
- 画面録画ツールを使い、操作中の課題を分析する
ステップ5:UATの結果をもとに修正・改善を行う
UATのフィードバックをもとに、操作性の向上(UI/UXの改善)、業務プロセスに合わせた調整、誤解を生むエラーメッセージの修正を行います。
UATの最終目的は、「ユーザーがストレスなくシステムを使える状態を作ること」です。技術的な動作が問題なくても、業務の流れに合わなければ本番導入後のトラブルにつながるため、UATの結果を反映することが重要です。
6. 運用段階で得たデータを次のプロジェクトに活かす方法
システムが運用フェーズに入った後も、品質向上の取り組みは続きます。運用段階で得たデータを適切に活用することで、次のプロジェクトの品質を向上させ、より良いシステム開発につなげられます。
6-1. プロジェクト終了=学びの終わりではない
システム開発では、納品・リリースがゴールではなく、そこからが本当のスタートです。運用が始まると、実際のユーザーがシステムを利用するため、開発時には想定できなかった問題や改善点が明確になります。
しかし、運用で発生した問題や得られたデータを活かさなければ、次回のプロジェクトでも同じ問題が発生します。「同じ失敗の繰り返し」という悪循環に陥らないためにも、運用データの活用が重要です。
運用データの活用が重要な理由:
- 実際のパフォーマンスを基に、次回のシステム設計を改善できる
- 障害発生の傾向を分析し、信頼性を向上させられる
- ユーザーのフィードバックを取り入れ、より使いやすいシステムを開発できる
- 運用コストの最適化につながる
これらの情報を整理・分析し、次のプロジェクトに活かす仕組みを構築することが、品質向上のカギとなります。
6-2. 障害データの活用方法
障害データの収集と整理
運用中に発生する障害のデータを適切に収集し、パターンを把握することで、次回のプロジェクトでは発生を未然に防げます。
障害データの収集方法:
- ログ管理ツール(ELK Stack、Splunk、Datadogなど)を活用する
- インシデント管理システム(JIRA、ServiceNowなど)に記録する
- SREのポストモーテム文化を採用し、障害の詳細と対策を文書化する
| 項目 | 記録する内容 |
|---|---|
| 発生日時 | 障害が発生した日時(UTC/JSTを統一) |
| 影響範囲 | どの機能・システムに影響を与えたか |
| 障害の種類 | アプリケーションエラー / サーバーダウン / データ破損 など |
| 原因分析 | コードのバグ、インフラ障害、設定ミスなどの原因特定 |
| 解決策 | どのように復旧したか |
| 再発防止策 | 次回のプロジェクトで活かす改善策 |
障害の傾向分析と次回プロジェクトへの適用
収集した障害データを分析し、次のプロジェクトで同様の障害が発生しないように改善策を講じることが重要です。
障害の傾向分析:
- 発生頻度の高い障害の特定(例:月に3回以上発生しているDB接続エラー)
- 特定のリリース後に増えた障害を分析(例:バージョン1.5リリース後のパフォーマンス低下)
- 時間帯ごとの障害発生パターンを分析(例:深夜帯にAPIリクエストが集中し障害多発)
次回のプロジェクトで実施すべき対策:
- 問題の多かった機能に対して、より厳格なテストを追加する
- 発生しやすい障害に対して、監視・アラートの強化を行う
- 根本原因を修正し、同様の問題が再発しないようにする
6-3. パフォーマンスログの活用方法
パフォーマンスデータの収集
運用フェーズでは、システムのパフォーマンスデータを収集し、ボトルネックを特定することが重要です。
| 項目 | 記録する内容 |
|---|---|
| CPU / メモリ使用率 | 負荷状況を把握し、リソース不足を特定 |
| レスポンスタイム | API / DBクエリの応答速度を測定 |
| トランザクション数 | システムの負荷状況を把握 |
| エラー率 | 例外発生率、HTTP 500エラーの頻度 |
パフォーマンス監視ツールの活用:
- Prometheus + Grafana(リアルタイム監視)
- New Relic / Datadog(アプリケーション監視)
パフォーマンス改善と次回プロジェクトへの適用
収集したパフォーマンスデータをもとに、次のプロジェクトではボトルネックを事前に解決できます。
パフォーマンス改善策の例:
- レスポンス遅延の多いAPIの最適化(クエリのインデックス追加など)
- 負荷が高い処理を非同期化し、処理待ち時間を削減する
- サーバーリソースのスケール調整を自動化する(オートスケール設定)
6-4. ユーザーフィードバックの活用方法
フィードバックの収集方法
運用中のユーザーからのフィードバックは、次回のプロジェクトでのUX向上に直結します。
収集方法:
- カスタマーサポート経由の問い合わせ分析
- アンケート・NPS(ネットプロモータースコア)調査
- ヒートマップツール(Hotjarなど)を活用し、ユーザーの操作傾向を分析
ユーザーフィードバックを次回プロジェクトに活かす方法
フィードバックを分析し、次回のプロジェクトではユーザーのニーズを満たす仕様に改善します。
次回のプロジェクトで考慮すべきUX改善策:
- 操作性が悪い部分のUIを改善する(ボタン配置・ナビゲーション整理)
- ユーザーの要望が多かった機能を追加する(検索機能強化など)
- エラーメッセージを改善する(ユーザーが理解しやすい表現に変更)
6-5. 「品質向上のサイクル」を回すための仕組み作り
障害データ、パフォーマンスログ、ユーザーフィードバックを定期的に分析し、ナレッジとして蓄積することで、品質向上のサイクルを回せます。
継続的な品質向上のための仕組み:
- KPT(Keep・Problem・Try)による振り返りを実施する
- プロジェクトごとのナレッジをWiki化し、組織全体で共有する
- 次回のプロジェクト開始前に、過去の障害データを確認する
運用データを活用することで、プロジェクトの品質を向上させ、より良いシステムを継続的に構築できます。
7. 今日からできるアクション
- 自社プロジェクトの品質の種類を整理し、それぞれの管理手法を決定する
- PMが品質管理のためにやるべきことをリストアップし、実施する
- リリース判断の基準を明確にし、チームと共有する
- 品質に関するKPI(バグ発生率、レスポンスタイムなど)を設定し、継続的に監視する
次回の記事
次回の第9回では、「プロジェクト終了と振り返り」をテーマに解説します。
第9回:プロジェクト終了と振り返り|クロージングから学びを次につなげる仕組みづくり
プロジェクトマネジメントシリーズ 記事一覧
- 第1回:プロジェクト管理の本質とは?スケジュール管理を超えた「価値を生むPM」の考え方
- 第2回:プロジェクト計画の立て方|WBS・スコープ定義・マイルストーンの実務テクニック
- 第3回:リスクマネジメントの実践|「想定外を想定する」ITプロジェクトのリスク管理プロセス
- 第4回:プロジェクト進捗管理のコツ|「順調です」に潜むリスクを見抜く実践手法
- 第5回:プロジェクトのチームマネジメントとリーダーシップ|フェーズごとに変わるPMの役割
- 第6回:ステークホルダーマネジメント|期待値管理・影響度分析・対立解決の実践ガイド
- 第7回:プロジェクトトラブル対応(火消しスキル)|炎上の兆候発見から収束まで
- 第8回:品質管理とデリバリー|「動けばOK」ではない、PMが押さえるべき品質の作り込み方(この記事)
- 第9回:プロジェクト終了と振り返り|クロージングから学びを次につなげる仕組みづくり
- 第10回:プロジェクトマネジメントスキルの継続的向上|エンジニアからPMへのキャリアパスと学習戦略