
新卒インフラエンジニア向け Kubernetes 実践教科書(第2巻 CKA 編)の第13回です。動作確認バージョン: AlmaLinux 10.1 / K8s v1.35.5 / kube-prometheus-stack chart v84.x / Loki chart v7.0.0(appVersion v3.6.7)/ Fluent Bit chart v0.57.x / kubeadm v1.35.5(2026-05-24 時点)。
- 今ここマップ(第13回 / 全16回 / 第5部開始)
- 第13回のスコープと設計 — 監視スタック 4 機構を 1 Namespace に集約する
- 第13回で「やること」と「やらないこと」
- 監視スタック全体アーキテクチャ
- 演習 Namespace の設計
- 設計判断① monitoring Namespace に 4 機構を一括配置
- 設計判断② Longhorn PVC + emptyDir フォールバック併記
- 設計判断③ serviceMonitorSelector: {} で全 Namespace 対象
- 設計判断④ Loki は deploymentMode: SingleBinary(単一バイナリ / Monolithic モード)
- 設計判断⑤ Fluent Bit は公式 Name loki プラグイン採用
- 設計判断⑥ Grafana ダッシュボードは 4 パネル構成
- kube-prometheus-stack の構成とコンポーネント
- Loki + Fluent Bit の構成
- ServiceMonitor + MicroProfile Metrics 5.1
- やってみよう① kube-prometheus-stack を Helm でインストールする
- やってみよう② Loki + Fluent Bit をインストールする
- やってみよう③ ServiceMonitor で fanclub-api のメトリクスをスクレイプする
- やってみよう④ Grafana ダッシュボードを作成する
- まとめ・現場ヒヤリハット・理解度チェック
- シリーズ一覧
今ここマップ(第13回 / 全16回 / 第5部開始)
今ここ: 第13回 / 全16回(第5部:監視・運用)
▓▓▓▓▓▓▓▓▓▓▓▓▓░░░ 81%
第1部(クラスタ構築): ■■■■■ 5/5 回(完了)
第2部(ワークロード管理): ■■■ 3/3 回(完了)
第3部(ネットワーク): ■■■ 3/3 回(完了)
第4部(ストレージ): ■ 1/1 回(完了)
第5部(監視・運用): ■□ 1/2 回 ← 今ここ
第6部(トラブルシュート): □□ 0/2 回第12回では Longhorn v1.11.1 を導入し、fanclub-db(PostgreSQL 18)を分散ストレージ上で稼働させました。第4部(ストレージ)を完走した今、第5部(監視・運用)に入ります。第13回では kube-prometheus-stack + Loki + Fluent Bit の監視スタックを一気に構築し、fanclub-api の JVM・HTTP メトリクスと Kubernetes クラスタ全体のログを Grafana ダッシュボードで可視化します。
第13回のキャッチコピー: 「kube-prometheus-stack + Loki + Fluent Bit + ServiceMonitor + MicroProfile Metrics 5.1 の連携でメトリクスとログを Grafana に集約する」
第13回は CKA D5「Troubleshooting」(30%)の主力回です。「Evaluate cluster and node logging」「Understand how to monitor applications」「Manage container stdout and stderr logs」の 3 つのスキルを、Prometheus + Grafana によるメトリクス可視化と、Loki + Fluent Bit によるログ集約の 2 つのパイプラインで一度に体験します。
第13回終了時の達成状態:
kubectl get pods -n monitoringで Prometheus / Grafana / Alertmanager / node-exporter / kube-state-metrics / Loki / Fluent Bit が全Runningkubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80で Grafana UI(admin / prom-operator)が開く- Grafana の Prometheus データソースが
Data source connected and labels found表示 - Grafana の Loki データソースが接続済み
kubectl get servicemonitor -n fanclubでfanclub-backend-monitorが存在- Prometheus の Targets ページで
fanclub/fanclub-backend-monitorがUP表示 - Grafana Explore で Loki クエリ
{namespace="fanclub"}にログが表示される - 4 パネルのカスタムダッシュボード(JVM ヒープ / Pod 再起動 / HTTP リクエストレート / エラーログ)が全パネルにデータを表示
第13回のスコープと設計 — 監視スタック 4 機構を 1 Namespace に集約する
本セクションでは、第13回で扱うこと・扱わないことを明確にし、監視スタック全体アーキテクチャ・演習 Namespace 設計・6 つの設計判断を整理します。
第13回で「やること」と「やらないこと」
| やること | やらないこと |
|---|---|
| kube-prometheus-stack(Prometheus + Grafana + Alertmanager)Helm 導入 | Prometheus の長期ストレージ(Thanos / Cortex) |
| ServiceMonitor で fanclub-api のメトリクスをスクレイプ | PodMonitor(ServiceMonitor で代替可能) |
| Loki(SingleBinary)+ Fluent Bit でクラスタ全体ログ集約 | ログの長期アーカイブ(S3 / MinIO 連携) |
| Grafana ダッシュボード 4 パネル作成 | PrometheusRule / Alertmanager 通知設定(第3巻 SRE 編) |
MicroProfile Metrics 5.1 の /metrics エンドポイント理解 | Metrics API Server(第8回で導入済み) |
監視スタック全体アーキテクチャ
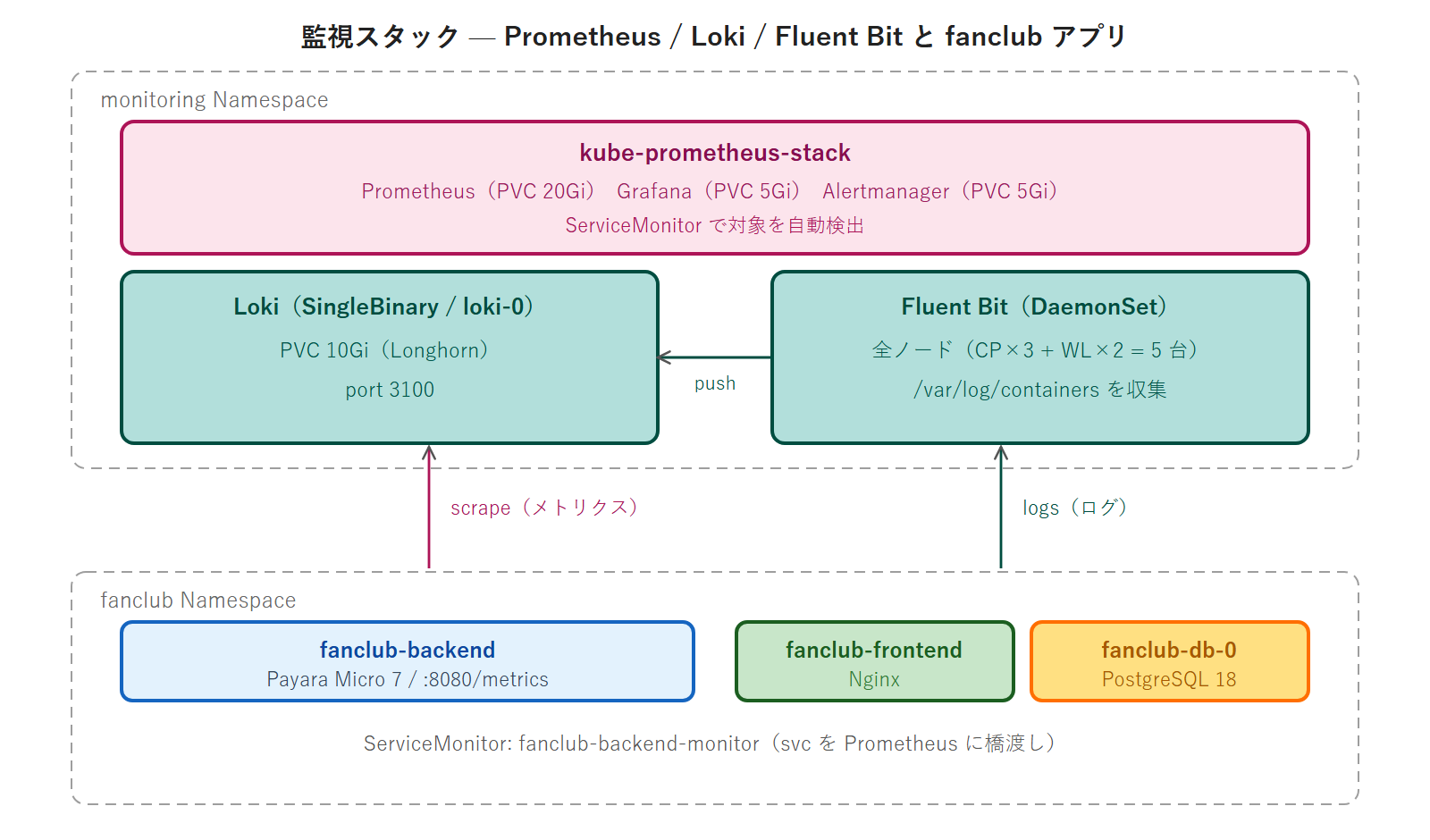
4 つの主要機構(Prometheus / Grafana / Loki / Fluent Bit)がすべて monitoring Namespace に集約され、fanclub Namespace のアプリケーションを ServiceMonitor 経由でスクレイプします。Fluent Bit は DaemonSet として全ノード(k8s-cp-01〜03 + k8s-wl-01〜02 の 5 台)に配置され、コンテナログを Loki に転送します。
演習 Namespace の設計
| Namespace | 役割 | 削除タイミング |
|---|---|---|
monitoring(新規) | kube-prometheus-stack / Loki / Fluent Bit を全部集約 | 削除しない(第14回 ArgoCD でも参照) |
fanclub(既存) | fanclub-api 稼働中 / ServiceMonitor を追加 | 変更しない |
longhorn-system(既存) | 第12回導入の Longhorn / PVC のバックエンド | 変更しない |
設計判断① monitoring Namespace に 4 機構を一括配置
kube-prometheus-stack / Loki / Fluent Bit をすべて monitoring Namespace にインストールします。監視スタック全体を 1 Namespace に集約すると RBAC 設計・トラブルシュートの見通しがよくなり、kubectl get pods -n monitoring 1 コマンドで全監視コンポーネントの状態確認が可能です。Namespace 分離設計(fanclub / monitoring)は CKA D5 試験でも標準パターンです。
設計判断② Longhorn PVC + emptyDir フォールバック併記
Prometheus / Grafana / Alertmanager / Loki の永続化は Longhorn StorageClass(storageClassName: longhorn)を使用します。第12回で Longhorn v1.11.1 を導入済みのため StorageClass として利用可能です。ただし Longhorn の admission webhook が monitoring Namespace の PVC 作成で干渉するケースが実機で確認されているため、本回ではヒヤリハット①として「longhorn.io/webhook-exempt: true ラベル付与」と「emptyDir フォールバック」の 2 つの回避手順を明示します。
設計判断③ serviceMonitorSelector: {} で全 Namespace 対象
kube-prometheus-stack のデフォルト設定(serviceMonitorSelectorNilUsesHelmValues: true)では、Helm でインストールされた ServiceMonitor のみ(release: kube-prometheus-stack ラベル付き)が自動検出されます。fanclub Namespace に kubectl apply した ServiceMonitor を検出させるため、values.yaml に以下を設定します。
prometheus:
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelector: {}
serviceMonitorNamespaceSelector: {}serviceMonitorSelector: {} と serviceMonitorNamespaceSelector: {} の 2 つを空オブジェクトで指定することで、全ラベル・全 Namespace の ServiceMonitor が自動検出対象になります。この設定の意味を理解することは CKA 試験でも重要です。
設計判断④ Loki は deploymentMode: SingleBinary(単一バイナリ / Monolithic モード)
Loki Helm chart v7.0.0(appVersion v3.6.7)を deploymentMode: SingleBinary(singleBinary.replicas: 1)でインストールします。本環境は k8s-wl-01/02 の 2 ノード構成・検証環境のため HA 不要で、単一バイナリ(SingleBinary)モードは 1 Pod で write/read/compactor を全部担うため管理対象が少なく済みます。ストレージは type: filesystem で Longhorn PVC(10 Gi)を割り当て、S3/MinIO は使用しません。
この単一バイナリ構成を Loki の公式ドキュメントでは「Monolithic mode」と概念的に呼びますが、Helm chart(v7.0.0)の deploymentMode に指定できる値は SingleBinary / SimpleScalable / Distributed の 3 つです。単一バイナリは SingleBinary を指定します。概念名の Monolithic は chart の値としては受け付けられず、指定しても loki の StatefulSet が生成されない(loki-canary だけが起動する)ので注意してください。values.yaml の設定セクション名も singleBinary: です。
設計判断⑤ Fluent Bit は公式 Name loki プラグイン採用
fluent/helm-charts の fluent-bit chart を使用し、output に Name loki(Fluent Bit プロジェクトの組み込み公式プラグイン)を設定します。Name grafana-loki(コミュニティプラグイン)は現在メンテ終了・非推奨のため採用しません。Helm chart の config.outputs セクションで [OUTPUT] Name loki を宣言するだけで導入可能です。
設計判断⑥ Grafana ダッシュボードは 4 パネル構成
| パネル | データソース | クエリ | パネル種別 |
|---|---|---|---|
| JVM ヒープ使用量(MB) | Prometheus | base_memory_usedHeap_bytes / 1024 / 1024 | Gauge |
| Pod 再起動回数(fanclub) | Prometheus | kube_pod_container_status_restarts_total{namespace="fanclub"} | Table |
| HTTP リクエストレート(5m) | Prometheus | rate(http_server_requests_total{namespace="fanclub"}[5m]) | Time series |
| エラーログ件数(Loki) | Loki | count_over_time({namespace="fanclub"} |= "ERROR" [5m]) | Stat |
JVM ヒープは MicroProfile base scope メトリクスで Payara Micro JVM の健全性を確認します。Pod 再起動は kube-state-metrics が提供するクラスタ健全性の基本指標です。HTTP レートは MicroProfile application/vendor scope または Payara 内蔵の HTTP メトリクスを使用します。エラーログは Loki + Fluent Bit で収集したログを LogQL で集計し、メトリクスとログ双方の扱いを 1 ダッシュボードで体験します。
kube-prometheus-stack の構成とコンポーネント
kube-prometheus-stack とは何か
kube-prometheus-stack は prometheus-community Helm chart の 1 つで、Prometheus 本体・Grafana・Alertmanager・各種 exporter を 1 つの Helm リリースで一括導入できます。Prometheus Operator が CRD(ServiceMonitor / PodMonitor / PrometheusRule 等)を監視し、Prometheus 本体の設定を宣言的に管理します。
同梱コンポーネント一覧
| コンポーネント | 役割 | デフォルト |
|---|---|---|
| prometheus-operator | CRD(ServiceMonitor 等)を監視して Prometheus 設定を自動更新 | 有効 |
| Prometheus | メトリクス収集・時系列 DB・PromQL エンジン | 有効 |
| Grafana | ダッシュボード・可視化 UI | 有効 |
| Alertmanager | アラート管理・通知ルーティング | 有効 |
| node-exporter | ノード(OS)メトリクス収集(DaemonSet) | 有効 |
| kube-state-metrics | Kubernetes オブジェクトメトリクス(Pod restart 等) | 有効 |
node-exporter は各ノードに 1 Pod ずつ配置され、CPU・メモリ・ディスク・ネットワーク等の OS レベルメトリクスを Prometheus に提供します。kube-state-metrics は API Server を Watch して Kubernetes オブジェクト(Pod / Deployment / Node 等)の状態を kube_* 系メトリクスとして公開します。両者は役割が異なる別物です。
ServiceMonitor CRD の役割
【従来の手動設定】 【ServiceMonitor CRD を使った宣言的設定】
prometheus.yml を手動編集: ServiceMonitor を kubectl apply:
scrape_configs: apiVersion: monitoring.coreos.com/v1
- job_name: 'fanclub' kind: ServiceMonitor
static_configs: metadata:
- targets: name: fanclub-backend-monitor
- fanclub-backend spec:
:8080 selector:
matchLabels:
ConfigMap 更新 + Prometheus app.kubernetes.io/name: fanclub-backend
reload が必要 endpoints:
- port: http
path: /metrics
→
prometheus-operator が自動検出して
Prometheus 設定に反映(再起動不要)ServiceMonitor CRD を使うと、スクレイプ対象を Kubernetes リソースとして宣言できます。prometheus-operator が ServiceMonitor を Watch し、検出した変更を Prometheus の設定に反映します。ConfigMap の手動編集や Prometheus 再起動は不要です。CKA 試験では「任意の Namespace の ServiceMonitor をスクレイプ対象にする」操作が出題されるため、この仕組みを理解することが重要です。
serviceMonitorSelector の落とし穴
デフォルト設定では他 Namespace の ServiceMonitor が検出されない
kube-prometheus-stack のデフォルトでは serviceMonitorSelectorNilUsesHelmValues: true となっており、Helm でインストールされた ServiceMonitor のみ(release: kube-prometheus-stack ラベルが付与されたもののみ)が検出されます。fanclub Namespace に kubectl apply した ServiceMonitor にはこのラベルがないため、何時間待っても Prometheus の Targets に出現しません。本シリーズでは設計判断③の通り values.yaml で serviceMonitorSelector: {} を指定して全 Namespace 対象に切り替えます。
Loki + Fluent Bit の構成
Loki の役割 — Prometheus との対比
| 観点 | Prometheus | Loki |
|---|---|---|
| 収集対象 | メトリクス(数値時系列) | ログ(テキスト行) |
| 収集方式 | Pull 型(Prometheus が /metrics を取得) | Push 型(Fluent Bit がログを送信) |
| クエリ言語 | PromQL | LogQL |
| ストレージ | 時系列 DB(TSDB) | チャンクストレージ(filesystem / S3) |
| ラベル設計 | 各メトリクスにラベル付与 | 各ログストリームにラベル付与 |
Loki は「ログのための Prometheus」と表現されます。Prometheus と同じラベルベースのクエリモデルを採用しつつ、ログテキストは全文インデックスではなくラベル単位でチャンク化して保存します。これにより低コストでクラスタ全体のログを集約できます。
ログ収集フロー(Fluent Bit DaemonSet → Loki Push API)

Fluent Bit は DaemonSet として全ノードに 1 Pod ずつ配置されます。各 Pod は自ノードの /var/log/containers/*.log を tail で読み取り、kubernetes filter で Namespace / Pod / Container 名のラベルを付与してから Loki の Push API(/loki/api/v1/push)に送信します。Loki は受信したログをラベル単位でチャンク化し、Longhorn PVC 上の filesystem に保存します。
Loki の deploymentMode(SingleBinary モード)
Loki Helm chart の deploymentMode には SingleBinary / SimpleScalable / Distributed の 3 値を指定できます。本シリーズが採用する単一バイナリ構成は、Loki 公式ドキュメントでは「Monolithic mode」と概念的に呼ばれますが、Helm chart に指定する deploymentMode の値は SingleBinary です。概念名の Monolithic は chart の値としては無効で、指定すると単一バイナリの StatefulSet が生成されません。なお values.yaml の設定セクション名も singleBinary: です。
| deploymentMode | 構成 | 用途 |
|---|---|---|
SingleBinary(Loki ドキュメントの Monolithic mode) | 1 Pod で write/read/compactor を全部担う | 本シリーズ採用・検証環境向け |
SimpleScalable | read/write/backend の 3 ロール分離 | 中規模本番 |
Distributed | マイクロサービス分割(distributor/ingester/querier 等) | 大規模本番 |
ServiceMonitor + MicroProfile Metrics 5.1
MicroProfile Metrics 5.1 のエンドポイント仕様
fanclub-backend は Payara Micro 7.2026.4(Jakarta EE 11 + MicroProfile 6.1)で稼働しており、MicroProfile Metrics 5.1 仕様に従って /metrics エンドポイントを公開しています。クエリパラメータ ?scope= でスコープごとの取得が可能です。
| エンドポイント | 内容 | 代表的なメトリクス |
|---|---|---|
GET /metrics | 全スコープ(デフォルト) | base + vendor + application 全件 |
GET /metrics?scope=base | JVM 基本 | ヒープ・GC・スレッド・CPU |
GET /metrics?scope=vendor | Payara 固有 | リクエスト数・セッション・接続プール |
GET /metrics?scope=application | アプリ定義 | @Counted / @Timed アノテーション |
デフォルト Accept ヘッダなし(ブラウザ)では Prometheus text format で出力されるため、ServiceMonitor の path: /metrics でそのまま全スコープ取得可能です。Payara Micro はポート 8080 で Jakarta EE コンテナを起動し、その内部で MicroProfile Metrics を提供します。
ServiceMonitor 完全マニフェスト
fanclub Namespace に配置する ServiceMonitor の完全マニフェストは以下です。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: fanclub-backend-monitor
namespace: fanclub
labels:
app.kubernetes.io/name: fanclub-backend
app.kubernetes.io/part-of: fanclub-api
spec:
namespaceSelector:
matchNames:
- fanclub
selector:
matchLabels:
app.kubernetes.io/name: fanclub-backend
endpoints:
- port: http
path: /metrics
interval: 30s
scheme: http
honorLabels: falsespec.selector.matchLabels で参照する Pod ラベルではなく Service ラベルが対象です。spec.endpoints[].port には数値ではなく Service の spec.ports[].name(ポート名)を指定します。fanclub-backend の Service で 8080 ポートに name: http が付いている前提です。interval: 30s は 30 秒ごとにスクレイプする設定で、これは Prometheus 本体のデフォルト(30 秒)と同じです。
やってみよう① kube-prometheus-stack を Helm でインストールする
kube-prometheus-stack v84.x を Helm でインストールし、Prometheus / Grafana / Alertmanager / node-exporter / kube-state-metrics を一括導入します。作業場所は k8s-ops(developer ユーザー)です。
Step 1: monitoring Namespace の作成と Longhorn webhook 除外ラベル付与
実行コマンド(k8s-ops 上・developer):
$ kubectl create namespace monitoring実行結果:
namespace/monitoring created実行コマンド:
$ kubectl label namespace monitoring longhorn.io/webhook-exempt=true実行結果:
namespace/monitoring labeledこのラベルは Longhorn の admission webhook が monitoring Namespace の PVC 作成を妨げないようにするための除外指示です(ヒヤリハット①で詳解)。
Step 2: prometheus-community リポジトリの追加
実行コマンド:
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts実行結果:
"prometheus-community" has been added to your repositories実行コマンド:
$ helm repo update prometheus-community実行結果:
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. Happy Helming!実行コマンド(バージョン確認):
$ helm search repo prometheus-community/kube-prometheus-stack --versions | head -5実行結果:
NAME CHART VERSION APP VERSION
prometheus-community/kube-prometheus-stack 84.5.0 v0.90.1
prometheus-community/kube-prometheus-stack 84.4.0 v0.89.0
prometheus-community/kube-prometheus-stack 84.3.0 v0.89.0Step 3: values.yaml の作成
kube-prometheus-stack の values.yaml を作成します。設計判断③(serviceMonitorSelector: {})と設計判断②(Longhorn PVC)を反映します。
ファイル名: kube-prometheus-stack-values.yaml
prometheus:
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelector: {}
serviceMonitorNamespaceSelector: {}
podMonitorSelectorNilUsesHelmValues: false
podMonitorSelector: {}
podMonitorNamespaceSelector: {}
ruleSelectorNilUsesHelmValues: false
ruleSelector: {}
ruleNamespaceSelector: {}
retention: 15d
resources:
requests:
cpu: 200m
memory: 512Mi
limits:
cpu: 1000m
memory: 2Gi
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
grafana:
adminPassword: "prom-operator"
persistence:
enabled: true
type: pvc
storageClassName: longhorn
accessModes:
- ReadWriteOnce
size: 5Gi
service:
type: ClusterIP
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
alertmanager:
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 200m
memory: 256Mi
kubeStateMetrics:
enabled: true
nodeExporter:
enabled: true
prometheusOperator:
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 300m
memory: 384Mi本シリーズでは adminPassword に Helm のデフォルト値 prom-operator を明示的に指定しています。本番では Secret 参照(admin.existingSecret)に変更してください。retention: 15d はメトリクス保持期間を 15 日に設定する指定で、検証環境のディスク消費を抑えます。
Step 4: Helm インストール
実行コマンド:
$ helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--version 84.5.0 \
--values kube-prometheus-stack-values.yaml実行結果:
NAME: kube-prometheus-stack
LAST DEPLOYED: Sun May 24 14:32:18 2026
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=kube-prometheus-stack"
Get Grafana 'admin' user password by running:
kubectl --namespace monitoring get secrets kube-prometheus-stack-grafana \
-o jsonpath="{.data.admin-password}" | base64 -dStep 5: Pod の起動確認
実行コマンド:
$ kubectl get pods -n monitoring実行結果:
NAME READY STATUS RESTARTS AGE
alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 0 3m12s
kube-prometheus-stack-grafana-7d4b5f9d6c-x8w7v 3/3 Running 0 3m20s
kube-prometheus-stack-kube-state-metrics-6f8d9c8b-zwk5m 1/1 Running 0 3m20s
kube-prometheus-stack-operator-79c4d65b48-h6n4p 1/1 Running 0 3m20s
kube-prometheus-stack-prometheus-node-exporter-4nq8t 1/1 Running 0 3m20s
kube-prometheus-stack-prometheus-node-exporter-9k7lx 1/1 Running 0 3m20s
kube-prometheus-stack-prometheus-node-exporter-r2m6w 1/1 Running 0 3m20s
kube-prometheus-stack-prometheus-node-exporter-t3xfg 1/1 Running 0 3m20s
kube-prometheus-stack-prometheus-node-exporter-v9b8j 1/1 Running 0 3m20s
prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 3m08snode-exporter は DaemonSet として 5 ノード(k8s-cp-01〜03 + k8s-wl-01〜02)に各 1 Pod ずつ配置されます。Prometheus と Alertmanager は StatefulSet として 1 レプリカずつ起動し、それぞれ Longhorn PVC を取得します。
Step 6: PVC の確認
実行コマンド:
$ kubectl get pvc -n monitoring実行結果:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
alertmanager-kube-prometheus-stack-alertmanager-db-alertmanager-kube-prometheus-stack-alertmanager-0 Bound pvc-3e7f1a02-... 5Gi RWO longhorn 3m45s
kube-prometheus-stack-grafana Bound pvc-8c12b9d4-... 5Gi RWO longhorn 3m45s
prometheus-kube-prometheus-stack-prometheus-db-prometheus-kube-prometheus-stack-prometheus-0 Bound pvc-a51d6f8e-... 20Gi RWO longhorn 3m45s3 つの PVC が Bound ステータスで STORAGECLASS: longhorn になっていることを確認します。
Step 7: Grafana への port-forward と UI アクセス
実行コマンド:
$ kubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80実行結果:
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000ブラウザで http://localhost:3000 を開き、ユーザー admin / パスワード prom-operator でログインします。左メニュー Connections > Data sources から Prometheus を選択し、Test ボタンを押すと Data source is working または Data source connected and labels found が表示されます。
現場ヒヤリハット① Longhorn webhook が monitoring Namespace の PVC 作成を阻害する
状況: helm install kube-prometheus-stack 実行後に Prometheus Pod が Pending のまま起動しない。kubectl describe pod -n monitoring prometheus-kube-prometheus-stack-prometheus-0 で「Unschedulable」「pod has unbound immediate PersistentVolumeClaims」が出力される。kubectl describe pvc -n monitoring を見ると admission webhook longhorn-webhook-service denied the request のエラーが記録されている。
原因: Longhorn の admission webhook は PVC 作成時に Longhorn 固有のバリデーション(StorageClass パラメータ整合性等)を実施するが、monitoring Namespace に対して webhook が期待しない応答を返すケースが Longhorn v1.11.1 で確認されている。
回避策 A(推奨・本シリーズの Step 1 に組み込み済み): monitoring Namespace に longhorn.io/webhook-exempt=true ラベルを付与してから Helm install する。
回避策 B(emptyDir フォールバック): values.yaml の storageSpec / persistence を削除して emptyDir で起動し、Longhorn 側の webhook 設定を見直してから helm upgrade で PVC に切り替える。emptyDir 設定例:
prometheus:
prometheusSpec:
storageSpec:
emptyDir:
sizeLimit: 20Gi
grafana:
persistence:
enabled: false
alertmanager:
alertmanagerSpec:
storage:
emptyDir:
sizeLimit: 5Gi教訓: 検証環境では Longhorn webhook の干渉が問題化する Namespace(特に新規作成 NS)でラベル除外を先に入れる。本番では webhook 側のバリデーション設定を見直す。emptyDir は Pod 再起動でデータ消失するため、検証中の応急処置にとどめる。
やってみよう② Loki + Fluent Bit をインストールする
Loki(SingleBinary)と Fluent Bit(DaemonSet)を Helm で連続インストールし、Grafana から LogQL でクラスタログを検索できる状態にします。
Step 1: grafana / fluent リポジトリの追加
実行コマンド:
$ helm repo add grafana https://grafana.github.io/helm-charts
$ helm repo add fluent https://fluent.github.io/helm-charts
$ helm repo update grafana fluent実行結果:
"grafana" has been added to your repositories
"fluent" has been added to your repositories
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "grafana" chart repository
...Successfully got an update from the "fluent" chart repository
Update Complete. Happy Helming!実行コマンド(バージョン確認):
$ helm search repo grafana/loki --versions | head -3
$ helm search repo fluent/fluent-bit --versions | head -3実行結果:
NAME CHART VERSION APP VERSION DESCRIPTION
grafana/loki 7.0.0 3.6.7 Helm chart for Grafana Loki in simple, scalable...
grafana/loki 7.0.0 3.6.7 Helm chart for Grafana Loki in simple, scalable...
NAME CHART VERSION APP VERSION DESCRIPTION
fluent/fluent-bit 0.57.6 5.0.6 Fast and lightweight log processor and forwarder
fluent/fluent-bit 0.57.5 5.0.5 Fast and lightweight log processor and forwarderStep 2: Loki values.yaml の作成
ファイル名: loki-values.yaml
deploymentMode: SingleBinary
loki:
auth_enabled: false
commonConfig:
replication_factor: 1
storage:
type: filesystem
schemaConfig:
configs:
- from: "2024-01-01"
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: loki_index_
period: 24h
limits_config:
reject_old_samples: true
reject_old_samples_max_age: 168h
ingestion_rate_mb: 16
ingestion_burst_size_mb: 32
per_stream_rate_limit: 8MB
per_stream_rate_limit_burst: 16MB
singleBinary:
replicas: 1
persistence:
enabled: true
storageClass: longhorn
accessModes:
- ReadWriteOnce
size: 10Gi
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 1000m
memory: 1Gi
read:
replicas: 0
write:
replicas: 0
backend:
replicas: 0
chunksCache:
enabled: false
resultsCache:
enabled: false
monitoring:
selfMonitoring:
enabled: false
grafanaAgent:
installOperator: false
lokiCanary:
enabled: false
test:
enabled: false
gateway:
enabled: false本シリーズは検証環境なので chunksCache / resultsCache / selfMonitoring / lokiCanary / gateway を無効化し、リソース消費を最小化します。本番では chunksCache(Memcached)を有効化してクエリ性能を上げてください。auth_enabled: false はクラスタ内通信のみのためマルチテナント機能を無効化する指定です。なお chart v7.0.0 では lokiCanary は トップレベルのキー(既定 enabled: true)であり、上記のように最上位で lokiCanary.enabled: false と指定します。monitoring.lokiCanary のように monitoring 配下にネストすると無視され、ログ自己診断用の loki-canary DaemonSet が各ノードに起動してしまうので注意してください。
limits_config の ingestion_rate_mb: 16 はデフォルトの 4 MB から引き上げています。これはクラスタ全体のログ流量がデフォルト上限を超えた際にログがサイレントに欠落する障害(ヒヤリハット④)を防ぐためです。
Step 3: Loki Helm インストール
実行コマンド:
$ helm install loki grafana/loki \
--namespace monitoring \
--version 7.0.0 \
--values loki-values.yaml実行結果:
NAME: loki
LAST DEPLOYED: Sun May 24 14:48:32 2026
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
***********************************************************************
Welcome to Grafana Loki
Chart version: 7.0.0
Chart Name: loki
Loki version: 3.6.7
***********************************************************************実行コマンド(起動確認):
$ kubectl get pods -n monitoring -l app.kubernetes.io/name=loki実行結果:
NAME READY STATUS RESTARTS AGE
loki-0 2/2 Running 0 85sStep 4: Fluent Bit values.yaml の作成
ファイル名: fluent-bit-values.yaml
kind: DaemonSet
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 200m
memory: 256Mi
config:
service: |
[SERVICE]
Daemon Off
Flush 5
Log_Level info
Parsers_File /fluent-bit/etc/parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
Health_Check On
inputs: |
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*.log
multiline.parser docker, cri
Refresh_Interval 5
Skip_Long_Lines On
DB /var/log/flb_kube.db
Mem_Buf_Limit 50MB
filters: |
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Merge_Log On
Keep_Log Off
K8S-Logging.Parser On
K8S-Logging.Exclude Off
outputs: |
[OUTPUT]
Name loki
Match kube.*
Host loki.monitoring.svc.cluster.local
Port 3100
Labels job=fluent-bit
label_keys $kubernetes['namespace_name'],$kubernetes['pod_name'],$kubernetes['container_name']
auto_kubernetes_labels off
line_format json
Retry_Limit 5
daemonSetVolumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: etcmachineid
hostPath:
path: /etc/machine-id
type: File
daemonSetVolumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: etcmachineid
mountPath: /etc/machine-id
readOnly: truetolerations で node-role.kubernetes.io/control-plane: NoSchedule を許可することで、Fluent Bit が Control Plane Node にも配置されクラスタ全 5 ノードのログを収集できます。[INPUT] tail セクションの DB /var/log/flb_kube.db はノード再起動後のログ重複を防ぐ重要設定です(ヒヤリハット②で詳解)。
Step 5: Fluent Bit Helm インストール
実行コマンド:
$ helm install fluent-bit fluent/fluent-bit \
--namespace monitoring \
--version 0.57.6 \
--values fluent-bit-values.yaml実行結果:
NAME: fluent-bit
LAST DEPLOYED: Sun May 24 14:55:11 2026
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
Get Fluent Bit build information by running these commands:
export POD_NAME=$(kubectl get pods --namespace monitoring -l "app.kubernetes.io/name=fluent-bit" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace monitoring port-forward $POD_NAME 2020:2020
curl http://127.0.0.1:2020実行コマンド(5 ノードに DaemonSet が配置されたか確認):
$ kubectl get pods -n monitoring -l app.kubernetes.io/name=fluent-bit -o wide実行結果:
NAME READY STATUS RESTARTS AGE IP NODE
fluent-bit-2nq5p 1/1 Running 0 62s 10.244.0.41 k8s-cp-01
fluent-bit-7mz8r 1/1 Running 0 62s 10.244.1.37 k8s-cp-02
fluent-bit-c6w4x 1/1 Running 0 62s 10.244.2.29 k8s-cp-03
fluent-bit-h9k3v 1/1 Running 0 62s 10.244.3.62 k8s-wl-01
fluent-bit-r4x8j 1/1 Running 0 62s 10.244.4.58 k8s-wl-02Control Plane Node 3 台と Workload Node 2 台の計 5 ノードすべてに Fluent Bit Pod が配置されていることを確認します。
Step 6: Grafana に Loki データソースを追加
Grafana UI(http://localhost:3000・port-forward 経由)にログイン後、左メニュー Connections > Add new connection から Loki を選択します。Add new data source を押し、URL に以下を入力します。
http://loki.monitoring.svc.cluster.local:3100Save & test を押すと Data source successfully connected が表示されます。続いて左メニュー Explore から Loki データソースを選び、クエリ欄に以下を入力します。
{job="fluent-bit"}過去 5 分間のログが流れ込んでいれば成功です。Namespace ラベルで絞り込む場合は以下のように指定します。
{namespace="fanclub"}現場ヒヤリハット② Fluent Bit の DB 設定なしではノード再起動後にログが重複する
状況: ノードを reboot や systemctl restart kubelet で再起動すると、Loki に同じログメッセージが大量に重複登録される。Grafana Explore で {namespace="fanclub"} |= "INFO" を叩くと、過去数時間分のログが同一時刻で重複して並ぶ。
原因: [INPUT] tail セクションに DB /var/log/flb_kube.db を設定していないと、Fluent Bit は「どのファイルをどこまで読んだか」を記憶せず、再起動後にすべてのログファイルを先頭から再読み込みする。
対処: values.yaml の config.inputs セクションに必ず DB /var/log/flb_kube.db を入れる(本シリーズの Step 4 設定例に含まれている)。DB は SQLite ファイルで、各ファイルの inode と最終読み込みオフセットを記録する。
教訓: Fluent Bit の tail input には DB ファイル設定が事実上の必須要件。検証時に DB なしで動かしてしまうと、運用本格化のタイミングでログ重複が発覚しトラブルシュートに数時間取られる。チャート values テンプレートで DB 設定がデフォルト無効になっている点に注意する。
やってみよう③ ServiceMonitor で fanclub-api のメトリクスをスクレイプする
ServiceMonitor CRD を fanclub Namespace に配置し、fanclub-backend の /metrics エンドポイントを Prometheus が自動スクレイプする状態にします。
Step 0: 第4回 Helm chart 由来 Service にメトリクス用ラベルを追加
第4回の helm install fanclub-api で生成された Service は名前が fanclub-api-fanclub-api(Release 名 + Chart 名)になっており、app.kubernetes.io/name: fanclub-api ラベルが付いています。本回で作成する ServiceMonitor は app.kubernetes.io/name: fanclub-backend selector でスクレイプ対象を探すため、このままでは検出できません。第14回で Kustomize 化されて Service 名・ラベルが fanclub-backend に揃うまでの暫定対応として、既存 Helm chart 由来 Service(fanclub-api-fanclub-api)に app.kubernetes.io/name: fanclub-backend ラベルを上書き追加して ServiceMonitor の selector に合わせます(本 Step ではラベル付与のみで、別名の新規 Service は作成しません)。実行コマンド:
$ kubectl label service fanclub-api-fanclub-api -n fanclub app.kubernetes.io/name=fanclub-backend --overwrite
$ kubectl get service -n fanclub --show-labelsこれで第13回 ServiceMonitor が同 Service をスクレイプ対象として検出できます。第14回で Kustomize に切り替わると Service 名が fanclub-backend になり、ラベルも揃った状態になるため、本 Step 0 の暫定対応は不要になります。
Step 1: Service のポート名確認
ServiceMonitor の endpoints[].port は数値ではなく Service のポート名を参照するため、まず Service にポート名が設定されていることを確認します。
実行コマンド:
$ kubectl get service fanclub-api-fanclub-api -n fanclub -o yaml実行結果(抜粋):
apiVersion: v1
kind: Service
metadata:
name: fanclub-api-fanclub-api
namespace: fanclub
labels:
app.kubernetes.io/name: fanclub-backend # Step 0 で追加
spec:
selector:
app.kubernetes.io/name: fanclub-api
ports:
- name: http
port: 80
targetPort: http
protocol: TCP
type: ClusterIPports[].name: http が設定されていることを確認します。設定されていない場合は kubectl edit service fanclub-api-fanclub-api -n fanclub で name: http を追加してください。
Step 2: ServiceMonitor マニフェストの作成
ファイル名: fanclub-backend-monitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: fanclub-backend-monitor
namespace: fanclub
labels:
app.kubernetes.io/name: fanclub-backend
app.kubernetes.io/part-of: fanclub-api
spec:
namespaceSelector:
matchNames:
- fanclub
selector:
matchLabels:
app.kubernetes.io/name: fanclub-backend
endpoints:
- port: http
path: /metrics
interval: 30s
scheme: http
honorLabels: falseStep 3: ServiceMonitor の適用
実行コマンド:
$ kubectl apply -f fanclub-backend-monitor.yaml実行結果:
servicemonitor.monitoring.coreos.com/fanclub-backend-monitor created実行コマンド(適用確認):
$ kubectl get servicemonitor -n fanclub実行結果:
NAME AGE
fanclub-backend-monitor 18sStep 4: Prometheus Targets での検出確認
実行コマンド(Prometheus への port-forward):
$ kubectl port-forward -n monitoring svc/kube-prometheus-stack-prometheus 9090:9090実行結果:
Forwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090ブラウザで http://localhost:9090/targets を開きます。serviceMonitor/fanclub/fanclub-backend-monitor/0 (1/1 up) のように UP 表示されれば成功です。検出までに最大 2 分かかります。表示されない場合はヒヤリハット③を参照してください。
Step 5: /metrics エンドポイントの直接確認
fanclub-backend の /metrics 出力を直接見て、MicroProfile Metrics のメトリクス名を確認します。Grafana ダッシュボードで使う PromQL のメトリクス名を実機で照合する手順です。
実行コマンド:
$ kubectl port-forward -n fanclub svc/fanclub-api-fanclub-api 8080:80別ターミナルで実行コマンド:
$ curl -s http://localhost:8080/metrics | head -30実行結果(抜粋):
# HELP base_memory_usedHeap_bytes Displays the amount of used heap memory in bytes.
# TYPE base_memory_usedHeap_bytes gauge
base_memory_usedHeap_bytes 1.23456789E8
# HELP base_memory_committedHeap_bytes Displays the amount of memory committed for the JVM to use in bytes.
# TYPE base_memory_committedHeap_bytes gauge
base_memory_committedHeap_bytes 2.68435456E8
# HELP base_cpu_processCpuLoad_percent Displays the recent CPU usage for the JVM process.
# TYPE base_cpu_processCpuLoad_percent gauge
base_cpu_processCpuLoad_percent 0.018
# HELP base_thread_count Displays the current number of live threads.
# TYPE base_thread_count gauge
base_thread_count 42.0MicroProfile Metrics 5.1 の base scope メトリクス(base_memory_usedHeap_bytes・base_thread_count 等)が Prometheus text format で出力されていることを確認します。HTTP メトリクスを使う場合はメトリクス名が Payara バージョンで変わるため、ここで実機の名前を控えておきます。
Step 6: Prometheus Graph での PromQL 動作確認
Prometheus UI(http://localhost:9090)の Graph タブで以下の PromQL を入力し、Execute を押します。
base_memory_usedHeap_bytes{namespace="fanclub"}fanclub-backend の Pod ごとに JVM ヒープ使用量(バイト単位)が時系列で表示されれば、ServiceMonitor 経由のメトリクス収集が正常に機能しています。
現場ヒヤリハット③ serviceMonitorSelector のデフォルト設定で fanclub NS の SM が発見されない
状況: ServiceMonitor を kubectl apply しても Prometheus の Targets ページに表示されない。kubectl get servicemonitor -n fanclub では fanclub-backend-monitor が存在し YAML も正しく見える。prometheus-operator の Pod ログにもエラーが出ない。
原因: kube-prometheus-stack のデフォルト設定 serviceMonitorSelectorNilUsesHelmValues: true では、Helm でインストールされた ServiceMonitor のみが対象になる。具体的には release: kube-prometheus-stack ラベルが付与された ServiceMonitor だけが Prometheus に拾われ、kubectl apply で作った SM は無視される。
対処(推奨・本シリーズ採用): values.yaml で以下を設定してから helm upgrade する。
prometheus:
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelector: {}
serviceMonitorNamespaceSelector: {}対処(非推奨): ServiceMonitor 側に release: kube-prometheus-stack ラベルを追加する。ただしリリース名が変わった場合に全 SM の更新が必要になり運用が煩雑になるため非推奨。
教訓: kube-prometheus-stack の NilUsesHelmValues 系設定は初見では意味不明だが、デフォルトのままだとアプリ Namespace の ServiceMonitor が一切拾われない最悪の挙動になる。values.yaml で {} 設定を入れる手順を CKA 試験の準備としても暗記する価値がある。本シリーズでは設計判断③で事前に組み込み済み。
やってみよう④ Grafana ダッシュボードを作成する
Grafana に 4 パネル構成のカスタムダッシュボードを作成し、Prometheus メトリクスと Loki ログを 1 画面で確認できる状態にします。
Step 1: ダッシュボードの新規作成
Grafana UI(http://localhost:3000)の左メニュー Dashboards > New > New dashboard を選択し、画面右上の Save dashboard をクリックして名前を fanclub-api Monitoring に設定します。
Step 2: パネル① JVM ヒープ使用量(Prometheus / Gauge)
Add visualization から Prometheus データソースを選択し、画面右上の Visualization 種別を Gauge に変更します。クエリ欄に以下を入力します。
base_memory_usedHeap_bytes{namespace="fanclub"} / 1024 / 1024右側の Standard options > Unit を data (Metric) > mebibytes (MiB) に設定し、パネル名を JVM Heap Used (MiB) に変更します。Pod 数だけパネル内に表示されるため、必要に応じて sum() や avg() でまとめます。
Step 3: パネル② Pod 再起動回数(Prometheus / Table)
新しいパネルを追加し、Visualization を Table に設定します。クエリ欄に以下を入力します。
kube_pod_container_status_restarts_total{namespace="fanclub"}Format を Table に切替・Instant をチェックすると、最新の Pod ごとの再起動回数が表形式で表示されます。パネル名を Pod Restarts (fanclub) に変更します。これは kube-state-metrics が提供するクラスタ健全性の基本指標です。
Step 4: パネル③ HTTP リクエストレート(Prometheus / Time series)
新しいパネルを追加し、Visualization は Time series(デフォルト)のまま使用します。クエリ欄に以下を入力します。
rate(http_server_requests_total{namespace="fanclub"}[5m])パネル名を HTTP Request Rate (rps) に設定します。Standard options > Unit を requests/sec に変更します。メトリクス名 http_server_requests_total は MicroProfile Metrics 実装の vendor scope または Payara 拡張で提供されますが、Payara のバージョンや設定で異なる場合があります。Step 5 の /metrics 直接確認(やってみよう③ Step 5)で実機のメトリクス名に合わせて修正してください。
Step 5: パネル④ エラーログ件数(Loki / Stat)
新しいパネルを追加し、データソースを Loki に切り替え、Visualization を Stat に設定します。クエリ欄(LogQL)に以下を入力します。
count_over_time({namespace="fanclub"} |= "ERROR" [5m])パネル名を Error Logs (5m) に設定します。Loki のラベル namespace は Fluent Bit の label_keys 設定($kubernetes['namespace_name'])から自動で付与されます。LogQL の |= は「文字列マッチ」で、ログ行に ERROR が含まれるものだけをカウントします。
Step 6: ダッシュボード保存と動作確認
画面右上の Save dashboard を押してダッシュボードを保存します。保存後の URL(例: http://localhost:3000/d/abc123def/fanclub-api-monitoring)をブックマークしておきます。
動作確認として fanclub-backend を再起動し、パネルに変化が現れることを確認します。
実行コマンド:
$ kubectl rollout restart deployment/fanclub-backend -n fanclub実行結果:
deployment.apps/fanclub-backend restartedPod 再起動から数十秒後、ダッシュボードの「Pod Restarts」テーブルに 1 が記録され、「JVM Heap Used」が新しい Pod の初期値にリセットされます。HTTP リクエストレートと エラーログ件数はトラフィック状況に応じて変動します。
まとめ・現場ヒヤリハット・理解度チェック
第13回のまとめ
- kube-prometheus-stack v84.x を Helm で導入し、Prometheus / Grafana / Alertmanager / node-exporter / kube-state-metrics を
monitoringNamespace に一括配置した。Longhorn PVC(Prometheus 20Gi / Grafana 5Gi / Alertmanager 5Gi)で永続化済み - Loki chart v7.0.0(appVersion v3.6.7)を
deploymentMode: SingleBinaryでインストールし、Longhorn PVC(10Gi)で filesystem ストレージを永続化。Fluent Bit chart v0.57.x を DaemonSet として全 5 ノードに配置し、公式Name lokiプラグインで Loki Push API にログ転送 - ServiceMonitor CRD(
fanclub-backend-monitor)を fanclub Namespace に配置し、Payara Micro 7 の/metricsエンドポイント(MicroProfile Metrics 5.1)から JVM・HTTP メトリクスを Prometheus にスクレイプ。serviceMonitorSelector: {}設定が他 NS の SM を検出するための鍵 - Grafana ダッシュボード 4 パネル(JVM ヒープ / Pod 再起動 / HTTP リクエストレート / エラーログ)を作成。Prometheus データソース(メトリクス)と Loki データソース(ログ)を 1 画面に統合した
CKA D5(Troubleshooting)との対応:
| CKA D5 スキル | 第13回での体験 |
|---|---|
| Evaluate cluster and node logging | Fluent Bit + Loki でノード・コンテナログ収集を実装 |
| Understand how to monitor applications | ServiceMonitor で fanclub-api メトリクスを収集 |
| Manage container stdout and stderr logs | kubectl logs + Loki Explore で多角的ログ確認 |
第5部「監視・運用」第1回完了:
第13回の完了で第5部の 1/2 回が完了しました。次回は第5部「監視・運用」を完走し、第14回で GitOps とバックアップを導入します。
次回予告
第14回では Helm + Kustomize でクラスタコンポーネントを宣言的に管理し、ArgoCD v3.4 で GitOps 化、Velero v1.18 でクラスタバックアップを構築 します。第13回まで手動 helm install で構築してきた監視スタックを ArgoCD で宣言的同期に移行し、Git push だけで監視設定が自動反映される環境を実現します。Velero では監視データを含むクラスタ全体のバックアップとリストアを扱い、第6部「トラブルシュート」での復旧演習に備えます。
現場ヒヤリハット④ Loki の ingestion limit でログがサイレントに欠落する
状況: Loki 自体は Running・Fluent Bit も全ノードで Running なのに、Grafana の Loki Explore でログが途切れている時間帯がある。kubectl logs -n monitoring loki-0 を見ても明確なエラーは出ず、Fluent Bit のログにも接続エラーが出ない。一見正常に見えるのが厄介な点。
原因: Loki のデフォルト limits_config.ingestion_rate_mb は 4 MB/s と低めに設定されており、クラスタログ流量がこの上限を超えると Loki はレート制限を発動して HTTP 429(Too Many Requests)を返す。Fluent Bit はリトライ設定がないとそのログを破棄して次に進むため、ログがサイレントに欠落する。
対処: Loki values.yaml の limits_config でレート上限を引き上げる。本シリーズの Step 2(やってみよう②)の loki-values.yaml には以下を組み込み済み。
loki:
limits_config:
ingestion_rate_mb: 16
ingestion_burst_size_mb: 32
per_stream_rate_limit: 8MB
per_stream_rate_limit_burst: 16MBFluent Bit 側も Retry_Limit 5 を [OUTPUT] loki セクションに設定して 429 応答時の自動再送を有効化する。
教訓: Loki のレート制限はサイレント障害になりやすい。loki_ingester_streams_created_total や loki_request_duration_seconds_count{status_code="429"} 等のメトリクスを Prometheus で監視し、429 が増え始めたら limits 設定を見直す。検証段階で低トラフィック・本番投入で大量ログが流れて初めて発覚するパターンに注意する。
理解度チェック
第13回の理解度を ○× 形式の 7 問で確認します。まず問題を読み、自分なりに答えを出してから解説を読んでください。
- 問 1: Prometheus の ServiceMonitor を使えば、スクレイプ対象のサービスを
prometheus.ymlに手動で記述することなく自動検出できる - 問 2: kube-prometheus-stack のデフォルト設定では、
kubectl applyで作成した ServiceMonitor がどの Namespace にあっても自動的に Prometheus に検出される - 問 3: Loki は Prometheus と同じように
/metricsエンドポイントをスクレイプしてメトリクスを蓄積する - 問 4: MicroProfile Metrics 5.1 の
/metrics?scope=baseエンドポイントでは JVM ヒープ・GC・スレッド等の基本メトリクスが取得できる - 問 5: Fluent Bit を DaemonSet として配置すると、全ノードのコンテナログを自動収集できる
- 問 6: Prometheus の node-exporter はコンテナ内のアプリケーションメトリクスを収集するために使用する
- 問 7:
kube_pod_container_status_restarts_totalは kube-state-metrics が提供するメトリクスであり、node-exporter では収集されない
問 1: ○ — ServiceMonitor CRD を prometheus-operator が監視し、Prometheus の設定を自動更新します。ConfigMap 更新や Prometheus 再起動は不要です。
問 2: × — デフォルト(serviceMonitorSelectorNilUsesHelmValues: true)では Helm 管理 SM のみが対象です。他 NS の SM を検出するには serviceMonitorSelector: {} を values.yaml で設定する必要があります(ヒヤリハット③参照)。
問 3: × — Loki はログの集約・検索が目的です。メトリクスは Prometheus が担当し、ログは Fluent Bit 等のエージェントが Loki の Push API にデータを送信するモデルです。
問 4: ○ — base スコープは MicroProfile Metrics 仕様が定義する標準メトリクス群です。/metrics で全スコープまとめて取得することも可能です。
問 5: ○ — DaemonSet は各ノードに 1 Pod ずつ起動するため、クラスタ内全ノードの /var/log/containers/ を収集できます。本シリーズでは Control Plane Node にも toleration で配置しています。
問 6: × — node-exporter はノード(OS レベル)のメトリクス(CPU・メモリ・ディスク・ネットワーク等)を収集します。アプリケーションメトリクスは ServiceMonitor + /metrics エンドポイントで収集します。
問 7: ○ — node-exporter はノード OS メトリクスが対象です。Pod の再起動回数等の Kubernetes オブジェクト状態は kube-state-metrics(kube_* 系メトリクス)が担当します。
シリーズ一覧
第1部:クラスタ構築
- 第1回 第2巻スコープ + CKA 試験形式紹介 + kubeadm 概要 + kubeadm vs RKE2/k0s/OKD 概観
- 第2回 kubeadm シングルノード起動(pkgs.k8s.io + kubeadm init + Calico CNI)+ alma-proxy whitelist 構築
- 第3回 kubeadm HA 設計 + HAProxy LB(API Server LB 構成)
- 第4回 kubeadm HA クラスタ構築(CP×3 + WL×2)+ fanclub-api HA 移行
- 第5回 etcd backup/restore(etcdutl)+ ノード drain/uncordon
第2部:ワークロード管理
- 第6回 kubeadm upgrade + ノード drain/cordon + ミニトラブルシュート演習
- 第7回 Pod スケジューリング(taint/toleration/affinity/anti-affinity/PriorityClass)
- 第8回 HPA + ResourceQuota + LimitRange
第3部:ネットワーク
- 第9回 Service 詳細 + MetalLB(LoadBalancer 動作確認)
- 第10回 NetworkPolicy 詳細 + Calico/Cilium 比較 + ミニトラブルシュート演習
- 第11回 Gateway API + Traefik + cert-manager + CoreDNS(HTTPS 公開完成)
第4部:ストレージ
第5部:監視・運用
- 第13回 Prometheus + Grafana + Loki + Fluent Bit + fanclub-api 監視ダッシュボード ← 今ここ
- 第14回 Helm + Kustomize でクラスタコンポーネント install + ArgoCD GitOps + Velero backup
