
新卒インフラエンジニア向け Kubernetes 実践教科書(第2巻 CKA 編)の第12回です。動作確認バージョン: AlmaLinux 10.1 / K8s v1.35.5 / Longhorn v1.11.1(Helm chart)/ PostgreSQL 18-alpine / kubeadm v1.35.5(2026-05-24 時点)
- 今ここマップ(第12回 / 全16回 / 第4部完走)
- 第12回のスコープと設計 — 6 機構の依存関係を把握する
- PV / PVC / StorageClass の関係をおさらいする
- アクセスモード(RWO / ROX / RWX / RWOP)と Reclaim Policy
- Longhorn アーキテクチャ — 分散ストレージの仕組み
- WL ノード前提準備 — iscsi-initiator-utils + /dev/sdb フォーマット
- やってみよう① — Longhorn v1.11.1 Helm インストール
- やってみよう② — SC 切替(local-path の default を解除・longhorn を唯一の default に)
- Step 1: local-path SC の default アノテーション解除
- Step 2: longhorn が唯一の default になったことを確認
- Step 3: sts-demo Namespace と demo StatefulSet を作成(旧 SC で)
- Step 4: volumeClaimTemplates を longhorn に変更しようと kubectl apply を試みる
- Step 5: –cascade=orphan で StatefulSet のみ削除
- Step 6: 旧 PVC を削除 + longhorn SC で StatefulSet 再作成
- Step 7: sts-demo Namespace ごと削除(クリーンアップ)
- やってみよう③ — fanclub-db StatefulSet デプロイ
- 既存 PVC の StorageClass 切替手順(–cascade=orphan パターンの一般化)
- まとめ・現場ヒヤリハット・理解度チェック
- シリーズ一覧
今ここマップ(第12回 / 全16回 / 第4部完走)
今ここ: 第12回 / 全16回(第4部:ストレージ)
▓▓▓▓▓▓▓▓▓▓▓▓░░░░ 75%
第1部(クラスタ構築): ■■■■■ 5/5 回(完了)
第2部(ワークロード管理): ■■■ 3/3 回(完了)
第3部(ネットワーク): ■■■ 3/3 回(完了)
第4部(ストレージ): ■ 1/1 回(完了)← 今ここ
第5部(監視・運用): □□ 0/2 回
第6部(トラブルシュート): □□ 0/2 回第11回では Gateway API + Traefik + cert-manager + CoreDNS の 4 機構連携で https://fanclub.local を実現しました。第3部「ネットワーク」を完走した今、データ層を強化します。第12回では分散ストレージ Longhorn v1.11.1 を導入し、fanclub-db(PostgreSQL 18)を耐障害性のあるボリュームで稼働させます。
第12回のキャッチコピー: 「PV / PVC / StorageClass + Longhorn 分散ストレージ + fanclub-db StatefulSet の 6 機構連携でデータ層を本番化する」
第12回は第4部「ストレージ」の単独回です。CKA D4「Storage」(10%)に対応し、PostgreSQL 18 を StatefulSet として Longhorn ボリューム上に配置します。データロスにつながる本番リスクを 4 件明示し、StatefulSet の volumeClaimTemplates 不変制約に対する --cascade=orphan の安全な扱い方を実機で体験します。
第12回終了時の達成状態:
kubectl get pods -n longhorn-systemで longhorn-manager / longhorn-driver-deployer / csi-* / longhorn-ui がRunning- Longhorn UI(NodePort 経由)でダッシュボードが開き、k8s-wl-01 / k8s-wl-02 が
Schedulable表示 kubectl get scでlonghorn (default)が表示され、local-pathは default でなくなっているkubectl get pods -n fanclubでfanclub-db-0がRunningkubectl get pvc -n fanclubでfanclub-db-data-fanclub-db-0がBoundかつSTORAGECLASS: longhorn- Longhorn UI で fanclub-db の Volume が
Healthy・レプリカ 2 台(k8s-wl-01 + k8s-wl-02) - StatefulSet の
volumeClaimTemplates不変制約と--cascade=orphan削除手順を演習で体験済み
第12回のスコープと設計 — 6 機構の依存関係を把握する
本セクションでは、第12回で扱うこと・扱わないこと、Longhorn 導入のフロー、演習 Namespace 設計、本番運用での 4 件の警告を整理します。
第12回で「やること」と「やらないこと」
| やること | やらないこと |
|---|---|
| PV / PVC / StorageClass の理論整理 | NFS サーバー構築(本環境スコープ外) |
| Longhorn v1.11.1 Helm インストール + ディスク登録 | Longhorn の Snapshot / Backup(MinIO 連携は第3巻外) |
| local-path → longhorn デフォルト SC 切替 | Rook-Ceph(第3巻で検討・本回スコープ外) |
| fanclub-db StatefulSet + HeadlessService + Secret | CloudNativePG(次のシリーズで検討) |
| StatefulSet volumeClaimTemplates 不変制約演習(demo) | PV の手動プロビジョニング詳細(動的プロビジョニングで代替) |
Longhorn 導入フロー図

6 ステップは順序依存です。iscsid が起動していなければ Volume のアタッチが失敗し、ディスクフォーマット前に Longhorn を入れるとレプリカが /var/lib/longhorn(OS ディスク)に配置されてしまい、SC 切替前に StatefulSet を作ると意図しない local-path が選択されます。
演習 Namespace の設計
| Namespace | 役割 | 削除タイミング |
|---|---|---|
longhorn-system(新規) | Longhorn コンポーネント全体(manager / driver-deployer / csi-* / ui) | 削除しない |
sts-demo(新規) | StatefulSet volumeClaimTemplates 変更演習用 | やってみよう② 完了後に削除 |
fanclub(既存) | fanclub-api 稼働中 + fanclub-db(本回で追加) | 変更しない |
設計判断 6 件
判断① Longhorn v1.11.1 を Helm でインストール・defaultReplicaCount=2
本環境は WL ノード 2 台(k8s-wl-01 / k8s-wl-02)のため、デフォルトの 3 レプリカでは PVC が Pending のままになります。Helm values で defaultSettings.defaultReplicaCount: 2 と persistence.defaultClassReplicaCount: 2 を指定し、longhorn SC の numberOfReplicas も 2 に揃えます。persistence.defaultClass: true(Helm のデフォルト)で longhorn SC が default アノテーション付きで自動作成されます。なお本番では「ノード数 ≧ replica + 1」の設計指針が一般的です(例: WL 3 台環境 → replica 2 で 1 ノード障害許容・WL 5 台環境 → replica 3 で 2 ノード障害許容)。replica 数とノード数が一致する設計(ノード数 = replica)だと、1 ノード障害で全 replica が消失する可能性があり推奨されません。
判断② local-path SC の is-default-class アノテーションを解除してから longhorn を default にする
Longhorn Helm インストール直後は local-path (default) と longhorn (default) が共存し、storageClassName 未指定 PVC が「最も新しい default SC」を使う不安定な状態になります。kubectl patch storageclass local-path で storageclass.kubernetes.io/is-default-class: "false" に変更し、default を 1 つに絞ります。
判断③ WL ノードの /dev/sdb を xfs フォーマット + /mnt/longhorn-disk にマウント
environment.md で k8s-wl-01 / 02 は「40 GB OS + 40 GB Longhorn」と定義済みです。Longhorn は OS ディスク(/dev/sda)とは別の専用ディスクを使うのが本番の作法です。AlmaLinux 10.1(kernel 6.12+)は最新 XFS(CRC / reflink 機能)対応済みのため、mkfs.xfs /dev/sdb + /etc/fstab に UUID 指定で永続化します。
判断④ iscsi-initiator-utils は Longhorn インストール前に WL ノード全台でインストール済みを前提とする
Longhorn の Volume attach / detach は iSCSI を経由します。iscsid が未起動のまま Longhorn Pod が Volume をアタッチしようとすると CrashLoopBackOff になります。environment.md に「k8s-wl-01〜02 に iscsi-initiator-utils インストール済み」と明記済みのため(SP_vol2-pre-12 前提状態)、本回では systemctl status iscsid でインストール済み・起動済みを確認します。
判断⑤ fanclub-db は本回で新規デプロイ(PostgreSQL 18 StatefulSet + HeadlessService + Secret)
fanclub-api Helm chart は backend(Java / Payara Micro)のみで DB は含まれていません(第1巻からの設計)。第11回終了時点で fanclub-db は未デプロイのため、本回で初回デプロイします。PostgreSQL 18 では PGDATA=/var/lib/postgresql/data/pgdata(サブディレクトリ)を指定し、xfs フォーマット直後の lost+found 問題を回避します。
判断⑥ StatefulSet volumeClaimTemplates 変更演習は demo StatefulSet で実施する
fanclub-db は本回が初回デプロイのため、--cascade=orphan 削除手順の演習は sts-demo Namespace の demo StatefulSet で安全に実施します。本番データを使う代わりに demo で挙動を体験してから、本回 H2「既存 PVC の StorageClass 切替手順」で一般化した手順を理解します。
PV / PVC / StorageClass の関係をおさらいする
本セクションでは、PV(PersistentVolume)/ PVC(PersistentVolumeClaim)/ StorageClass の役割分担と、静的プロビジョニング・動的プロビジョニングの違い、PV ライフサイクルを整理します。CKA D4「Storage」の理論部分の核です。
PV / PVC / SC の役割分担図
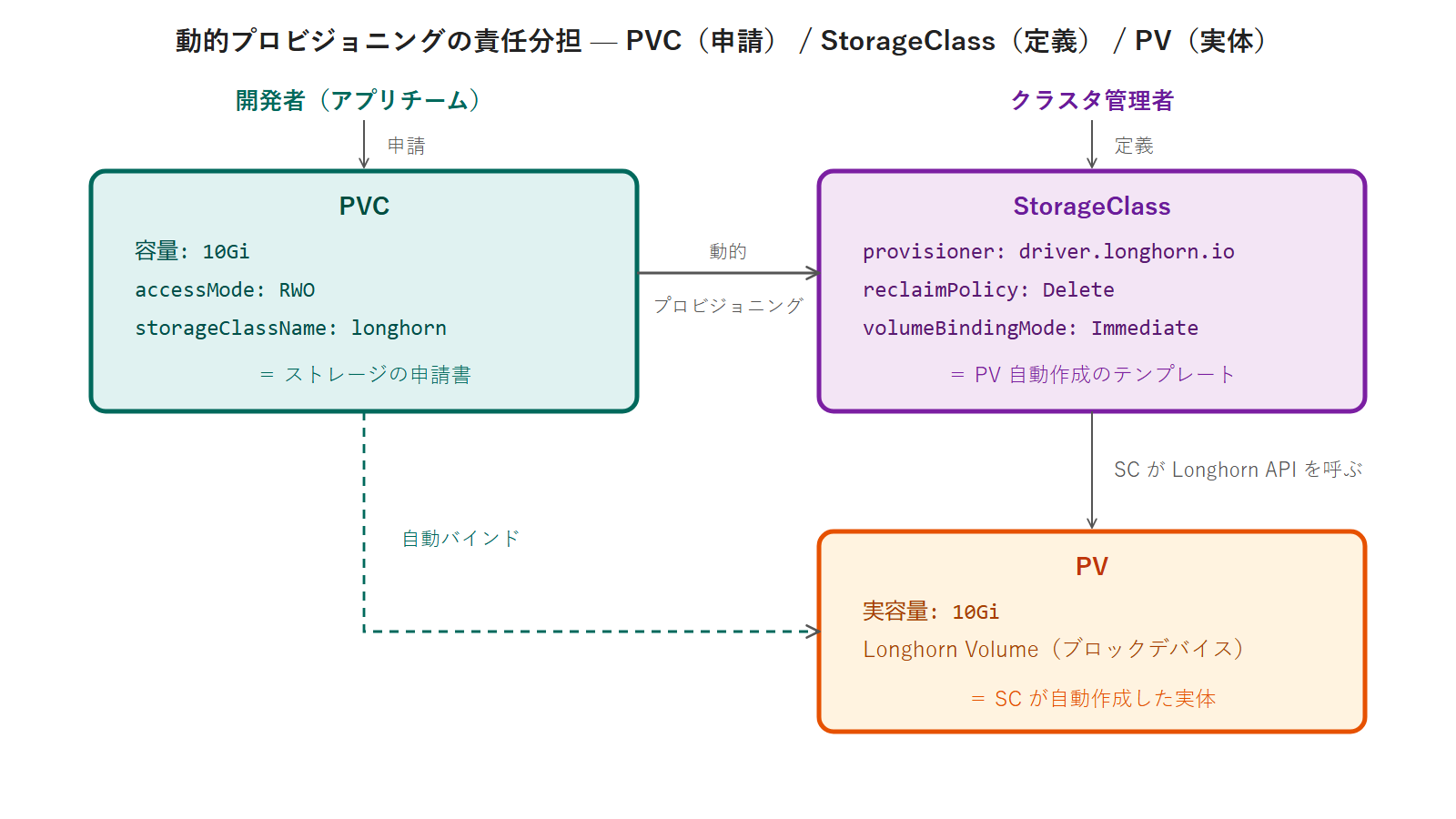
PV は「実際のストレージ実体(Longhorn Volume / NFS export / EBS Volume など)」を Kubernetes に登録したオブジェクトです。PVC は「アプリが必要なストレージの要件(容量・accessMode・SC)」を宣言する申請書です。StorageClass は「動的プロビジョニング時にどのドライバーで PV を自動作成するか」を定義したテンプレートです。
静的プロビジョニングと動的プロビジョニングの比較
| 項目 | 静的プロビジョニング | 動的プロビジョニング |
|---|---|---|
| PV 作成者 | クラスタ管理者が手動作成 | StorageClass が自動作成 |
| 運用コスト | 高い(PV 枯渇・サイズ調整が手動) | 低い(PVC 申請で自動確保) |
| CKA 試験での出題 | PV/PVC マニュアル作成として出題あり | StorageClass の動作理解が必須 |
| 本環境での使い方 | 第3部まで emptyDir / hostPath(擬似的) | 第12回から Longhorn SC で動的プロビジョニング |
PV ライフサイクル(5 状態)
- Provisioning: SC が Volume を作成(動的)または管理者が PV を作成(静的)
- Binding: PVC と PV が 1:1 でバインド(容量・accessMode が一致したもの)
- Using: Pod が PVC をマウントして利用中
- Releasing: PVC が削除されると PV は
Released状態 - Reclaiming:
reclaimPolicyに従い Delete(削除)または Retain(保持)
動的プロビジョニングでは Provisioning と Binding が透過的に進みます。PVC を kubectl apply した時点で SC が PV を自動作成し、即座にバインドされます。第1巻の kind 環境では擬似的に emptyDir や hostPath を使っていましたが、これらはノード再起動で消える「擬似ボリューム」でした。第12回からは Longhorn による真の PV を扱います。
アクセスモード(RWO / ROX / RWX / RWOP)と Reclaim Policy
PVC / PV のアクセスモードと、PVC 削除時に PV をどう扱うかの reclaimPolicy は CKA D4 の頻出ポイントです。本セクションで一通り押さえます。
4 種類のアクセスモード
| モード | 省略形 | 説明 | 主な用途 |
|---|---|---|---|
| ReadWriteOnce | RWO | 単一ノードから読み書き可能(K8s v1.22 以前は単一 Pod も可) | DB・StatefulSet(fanclub-db もこれ) |
| ReadOnlyMany | ROX | 複数ノードから読み取り専用でマウント可 | 静的コンテンツ・設定ファイル共有 |
| ReadWriteMany | RWX | 複数ノードから読み書き可能 | 共有ログ・CMS メディア(NFS / Longhorn RWX 対応) |
| ReadWriteOncePod | RWOP | 単一 Pod からのみ読み書き(K8s v1.22 beta、v1.27 GA) | Pod レベルの排他制御(RWO より厳密) |
Longhorn v1.11.1 のアクセスモード対応
| モード | V1 Data Engine | V2 Data Engine |
|---|---|---|
| RWO | 対応 | 対応 |
| RWX | 対応(内部で NFSv4 を使用) | 非対応 |
| ROX | 非対応 | 非対応 |
| RWOP | 対応(K8s が RWO として扱う) | 非対応 |
fanclub-db(PostgreSQL)は同時に複数ノードから書き込みを受け付けません。RWO が正しい選択です。Longhorn の RWX は内部で NFSv4 サーバーを動かす実装のため、外部 NFS サーバーを別途構築する必要はありません。
Reclaim Policy(Retain / Delete)の動作差分
| ポリシー | PVC 削除時の PV / データの扱い | 動的 SC のデフォルト | 適した用途 |
|---|---|---|---|
| Delete | PV オブジェクトを削除し外部ストレージのデータも削除 | Delete(デフォルト) | テスト環境・一時的なデータ |
| Retain | PV は Released 状態で残存・データ保持・管理者が手動回収 | 要明示設定 | 本番 DB・重要データ |
本番警告①: Reclaim Policy Delete は PVC 削除でデータも連鎖削除される
Longhorn SC のデフォルト Reclaim Policy は Delete です。PVC を誤って削除すると、PV 削除 → Longhorn Volume 削除 → 外部ストレージのデータも消える、という連鎖でデータが完全に失われます。本番環境では StorageClass の reclaimPolicy を Retain に設定するか、定期的な Longhorn Snapshot / Velero バックアップが必須です。Helm 管理下では helm.sh/resource-policy: keep アノテーションを PVC に付与しておくと helm uninstall でも PVC が削除されません。
Longhorn アーキテクチャ — 分散ストレージの仕組み
Longhorn の主要コンポーネントと、Volume レプリカの分散配置によって耐障害性が実現される仕組みを整理します。WL ノード障害時のフェイルオーバー挙動も含めます。
Longhorn アーキテクチャ図
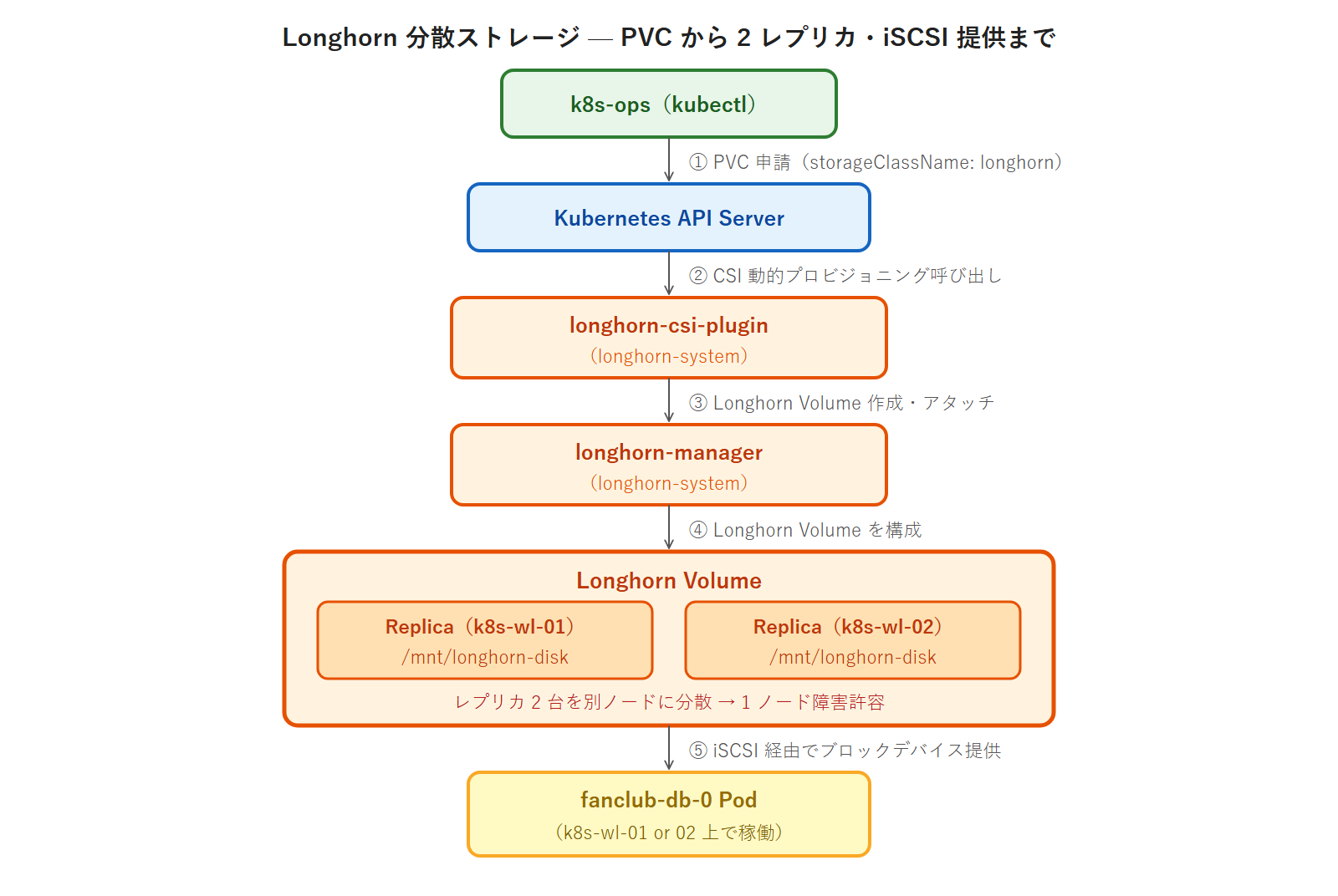
Longhorn コンポーネントの役割
| コンポーネント | 役割 |
|---|---|
longhorn-manager | Volume のライフサイクル管理・レプリカ調整・フェイルオーバー |
longhorn-driver-deployer | CSI ドライバーのインストール・更新 |
csi-provisioner | PVC → PV の動的プロビジョニング |
csi-attacher | Volume の attach / detach |
csi-resizer | Volume サイズ拡張 |
csi-snapshotter | Volume Snapshot(VolumeSnapshot CRD 連携) |
csi-node-driver-registrar | 各ノードへの CSI ドライバー登録 |
longhorn-ui | Web ダッシュボード(NodePort 経由でアクセス) |
WL ノード障害時のフェイルオーバー挙動
- k8s-wl-01 が障害 → k8s-wl-01 上のレプリカが
Degraded表示 longhorn-managerが k8s-wl-02 のレプリカで Volume をサービング継続- Pod は k8s-wl-02 に再スケジュールされ、データロスなしで起動
- k8s-wl-01 復旧後 → レプリカが自動再同期(
Rebuilding→Healthy)
レプリカ数が 2 のため、両 WL ノードが同時障害になると Volume は復旧不能になります(Longhorn の Backup を S3 互換ストレージに取得していれば、その時点までは復旧可能)。本番環境では WL ノード 3 台以上・レプリカ数 3 を推奨します。Longhorn の Backup も併用すべき本番テーマで、次のシリーズで扱います。
WL ノード前提準備 — iscsi-initiator-utils + /dev/sdb フォーマット
本セクションでは、Longhorn インストール前に WL ノード(k8s-wl-01 / k8s-wl-02)で必要な前提準備を確認します。iscsid 起動確認 → /dev/sdb フォーマット → マウント → /etc/fstab 永続化の順に進めます。
Step 1: iscsid 稼働確認(k8s-wl-01)
k8s-wl-01 に SSH でログインし、iscsid サービスが active (running) であることを確認します。
実行コマンド:
$ sudo systemctl status iscsid実行結果:
● iscsid.service - Open-iSCSI
Loaded: loaded (/usr/lib/systemd/system/iscsid.service; enabled; preset: disabled)
Active: active (running) since Sun 2026-05-24 08:12:34 JST; 2h ago
TriggeredBy: ● iscsid.socket
Docs: man:iscsid(8)
Main PID: 1234 (iscsid)
Tasks: 2 (limit: 4665)
Memory: 8.5M
CPU: 12msStep 2: iscsi_tcp カーネルモジュール確認
iscsid 起動には iscsi_tcp カーネルモジュールが必須です。SP_vol2-pre-12 では modprobe iscsi_tcp 実施済みです。
実行コマンド:
$ lsmod | grep iscsi実行結果:
iscsi_tcp 24576 0
libiscsi_tcp 28672 1 iscsi_tcp
libiscsi 73728 2 libiscsi_tcp,iscsi_tcp
scsi_transport_iscsi 159744 3 libiscsi,iscsi_tcpStep 3: /dev/sdb 未フォーマット確認
追加ディスク(40 GB)が未フォーマット・未マウントの状態であることを lsblk で確認します。重要:Longhorn 用の空きディスクのデバイス名はノードによって異なる場合があります。 lsblk -o NAME,SIZE,TYPE,FSTYPE,MOUNTPOINT の出力で「パーティションを持たず・FSTYPE も MOUNTPOINT も空のディスク」が Longhorn 用の空きディスクです。多くの環境では /dev/sdb ですが、ディスクの認識順序によっては /dev/sda が空きディスクで /dev/sdb が OS ディスクというノードも存在します(本シリーズの実機検証でも k8s-wl-02 で OS ディスクが /dev/sdb 側になる事例を確認しています)。以降のコマンドの /dev/sdb は、各ノードで確認した空きディスクのデバイス名に必ず読み替えてください。OS ディスクを mkfs すると稼働中のシステムを破壊します。
実行コマンド:
$ lsblk実行結果:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 40G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 39G 0 part /
sdb 8:16 0 40G 0 diskStep 4: /dev/sdb を xfs でフォーマット
実行コマンド:
$ sudo mkfs.xfs /dev/sdb実行結果:
meta-data=/dev/sdb isize=512 agcount=4, agsize=2621440 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=1
= reflink=1 bigtime=1 inobtcount=1 nrext64=1
data = bsize=4096 blocks=10485760, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=16384, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Discarding blocks...Done.Step 5: マウントポイント作成 + マウント
実行コマンド:
$ sudo mkdir -p /mnt/longhorn-disk
$ sudo mount /dev/sdb /mnt/longhorn-disk
$ mount | grep longhorn実行結果:
/dev/sdb on /mnt/longhorn-disk type xfs (rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=32k,noquota)Step 6: /etc/fstab に UUID 指定で永続化
ノード再起動後も自動マウントされるよう、/etc/fstab に UUID 指定エントリを追記します。デバイス名(/dev/sdb)指定だと将来ディスクが増えた際に名前が変わるリスクがあるため、UUID で固定します。
実行コマンド:
$ UUID=$(sudo blkid -s UUID -o value /dev/sdb)
$ echo "UUID=${UUID} /mnt/longhorn-disk xfs defaults 0 0" | sudo tee -a /etc/fstab
$ cat /etc/fstab | grep longhorn実行結果:
UUID=8b3e7f1a-2c4d-4f6e-9a8b-1c2d3e4f5a6b /mnt/longhorn-disk xfs defaults 0 0Step 1〜6 を k8s-wl-02 でも実施します。ただし mkfs / mount の対象デバイス名は、k8s-wl-02 で必ず lsblk -o NAME,SIZE,TYPE,FSTYPE,MOUNTPOINT を実行して空きディスクを再確認してください。 ディスクの認識順序はノードごとに異なり得るため、k8s-wl-01 の空きディスクが /dev/sdb でも、k8s-wl-02 の空きディスクは /dev/sda(OS ディスクが /dev/sdb 側)というケースがあります。その場合は /dev/sda を mkfs / mount します。確認せずに /dev/sdb を mkfs すると、k8s-wl-02 では稼働中の OS ディスクを破壊します。 UUID は WL ノード毎に異なる値が得られます。
本番警告②: iscsid 未起動だと Longhorn Pod が CrashLoopBackOff になる
iscsid が起動していない状態で Longhorn Volume を Pod にアタッチしようとすると、longhorn-csi-attacher が iSCSI セッション確立に失敗し、PVC を使う Pod が ContainerCreating から CrashLoopBackOff になります。Longhorn インストール前に必ず WL ノード全台で systemctl enable --now iscsid を実施し、iscsi_tcp モジュールをロードしておきます。/etc/modules-load.d/iscsi.conf に iscsi_tcp を記述しておくと再起動後もモジュールが自動ロードされます。
やってみよう① — Longhorn v1.11.1 Helm インストール
k8s-ops に戻り、Longhorn Helm chart を v1.11.1 でインストールします。alma-proxy whitelist 確認 → Helm repo 追加 → values.yaml 作成 → install → Pod Running 確認 → SC 確認 → Longhorn UI 表示までを進めます。
Step 1: alma-proxy whitelist 確認(charts.longhorn.io)
Longhorn Helm chart のダウンロード元 charts.longhorn.io が alma-proxy whitelist に登録されていることを確認します(environment.md に登録済み)。
実行コマンド:
$ curl -sI https://charts.longhorn.io/index.yaml | head -1実行結果:
HTTP/2 200Step 2: Longhorn Helm リポジトリ追加
実行コマンド:
$ helm repo add longhorn https://charts.longhorn.io
$ helm repo update
$ helm search repo longhorn/longhorn --version 1.11.1実行結果:
"longhorn" has been added to your repositories
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "longhorn" chart repository
Update Complete. ⎈Happy Helming!⎈
NAME CHART VERSION APP VERSION DESCRIPTION
longhorn/longhorn 1.11.1 v1.11.1 Longhorn is a distributed block storage syste...Step 3: longhorn-values.yaml を作成
WL ノード 2 台環境に合わせて defaultReplicaCount: 2 と defaultClassReplicaCount: 2 を指定します。persistence.defaultClass: true は Helm デフォルトのままで、longhorn SC が default アノテーション付きで作成されます。
実行コマンド:
$ cat > longhorn-values.yaml <<'EOF'
defaultSettings:
defaultReplicaCount: 2
persistence:
defaultClass: true
defaultClassReplicaCount: 2
EOF
$ cat longhorn-values.yaml実行結果:
defaultSettings:
defaultReplicaCount: 2
persistence:
defaultClass: true
defaultClassReplicaCount: 2Step 4: Longhorn Helm インストール
実行コマンド:
$ helm install longhorn longhorn/longhorn \
--namespace longhorn-system \
--create-namespace \
--version 1.11.1 \
-f longhorn-values.yaml実行結果:
NAME: longhorn
LAST DEPLOYED: Sun May 24 11:34:21 2026
NAMESPACE: longhorn-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Longhorn is now installed on the cluster!
Please wait a few minutes for other Longhorn components such as CSI deployments,
Engine Images, and Instance Managers to be initialized.Step 5: longhorn-system 全 Pod Running 確認
longhorn-manager / longhorn-driver-deployer / csi-* / longhorn-ui がすべて Running になるまで 3〜5 分待ちます。
実行コマンド:
$ kubectl get pods -n longhorn-system実行結果:
NAME READY STATUS RESTARTS AGE
csi-attacher-7d4b9c5f8d-abcde 1/1 Running 0 3m
csi-attacher-7d4b9c5f8d-fghij 1/1 Running 0 3m
csi-attacher-7d4b9c5f8d-klmno 1/1 Running 0 3m
csi-provisioner-65f9c8d6b7-pqrst 1/1 Running 0 3m
csi-provisioner-65f9c8d6b7-uvwxy 1/1 Running 0 3m
csi-provisioner-65f9c8d6b7-zabcd 1/1 Running 0 3m
csi-resizer-58d7b8c9d4-efghi 1/1 Running 0 3m
csi-resizer-58d7b8c9d4-jklmn 1/1 Running 0 3m
csi-resizer-58d7b8c9d4-opqrs 1/1 Running 0 3m
csi-snapshotter-6c9d7e8f5b-tuvwx 1/1 Running 0 3m
csi-snapshotter-6c9d7e8f5b-yzabc 1/1 Running 0 3m
csi-snapshotter-6c9d7e8f5b-defgh 1/1 Running 0 3m
engine-image-ei-abc12345-wl01 1/1 Running 0 4m
engine-image-ei-abc12345-wl02 1/1 Running 0 4m
instance-manager-wl01-xyz 1/1 Running 0 4m
instance-manager-wl02-xyz 1/1 Running 0 4m
longhorn-csi-plugin-wl01 3/3 Running 0 3m
longhorn-csi-plugin-wl02 3/3 Running 0 3m
longhorn-driver-deployer-7c8d9e6f5b-ijklm 1/1 Running 0 5m
longhorn-manager-wl01 2/2 Running 0 5m
longhorn-manager-wl02 2/2 Running 0 5m
longhorn-ui-7b8c9d6e5f-nopqr 1/1 Running 0 5m
longhorn-ui-7b8c9d6e5f-stuvw 1/1 Running 0 5mStep 6: longhorn StorageClass 確認
longhorn SC が default アノテーション付きで作成され、同時に既存の local-path SC もまだ default のままになっていることを確認します。
実行コマンド:
$ kubectl get sc実行結果:
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
local-path (default) rancher.io/local-path Delete WaitForFirstConsumer false 41d
longhorn (default) driver.longhorn.io Delete Immediate true 5mこの時点では (default) マーカーが 2 つあり、複数 default SC が共存している不安定な状態です。次のやってみよう② で local-path の default を解除します。
Step 7: Longhorn UI NodePort 公開
Longhorn UI を NodePort 30080 で公開し、ブラウザでダッシュボードにアクセスします。
実行コマンド:
$ kubectl -n longhorn-system patch service longhorn-frontend \
-p '{"spec":{"type":"NodePort","ports":[{"port":80,"targetPort":8000,"nodePort":30080}]}}'
$ kubectl -n longhorn-system get service longhorn-frontend実行結果:
service/longhorn-frontend patched
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
longhorn-frontend NodePort 10.108.45.123 <none> 80:30080/TCP 6mブラウザから http://192.168.1.128:30080/(k8s-wl-01 の IP + NodePort)にアクセスすると Longhorn ダッシュボードが表示されます。Node タブで k8s-wl-01 / k8s-wl-02 が Schedulable として一覧されます。
Step 8: Longhorn Node にディスクパスを登録
Longhorn は初期状態でホストの /var/lib/longhorn(OS ディスク)をレプリカ配置先として使います。本シリーズでは /dev/sdb をマウントした /mnt/longhorn-disk を専用ディスクとして登録します。
実行コマンド:
$ kubectl -n longhorn-system edit node.longhorn.io k8s-wl-01spec.disks に以下を追記して保存します(k8s-wl-02 にも同じ操作を実施)。
spec:
allowScheduling: true
disks:
longhorn-disk:
allowScheduling: true
diskDriver: ""
diskType: filesystem
evictionRequested: false
path: /mnt/longhorn-disk
storageReserved: 0
tags: []Longhorn UI の Node タブで k8s-wl-01 / k8s-wl-02 の Disks 欄に longhorn-disk エントリが追加され、Schedulable: true・Size: 約 40 GB と表示されることを確認します。
やってみよう② — SC 切替(local-path の default を解除・longhorn を唯一の default に)
本セクションでは、複数 default SC の競合を解消し、sts-demo Namespace の demo StatefulSet で volumeClaimTemplates 不変制約と --cascade=orphan を体験します。
本番警告③: 複数の default SC が共存すると storageClassName 未指定 PVC が不安定になる
kubectl get sc で (default) マーカーが 2 つ以上ついている状態は危険です。storageClassName を指定しない PVC を作成すると、Kubernetes は「最も新しく作成された default SC」を使います。本番環境では意図しない SC が選択されて容量・性能・Reclaim Policy が異なるボリュームが作成される可能性があります。SC 切替作業後は必ず kubectl get sc で default が 1 つだけであることを確認します。
Step 1: local-path SC の default アノテーション解除
実行コマンド:
$ kubectl patch storageclass local-path \
-p '{"metadata":{"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'実行結果:
storageclass.storage.k8s.io/local-path patchedStep 2: longhorn が唯一の default になったことを確認
実行コマンド:
$ kubectl get sc実行結果:
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
local-path rancher.io/local-path Delete WaitForFirstConsumer false 41d
longhorn (default) driver.longhorn.io Delete Immediate true 8mlocal-path から (default) マーカーが消え、longhorn のみが default になりました。以降の PVC で storageClassName を省略すると longhorn SC が使われます。
Step 3: sts-demo Namespace と demo StatefulSet を作成(旧 SC で)
volumeClaimTemplates 不変制約を体験するため、sts-demo Namespace に storageClassName: local-path の demo StatefulSet を作成します。
実行コマンド:
$ kubectl create namespace sts-demo
$ kubectl apply -n sts-demo -f - <<'EOF'
apiVersion: v1
kind: Service
metadata:
name: demo
namespace: sts-demo
labels:
app: demo
spec:
clusterIP: None
selector:
app: demo
ports:
- name: web
port: 80
targetPort: 80
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: demo
namespace: sts-demo
spec:
serviceName: demo
replicas: 1
selector:
matchLabels:
app: demo
template:
metadata:
labels:
app: demo
spec:
containers:
- name: nginx
image: 192.168.1.123:5000/nginx:1.27
ports:
- containerPort: 80
name: web
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: local-path
resources:
requests:
storage: 1Gi
EOF実行結果:
namespace/sts-demo created
service/demo created
statefulset.apps/demo createdStep 4: volumeClaimTemplates を longhorn に変更しようと kubectl apply を試みる
storageClassName: local-path を storageClassName: longhorn に変えた YAML を kubectl apply で適用しようとして、不変制約のエラーを確認します。
実行コマンド:
$ kubectl apply -n sts-demo -f - <<'EOF'
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: demo
namespace: sts-demo
spec:
serviceName: demo
replicas: 1
selector:
matchLabels:
app: demo
template:
metadata:
labels:
app: demo
spec:
containers:
- name: nginx
image: 192.168.1.123:5000/nginx:1.27
ports:
- containerPort: 80
name: web
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: longhorn
resources:
requests:
storage: 1Gi
EOF実行結果:
The StatefulSet "demo" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'ordinals', 'template', 'updateStrategy', 'persistentVolumeClaimRetentionPolicy' and 'minReadySeconds' are forbiddenStatefulSet の spec.volumeClaimTemplates は不変フィールド(immutable)です。kubectl apply も kubectl edit も拒否されます。変更には StatefulSet 自体を削除して再作成する必要があります。
Step 5: –cascade=orphan で StatefulSet のみ削除
--cascade=orphan を指定すると、StatefulSet オブジェクトのみが削除され、配下の Pod と PVC は孤立した状態で残ります。本番では「データを保護しつつ StatefulSet 定義を作り直したい」場面で使います。
実行コマンド:
$ kubectl delete statefulset demo -n sts-demo --cascade=orphan
$ kubectl get pods,pvc -n sts-demo実行結果:
statefulset.apps "demo" deleted
NAME READY STATUS RESTARTS AGE
pod/demo-0 1/1 Running 0 3m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/data-demo-0 Bound pvc-aaaaa 1Gi RWO local-path 3mStatefulSet オブジェクトは削除されましたが、Pod demo-0 と PVC data-demo-0 は残っています。storageClassName: local-path も保持されたままです。
本番警告④: –cascade=orphan を省略すると Helm / ArgoCD 経由でデータロスが起きる
素の kubectl delete statefulset では Pod は削除されますが PVC はデフォルトで残ります。ただし Helm の helm uninstall・ArgoCD Application 削除・CI/CD パイプラインの自動削除では PVC まで一括削除されるケースがあります。特に Helm で StatefulSet を管理している場合は helm.sh/resource-policy: keep アノテーションを PVC に付与してデータロスを防ぎます。--cascade=orphan は「StatefulSet を削除して Pod に孤立マークを付け、関連リソースを削除しない」という明示的な意図の宣言として使います。本番運用では「--cascade=orphan を付け忘れた」事故が頻発するため、削除コマンドを Runbook に必ず記載します。
Step 6: 旧 PVC を削除 + longhorn SC で StatefulSet 再作成
デモのため、ここでは旧 PVC(local-path のもの)を削除し、新しい longhorn SC で StatefulSet を再作成します。本番ではこの前に pg_dump 等でデータバックアップが必須です(次の H2 で一般化手順を整理します)。
実行コマンド:
$ kubectl delete pod demo-0 -n sts-demo
$ kubectl delete pvc data-demo-0 -n sts-demo
$ kubectl apply -n sts-demo -f - <<'EOF'
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: demo
namespace: sts-demo
spec:
serviceName: demo
replicas: 1
selector:
matchLabels:
app: demo
template:
metadata:
labels:
app: demo
spec:
containers:
- name: nginx
image: 192.168.1.123:5000/nginx:1.27
ports:
- containerPort: 80
name: web
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: longhorn
resources:
requests:
storage: 1Gi
EOF
$ kubectl get pvc -n sts-demo実行結果:
pod "demo-0" deleted
persistentvolumeclaim "data-demo-0" deleted
statefulset.apps/demo created
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-demo-0 Bound pvc-bbbbb 1Gi RWO longhorn 20s新しい PVC は STORAGECLASS: longhorn に切り替わり、Longhorn Volume として動的プロビジョニングされました。
Step 7: sts-demo Namespace ごと削除(クリーンアップ)
演習が終わったら sts-demo Namespace ごと削除して環境をクリーンに戻します。
実行コマンド:
$ kubectl delete namespace sts-demo
$ kubectl get ns sts-demo実行結果:
namespace "sts-demo" deleted
Error from server (NotFound): namespaces "sts-demo" not foundやってみよう③ — fanclub-db StatefulSet デプロイ
本セクションでは、fanclub Namespace に PostgreSQL 18 を StatefulSet として新規デプロイします。Secret → HeadlessService → StatefulSet の順に作成し、Longhorn ボリュームに PGDATA=/var/lib/postgresql/data/pgdata(サブディレクトリ)でデータを永続化します。
Step 1: fanclub-db-secret を作成
PostgreSQL の認証情報(POSTGRES_USER / POSTGRES_PASSWORD / POSTGRES_DB)を Secret として作成します。
実行コマンド:
$ kubectl apply -f - <<'EOF'
apiVersion: v1
kind: Secret
metadata:
name: fanclub-db-secret
namespace: fanclub
type: Opaque
stringData:
POSTGRES_USER: fanclub
POSTGRES_PASSWORD: fanclub-secret-password
POSTGRES_DB: fanclub
EOF
$ kubectl get secret fanclub-db-secret -n fanclub実行結果:
secret/fanclub-db-secret created
NAME TYPE DATA AGE
fanclub-db-secret Opaque 3 5sStep 2: fanclub-db HeadlessService を作成
StatefulSet が安定した Pod DNS 名(fanclub-db-0.fanclub-db.fanclub.svc.cluster.local)を提供するために HeadlessService(clusterIP: None)を作成します。
実行コマンド:
$ kubectl apply -f - <<'EOF'
apiVersion: v1
kind: Service
metadata:
name: fanclub-db
namespace: fanclub
labels:
app: fanclub-db
spec:
clusterIP: None
selector:
app: fanclub-db
ports:
- name: postgres
port: 5432
targetPort: 5432
EOF
$ kubectl get service fanclub-db -n fanclub実行結果:
service/fanclub-db created
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
fanclub-db ClusterIP None <none> 5432/TCP 3sCLUSTER-IP が None になっていることが HeadlessService の特徴です。これにより DNS は ClusterIP ではなく Pod IP を直接返します。
Step 3: fanclub-db StatefulSet を作成
PostgreSQL 18 の Docker 公式イメージを private registry 経由(192.168.1.123:5000/postgres:18-alpine)で使用します。PGDATA をボリュームマウント先のサブディレクトリ /var/lib/postgresql/data/pgdata に設定することで、xfs フォーマット直後の lost+found ディレクトリによる初期化失敗を回避します。
実行コマンド:
$ kubectl apply -f - <<'EOF'
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: fanclub-db
namespace: fanclub
spec:
serviceName: fanclub-db
replicas: 1
selector:
matchLabels:
app: fanclub-db
template:
metadata:
labels:
app: fanclub-db
spec:
containers:
- name: postgres
image: 192.168.1.123:5000/postgres:18-alpine
ports:
- containerPort: 5432
name: postgres
env:
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: fanclub-db-secret
key: POSTGRES_USER
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: fanclub-db-secret
key: POSTGRES_PASSWORD
- name: POSTGRES_DB
valueFrom:
secretKeyRef:
name: fanclub-db-secret
key: POSTGRES_DB
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "500m"
memory: "1Gi"
volumeMounts:
- name: fanclub-db-data
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: fanclub-db-data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: longhorn
resources:
requests:
storage: 10Gi
EOF実行結果:
statefulset.apps/fanclub-db createdStep 4: fanclub-db-0 が Running になったことを確認
Longhorn が PV を動的プロビジョニング → アタッチ → PostgreSQL 初期化、までを 1〜2 分で完了します。
実行コマンド:
$ kubectl get pods -n fanclub実行結果:
NAME READY STATUS RESTARTS AGE
fanclub-api-fanclub-api-bbbfdf9bf-xk2pq 1/1 Running 0 3d
fanclub-api-fanclub-api-bbbfdf9bf-zk9xt 1/1 Running 0 3d
fanclub-db-0 1/1 Running 0 90sStep 5: PVC が Bound・STORAGECLASS=longhorn を確認
実行コマンド:
$ kubectl get pvc -n fanclub実行結果:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
fanclub-db-data-fanclub-db-0 Bound pvc-ccccc 10Gi RWO longhorn 90sStep 6: PostgreSQL への接続確認(kubectl exec で psql)
fanclub-db-0 Pod 内で psql を起動し、データベース一覧を確認します。
実行コマンド:
$ kubectl exec -it fanclub-db-0 -n fanclub -- psql -U fanclub -d fanclub -c "\l"実行結果:
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | Locale | ICU Rules | Access privileges
-----------+---------+----------+-----------------+------------+------------+--------+-----------+-------------------
fanclub | fanclub | UTF8 | libc | en_US.utf8 | en_US.utf8 | | |
postgres | fanclub | UTF8 | libc | en_US.utf8 | en_US.utf8 | | |
template0 | fanclub | UTF8 | libc | en_US.utf8 | en_US.utf8 | | | =c/fanclub +
| | | | | | | | fanclub=CTc/fanclub
template1 | fanclub | UTF8 | libc | en_US.utf8 | en_US.utf8 | | | =c/fanclub +
| | | | | | | | fanclub=CTc/fanclub
(4 rows)fanclub データベースが作成され、所有者が fanclub ユーザーで初期化されていることが確認できます。fanclub-api 側からは fanclub-db.fanclub.svc.cluster.local:5432 で接続できます。
Step 7: Longhorn UI で Volume Healthy 確認
ブラウザの Longhorn UI(http://192.168.1.128:30080/)を開き、Volume タブで fanclub-db-data-fanclub-db-0 由来の Volume を確認します。State: Healthy、Replicas: 2(k8s-wl-01 + k8s-wl-02 にそれぞれ 1 つずつ配置)、Robustness: Healthy が表示されます。
kubectl 側からも Volume リソースの状態を確認できます。
実行コマンド:
$ kubectl -n longhorn-system get volume.longhorn.io実行結果:
NAME DATA ENGINE STATE ROBUSTNESS SCHEDULED SIZE NODE AGE
pvc-ccccc v1 attached healthy 10737418240 k8s-wl-01 3m既存 PVC の StorageClass 切替手順(–cascade=orphan パターンの一般化)
本セクションでは、稼働中の StatefulSet(PVC にデータあり)を別の SC に切り替える本番手順を一般化します。今回の fanclub-db は初回デプロイのためバックアップ・リストアが不要でしたが、本番では必須のステップです。
一般化した SC 切替手順(7 ステップ)
【既存 StatefulSet(storageClassName: local-path)を longhorn に切り替える本番手順】
Step 1: データバックアップ(本番では必須)
kubectl exec -it fanclub-db-0 -n fanclub -- pg_dump -U fanclub fanclub > backup.sql
Step 2: StatefulSet のみ削除(PVC・データを保持)
kubectl delete statefulset fanclub-db -n fanclub --cascade=orphan
Step 3: Pod が削除されていることを確認(PVC は残存)
kubectl get pods -n fanclub ← fanclub-db-0 が消えた
kubectl get pvc -n fanclub ← fanclub-db-data-fanclub-db-0 は残存
Step 4: 旧 PVC を削除(storageClassName が local-path のもの)
kubectl delete pvc fanclub-db-data-fanclub-db-0 -n fanclub
Step 5: storageClassName=longhorn で新 StatefulSet を作成
kubectl apply -f fanclub-db-statefulset.yaml
Step 6: 新 PVC が Bound(STORAGECLASS=longhorn)になったことを確認
kubectl get pvc -n fanclub
Step 7: データリストア(本番では必須)
kubectl exec -i fanclub-db-0 -n fanclub -- psql -U fanclub -d fanclub < backup.sql本番シナリオと演習との差異
| 項目 | 第12回演習 | 本番シナリオ |
|---|---|---|
| 初期データ | なし(初回デプロイ) | 稼働中・実データあり |
| バックアップ | 不要 | pg_dump 必須 |
| 移行ウィンドウ | 制約なし | 事前告知・メンテ時間確保が必須 |
| リストア確認 | 不要 | レコード件数 + チェックサム比較 |
| ロールバック手順 | 不要 | 旧 PVC を Retain で残し復元可能に |
Helm / ArgoCD 管理下での注意点
- Helm で StatefulSet を管理している場合、
helm upgradeでvolumeClaimTemplatesを変更しようとするとエラーになる(不変フィールド) helm.sh/resource-policy: keepアノテーションを PVC に付与しておくとhelm uninstall時にも PVC が削除されない- ArgoCD GitOps 管理下では Application 削除時の PVC 保護設定(
syncPolicy.syncOptions: [PruneLast=true]等)を事前に確認する - 本番 DB の SC 移行は「StatefulSet を Helm / ArgoCD 管理から一時的に外し、kubectl で直接操作する」運用が定石
まとめ・現場ヒヤリハット・理解度チェック
第12回のまとめ
- PV / PVC / StorageClass は「ストレージ実体(PV)」「申請(PVC)」「動的プロビジョニングルール(SC)」の 3 層構造。動的プロビジョニングにより SC を指定するだけで PV が自動作成される
- アクセスモードは RWO(単一ノード読み書き)/ ROX(複数ノード読み取り)/ RWX(複数ノード読み書き)/ RWOP(単一 Pod 読み書き)の 4 種。PostgreSQL DB は RWO が基本
- Longhorn は CSI 経由でブロックデバイスを提供し、複数 WL ノードにレプリカを分散してデータ耐障害性を実現する
- Longhorn インストール前に k8s-wl 全台で
iscsidサービスがactive (running)であることを必ず確認する local-path (default)とlonghorn (default)が共存する状態を放置しない。必ずkubectl patch storageclass local-pathで default を解除する- StatefulSet の
volumeClaimTemplatesは作成後に変更不可(immutable field)。変更するにはkubectl delete statefulset <name> --cascade=orphanで StatefulSet のみ削除し PVC を保持した上で再作成する - PostgreSQL 18 の
PGDATAは/var/lib/postgresql/data/pgdata(サブディレクトリ)に設定する。親ディレクトリ直接指定ではlost+found問題で初期化が失敗する
次回予告
第13回では Prometheus + Grafana + Loki + Fluent Bit を導入し、fanclub-api の監視ダッシュボードを構築します。第12回で Longhorn 上に配置した fanclub-db を含むクラスタ全体のメトリクス収集とログ集約を実現し、第5部「監視・運用」の開始回として位置づけます。kube-prometheus-stack v84.x の Helm chart 構成・ServiceMonitor / PodMonitor の設計・Loki + Fluent Bit のログパイプライン構築を扱います。
現場ヒヤリハット①: Longhorn Volume が Degraded のまま回復しなかった
状況: Longhorn UI でボリュームが Degraded・レプリカが 1/2 のまま回復せず、Pod は何とか動いているもののアラートが鳴り続ける状態になりました。
原因: k8s-wl-02 の /mnt/longhorn-disk が /etc/fstab 未設定で、ノード再起動後にアンマウント状態のまま放置されていました。Longhorn は /mnt/longhorn-disk 配下にレプリカを書こうとして失敗し、ノード単位でディスクが Disabled として扱われていました。
修正:
$ sudo mount -a
$ mount | grep longhorn-disk再マウント後、Longhorn UI でノードの「Enable Scheduling」を確認し、ディスクを有効化しました。恒久対応として /etc/fstab に UUID 指定エントリを追加しました。
教訓: mount /dev/sdb /mnt/longhorn-disk はワンショット操作で再起動後に消えます。永続化は必ず /etc/fstab + UUID で行います。チームの kubeadm 環境構築 Runbook に「Longhorn 用ディスクは UUID 指定で fstab 永続化」を必須チェック項目として明記します。
現場ヒヤリハット②: fanclub-db-0 が CrashLoopBackOff(PGDATA の lost+found 問題)
状況: fanclub-db StatefulSet を初回デプロイしたところ、fanclub-db-0 が CrashLoopBackOff を繰り返し、PostgreSQL が起動しませんでした。
原因: kubectl logs fanclub-db-0 -n fanclub で確認すると以下のエラーが出ていました。
initdb: error: directory "/var/lib/postgresql/data" exists but is not empty
initdb: hint: If you want to create a new database system, either remove or empty the directory "/var/lib/postgresql/data" or run initdb with an argument other than "/var/lib/postgresql/data".PGDATA環境変数を省略または/var/lib/postgresql/dataに直接指定していた- xfs フォーマット直後の
lost+foundディレクトリが存在しているため PostgreSQL のinitdbが「空でない」と判定して初期化を拒否した
修正: StatefulSet の env に PGDATA=/var/lib/postgresql/data/pgdata(サブディレクトリ)を追加しました。--cascade=orphan で StatefulSet を削除 → PVC を削除 → 再作成、の手順で対応しました。
教訓: PostgreSQL の公式 Docker イメージで永続ボリュームを使う場合は、PGDATA を必ずマウントポイントのサブディレクトリに設定します。lost+found はファイルシステム作成時の予約ディレクトリで、削除しても再作成されます。Helm の bitnami/postgresql chart も同じ理由でデフォルトで PGDATA をサブディレクトリにしています。
現場ヒヤリハット③: kubectl apply で SC 変更を試みて意図せず PVC を消した
状況: 既存 StatefulSet の SC を切り替えるため kubectl apply で storageClassName を変えて再適用しようとしたところ、エラーが返ってきました。新人が「では Namespace ごと作り直そう」と kubectl delete namespace を実行したところ、配下の PVC まで削除され、Reclaim Policy が Delete だったため Longhorn Volume も連鎖削除されました。
原因:
- StatefulSet の
volumeClaimTemplates不変制約を理解せず、エラー解決の手段として Namespace 削除を選んだ - Namespace 削除は配下の全リソース(PVC 含む)を一括削除する
- SC の
reclaimPolicy: Deleteにより PVC 削除と同時にデータが永久消失した
修正: Namespace 削除前に kubectl get pvc -n <ns> で Bound な PVC を必ず確認します。SC 切替は本記事 H2「既存 PVC の StorageClass 切替手順」に従い、--cascade=orphan + PVC 個別管理で実施します。Helm 管理下では helm.sh/resource-policy: keep アノテーションを PVC に付与しておきます。
教訓: 「とりあえず Namespace を作り直す」はデータを扱う Namespace では絶対に避けます。チームの kubeadm Runbook に「データ層 Namespace(fanclub / longhorn-system 等)の kubectl delete namespace は事前承認必須」を明記し、Reviewer の必須チェック項目に組み込みます。
理解度チェック(○×形式・7 問)
各問に対して○か×で答え、解説を確認してください。
| # | 問題文 | 正解 | 解説 |
|---|---|---|---|
| Q1 | StorageClass の reclaimPolicy: Delete を設定した SC で動的プロビジョニングされた PVC を削除すると、PV と外部ストレージのデータも自動的に削除される | ○ | Delete ポリシーでは PVC 削除 → PV 削除 → 外部ストレージ削除が連鎖する。本番では Retain か定期バックアップが必要 |
| Q2 | Longhorn の RWX(ReadWriteMany)アクセスモードは内部的に NFS を使用するため、別途 NFS サーバーの構築が必要である | × | Longhorn は V1 Data Engine で RWX を内部 NFSv4 として提供する。外部 NFS サーバーは不要 |
| Q3 | StatefulSet の volumeClaimTemplates の storageClassName は、作成後に kubectl apply で変更できる | × | volumeClaimTemplates は不変フィールド(immutable)。変更するには StatefulSet を --cascade=orphan で削除し、PVC を保持した上で再作成する |
| Q4 | kubectl delete statefulset <name> --cascade=orphan を実行すると、関連する PVC も自動的に削除される | × | --cascade=orphan は StatefulSet オブジェクトのみを削除し、Pod や PVC は保持する。PVC を削除したい場合は別途 kubectl delete pvc を実行する |
| Q5 | Kubernetes クラスタに 2 つの StorageClass が storageclass.kubernetes.io/is-default-class: "true" でアノテーションされている場合、storageClassName を指定しない PVC には最も古い default SC が使われる | × | 複数 default が存在する場合は、最後に作成された SC が使われる挙動になることが多いが、これは実装依存であり信頼してはいけない。default SC は常に 1 つだけに保つのが本番運用の鉄則 |
| Q6 | PostgreSQL 18 の Docker イメージを使う StatefulSet で PGDATA=/var/lib/postgresql/data を設定すると、xfs フォーマット直後の lost+found ディレクトリにより初期化が失敗することがある | ○ | PostgreSQL は PGDATA ディレクトリが空でないと初期化を拒否する。PGDATA にサブディレクトリ(例: /var/lib/postgresql/data/pgdata)を指定することで回避できる |
| Q7 | Longhorn では iscsid サービスが未起動の状態でも CSI ドライバーが Volume を Pod にアタッチできる | × | Longhorn の Volume アタッチは iSCSI を使用する。iscsid が未起動だと attach が失敗し Pod が ContainerCreating → CrashLoopBackOff になる |
シリーズ一覧
第1部:クラスタ構築
- 第1回 第2巻スコープ + CKA 試験形式紹介 + kubeadm 概要 + kubeadm vs RKE2/k0s/OKD 概観
- 第2回 kubeadm シングルノード起動(pkgs.k8s.io + kubeadm init + Calico CNI)+ alma-proxy whitelist 構築
- 第3回 kubeadm HA 設計 + HAProxy LB(API Server LB 構成)
- 第4回 kubeadm HA クラスタ構築(CP×3 + WL×2)+ fanclub-api HA 移行
- 第5回 etcd backup/restore(etcdutl)+ ノード drain/uncordon
第2部:ワークロード管理
- 第6回 kubeadm upgrade + ノード drain/cordon + ミニトラブルシュート演習
- 第7回 Pod スケジューリング(taint/toleration/affinity/anti-affinity/PriorityClass)
- 第8回 HPA + ResourceQuota + LimitRange
第3部:ネットワーク
- 第9回 Service 詳細 + MetalLB(LoadBalancer 動作確認)
- 第10回 NetworkPolicy 詳細 + Calico/Cilium 比較 + ミニトラブルシュート演習
- 第11回 Gateway API + Traefik + cert-manager + CoreDNS(HTTPS 公開完成)
第4部:ストレージ
- 第12回 PV/PVC/StorageClass + Longhorn 構築 + fanclub-db ボリューム移行 ← 今ここ
第5部:監視・運用
- 第13回 Prometheus + Grafana + Loki + Fluent Bit + fanclub-api 監視ダッシュボード
- 第14回 Helm + Kustomize でクラスタコンポーネント install + ArgoCD GitOps + Velero backup
