
新卒インフラエンジニア向け「Kubernetes 実践教科書① CKAD アプリケーション開発編」の第14回です。第13回では複数のデプロイ戦略を体験しました。第12・13回で何度も「kind ノードは CPU 2 コアなので Pod を増やせない」という壁に当たりましたが、今回はそのリソースの取り合いをルールで管理します。Namespace でワークロードを分け、ResourceQuota で Namespace 全体の上限を、LimitRange で Pod / Container の既定値・上限を設定します。
動作確認バージョン:kind v0.31.0(K8s v1.35.0)/ kubectl v1.35.6 / fanclub-backend:0.3.1(default で稼働)/ busybox:1.37(2026-06-29 実機検証時点)
今ここマップ(全 19 回中の現在地)
現在地は第 4 部「ワークロード戦略」の第 14 回(部の最終回)です。リソース管理を学び、第 5 部のセキュリティへ橋渡しします。
- 第 1 部 コンテナと Docker(第 1〜4 回)
- 第 2 部 Kubernetes 基礎(第 5〜6 回)
- 第 3 部 アプリリソース(第 7〜11 回)
- 第 4 部 ワークロード戦略(第 12〜14 回)← 今ここ
- 第 5 部 セキュリティ基礎(第 15〜16 回)
- 第 6 部 パッケージ管理と HTTPS 公開(第 17〜19 回)
この回のゴール
- Namespace でワークロードを分離し、操作対象の Namespace を指定できる。
- ResourceQuota(Namespace 全体の上限)と LimitRange(Pod/Container の既定値・上限)を設定できる。
- 両者の相互作用と、requests / limits・QoS クラスの設計指針を説明できる。
本番の fanclub-api(frontend / backend / DB)は default Namespace でそのまま動かし続けます。今回は新しく fanclub-dev / fanclub-prod を作って、そこでリソース管理を体験します(本番アプリ全体の Namespace 移行は第17回の Helm で扱います)。
Namespace(マルチテナント分離単位)
Namespace はクラスタ内を論理的に区切る仕切りです。同じ名前のリソース(例: fanclub-backend という Deployment)を Namespace ごとに別々に持てるので、dev / staging / production のような環境分離に使います。ResourceQuota・LimitRange・RBAC はこの Namespace 単位で効きます。まず 2 つ作ります。実行コマンド:
$ kubectl create namespace fanclub-dev
$ kubectl create namespace fanclub-prod
$ kubectl get namespaces実行結果(例):作成した 2 つに加え、最初からある default や kube-system が並びます。
NAME STATUS AGE
default Active 8d
fanclub-dev Active 5s
fanclub-prod Active 5s
kube-node-lease Active 8d
kube-public Active 8d
kube-system Active 8d
local-path-storage Active 8dkubectl の操作は既定で default Namespaceを対象にします。別の Namespace を見る・触るには -n <namespace> を付けます(付け忘れると別の Namespace を操作してしまう、ありがちなミスです)。実行コマンド:
$ kubectl get pods -n fanclub-dev
$ kubectl get pods実行結果(例):fanclub-dev はまだ空、default には本番 fanclub-api が並びます。
No resources found in fanclub-dev namespace.
NAME READY STATUS RESTARTS AGE
fanclub-backend-xxxxxxxxxx-xxxxx 2/2 Running 0 1h
fanclub-db-0 1/1 Running 0 1h
fanclub-frontend 1/1 Running 0 1h
fanclub-logcollector-xxxxx 1/1 Running 0 1h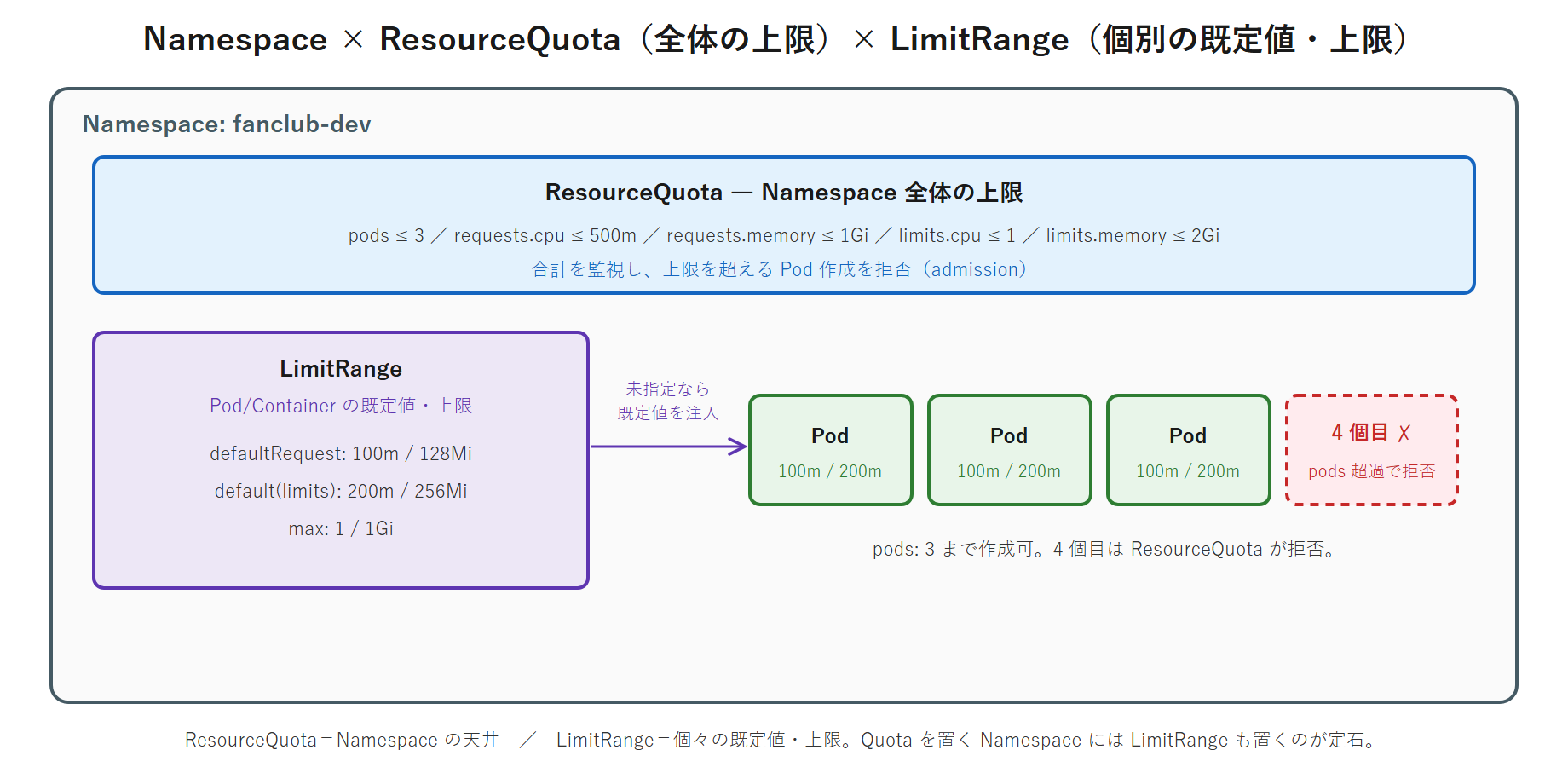
ResourceQuota(Namespace 全体の上限)
ResourceQuota は、その Namespace で使える合計の上限を決めます。CPU / メモリの requests・limits 合計や、Pod 数・PVC 数などを制限できます。fanclub-dev に適用します。次を fanclub-quota.yaml として developer のホームに作成します(一般ユーザー所有・root 不要)。
apiVersion: v1
kind: ResourceQuota
metadata:
name: fanclub-quota
namespace: fanclub-dev
spec:
hard:
requests.cpu: "500m"
requests.memory: 1Gi
limits.cpu: "1"
limits.memory: 2Gi
pods: "3"
persistentvolumeclaims: "2"本番想定ではもっと大きな値(CPU 数コア〜)を設定しますが、ここでは学習用に小さめにして「上限に当たる」様子を見やすくしています。適用して中身を確認します。実行コマンド:
$ kubectl apply -f fanclub-quota.yaml
$ kubectl describe resourcequota fanclub-quota -n fanclub-dev実行結果(例):まだ何も置いていないので Used はすべて 0 です。
Name: fanclub-quota
Namespace: fanclub-dev
Resource Used Hard
-------- ---- ----
limits.cpu 0 1
limits.memory 0 2Gi
persistentvolumeclaims 0 2
pods 0 3
requests.cpu 0 500m
requests.memory 0 1GiLimitRange(Pod / Container の既定値・上限)
LimitRange は、その Namespace の Pod / Container に対して requests / limits の既定値(指定し忘れたとき自動で付く値)と上限を与えます。fanclub-dev に適用します。次を fanclub-limits.yaml として作成します(developer 所有・root 不要)。
apiVersion: v1
kind: LimitRange
metadata:
name: fanclub-limits
namespace: fanclub-dev
spec:
limits:
- type: Container
default:
cpu: "200m"
memory: 256Mi
defaultRequest:
cpu: "100m"
memory: 128Mi
max:
cpu: "1"
memory: 1Gidefault:limitsを書かなかったコンテナに付く上限。defaultRequest:requestsを書かなかったコンテナに付く要求量。max:1 コンテナが指定できる上限(超える指定は拒否)。
適用し、リソース未指定の軽量ワークロードを fanclub-dev に置いて、既定値が自動で付くことを確認します。ここで fanclub-frontend を単体で置かないのには理由があります。frontend の Nginx は起動時に fanclub-backend を名前解決するため、backend Service の無い fanclub-dev では host not found in upstream で起動に失敗します(backend も fanclub-db 待ちで止まります)。実アプリは互いに依存するので、丸ごと別 Namespace へ移すには一式そろえる必要があり、それは第17回の Helm で扱います。ここでは quota / limitrange の確認に専念するため、依存の無い busybox の常駐ワークロードを使います。次を sample-app.yaml として作成します(developer 所有・root 不要)。
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
namespace: fanclub-dev
labels:
app: sample-app
spec:
replicas: 1
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: app
image: busybox:1.37
command: ["sleep", "infinity"]実行コマンド:
$ kubectl apply -f fanclub-limits.yaml
$ kubectl apply -f sample-app.yaml
$ kubectl rollout status deployment/sample-app -n fanclub-dev
$ POD=$(kubectl get pod -n fanclub-dev -l app=sample-app -o name | head -1)
$ kubectl get "$POD" -n fanclub-dev -o jsonpath='{.spec.containers[0].resources}{"\n"}'
$ kubectl get "$POD" -n fanclub-dev -o jsonpath='qos={.status.qosClass}{"\n"}'実行結果(例):マニフェストに resources を書いていないのに、LimitRange の既定値(requests 100m/128Mi・limits 200m/256Mi)が自動で注入されています。requests と limits が異なるので QoS クラスは Burstable です。
{"limits":{"cpu":"200m","memory":"256Mi"},"requests":{"cpu":"100m","memory":"128Mi"}}
qos=BurstableResourceQuota の使用量にも反映されます。実行コマンド:
$ kubectl describe resourcequota fanclub-quota -n fanclub-dev実行結果(例):Pod 1 つぶんが Used に乗りました。
Resource Used Hard
-------- ---- ----
limits.cpu 200m 1
limits.memory 256Mi 2Gi
persistentvolumeclaims 0 2
pods 1 3
requests.cpu 100m 500m
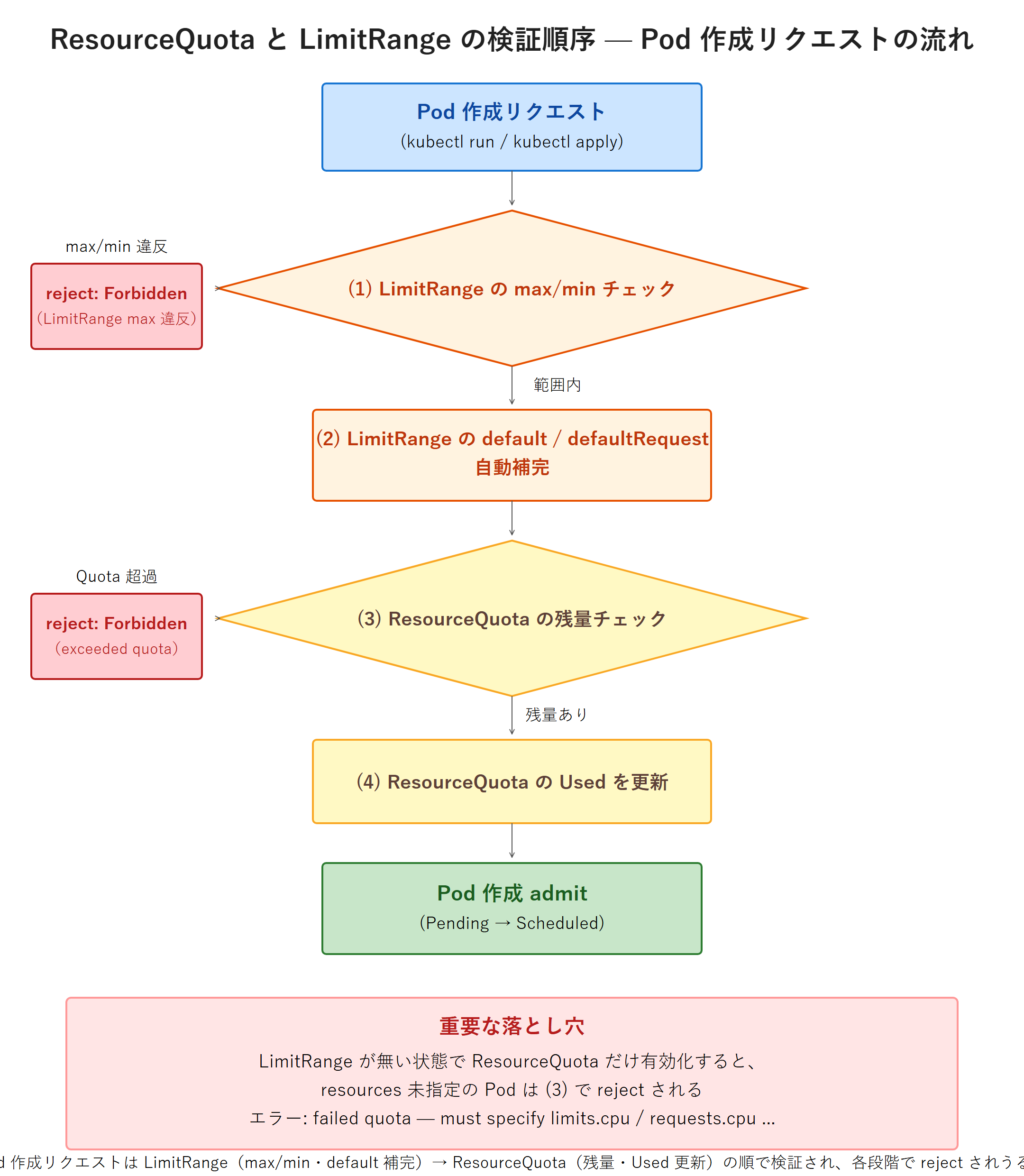
requests.memory 128Mi 1GiResourceQuota と LimitRange の相互作用
2 つの効き目を実際に確かめます。まず Quota の上限に当たるケース。fanclub-dev は pods: 3 なので、sample-app を 6 レプリカに増やしても 3 までしか作れません。実行コマンド:
$ kubectl scale deployment/sample-app -n fanclub-dev --replicas=6
$ kubectl get pods -n fanclub-dev
$ kubectl describe replicaset -n fanclub-dev -l app=sample-app | grep -iE "exceeded quota|forbidden" | head -1実行結果(例):Pod は 3 で頭打ちになり、ReplicaSet のイベントに「Quota を超えた」と出ます。
NAME READY STATUS RESTARTS AGE
sample-app-57bcb8d947-2xk9p 1/1 Running 0 3m
sample-app-57bcb8d947-7sld2 1/1 Running 0 15s
sample-app-57bcb8d947-9wm4c 1/1 Running 0 15s
Warning FailedCreate ... Error creating: pods "sample-app-57bcb8d947-..." is forbidden: exceeded quota: fanclub-quota, requested: pods=1, used: pods=3, limited: pods=3なお ResourceQuota は「作成を許す上限(admission)」であって、作成できた Pod が実際に動くかはノードの空き容量とは別問題です。本シリーズの 2 コアノードでは、Quota を大きくしてもノード容量を超える Pod は Pending(Insufficient cpu)になります。今回は Pod 数を 3 に抑え、全部が動く範囲で Quota の頭打ちだけを見ています。
確認できたら 1 レプリカに戻します。実行コマンド:
$ kubectl scale deployment/sample-app -n fanclub-dev --replicas=1次に、ResourceQuota はあるのに LimitRange が無いケース。fanclub-prod に Quota だけ付けて、resources 未指定の Pod を作ろうとすると——既定値を付ける LimitRange が無いため、Quota が「requests/limits を明示せよ」と拒否します。実行コマンド:
$ kubectl create quota prod-quota -n fanclub-prod --hard=requests.cpu=500m,limits.cpu=1
$ kubectl run noreq --image=busybox:1.37 -n fanclub-prod --command -- sleep 3600実行結果(例):Pod 作成が拒否されます。
Error from server (Forbidden): pods "noreq" is forbidden: failed quota: prod-quota: must specify limits.cpu for: noreq; requests.cpu for: noreqつまり Quota を置く Namespace には LimitRange も置くのが定石です。そうすれば、開発者が resources を書き忘れても既定値が付いて Pod が作れ、かつ Namespace 全体の上限も守られます。
requests / limits 設計指針と QoS クラス
- requests:スケジューラが「この量は確保する」と保証する値。ノードの空きと突き合わせて配置先を決める基準。
- limits:そのコンテナが使える上限。CPU は超えるとスロットリング、メモリは超えると
OOMKilled。
requests と limits の付け方で、Pod は 3 つの QoS クラスに分かれます。ノードが逼迫したときの追い出され(Eviction)の優先順位に影響します。
- Guaranteed:全コンテナで requests=limits(両方指定・同値)。最優先で守られる。
- Burstable:requests < limits など、一部だけ指定。空きがあれば limits まで使える。
- BestEffort:requests も limits も無し。最初に追い出される。
設計の目安は、requests は「普段必要な量」を控えめに、limits は「ピークの上限」を現実的に。本番の重要ワークロードは requests=limits の Guaranteed に寄せると安定します。第12回の Backend は requests 250m / limits 1000m の Burstable で、起動時だけ多めに CPU を使えるようにしていました。
やってみよう
fanclub-dev/fanclub-prodを作成し、kubectl get pods -n fanclub-devと-nなしの違いを確認する。fanclub-devに ResourceQuota(pods: 3等)と LimitRange(default / defaultRequest / max)を適用する。- リソース未指定の軽量ワークロード(
sample-app・busybox)をfanclub-devに置き、LimitRange の既定値が注入され QoS がBurstableになることを確認する。 sample-appを 6 レプリカに増やし、pods: 3で頭打ち+exceeded quotaイベントを確認し、1 に戻す。fanclub-prodに Quota だけ付け、resources 未指定 Pod が拒否される(LimitRange の必要性)ことを確認する。
理解度チェック
次の各文が正しいか(○)誤りか(×)を判断してください。解答は下にまとめています。
- Namespace は同名リソースの衝突を避け、ResourceQuota や RBAC の適用単位になる。
- ResourceQuota は Namespace 全体の合計リソース上限(CPU/メモリ/Pod 数など)を設ける。
- LimitRange は Pod / Container に requests / limits の既定値や上限を与える。
- ResourceQuota がある Namespace で LimitRange が無いと、resources 未指定の Pod は作成できないことがある。
- requests はスケジューリング時に確保を保証する値、limits は使用上限である。
- 全コンテナで requests と limits が等しい Pod は BestEffort クラスになる。
- ResourceQuota の使用量は
kubectl describe resourcequotaで確認できる。 - 別の Namespace のリソースは、
-nを付けなくても既定で一覧に出る。
解答
- 1. ○:論理分離の単位で、Quota / LimitRange / RBAC はこの単位で効く。
- 2. ○:Namespace 内の合計に対する上限。
- 3. ○:既定値(default / defaultRequest)と上限(max)を与える。
- 4. ○:既定値を付ける LimitRange が無いと、Quota が requests/limits の明示を要求して弾く。
- 5. ○:requests=保証、limits=上限。
- 6. ×:requests=limits は Guaranteed。BestEffort は両方未指定。
- 7. ○:
Used/Hardが表示される。 - 8. ×:kubectl は既定で
default対象。別 Namespace は-n指定が必要。
まとめ
本記事では、Namespace でワークロードを分け、ResourceQuota で Namespace 全体の上限を、LimitRange で Pod/Container の既定値・上限を設定しました。両者は補い合う関係で、Quota を置く Namespace には LimitRange も置くのが定石です。requests=保証・limits=上限という役割と、QoS クラス(Guaranteed / Burstable / BestEffort)の違いも押さえました。本番 fanclub-api は default のまま、新設の fanclub-dev でリソース管理を体験しました。これで第 4 部「ワークロード戦略」は完了です。
次回予告
次回(第15回)からは第 5 部「セキュリティ基礎」です。RBAC(誰が何をできるか)・SecurityContext(非 root / 読み取り専用ルートFS)・Admission Controller の概念・CRD の利用で、アプリをセキュアにしていきます。
シリーズ一覧
第1部:コンテナと Docker
- 第1回 コンテナ技術概念 + Docker 環境準備
- 第2回 Docker 基本操作
- 第3回 Dockerfile + マルチステージ + JDK 25 / Payara Micro イメージビルド
- 第4回 コンテナレジストリ + イメージタグ戦略 + Trivy スキャン
第2部:Kubernetes 基礎
第3部:アプリリソース
- 第7回 Pod + Multi-container パターン
- 第8回 Service とネットワーキング
- 第9回 ストレージ(PVC + StatefulSet)+ PostgreSQL DB 追加
- 第10回 ConfigMap + Secret + ServiceAccount 基礎
- 第11回 Job + CronJob + DaemonSet
第4部:ワークロード戦略
- 第12回 Deployment + 3 Probe + Rolling Update + Probe デバッグ実践
- 第13回 Deployment 戦略補完(Blue/Green + Canary + Recreate)
- 第14回 ResourceQuota + LimitRange + Multi-tenant Namespace ← 今ここ
