
新卒インフラエンジニア向け Kubernetes 実践教科書(第2巻 CKA 編)の第15回です。動作確認バージョン: AlmaLinux 10.1 / K8s v1.35.5 / etcd v3.6.6 / etcdutl v3.6.6 / kubeadm v1.35.5(2026-05-24 時点)
今ここマップ(第15回 / 全16回 / 第6部開始)
今ここ: 第15回 / 全16回(第6部:トラブルシュート)
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓░ 94%
第1部(クラスタ構築): ■■■■■ 5/5 回(完了)
第2部(ワークロード管理): ■■■ 3/3 回(完了)
第3部(ネットワーク): ■■■ 3/3 回(完了)
第4部(ストレージ): ■ 1/1 回(完了)
第5部(監視・運用): ■■ 2/2 回(完了)
第6部(トラブルシュート): ■□ 1/2 回 ← 今ここ第14回で Kustomize + ArgoCD + Velero による宣言的運用基盤を完成させました。第15回からは最終第6部「トラブルシュート」に入ります。本回は Control Plane + etcd の障害シナリオ 4 本を実機でシミュレートし、診断から復旧までの手順を体で覚えます。CKA D5「Troubleshooting」(試験配点 30%・最大ドメイン)の Control Plane 領域に対応する Opus 必須回です。
第15回のキャッチコピー: 「Static Pod を壊して直す・etcd restore の失敗を診断する・kubelet を蘇らせる」
SP_vol2-pre-15 への明示ロールバック前提: 本回は破壊的演習のため、各演習開始前に必ず Hyper-V チェックポイント SP_vol2-pre-15 にロールバックしてください。データロスリスクを伴う操作を含みます。本番クラスタでは絶対に試さず、必ず検証環境(本シリーズの 5 ノード HA クラスタ)で実施してください。
第15回終了時の達成状態:
kubectl get pods -n kube-systemでkube-apiserver-k8s-cp-01がRunningに戻る(演習① 復旧後)kubectl get pods -n kube-systemでetcd-k8s-cp-01がRunningかつ restore テストリソースが復元されている(演習② 復旧後)kubectl get nodesで k8s-cp-01 がReadyに戻る(演習③ 復旧後)kubectl get nodesが正常応答する(演習④ 修正後)- CKA D5「Control Plane + etcd トラブルシュート」スキルを 4 シナリオで体験した
第15回のスコープと安全注意 — 破壊的演習を HA で安全に行う設計
本セクションでは、第15回で扱うこと・扱わないことを明確化し、HA クラスタの冗長性を活用して破壊的演習を安全に実施する設計判断を説明します。
やること / やらないこと
| やること | やらないこと |
|---|---|
| kube-apiserver.yaml 破損 → crictl 診断 → 復旧 | 全 3 CP 同時障害(HA quorum 崩壊) |
| etcd restore 失敗状態(hostPath 未更新)の診断・修正 | etcd 全メンバ同時 restore(第5回参照・別設計) |
| kubelet stop → journalctl → start(k8s-cp-01 のみ) | kubeadm 設定ファイルの再生成 |
| kubeconfig server URL 誤設定 → config view → set-cluster | TLS 証明書の再発行 |
| crictl ps / logs による Static Pod 診断 | RBAC・NetworkPolicy トラブルシュート(第16回) |
本番警告 5 件
- 本番警告①: kube-apiserver.yaml を
/etc/kubernetes/manifests/内でバックアップしないでください。kubelet がバックアップファイルも Static Pod 定義として読み込み、同名 Pod が 2 定義状態になります。バックアップは必ず/tmp/等 manifests/ 外に保存します。 - 本番警告②:
etcdutl snapshot restoreの--data-dirに既存ディレクトリを指定するとエラーになります。新ディレクトリ名を指定し、restore 後にetcd.yamlの--data-dirとvolumeMounts.mountPathとvolumes.hostPath.pathの 3 箇所すべてを更新します。 - 本番警告③: HA クラスタで 1 ノードのみ etcd restore を実行すると、他メンバとの quorum 選択で restore 内容が上書きされる可能性があります。HA 全 restore は全メンバ同時停止 + 全メンバ同時 restore +
--initial-cluster再設定が必須です(本回は k8s-cp-01 のみ・新ディレクトリ復元体験まで)。 - 本番警告④:
kubectl config set-clusterでサーバ URL を誤ったアドレスに設定すると、該当ノード上のすべての kubectl 操作が不通になります。~/.kube/configまたは/etc/kubernetes/admin.confのバックアップを事前に取得してください。 - 本番警告⑤: etcd v3.6 では
etcdctl snapshot restoreが完全廃止されました。restore はetcdutl snapshot restoreを使用します。etcdctl snapshot saveは引き続き有効です。「save は etcdctl・restore と status は etcdutl」と覚えてください。
HA 安全活用設計
本回の破壊的演習は k8s-cp-01 1 台のみ を対象に行います。k8s-cp-02 / k8s-cp-03 は稼働を継続させ、API Server / etcd の冗長性を維持したまま障害をシミュレートします。
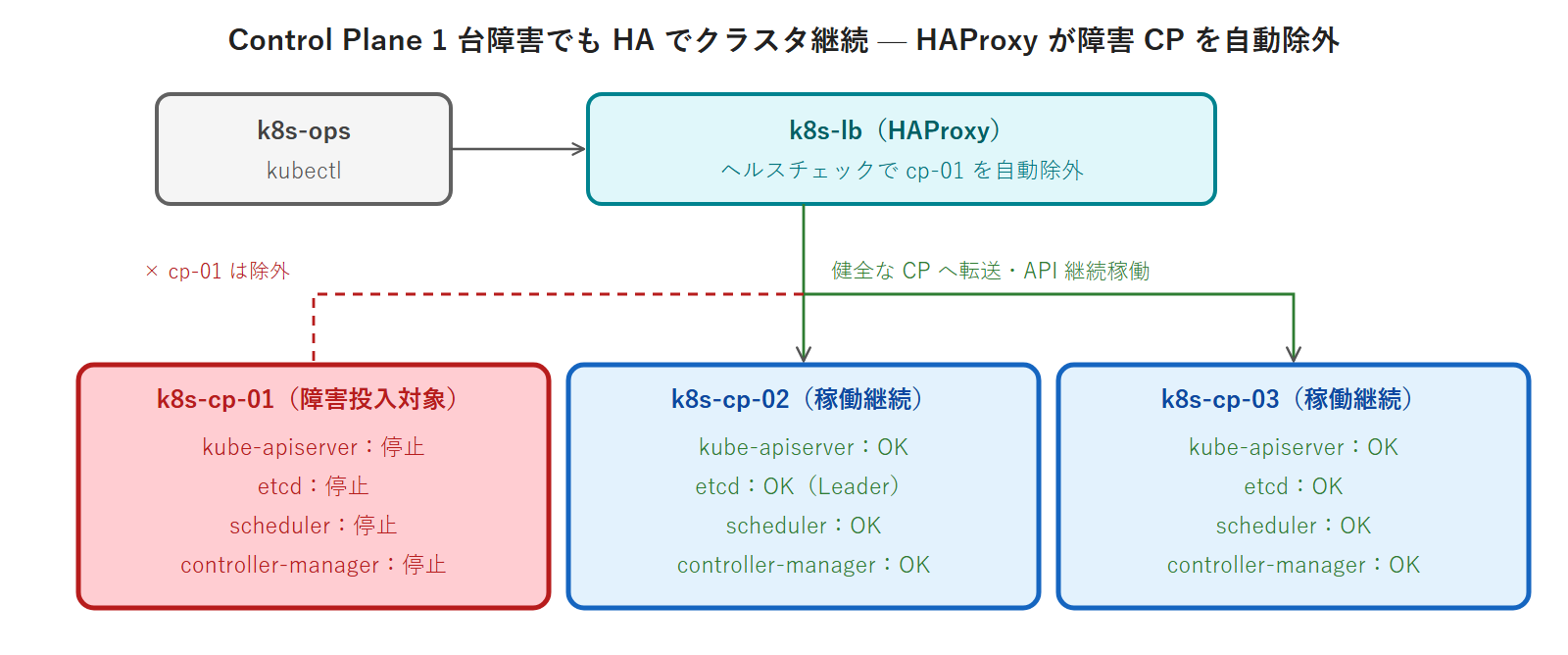
k8s-ops から発行する kubectl コマンドは k8s-lb(HAProxy)経由で k8s-cp-02 または k8s-cp-03 に転送されるため、k8s-cp-01 の障害中も継続して使用できます。HAProxy のヘルスチェック(第3回で構築済み)が k8s-cp-01 の :6443 ポートの応答喪失を検知し、自動的にバックエンドから除外します。
演習用 Namespace 設計
| Namespace | 用途 | 演習後 |
|---|---|---|
kube-system | Static Pod(変更対象) | 演習終了後に元の状態に戻す |
restore-test | etcd restore 確認用テストリソース | 演習② 完了後に削除 |
fanclub | fanclub-api(変更なし) | 変更なし |
Control Plane トラブルシュートの方法論
4 つの演習に入る前に、Control Plane 障害の診断・復旧で使う 4 ステップフレームワークと、各コンポーネントの管理主体・診断ツールを整理します。これらが頭に入っていないと、障害発生時にどのコマンドから打てばよいか迷います。
症状 → 原因 → 修正 → 復旧確認の 4 ステップ

Step 1 の「kubectl が応答するか」で診断が大きく 2 系統に分岐します。応答するなら kube-apiserver は生きているので、特定の Pod 障害や Workload 層の問題を疑います。応答しないなら kube-apiserver 自体(Static Pod)か、kubeconfig の誤設定を疑います。
Control Plane コンポーネントと管理主体
| コンポーネント | 管理主体 | 障害時の診断ツール |
|---|---|---|
| kube-apiserver | kubelet(Static Pod) | crictl ps / crictl logs |
| etcd | kubelet(Static Pod) | crictl logs / etcdctl endpoint health |
| kube-scheduler | kubelet(Static Pod) | crictl ps / crictl logs |
| kube-controller-manager | kubelet(Static Pod) | crictl ps / crictl logs |
| kubelet 自体 | systemd | journalctl -u kubelet / systemctl status kubelet |
Control Plane の 4 コンポーネント(kube-apiserver / etcd / kube-scheduler / kube-controller-manager)はすべて kubelet が管理する Static Pod として起動しています。kubelet 自体は systemd ユニットなので、kubelet の障害診断には journalctl -u kubelet と systemctl status kubelet を使います。階層は「systemd → kubelet → Static Pod」の順です。
各コンポーネントの manifest パス
/etc/kubernetes/manifests/kube-apiserver.yaml
/etc/kubernetes/manifests/etcd.yaml
/etc/kubernetes/manifests/kube-scheduler.yaml
/etc/kubernetes/manifests/kube-controller-manager.yamlkubelet は /etc/kubernetes/manifests/ ディレクトリを inotify で監視し、配置されているファイルを Static Pod 定義として読み込みます。「.(ドット)で始まらない全ファイル」が対象で、拡張子フィルタはありません。つまり kube-apiserver.yaml.bak も Static Pod として解釈されます(後述の本番警告①)。
やってみよう①: Static Pod 障害(kube-apiserver.yaml 破損)
最初の演習は kube-apiserver の Static Pod を意図的に壊し、crictl で診断して復旧する流れです。CKA D5「Troubleshoot cluster components」の中核スキルです。
シナリオ: k8s-cp-01 の kube-apiserver.yaml の --etcd-servers ポートを 2379 から 9999 に変更 → API Server が起動不能 → crictl 診断 → manifest 修正 → 復旧。
作業ノード: k8s-cp-01(root 権限・障害投入と修正)と k8s-ops(developer・kubectl 観察)。
障害投入フェーズ
Step 1: /tmp/ へ事前バックアップを取ります。/etc/kubernetes/manifests/ 内でバックアップしてはいけない理由は本番警告①の通りです。
実行コマンド:
# cp /etc/kubernetes/manifests/kube-apiserver.yaml /tmp/kube-apiserver.yaml.backup
# ls -la /tmp/kube-apiserver.yaml.backup実行結果:
-rw------- 1 root root 4321 May 24 10:04 /tmp/kube-apiserver.yaml.backupStep 2: --etcd-servers のポートを 2379 から 9999 に書き換えます。kube-apiserver が etcd に接続できなくなり、起動失敗を引き起こします。
実行コマンド:
# sed -i 's|--etcd-servers=https://127.0.0.1:2379|--etcd-servers=https://127.0.0.1:9999|' /etc/kubernetes/manifests/kube-apiserver.yaml
# grep etcd-servers /etc/kubernetes/manifests/kube-apiserver.yaml実行結果:
- --etcd-servers=https://127.0.0.1:9999Step 3: kubelet が manifest 変更を検知し、新しい kube-apiserver Pod を起動しようとしますが etcd に接続できず失敗します。30 秒ほど待ってから crictl ps -a でコンテナ状態を確認します。
実行コマンド:
# crictl ps -a | grep kube-apiserver実行結果:
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
a1b2c3d4e5f6 registry... 30 seconds ago Exited kube-apiserver 1 abc123def456
b2c3d4e5f6a7 registry... 90 seconds ago Exited kube-apiserver 0 abc123def456STATE 列が Exited になっており、ATTEMPT が増えていく(再起動を繰り返している)状態です。これが Static Pod 障害の典型的な見え方です。
診断フェーズ
Step 4: crictl logs でコンテナのエラー出力を確認します。コンテナ ID は前のステップの a1b2c3d4e5f6 を使います。
実行コマンド:
# crictl logs a1b2c3d4e5f6 2>&1 | tail -n 20実行結果:
W0524 10:05:00.000000 1 logging.go:55] [core] [Channel #1 SubChannel #2]grpc: addrConn.createTransport failed to connect to {Addr: "127.0.0.1:9999", ServerName: "127.0.0.1:9999"}. Err: connection error: desc = "transport: Error while dialing: dial tcp 127.0.0.1:9999: connect: connection refused"
E0524 10:05:30.123456 1 run.go:74] "command failed" err="context deadline exceeded, ctx err: context deadline exceeded"
F0524 10:05:30.234567 1 hooks.go:210] PostStartHook \"start-service-ip-repair-controllers\" failed: unable to perform initial IP and Port allocation checkconnect: connection refused (127.0.0.1:9999) という明確なエラーが出ています。etcd の標準ポート 2379 ではなく 9999 を指定したため、ポート 9999 で listen しているプロセスがなく、接続拒否となっています。原因が --etcd-servers のポート誤りであることが特定できました。
Step 5: k8s-ops 側で kubectl の挙動を観察します。k8s-cp-01 の API Server が落ちていても、HA 構成のため k8s-lb 経由で k8s-cp-02 / k8s-cp-03 に転送されるため、kubectl は継続して使用できるはずです。
実行コマンド:
$ kubectl get pods -n kube-system -o wide | grep apiserver実行結果:
kube-apiserver-k8s-cp-01 0/1 CrashLoopBackOff 3 2m 192.168.1.125 k8s-cp-01
kube-apiserver-k8s-cp-02 1/1 Running 0 12d 192.168.1.126 k8s-cp-02
kube-apiserver-k8s-cp-03 1/1 Running 0 12d 192.168.1.127 k8s-cp-03k8s-cp-01 の kube-apiserver が CrashLoopBackOff ですが、k8s-cp-02 / k8s-cp-03 は Running を維持しています。HA 構成の冗長性が機能しており、kubectl は継続利用できています。
復旧フェーズ
Step 6: /tmp/ のバックアップから元の manifest を復元します。
実行コマンド:
# cp /tmp/kube-apiserver.yaml.backup /etc/kubernetes/manifests/kube-apiserver.yaml
# grep etcd-servers /etc/kubernetes/manifests/kube-apiserver.yaml実行結果:
- --etcd-servers=https://127.0.0.1:2379Step 7: kubelet が manifest 変更を検知して kube-apiserver を再起動します。30〜60 秒後に Pod が Running に戻ることを確認します。
実行コマンド:
$ kubectl get pods -n kube-system | grep apiserver実行結果:
kube-apiserver-k8s-cp-01 1/1 Running 0 45s
kube-apiserver-k8s-cp-02 1/1 Running 0 12d
kube-apiserver-k8s-cp-03 1/1 Running 0 12dk8s-cp-01 の kube-apiserver が復旧しました。AGE が 45 秒(再起動直後)になっており、新しい Pod として起動したことが分かります。
ポイント解説
- バックアップは
/tmp/など/etc/kubernetes/manifests/外に保存します。manifests/ 内に.bak等で残すと kubelet が両方を Static Pod 定義として読み込み、同名 Pod が 2 定義状態になります。 - manifest 変更後 30〜60 秒で kubelet が自動で Static Pod を再起動します。inotify 監視が取りこぼした場合は
systemctl restart kubeletで強制再読込できます。 - kubectl が応答しない場合の Static Pod 診断には
crictl ps -a(停止コンテナも表示)とcrictl logs <id>が必須です。kubectl とは独立に containerd に直接問い合わせられるため、API Server が落ちていても診断できます。
やってみよう②: etcd backup-restore 失敗診断
2 つ目の演習は etcd restore の「失敗診断」です。第5回では正常な restore 手順を習得しましたが、本回は意図的に失敗した状態の restore を投入し、volumes.hostPath.path の更新漏れを自力で発見・修正する形式で行います。
シナリオ: restore-test Namespace を作成 → etcd snapshot を取得 → Namespace を削除 → etcdutl で新ディレクトリに restore → etcd.yaml の 3 箇所中 2 箇所のみ更新(hostPath.path を未更新のまま)→ etcd は起動するが Namespace が復元されない → grep で 3 箇所確認 → hostPath.path を修正 → restore-test 復元確認。
作業ノード: k8s-cp-01(root 権限)と k8s-ops(developer・kubectl 観察)。
事前準備フェーズ(テストリソース作成)
Step 1: restore 確認用の Namespace と ConfigMap を作成します。後で削除し、restore で復活するかを判定するマーカーになります。
実行コマンド:
$ kubectl create namespace restore-test
$ kubectl create configmap restore-marker -n restore-test --from-literal=created-at=2026-05-24 --from-literal=purpose=etcd-restore-test
$ kubectl get configmap restore-marker -n restore-test実行結果:
namespace/restore-test created
configmap/restore-marker created
NAME DATA AGE
restore-marker 2 5sStep 2: etcd snapshot を /tmp/ に取得します。etcdctl snapshot save は etcd v3.6 でも引き続き有効です(restore のみ廃止)。
実行コマンド:
# ETCDCTL_API=3 etcdctl snapshot save /tmp/etcd-snapshot-15.db \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
# etcdutl snapshot status /tmp/etcd-snapshot-15.db --write-out=table実行結果:
{"level":"info","ts":"2026-05-24T10:08:12.345+0900","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"/tmp/etcd-snapshot-15.db.part"}
{"level":"info","ts":"2026-05-24T10:08:13.789+0900","caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/tmp/etcd-snapshot-15.db"}
Snapshot saved at /tmp/etcd-snapshot-15.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| a1b2c3d4 | 15234 | 892 | 5.2 MB |
+----------+----------+------------+------------+Step 3: テストリソース(restore-test Namespace)を削除します。この後の restore で復活するかが判定基準です。
実行コマンド:
$ kubectl delete namespace restore-test
$ kubectl get namespace restore-test実行結果:
namespace "restore-test" deleted
Error from server (NotFound): namespaces "restore-test" not found障害投入フェーズ(失敗した restore の仕込み)
Step 4: etcd Static Pod を停止します。manifest を /tmp/ に退避する方式で行います(HA クラスタでは k8s-cp-02/03 の etcd が稼働継続するため安全)。
実行コマンド:
# mv /etc/kubernetes/manifests/etcd.yaml /tmp/etcd.yaml.backup
# sleep 15
# crictl ps -a | grep -E '\setcd\s'実行結果:
c3d4e5f6a7b8 registry... 30 seconds ago Exited etcd 0 def456abc789k8s-cp-01 の etcd コンテナが Exited 状態になりました。kube-apiserver も etcd へ接続できないため停止しますが、k8s-cp-02/03 で API は継続稼働しています。
Step 5: etcdutl snapshot restore で新しいデータディレクトリ /var/lib/etcd-restored に復元します。etcd v3.6 では etcdctl snapshot restore は使えません。
実行コマンド:
# etcdutl snapshot restore /tmp/etcd-snapshot-15.db --data-dir=/var/lib/etcd-restored
# ls -la /var/lib/etcd-restored/実行結果:
2026-05-24T10:10:01+0900 info snapshot/v3_snapshot.go:260 restoring snapshot {"path": "/tmp/etcd-snapshot-15.db", "wal-dir": "/var/lib/etcd-restored/member/wal", "data-dir": "/var/lib/etcd-restored", "snap-dir": "/var/lib/etcd-restored/member/snap"}
2026-05-24T10:10:02+0900 info snapshot/v3_snapshot.go:289 restored snapshot {"path": "/tmp/etcd-snapshot-15.db", "wal-dir": "/var/lib/etcd-restored/member/wal", "data-dir": "/var/lib/etcd-restored", "snap-dir": "/var/lib/etcd-restored/member/snap"}
total 8
drwx------ 3 root root 60 May 24 10:10 memberStep 6: 意図的な失敗パターン仕込みです。etcd.yaml の --data-dir と volumeMounts.mountPath は新パスに更新しますが、volumes.hostPath.path を旧パスのまま残します。本来 3 箇所すべて更新が必要です。
実行コマンド:
# sed -i 's|--data-dir=/var/lib/etcd$|--data-dir=/var/lib/etcd-restored|' /tmp/etcd.yaml.backup
# sed -i 's|mountPath: /var/lib/etcd$|mountPath: /var/lib/etcd-restored|' /tmp/etcd.yaml.backup
# grep -n 'data-dir\|hostPath\|/var/lib/etcd' /tmp/etcd.yaml.backup実行結果:
24: - --data-dir=/var/lib/etcd-restored
52: mountPath: /var/lib/etcd-restored
63: path: /var/lib/etcd3 行目(path: /var/lib/etcd)が旧パスのまま残っています。これが本回の失敗パターン仕込みです。
Step 7: manifest を /etc/kubernetes/manifests/ に戻し、失敗状態のまま etcd を起動します。
実行コマンド:
# cp /tmp/etcd.yaml.backup /etc/kubernetes/manifests/etcd.yaml
# sleep 45
# crictl ps | grep -E '\setcd\s'実行結果:
e5f6a7b8c9d0 registry... 40 seconds ago Running etcd 0 def456abc789etcd は Running で起動しました。ところが restore された内容が反映されていません(これから診断する状態です)。
診断フェーズ
Step 8: restore-test Namespace が復元されたかを確認します。
実行コマンド:
$ kubectl get namespace restore-test実行結果:
Error from server (NotFound): namespaces "restore-test" not foundetcd は起動していますが、restore したはずの restore-test Namespace が見えません。restore が反映されていない状態です。原因を探ります。
Step 9: etcd.yaml 内で /var/lib/etcd を参照する全箇所を grep して、不整合を発見します。
実行コマンド:
# grep -n 'data-dir\|hostPath\|/var/lib/etcd' /etc/kubernetes/manifests/etcd.yaml実行結果:
24: - --data-dir=/var/lib/etcd-restored
52: mountPath: /var/lib/etcd-restored
63: path: /var/lib/etcd3 行のうち 24 行目と 52 行目は /var/lib/etcd-restored(新パス)になっていますが、63 行目の hostPath.path だけが /var/lib/etcd(旧パス)のままです。これが症状の原因です。
動作原理としては、hostPath.path が「ホスト上の実ディレクトリ」を指定します。ここが旧パスのままだと、ホストの旧データディレクトリ(restore 前の古いデータ)がコンテナにマウントされ、コンテナ内では新パス(--data-dir)で参照されます。つまり「コンテナ内のパスは新しいが、中身は古い」状態です。
復旧フェーズ
Step 10: hostPath.path を新パスに修正します。
実行コマンド:
# sed -i 's|path: /var/lib/etcd$|path: /var/lib/etcd-restored|' /etc/kubernetes/manifests/etcd.yaml
# grep -n 'data-dir\|hostPath\|/var/lib/etcd' /etc/kubernetes/manifests/etcd.yaml実行結果:
24: - --data-dir=/var/lib/etcd-restored
52: mountPath: /var/lib/etcd-restored
63: path: /var/lib/etcd-restoredStep 11: kubelet が manifest 変更を検知して etcd Pod を再起動します。restore-test Namespace と ConfigMap が復元されることを確認します。
実行コマンド(root 権限・k8s-cp-01 上):
# systemctl restart kubelet続いて developer 権限(k8s-ops)から復元状態を確認します。実行コマンド:
$ sleep 30
$ kubectl get namespace restore-test
$ kubectl get configmap restore-marker -n restore-test実行結果:
NAME STATUS AGE
restore-test Active 3s
NAME DATA AGE
restore-marker 2 3srestore-test Namespace と restore-marker ConfigMap が復元されました。AGE が新しく見えるのは API 再認識のためで、内部の creationTimestamp は snapshot 時点のものを保持しています。
ポイント解説(「3 箇所すべて更新する」理由)
| 行 | フィールド | 役割 |
|---|---|---|
| 24 | --data-dir | etcd プロセスが「データディレクトリ」として認識するパス(コンテナ内視点) |
| 52 | volumeMounts.mountPath | コンテナ内のマウントポイント(--data-dir と一致必須) |
| 63 | volumes.hostPath.path | ホスト上の実ディレクトリ(コンテナにマウントされる実体) |
3 行は連動しています。コンテナの volumeMounts.mountPath はホストの volumes.hostPath.path がマウントされる場所で、その同じパスを --data-dir として etcd プロセスに渡します。1 箇所でも旧パスのままだと、ホストの旧ディレクトリ(旧データ)がコンテナの新パスにマウントされてしまい、restore 内容が反映されません。
etcd v3.6 重要注意: etcdctl snapshot restore は etcd v3.6 で完全廃止されました。restore には必ず etcdutl snapshot restore を使ってください。etcdctl snapshot save は引き続き有効です。役割分担を「save は etcdctl・restore と status は etcdutl」と覚えると混乱しません。
演習後クリーンアップ
restore-test Namespace を削除します。/tmp/etcd-snapshot-15.db と /tmp/etcd.yaml.backup も不要になれば削除します。
実行コマンド:
$ kubectl delete namespace restore-test実行結果:
namespace "restore-test" deletedやってみよう③: kubelet 復旧(systemd)
3 つ目の演習は kubelet の停止と復旧です。kubelet は systemd ユニットなので、Static Pod とは異なり systemctl と journalctl で操作・診断します。
シナリオ: k8s-cp-01 の kubelet を systemctl stop で停止 → k8s-cp-01 の Static Pod が全停止 → k8s-cp-01 が NotReady になる → journalctl -u kubelet でログ確認 → systemctl start kubelet で復旧 → kubectl get nodes で Ready 確認。
作業ノード: k8s-cp-01(root 権限・障害投入と復旧)と k8s-ops(developer・kubectl 観察)。
HA 安全活用の事前確認
Step 0: k8s-cp-02 / k8s-cp-03 の apiserver が稼働中であることを確認します。これが Running でないと、k8s-cp-01 を停止したときに kubectl 自体が不通になります。
実行コマンド:
$ kubectl get pods -n kube-system | grep apiserver実行結果:
kube-apiserver-k8s-cp-01 1/1 Running 0 10m
kube-apiserver-k8s-cp-02 1/1 Running 0 12d
kube-apiserver-k8s-cp-03 1/1 Running 0 12d障害投入フェーズ
Step 1: k8s-cp-01 上で kubelet を停止します。停止後 kubectl get nodes でノードが NotReady に変化するまでには約 40 秒かかります(--node-monitor-grace-period のデフォルト値・node-controller がノードからの heartbeat 喪失を検知するまでの猶予時間)。即座に NotReady にならなくても焦らず、40 秒以上経過してから状態確認してください。
実行コマンド:
# systemctl stop kubelet
# systemctl status kubelet --no-pager実行結果:
○ kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; preset: disabled)
Active: inactive (dead) since Sun 2026-05-24 10:20:00 JST; 5s ago
Docs: https://kubernetes.io/docs/
Process: 12340 ExecStart=/usr/bin/kubelet ... (code=exited, status=0/SUCCESS)
Main PID: 12340 (code=exited, status=0/SUCCESS)Active 行が inactive (dead) になり、kubelet が停止しました。
診断フェーズ
Step 2: k8s-ops 側で k8s-cp-01 が NotReady になることを確認します。30〜40 秒程度で node lease の更新が止まり、コントローラーが NotReady を判定します。
実行コマンド:
$ sleep 40
$ kubectl get nodes実行結果:
NAME STATUS ROLES AGE VERSION
k8s-cp-01 NotReady control-plane 20d v1.35.5
k8s-cp-02 Ready control-plane 20d v1.35.5
k8s-cp-03 Ready control-plane 20d v1.35.5
k8s-wl-01 Ready <none> 20d v1.35.5
k8s-wl-02 Ready <none> 20d v1.35.5k8s-cp-01 だけが NotReady、他は Ready のままです。kubectl が継続して動作しているのは k8s-lb 経由で k8s-cp-02/03 の apiserver に転送されているためです。
Step 3: k8s-cp-01 上で journalctl でログを確認します。停止前後の動作を見ます。
実行コマンド:
# journalctl -u kubelet -n 20 --no-pager実行結果:
May 24 10:19:55 k8s-cp-01 kubelet[12340]: I0524 10:19:55.123456 12340 kubelet.go:2461] "SyncLoop (PLEG): event for pod" pod="kube-system/kube-apiserver-k8s-cp-01"
May 24 10:20:00 k8s-cp-01 systemd[1]: Stopping kubelet: The Kubernetes Node Agent...
May 24 10:20:00 k8s-cp-01 kubelet[12340]: I0524 10:20:00.234567 12340 server.go:1357] "Received signal" signal="terminated"
May 24 10:20:00 k8s-cp-01 systemd[1]: kubelet.service: Deactivated successfully.
May 24 10:20:00 k8s-cp-01 systemd[1]: Stopped kubelet: The Kubernetes Node Agent.Stopping kubelet → Received signal terminated → Deactivated successfully のシーケンスが見えます。systemctl stop による正常停止と確認できました。
Step 4: k8s-cp-01 の Static Pod が全停止していることを crictl で確認します。kubelet が停止すると Static Pod の管理者がいなくなるため、kube-apiserver / etcd / scheduler / controller-manager のコンテナはすべて Exited 状態になります。
実行コマンド:
# crictl ps -a | grep -E 'kube-apiserver|^[a-f0-9]+\s+\S+\s+\S+\s+\S+\s+\S+\s+(etcd|kube-scheduler|kube-controller-manager)\s'実行結果:
a1b2c3d4e5f6 registry... 2 minutes ago Exited kube-apiserver 0 ...
c3d4e5f6a7b8 registry... 2 minutes ago Exited etcd 0 ...
e5f6a7b8c9d0 registry... 2 minutes ago Exited kube-scheduler 0 ...
f6a7b8c9d0e1 registry... 2 minutes ago Exited kube-controller-manager 0 ...4 コンポーネントすべて Exited 状態です。kubelet が止まると、kubelet が管理する Static Pod も停止することが分かります。
復旧フェーズ
Step 5: kubelet を起動します。
実行コマンド:
# systemctl start kubelet
# systemctl status kubelet --no-pager実行結果:
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; preset: disabled)
Active: active (running) since Sun 2026-05-24 10:21:00 JST; 3s ago
Docs: https://kubernetes.io/docs/
Main PID: 13456 (kubelet)
Tasks: 12 (limit: 38234)
Memory: 45.2M
CPU: 1.234sActive 行が active (running) になりました。
Step 6: k8s-ops で k8s-cp-01 が Ready に戻ることを確認します。kubelet が起動するとすぐに node lease の更新が再開されるため、20〜30 秒で Ready に戻ります。
実行コマンド:
$ sleep 30
$ kubectl get nodes実行結果:
NAME STATUS ROLES AGE VERSION
k8s-cp-01 Ready control-plane 20d v1.35.5
k8s-cp-02 Ready control-plane 20d v1.35.5
k8s-cp-03 Ready control-plane 20d v1.35.5
k8s-wl-01 Ready <none> 20d v1.35.5
k8s-wl-02 Ready <none> 20d v1.35.5Step 7: k8s-cp-01 の Static Pod 復旧を確認します。
実行コマンド:
$ kubectl get pods -n kube-system --field-selector spec.nodeName=k8s-cp-01実行結果:
NAME READY STATUS RESTARTS AGE
etcd-k8s-cp-01 1/1 Running 0 1m
kube-apiserver-k8s-cp-01 1/1 Running 0 1m
kube-controller-manager-k8s-cp-01 1/1 Running 0 1m
kube-scheduler-k8s-cp-01 1/1 Running 0 1m4 つの Static Pod すべて Running に復帰しました。
journalctl の主要オプション
| コマンド | 用途 |
|---|---|
journalctl -u kubelet -f | リアルタイム追跡(障害発生中の確認) |
journalctl -u kubelet -n 100 --no-pager | 直近 100 行表示(過去ログ確認) |
journalctl -u kubelet --since "5 minutes ago" | 直近 5 分のログ |
journalctl -u kubelet -p err | ERROR 以上のみ |
journalctl -u kubelet --since today --until "1 hour ago" | 当日かつ 1 時間以上前まで |
やってみよう④: API Server 不通(kubeconfig server 誤値)
4 つ目の演習は kubeconfig の server URL を誤った値に設定し、kubectl の応答不能を診断・修正します。クラスタ側に問題はないのに、クライアント側設定だけで kubectl が動かなくなるパターンです。CKA D5「Troubleshoot services and networking」の対応スキルです。
シナリオ: k8s-ops の ~/.kube/config の server URL を誤値に変更 → kubectl が全コマンド不通 → kubectl config view で診断 → kubectl config set-cluster で修正 → 復旧確認。
作業ノード: k8s-ops(developer ユーザー)。
事前バックアップ
Step 1: kubeconfig を /tmp/ にバックアップします。本番警告④の通り、誤設定で kubectl が不通になっても、ファイル直接編集で復元できるようにしておきます。
実行コマンド:
$ cp ~/.kube/config /tmp/kube-config.backup
$ kubectl config view --minify | grep server実行結果:
server: https://k8s-lb:6443現在の server URL は https://k8s-lb:6443(k8s-lb の HAProxy アドレス)です。
障害投入フェーズ
Step 2: kubectl config set-cluster でポートを 9999 に変更します。
実行コマンド:
$ kubectl config set-cluster kubernetes --server=https://k8s-lb:9999
$ kubectl config view --minify | grep server実行結果:
Cluster "kubernetes" set.
server: https://k8s-lb:9999Step 3: kubectl が不通になることを確認します。
実行コマンド:
$ kubectl get nodes実行結果:
E0524 10:25:00.123456 14567 memcache.go:265] couldn't get current server API group list: Get "https://k8s-lb:9999/api?timeout=32s": dial tcp 192.168.1.124:9999: connect: no route to host
Unable to connect to the server: dial tcp 192.168.1.124:9999: connect: no route to hostkubectl は完全に不通になりました。サーバ側に問題があるのではなく、クライアント設定が誤っていることを示すエラーです。
診断フェーズ
Step 4: kubectl config view で kubeconfig の内容を確認します。config view はサーバへ問い合わせず、ローカルファイルを読むだけなので、kubectl が不通でも実行できます。
実行コマンド:
$ kubectl config view実行結果:
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://k8s-lb:9999
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTEDserver 行が https://k8s-lb:9999 になっており、ポートが誤っていることが分かります。正しいポートは 6443 です。
Step 5: kubectl config get-contexts でコンテキスト一覧を確認します。これもローカルファイル参照のみで動作します。
実行コマンド:
$ kubectl config get-contexts実行結果:
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* kubernetes-admin@kubernetes kubernetes kubernetes-admin復旧フェーズ
Step 6: kubectl config set-cluster で正しいポートに修正します。
実行コマンド:
$ kubectl config set-cluster kubernetes --server=https://k8s-lb:6443実行結果:
Cluster "kubernetes" set.Step 7: kubectl の復旧を確認します。
実行コマンド:
$ kubectl config view --minify | grep server
$ kubectl get nodes実行結果:
server: https://k8s-lb:6443
NAME STATUS ROLES AGE VERSION
k8s-cp-01 Ready control-plane 20d v1.35.5
k8s-cp-02 Ready control-plane 20d v1.35.5
k8s-cp-03 Ready control-plane 20d v1.35.5
k8s-wl-01 Ready <none> 20d v1.35.5
k8s-wl-02 Ready <none> 20d v1.35.5kubectl が復旧しました。
kubectl config 診断コマンド一覧
| コマンド | 用途 |
|---|---|
kubectl config view | kubeconfig 全体表示(ローカル読込のみ) |
kubectl config view --minify | 現在コンテキストのみ表示 |
kubectl config get-contexts | コンテキスト一覧 |
kubectl config current-context | 現在のコンテキスト名 |
kubectl config set-cluster <name> --server=<url> | server URL 更新 |
kubectl cluster-info | 実際の接続先確認(API へ問い合わせるため不通時は失敗) |
よくある誤設定パターンと症状
| 誤設定例 | エラーメッセージ | 修正方法 |
|---|---|---|
| ポート誤り(9999 等) | connection refused | set-cluster --server でポート修正 |
| IP アドレス誤り | no route to host または timeout | set-cluster --server で IP 修正 |
http:// で設定(TLS なし) | server gave HTTP response to HTTPS client | https:// に変更 |
| 名前解決失敗(hostname 誤り) | no such host | IP アドレスで再設定 |
現場ヒヤリハット 3 本と CKA D5 対応総括
ヒヤリハット①: manifests/ 内にバックアップを作成して 2 重起動
状況: 緊急対応で kube-apiserver.yaml を編集する前に、念のため同ディレクトリで cp kube-apiserver.yaml kube-apiserver.yaml.bak としてバックアップを取った。直後に kube-apiserver が CrashLoopBackOff になり、crictl ps -a で見ると kube-apiserver コンテナが 2 つ起動しようとしていた。
原因: kubelet は /etc/kubernetes/manifests/ 内の「. で始まらない全ファイル」を Static Pod 定義として読み込みます。拡張子フィルタはないため、.bak も対象です。同じ Pod 名(kube-apiserver-k8s-cp-01)で 2 つの定義が同時にロードされ、ポート競合で両方失敗します。
対処: バックアップは必ず manifests/ 外(/tmp/ 等)に保存します。manifests/ 内に置きたい場合はファイルを完全に削除するか、ドット始まり(.kube-apiserver.yaml.bak)にすれば kubelet は読み込みません。
ヒヤリハット②: etcd restore 後に 3 箇所中 1 箇所更新漏れ
状況: 本番 etcd restore 作業中、etcd.yaml の --data-dir と volumeMounts.mountPath は更新したが volumes.hostPath.path を忘れた。etcd は起動するが、なぜか restore 前のデータがそのまま見える状態。
原因: hostPath.path がホスト上の実ディレクトリを指しており、ここが旧パスのままだと旧データがコンテナにマウントされます。--data-dir と mountPath はコンテナ内視点のパスなので、見かけ上は新パスだが中身は旧データという状態が起こります。
対処: grep -n 'data-dir\|hostPath\|/var/lib/etcd' /etc/kubernetes/manifests/etcd.yaml で 3 箇所すべてが新パスになっているかを確認する習慣をつけます。本回の演習②そのもののパターンです。
ヒヤリハット③: etcd v3.6 で etcdctl snapshot restore を試みてコマンドが見つからない
状況: 過去の運用メモを見て etcdctl snapshot restore を実行したら Error: unknown command "restore" for "etcdctl snapshot" が返った。
原因: etcd v3.5 で deprecated 宣告された etcdctl snapshot restore が v3.6 で完全削除されました。本シリーズ環境(etcd v3.6.6)では etcdutl snapshot restore のみ有効です。
対処: 「save は etcdctl・restore と status は etcdutl」と役割で覚えます。etcdctl は etcd サーバへ TCP 接続して操作するクライアント、etcdutl はローカルファイルへの直接操作ユーティリティ、と機能が整理されました。
第15回まとめ(CKA D5 対応表)
| CKA D5 スキル | 第15回演習での対応 |
|---|---|
| Troubleshoot cluster components | 演習① kube-apiserver Static Pod 障害診断・復旧 |
| Troubleshoot clusters and nodes | 演習③ kubelet 停止 → journalctl 診断 → 復旧 |
| Manage and evaluate container output streams | crictl logs / journalctl によるログ確認 |
| Monitor cluster and application resource usage | crictl ps -a / kubectl get pods -n kube-system |
| Troubleshoot services and networking | 演習④ kubeconfig server URL 誤設定診断 |
| Manage etcd (D1) | 演習② etcd restore 失敗診断・hostPath.path 整合性 |
第6部「トラブルシュート」進捗: 2 回中 1 回完走。次回(第16回)で Workload Node + Network + App トラブルシュートを完成させ、第2巻完走宣言となります。
理解度チェック(○×・7 問)
- kubelet は
/etc/kubernetes/manifests/ディレクトリ内の.yaml拡張子のファイルのみを Static Pod 定義として読み込む crictl psは kubectl が応答しない状況でも Control Plane コンテナの状態を確認できる- etcd v3.6 では
etcdctl snapshot restoreは廃止されており、etcdutl snapshot restoreを使用する必要がある etcdutl snapshot restoreで--data-dirに指定したパスが既存ディレクトリの場合、既存データに上書きして restore が実行されるetcd.yamlの--data-dir・volumeMounts.mountPath・volumes.hostPath.pathの 3 箇所をすべて新しいデータディレクトリに更新しないと、restore 内容がクラスタに反映されない- HA クラスタ(CP×3)で k8s-cp-01 の kubelet を
systemctl stopで停止しても、k8s-cp-02/03 が稼働していれば kubectl コマンドは継続して使用できる kubectl config set-cluster kubernetes --server=https://k8s-lb:6443を実行すると、~/.kube/configのserverフィールドが更新される
各問の正解と解説を以下に示します。先に自分で○か×を考えてから読み進めてください。
問 1: × — kubelet は「.(ドット)で始まらない全ファイル」を Static Pod 定義として読み込みます。拡張子フィルタはありません。そのため .yaml.bak や .json も対象になり、manifests/ 内でのバックアップは禁忌です。
問 2: ○ — crictl は containerd(または CRI 互換ランタイム)に直接問い合わせるツールです。kube-apiserver が落ちていても、ノード上で動いているコンテナの状態を crictl ps -a や crictl logs で確認できます。Static Pod 障害診断の中核ツールです。
問 3: ○ — etcd v3.5 で deprecated、v3.6 で完全削除されました。本シリーズ環境(etcd v3.6.6)では etcdutl snapshot restore のみ有効です。etcdctl snapshot save(save 側)は引き続き有効である点に注意します。
問 4: × — etcdutl snapshot restore は --data-dir に既存ディレクトリを指定するとエラー(Error: data-dir <path> not empty or could not be read)になります。新ディレクトリ名を指定するか、事前に既存ディレクトリを退避します。
問 5: ○ — 3 箇所は連動しています。--data-dir(プロセス引数)と volumeMounts.mountPath(コンテナ内マウント点)と volumes.hostPath.path(ホスト実ディレクトリ)の 3 つすべてが新パスに揃っていないと、ホストの旧データがコンテナにマウントされる現象が起こります。
問 6: ○ — k8s-ops の kubectl は k8s-lb(HAProxy)経由で k8s-cp-02/03 の apiserver に転送されます。k8s-cp-01 の apiserver / etcd / kubelet が止まっても HA の冗長性で API は継続稼働します。これが本回の演習を安全に行える根拠です。
問 7: ○ — kubectl config set-cluster はカレントの kubeconfig ファイル($KUBECONFIG または ~/.kube/config)の clusters[name=<name>].cluster.server フィールドを書き換えます。サブコマンドはローカルファイル操作のみで、API への問い合わせは発生しません。
次回予告
第16回は Workload Node + Network + App トラブルシュート演習 + 第2巻完走宣言 回です。Workload Node の NotReady 診断、NetworkPolicy によるアクセス遮断の解除、CrashLoopBackOff アプリの修正など、実務で最も頻繁に直面する障害シナリオを網羅します。第2巻で学んだすべての技術スタック(kubeadm HA クラスタ・etcd・Calico・MetalLB・Gateway API・Longhorn・ArgoCD・Velero)の集大成として、読者が「立派な Kubernetes エンジニア」として自信を持てる完走宣言で第2巻を締めくくります。
シリーズ一覧
第1部:クラスタ構築
- 第1回 第2巻スコープ + CKA 試験形式紹介 + kubeadm 概要 + kubeadm vs RKE2/k0s/OKD 概観
- 第2回 kubeadm シングルノード起動(pkgs.k8s.io + kubeadm init + Calico CNI)+ alma-proxy whitelist 構築
- 第3回 kubeadm HA 設計 + HAProxy LB(API Server LB 構成)
- 第4回 kubeadm HA クラスタ構築(CP×3 + WL×2)+ fanclub-api HA 移行
- 第5回 etcd backup/restore(etcdutl)+ ノード drain/uncordon
第2部:ワークロード管理
- 第6回 kubeadm upgrade + ノード drain/cordon + ミニトラブルシュート演習
- 第7回 Pod スケジューリング(taint/toleration/affinity/anti-affinity/PriorityClass)
- 第8回 HPA + ResourceQuota + LimitRange
第3部:ネットワーク
- 第9回 Service 詳細 + MetalLB(LoadBalancer 動作確認)
- 第10回 NetworkPolicy 詳細 + Calico/Cilium 比較 + ミニトラブルシュート演習
- 第11回 Gateway API + Traefik + cert-manager + CoreDNS(HTTPS 公開完成)
第4部:ストレージ
第5部:監視・運用
- 第13回 Prometheus + Grafana + Loki + Fluent Bit + fanclub-api 監視ダッシュボード
- 第14回 Helm + Kustomize でクラスタコンポーネント install + ArgoCD GitOps + Velero backup
第6部:トラブルシュート
- 第15回 Control Plane + etcd トラブルシュート演習(Static Pod / etcdctl / kubelet 復旧) ← 今ここ
- 第16回 Workload Node + Network + App トラブルシュート演習 + 第2巻完走宣言 ★
