
新卒インフラエンジニア向け「Kubernetes 実践教科書① CKAD アプリケーション開発編」の第5回です。第4回までで、コンテナのビルドからレジストリへの共有まで Docker の基礎を一通り扱いました。今回からは第2部「Kubernetes 基礎」に入ります。まず Docker 単独では何が足りないのかを整理し、Kubernetes が解決する問題と全体アーキテクチャを押さえたうえで、kind で学習用の軽量クラスタを手元に立ち上げ、Calico を CNI として導入して kubectl で初めてクラスタに接続します。
動作確認バージョン:AlmaLinux 10.2 / Docker CE 29.6.0 / kind v0.31.0(kindest/node v1.35.0・containerd 2.2.0)/ kubectl v1.35.6 / Calico v3.32.0(2026-06-23 実機検証時点)
今ここマップ(全 19 回中の現在地)
現在地は第 2 部「Kubernetes 基礎」の第 5 回です。第 1 部で扱った Docker のコンテナ・イメージの知識を土台に、ここから Kubernetes 本体へ入ります。
- 第 1 部 コンテナと Docker(第 1〜4 回)
- 第 2 部 Kubernetes 基礎(第 5〜6 回)← 今ここ
- 第 3 部 アプリリソース(第 7〜11 回)
- 第 4 部 ワークロード戦略(第 12〜14 回)
- 第 5 部 セキュリティ基礎(第 15〜16 回)
- 第 6 部 パッケージ管理と HTTPS 公開(第 17〜19 回)
この回のゴール
- Kubernetes のアーキテクチャ(Control Plane Node / Workload Node)を説明できる。
- kind で軽量な Kubernetes クラスタを起動し、Calico CNI を導入できる。
kubectl get nodesでクラスタに接続し、CNI 導入前後の NotReady → Ready の遷移を理解できる。
Docker 単独の限界
第 1 部で、1 台のホスト上でコンテナをビルド・起動・共有できるようになりました。しかし業務でサービスを動かし続けるには、Docker 単独では手が回らない領域があります。
- 自己回復がない:コンテナが落ちても、誰かが気づいて
docker runし直すまで止まったままになる。 - スケールが手作業:負荷が増えたとき、複数のコンテナを起動して負荷分散するのを人手で管理しなければならない。
- 複数ホストをまたげない:1 台のホストに載る量には限りがあるが、Docker 単体には複数ホストへコンテナを配置する仕組みがない。
- 宣言的に管理できない:「あるべき状態」を宣言して維持させる仕組みがなく、起動・停止の命令を都度出す運用になる。
これらを担うのがコンテナオーケストレーターであり、その事実上の標準が Kubernetes です。
Kubernetes が解決する問題
Kubernetes は「コンテナ化されたアプリを、宣言した状態どおりに動かし続ける」ための基盤です。中心にあるのは宣言的管理という考え方で、「Pod を 3 つ動かす」といったあるべき状態を宣言すると、Kubernetes が現状との差分を検出して自動で埋め続けます。
- 自己回復:コンテナやノードが落ちると、あるべき状態に戻すため自動で再作成・再配置する。
- スケーリング:レプリカ数を宣言するだけで増減でき、負荷に応じた自動スケールも設定できる。
- スケジューリング:複数ノードの空きリソースを見て、コンテナをどこで動かすかを自動で決める。
- サービスディスカバリと負荷分散:動的に入れ替わる Pod 群へ、安定した名前でアクセスできる(第 8 回の Service で扱います)。
本シリーズでは、この宣言的管理を kubectl apply -f による YAML 適用を通して体得していきます。
Kubernetes アーキテクチャ概要
Kubernetes クラスタは、頭脳にあたる Control Plane Node と、実際にコンテナを動かす Workload Node から構成されます(従来「マスター」「ワーカー」と呼ばれた役割で、本シリーズは公式の呼称に合わせます)。本回の kind は学習用のため 1 台のノードが両方の役割を兼ねますが、本番(第 2 巻の kubeadm)では役割ごとにノードを分けます。全体像を次の図に示します。
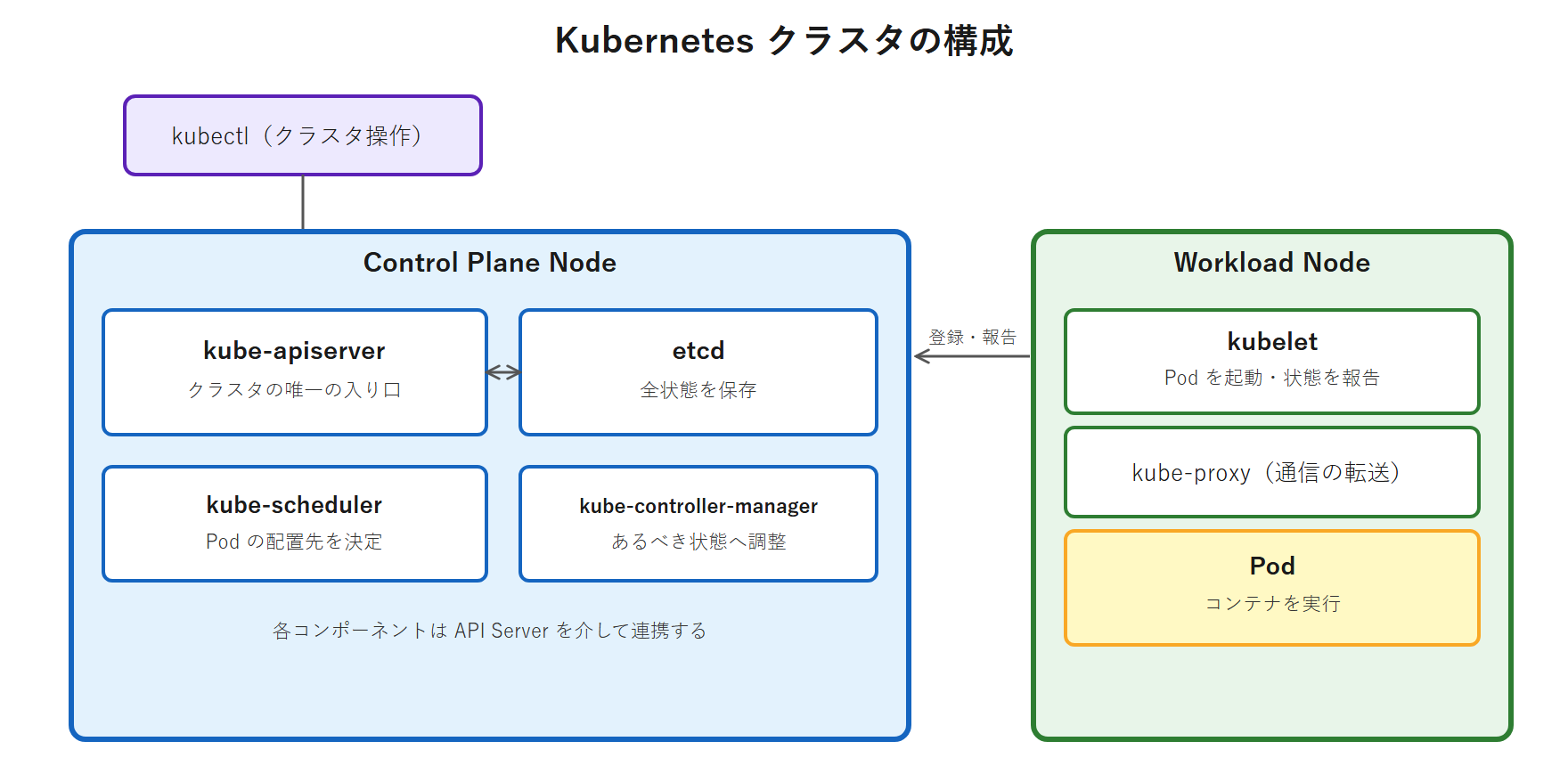
Control Plane Node の主要コンポーネント
- kube-apiserver:クラスタの唯一の入り口。
kubectlや各コンポーネントはすべて API Server を介してやり取りする。 - etcd:クラスタの全状態を保存する分散キーバリューストア。「あるべき状態」と現状はここに記録される。
- kube-scheduler:新しい Pod を、どの Workload Node に載せるかを決める。
- kube-controller-manager:現状をあるべき状態に近づけるコントローラ群(自己回復の中心)。
Workload Node の主要コンポーネント
- kubelet:各ノードで動くエージェント。API Server の指示を受け、コンテナランタイムにコンテナを起動させ、状態を報告する。
- kube-proxy:Service 宛の通信を適切な Pod へ転送するネットワーク処理を担う。
このあと kubectl get pods -n kube-system で、これらのコンポーネント(kube-apiserver / etcd / kube-scheduler / kube-controller-manager / kube-proxy)が実際に Pod として動いている様子を確認します。
containerd と Docker の違い
kubelet がコンテナを動かす相手がコンテナランタイムです。Kubernetes は CRI(Container Runtime Interface)という規格でランタイムと話し、現在の標準は containerd です(Docker そのものは使いません)。第 1 部で Docker を通して学んだイメージやコンテナの考え方は、第 1 回で触れた OCI 標準を介して containerd でもそのまま通用します。実際、このあと作る kind ノードのランタイムも containerd です。
kind と kubectl を導入する
kind(Kubernetes IN Docker)は、Docker コンテナを Kubernetes ノードに見立ててクラスタを 1 コマンドで起動できる公式ツールです。VM を増やさず k8s-ops 上の Docker だけで完結するため、学習・再現に向いています。操作には kubectl(クラスタ操作の CLI)も必要です。両方を k8s-ops に導入します。
kubectl を導入する
kubectl は公式配布元 dl.k8s.io からバイナリを取得します。クラスタの Kubernetes(v1.35 系)に合わせ、v1.35 系の kubectl を入れます。sudo はシェルのプロキシ環境変数を引き継がないため、第 1 回と同様にダウンロードは一般ユーザーで(ここでは一時ディレクトリ /tmp に)行い、配置のみ sudo で行います。配置先の /usr/local/bin は PATH が通った全ユーザー共通のディレクトリで、install -m 0755 によりバイナリは root 所有・パーミッション 755(所有者は書き込み可、他は実行・読み取りのみ)で置かれます。これにより developer から sudo なしで実行できます。
実行コマンド:
$ curl -fsSL -o /tmp/kubectl https://dl.k8s.io/release/v1.35.6/bin/linux/amd64/kubectl
$ sudo install -m 0755 /tmp/kubectl /usr/local/bin/kubectl
$ kubectl version --client実行結果(例):
Client Version: v1.35.6
Kustomize Version: v5.7.1kind を導入する
kind は GitHub Releases からバイナリを取得します(配布元の kind.sigs.k8s.io/dl/ は本シリーズの whitelist プロキシに未対応のため、GitHub 経由にします)。
実行コマンド:
$ curl -fsSL -o /tmp/kind https://github.com/kubernetes-sigs/kind/releases/download/v0.31.0/kind-linux-amd64
$ sudo install -m 0755 /tmp/kind /usr/local/bin/kind
$ kind version実行結果(例):
kind v0.31.0 go1.25.5 linux/amd64kind-config.yaml を用意する
クラスタを作る前に、設定ファイル kind-config.yaml を用意します。これは developer のホームディレクトリ(~)に置く一般ユーザー所有のファイルで、root 権限は不要です(システムへインストールするものではなく、kind に読ませる入力ファイルです)。ここで指定する項目のうち 既定 CNI の無効化・ポート転送・ノードの構成は、クラスタ作成時にしか設定できません。あとから足せないため、この先の回で使うものを含めて最初に決めておきます。次の内容で ~/kind-config.yaml を作成します。
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
disableDefaultCNI: true
podSubnet: "10.244.0.0/16"
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 80
hostPort: 80
protocol: TCP
- containerPort: 443
hostPort: 443
protocol: TCPdisableDefaultCNI: true:kind 標準の CNI(kindnet)を無効化します。代わりに後述の Calico を入れます。無効化したため、クラスタ作成直後のノードは NotReady になります。podSubnet: "10.244.0.0/16":Pod に割り当てる IP の範囲。Calico の設定と一致させます(Calico 既定の192.168.0.0/16は検証環境の LAN192.168.1.0/24と重複するため変更します)。containerdConfigPatches:ノードの containerd に「レジストリ設定を/etc/containerd/certs.d配下から読む」と指示します。第 7 回以降、自社イメージを k8s-registry から pull する準備です。extraPortMappings(80 / 443):ホスト OS の 80 / 443 をノードへ転送します。第 18 回の Gateway API でhttps://fanclub.localにアクセスするために使います(本回ではまだ未使用ですが、作成時にしか追加できないため先に確保します)。
クラスタを作成する
設定ファイルを指定してクラスタを作成します。ノードイメージは Docker Hub のミラーを明示します。初回はノードイメージ(約 1 GB)の取得に時間がかかります。
実行コマンド:
$ kind create cluster --config ~/kind-config.yaml --image docker.io/kindest/node:v1.35.0実行結果(例):
Creating cluster "kind" ...
✓ Ensuring node image (docker.io/kindest/node:v1.35.0)
✓ Preparing nodes
✓ Writing configuration
✓ Starting control-plane
✓ Installing StorageClass
Set kubectl context to "kind-kind"作成時、kind は kubectl の接続先(kubeconfig)を自動で設定します。具体的には developer の ~/.kube/config(developer 所有・パーミッション 600)に kind-kind という接続情報(コンテキスト)が書き込まれ、以降の kubectl はこれを使います。クラスタの API Server はローカルの 127.0.0.1 のランダムポートで待ち受けます(kind は 0.0.0.0 ではなく 127.0.0.1 で公開するため、プロキシ環境でも kubectl がプロキシを経由せずローカル接続できます)。
このクラスタはノードという Docker コンテナとして残るため、いったん作れば次回以降(第6回以降)もそのまま使い続けられます。ただしホストや Docker デーモンを再起動するとノードコンテナが停止することがあり、その場合は kubectl get nodes が応答しなくなります。停止していたら docker start kind-control-plane で再開でき、しばらくすると Ready に戻ります(復旧しない場合は kind delete cluster で削除し、本回の手順で作り直します)。
注意点(プロキシ環境):このあと導入する Calico はコンテナイメージをインターネット(quay.io)から取得します。whitelist プロキシ環境では、kind が ホストの HTTP_PROXY / HTTPS_PROXY / NO_PROXY をノードへ自動的に引き継ぐため、ノードの containerd はプロキシ経由でイメージを取得できます(kind は NO_PROXY に kind ネットワークやクラスタ内 CIDR を自動追記します)。quay.io が whitelist に登録されていれば追加設定は不要です。プロキシの無い環境では何も意識せずそのまま取得できます。
Calico CNI を導入する
Kubernetes は Pod 間の通信を CNI(Container Network Interface)プラグインに任せます。CNI が入るまでノードは NotReady のままです。本シリーズでは CNI に Calico を採用します。
- NetworkPolicy を確実にエンフォースする:第 16 回で学ぶ Pod 間の通信制御(NetworkPolicy)を、Calico は確実に適用します。kind 標準の kindnet はこのエンフォースが不確実です。
- 本番・試験と一致する:CKAD 本番試験の環境や第 2 巻の kubeadm クラスタでも Calico を使うため、学習環境を揃えられます。
Calico のマニフェストを取得し、Pod の IP 範囲を kind-config.yaml の podSubnet と一致させてから適用します。マニフェスト内の CALICO_IPV4POOL_CIDR(既定はコメントアウトされ 192.168.0.0/16)を 10.244.0.0/16 に変更します。次のコマンドは developer のホームディレクトリで実行し、calico.yaml はそこに(一般ユーザー所有で)ダウンロードされます。kubectl apply はファイルをクラスタへ送るだけなので root 権限は不要です。sed はマニフェストの版が変わるとパターンが一致しないことがあるため、適用前に grep -A1 CALICO_IPV4POOL_CIDR calico.yaml で値が 10.244.0.0/16 に変わったことを確認しておくと確実です(変わっていないと既定の 192.168.0.0/16 のままになり、検証環境の LAN と重複します)。
実行コマンド:
$ curl -fsSL -o calico.yaml https://raw.githubusercontent.com/projectcalico/calico/v3.32.0/manifests/calico.yaml
$ sed -i 's/# - name: CALICO_IPV4POOL_CIDR/- name: CALICO_IPV4POOL_CIDR/; s|# value: "192.168.0.0/16"| value: "10.244.0.0/16"|' calico.yaml
$ kubectl apply -f calico.yaml実行結果(例・抜粋):
daemonset.apps/calico-node created
deployment.apps/calico-kube-controllers created
serviceaccount/calico-node created
(ほかに ConfigMap・CRD・ClusterRole などが作成される)適用後、Calico の Pod(calico-node と calico-kube-controllers)が起動し、CoreDNS も含めて Running になると、ノードが Ready に変わります。手元の環境では適用から 2 分ほどで全 Pod が Running になりました。ここまでの kind とノード・Calico の関係を次の図に整理します。
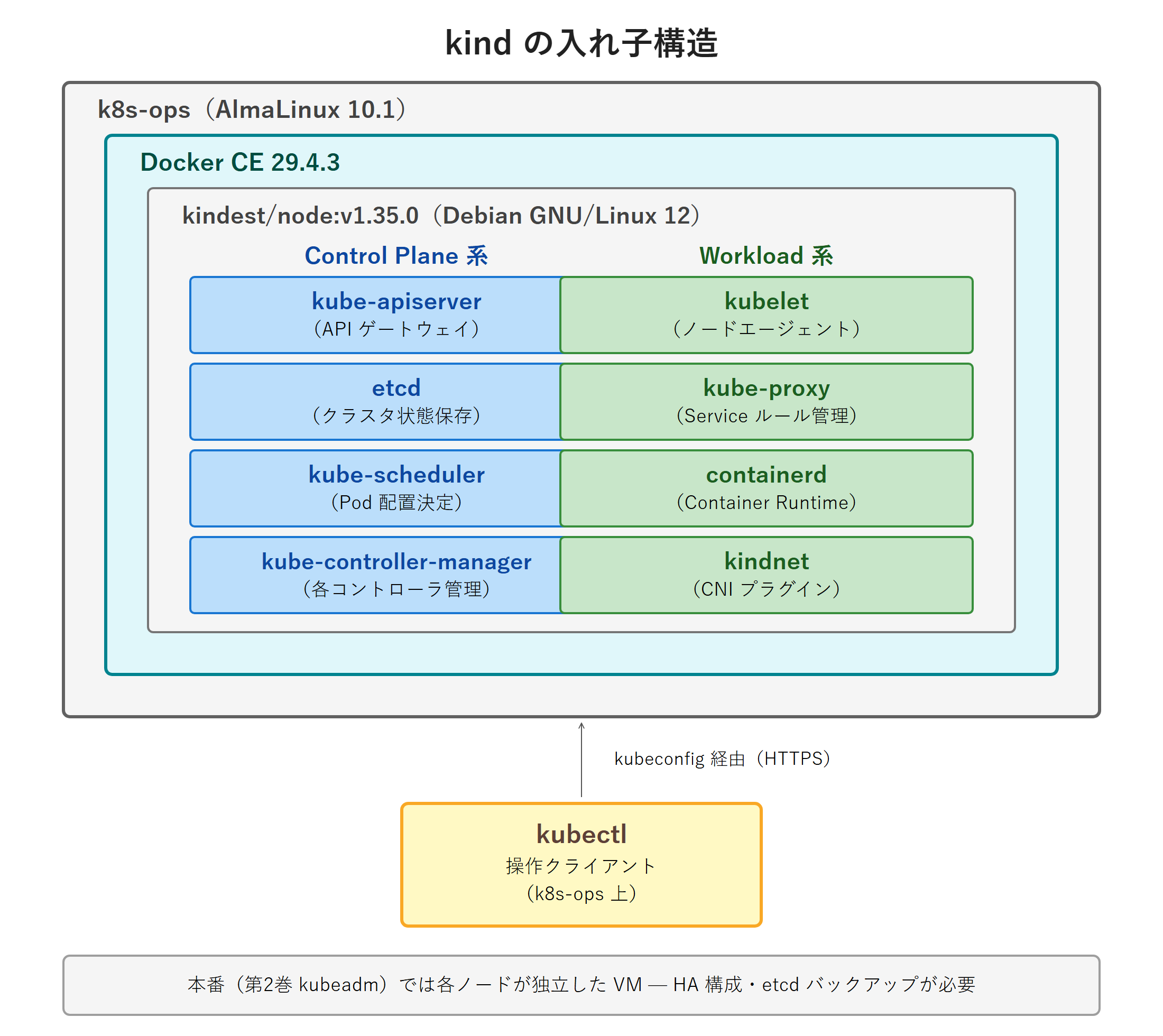
初めてクラスタに接続する
kubectl get nodes でノードの状態を確認します。CNI 導入の前後で STATUS が変わるのが観察ポイントです。Calico 適用前は次のように NotReady です。
実行コマンド:
$ kubectl get nodes実行結果(Calico 適用前の例):
NAME STATUS ROLES AGE VERSION
kind-control-plane NotReady control-plane 4s v1.35.0Calico 適用後にもう一度確認すると Ready になります。
実行結果(Calico 適用後の例):
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready control-plane 2m v1.35.0先ほどアーキテクチャ概要で挙げたコンポーネントが、実際に Pod として動いていることも確認します。
実行コマンド:
$ kubectl get pods -n kube-system実行結果(例):
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6b4b6457d5-twh8z 1/1 Running 0 35s
calico-node-bt2wx 1/1 Running 0 35s
coredns-7d764666f9-k26qw 1/1 Running 0 112s
coredns-7d764666f9-pfc52 1/1 Running 0 112s
etcd-kind-control-plane 1/1 Running 0 2m
kube-apiserver-kind-control-plane 1/1 Running 0 2m
kube-controller-manager-kind-control-plane 1/1 Running 0 119s
kube-proxy-968z5 1/1 Running 0 112s
kube-scheduler-kind-control-plane 1/1 Running 0 2m接続先のクラスタ情報は kubectl cluster-info で確認できます。
実行コマンド:
$ kubectl cluster-info実行結果(例):
Kubernetes control plane is running at https://127.0.0.1:33965
CoreDNS is running at https://127.0.0.1:33965/api/v1/namespaces/kube-system/services/kube-dns:dns/proxykind ノードからレジストリを参照できるようにする(第 7 回の準備)
第 7 回以降、第 4 回で push した自社イメージ k8s-registry:5000/fanclub-backend を Pod として動かします。そのとき Pod のイメージを取得するのは、ホストの Docker ではなくノードの containerd です。kind-config.yaml の containerdConfigPatches で指定した /etc/containerd/certs.d 配下に、k8s-registry 用の hosts.toml を作成して HTTP(TLS なし)での取得を許可します。ノードは k8s-ops の /etc/hosts を共有しないため、接続先は IP(192.168.1.123)で直接指定します。次のコマンドの kind-control-plane は、kind がノードとして作成した Docker コンテナの名前です(kubectl get nodes に出たノード名と同じで、docker ps でも確認できます)。docker exec はホスト上の developer が発行しますが、コマンドはノードコンテナ内では root として実行されるため、作成される hosts.toml はノード内の root 所有ファイルになります。なおこのファイルはノードコンテナ内に置かれるため、クラスタやノードを作り直すと消えます(その場合は再度作成します)。
実行コマンド:
$ docker exec kind-control-plane mkdir -p /etc/containerd/certs.d/k8s-registry:5000
$ docker exec kind-control-plane sh -c 'cat > /etc/containerd/certs.d/k8s-registry:5000/hosts.toml <<EOF
[host."http://192.168.1.123:5000"]
capabilities = ["pull", "resolve"]
skip_verify = true
EOF'ノードの containerd から自社イメージを取得できるか、crictl pull で確認します(crictl はノードに同梱されている CRI 操作ツールで、ホストへ別途導入する必要はありません)。
実行コマンド:
$ docker exec kind-control-plane crictl pull k8s-registry:5000/fanclub-backend:0.2.0実行結果(例):
Image is up to date for sha256:52b497e4d130...取得できれば、第 7 回で自社イメージを Pod として動かす土台が整いました。
学習用 kind と本番 kubeadm の違い:kind は 1 つの Docker コンテナをノードに見立てる学習用ツールで、API Server も 127.0.0.1 のローカル接続です。本番では複数の VM に Control Plane Node と Workload Node を分けて冗長化し、kubeadm で構築します。これは第 2 巻で扱います。学習で身につける kubectl 操作やマニフェストは、本番でもそのまま通用します。
やってみよう
dl.k8s.ioから kubectl(v1.35 系)、GitHub Releases から kind v0.31.0 を取得して配置し、それぞれバージョンを確認する。disableDefaultCNI: true/podSubnet: 10.244.0.0/16/extraPortMappings(80・443)を含むkind-config.yamlをホームディレクトリに作成する。kind create cluster --config ~/kind-config.yaml --image docker.io/kindest/node:v1.35.0でクラスタを作成し、kubectl get nodesでノードがNotReadyであることを確認する。calico.yamlを取得してCALICO_IPV4POOL_CIDRを10.244.0.0/16に変更し、kubectl applyする。- しばらく待って
kubectl get nodesがReadyに変わること、kubectl get pods -n kube-systemで calico-node などが Running であることを確認する。
理解度チェック
次の各文が正しいか(○)誤りか(×)を判断してください。解答は下にまとめています。
- クラスタの全状態(あるべき状態・現状)は etcd に保存される。
kubectlをはじめ各コンポーネントは、すべて kube-apiserver を介してやり取りする。- Kubernetes はコンテナランタイムとして Docker を必須とし、containerd は使えない。
- 新しい Pod をどのノードに載せるかを決めるのは kube-scheduler である。
- CNI プラグインを導入しなくても、ノードは最初から Ready になる。
disableDefaultCNI: trueとextraPortMappingsは、クラスタ作成後でも自由に追加・変更できる。- 本シリーズが Calico を採用する理由の一つは、NetworkPolicy を確実にエンフォースし、CKAD 本番や第 2 巻と CNI を揃えられるためである。
解答
- 1. ○:etcd がクラスタの状態を保持する分散キーバリューストア。
- 2. ○:API Server がクラスタの唯一の入り口。
- 3. ×:標準は containerd。Docker は必須ではなく、知識は OCI 標準を介して通用する。
- 4. ○:スケジューラが Pod の配置先ノードを決める。
- 5. ×:CNI が入るまでノードは NotReady。本回は Calico 導入で Ready になった。
- 6. ×:いずれもクラスタ作成時にしか設定できない。だから最初に決めておく。
- 7. ○:NetworkPolicy の確実なエンフォースと、本番・試験との CNI 一致が採用理由。
まとめ
本記事では、Docker 単独の限界(自己回復・スケール・複数ホスト・宣言的管理の不在)を起点に、Kubernetes が解決する問題とアーキテクチャ(Control Plane Node / Workload Node の各コンポーネント)を整理しました。そのうえで kind と kubectl を導入し、既定 CNI を無効化したクラスタを作成して NotReady を確認、Calico v3.32.0 を導入して Ready への遷移を観察しました。containerd のレジストリ設定で、第 7 回に向けた自社イメージ取得の準備も整えました。これで Kubernetes を操作する土台ができました。
次回予告
次回(第 6 回)は kubectl の基本操作と Observability(可観測性)・デバッグ入門を扱います。get / describe / logs / exec といった日常操作、-o yaml や kubectl explain の使い方、Pod のログ確認やイベント確認の基本を、実機で身につけます。
シリーズ一覧
第1部:コンテナと Docker
- 第1回 コンテナ技術概念 + Docker 環境準備
- 第2回 Docker 基本操作
- 第3回 Dockerfile + マルチステージ + JDK 25 / Payara Micro イメージビルド
- 第4回 コンテナレジストリ + イメージタグ戦略 + Trivy スキャン
第2部:Kubernetes 基礎
- 第5回 Kubernetes の全体像 + kind で軽量 K8s ← 今ここ
- 第6回 kubectl 基本操作 + Observability・Debug
第3部:アプリリソース
- 第7回 Pod + Multi-container パターン
- 第8回 Service とネットワーキング
- 第9回 ストレージ(PVC + StatefulSet)+ PostgreSQL DB 追加
- 第10回 ConfigMap + Secret + ServiceAccount 基礎
- 第11回 Job + CronJob + DaemonSet
第4部:ワークロード戦略
- 第12回 Deployment + 3 Probe + Rolling Update + Probe デバッグ実践
- 第13回 Deployment 戦略補完(Blue/Green + Canary + Recreate)
- 第14回 ResourceQuota + LimitRange + Multi-tenant Namespace
