
新卒インフラエンジニア向け「Kubernetes 実践教科書① CKAD アプリケーション開発編」の第12回です。第11回までで 3 層アプリと Job/CronJob/DaemonSet が揃いました。ただし Backend はまだ素の Podで、消えると自分では戻りません。ここから第 4 部「ワークロード戦略」です。今回は Backend を Deployment 化して自己回復を持たせ、3 種の Probe(liveness / readiness / startup)とローリングアップデート、そして Probe のデバッグを学びます。
動作確認バージョン:kind v0.31.0(K8s v1.35.0)/ kubectl v1.35.6 / fanclub-backend:0.3.0 / busybox:1.37 / postgres:18(2026-06-28 実機検証時点)
今ここマップ(全 19 回中の現在地)
現在地は第 4 部「ワークロード戦略」の第 12 回です。Backend を本番運用の形(Deployment + Probe)に整えます。
- 第 1 部 コンテナと Docker(第 1〜4 回)
- 第 2 部 Kubernetes 基礎(第 5〜6 回)
- 第 3 部 アプリリソース(第 7〜11 回)
- 第 4 部 ワークロード戦略(第 12〜14 回)← 今ここ
- 第 5 部 セキュリティ基礎(第 15〜16 回)
- 第 6 部 パッケージ管理と HTTPS 公開(第 17〜19 回)
この回のゴール
- Backend を Deployment 化し、自己回復とローリングアップデートを実施できる。
- startupProbe / livenessProbe / readinessProbe を設計し、3 つの役割を説明できる。
- Probe 起因の CrashLoopBackOff を
describe/logs --previousで切り分けられる。
Deployment と ReplicaSet
これまで Backend は単体の Pod でした。Pod を直接作ると、ノード障害や誤削除で消えたときに誰も復旧してくれません。Deployment は「望ましい状態(レプリカ数・使うイメージ)」を宣言し、その状態を保ち続けるワークロードです。Deployment は内部で ReplicaSet を作り、ReplicaSet が指定数の Pod を維持します(Pod が減れば作り直す=自己回復)。さらに Deployment はイメージ更新時のローリングアップデートも担います。
関係は Deployment →(管理)→ ReplicaSet →(管理)→ Pod です。私たちは Deployment を宣言するだけで、ReplicaSet と Pod は自動で面倒を見てもらえます。
3 種の Probe
Kubernetes は 3 種類の Probe(ヘルスチェック)で Pod の状態を判断します。fanclub-backend は第3回から MicroProfile Health の /health/live・/health/ready・/health/started を備えているので、それらを使います。
- livenessProbe(
/health/live):プロセスが生きているか。失敗するとコンテナを再起動します。DB 切断時もUPを返す設計(DB 障害で再起動ループに陥らせない)。 - readinessProbe(
/health/ready):リクエストを受けられるか。失敗すると Service の転送先から外されます(DB 接続を確認)。 - startupProbe(
/health/started):起動が完了したか。成功するまで liveness/readiness を始めません。Java/Payara のように起動が遅いアプリで liveness の誤射を防ぎます。
本シリーズの Payara Micro は起動に約 11 秒かかります(実機計測)。startupProbe を failureThreshold: 30 × periodSeconds: 10 = 最大 300 秒で構えておけば、起動が多少伸びても liveness に殺されません。この「startup が終わるまで liveness を待たせる」協調が肝心です。

Backend を Deployment + 3 Probe にする
第11回までの単体 Pod を Deployment に置き換えます。次のマニフェストを developer のホームに backend-deploy.yaml として作成します(一般ユーザー所有のファイルで、kubectl apply はクラスタへ送るだけなので root 権限は不要です)。設定は第10回の ConfigMap / Secret を envFrom で再利用し、専用 SA も引き継ぎます。第7回で組んだ依存待ち Init Container(wait-for-db)とログ Sidecar(log-shipper)も applog ボリュームごとそのまま引き継ぎ、本体コンテナに 3 Probe を足します(積み上げてきたマルチコンテナ構成を保ったまま Deployment 化します。Init / Sidecar の詳細は第7回参照)。参照する fanclub-config(ConfigMap)・fanclub-db-secret(Secret)・fanclub-backend(ServiceAccount)と、wait-for-db が名前解決を待つ DB の fanclub-db Service は、いずれも前回までに作成済みである前提です(未作成だと Pod が CreateContainerConfigError や Init で停止します)。イメージは 0.3.0 のままです(Probe は既存の /health/* を使うだけで、再ビルドは不要)。
apiVersion: apps/v1
kind: Deployment
metadata:
name: fanclub-backend
labels:
app: fanclub-backend
spec:
replicas: 1
selector:
matchLabels:
app: fanclub-backend
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
template:
metadata:
labels:
app: fanclub-backend
spec:
serviceAccountName: fanclub-backend
automountServiceAccountToken: false
initContainers:
- name: wait-for-db
image: busybox:1.37
command:
- sh
- -c
- 'until nslookup fanclub-db.default.svc.cluster.local >/dev/null 2>&1; do echo "waiting for fanclub-db..."; sleep 2; done; echo "fanclub-db resolved"'
- name: log-shipper
image: busybox:1.37
restartPolicy: Always
command:
- sh
- -c
- 'echo "sidecar started"; tail -F /var/log/app/app.log 2>/dev/null || sleep infinity'
volumeMounts:
- name: applog
mountPath: /var/log/app
containers:
- name: backend
image: k8s-registry:5000/fanclub-backend:0.3.0
ports:
- containerPort: 8080
envFrom:
- configMapRef:
name: fanclub-config
- secretRef:
name: fanclub-db-secret
startupProbe:
httpGet:
path: /health/started
port: 8080
failureThreshold: 30
periodSeconds: 10
livenessProbe:
httpGet:
path: /health/live
port: 8080
periodSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /health/ready
port: 8080
periodSeconds: 10
failureThreshold: 3
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "768Mi"
cpu: "1000m"
volumeMounts:
- name: applog
mountPath: /var/log/app
volumes:
- name: applog
emptyDir: {} replicas は 1(学習環境の都合):本シリーズの kind ノードは CPU 2 コアです。requests.cpu: 250m の Backend を 2 レプリカにすると、ローリングアップデート時に一時的に増える 3 つ目の Pod が CPU 不足でスケジュールできず(Insufficient cpu)ロールアウトが止まります。ここでは replicas: 1 とし、更新時は maxSurge: 1 で一時的に 2 Pod(合計 500m)に収めます。本番の複数レプリカは第2巻の HA クラスタで扱います。
第11回までの単体 Pod を削除してから Deployment を適用します。実行コマンド:
$ kubectl delete pod fanclub-backend --ignore-not-found
$ kubectl apply -f backend-deploy.yaml
$ kubectl rollout status deployment/fanclub-backend
$ kubectl get deploy,rs,pod -l app=fanclub-backend実行結果(例):Deployment → ReplicaSet → Pod の階層ができ、Pod が 2/2 で Running になります(本体 backend + log-shipper サイドカーの 2 コンテナ。startupProbe が Payara 起動を待ってから Ready 判定)。
deployment "fanclub-backend" successfully rolled out
NAME READY UP-TO-DATE AVAILABLE
deployment.apps/fanclub-backend 1/1 1 1
NAME DESIRED CURRENT READY
replicaset.apps/fanclub-backend-558f57548f 1 1 1
NAME READY STATUS RESTARTS
pod/fanclub-backend-558f57548f-bc26v 2/2 Running 0readiness が UP になり、CRUD が動くことを確認します(DB のデータは第9・11回から PVC に残っています)。アクセス先の http://fanclub-backend:8080 は第8回で作った fanclub-backend Service の名前解決です。Deployment が作る Pod も app: fanclub-backend ラベルを持つので、この Service の転送先(endpoint)として自動登録され、Pod 名が変わってもアクセス先は変わりません。
実行コマンド:
$ kubectl run c1 --rm -i --restart=Never --image=curlimages/curl:latest -- \
curl -s http://fanclub-backend:8080/health/ready
$ kubectl run c2 --rm -i --restart=Never --image=curlimages/curl:latest -- \
curl -s -o /dev/null -w "api=%{http_code}\n" http://fanclub-backend:8080/api/members実行結果(例):
{"status":"UP","checks":[{"name":"fanclub-api-ready","status":"UP","data":{}}]}
api=200自己回復を体験する
Pod を消しても ReplicaSet がすぐ新しい Pod を作ることを確認します。実行コマンド:
$ kubectl get pod -l app=fanclub-backend
$ kubectl delete pod -l app=fanclub-backend
$ kubectl get pod -l app=fanclub-backend実行結果(例):削除直後に別名の新しい Podが作られています(単体 Pod 時代には無かった自己回復です)。生まれたての Pod は 1/2=先に起動する log-shipper サイドカーだけ Ready で、backend は startupProbe 通過後に 2/2 へ進みます。
NAME READY STATUS RESTARTS AGE
fanclub-backend-558f57548f-bc26v 2/2 Running 0 3m
(削除後)
NAME READY STATUS RESTARTS AGE
fanclub-backend-558f57548f-j5nrm 1/2 Running 0 8sローリングアップデート
Deployment のテンプレートを変えると、Deployment は新しい ReplicaSet を作り、Pod を少しずつ入れ替えます。入れ替え方は strategy.rollingUpdate で決めます。
maxSurge:更新中に一時的に増やせる Pod 数。1なら新 Pod を 1 つ先に立てられます。maxUnavailable:更新中に欠けてよい Pod 数。0なら「新 Pod が Ready になってから旧 Pod を消す」=ダウンタイムなし。
動作を見るため、環境変数を 1 つ足してロールアウトを起こします(イメージは変えません)。実行コマンド:
$ kubectl set env deployment/fanclub-backend ROLLOUT_DEMO=1
$ kubectl rollout status deployment/fanclub-backend
$ kubectl rollout history deployment/fanclub-backend実行結果(例):新 Pod が Ready になってから旧 Pod が終了し、ロールアウトが完了します。history にリビジョンが積まれます。
Waiting for deployment "fanclub-backend" rollout to finish: 1 old replicas are pending termination...
deployment "fanclub-backend" successfully rolled out
deployment.apps/fanclub-backend
REVISION CHANGE-CAUSE
1 <none>
2 <none>問題があれば 1 つ前のリビジョンに戻せます(undo)。実行コマンド:
$ kubectl rollout undo deployment/fanclub-backend
$ kubectl rollout status deployment/fanclub-backend実行結果(例):
deployment.apps/fanclub-backend rolled back
deployment "fanclub-backend" successfully rolled out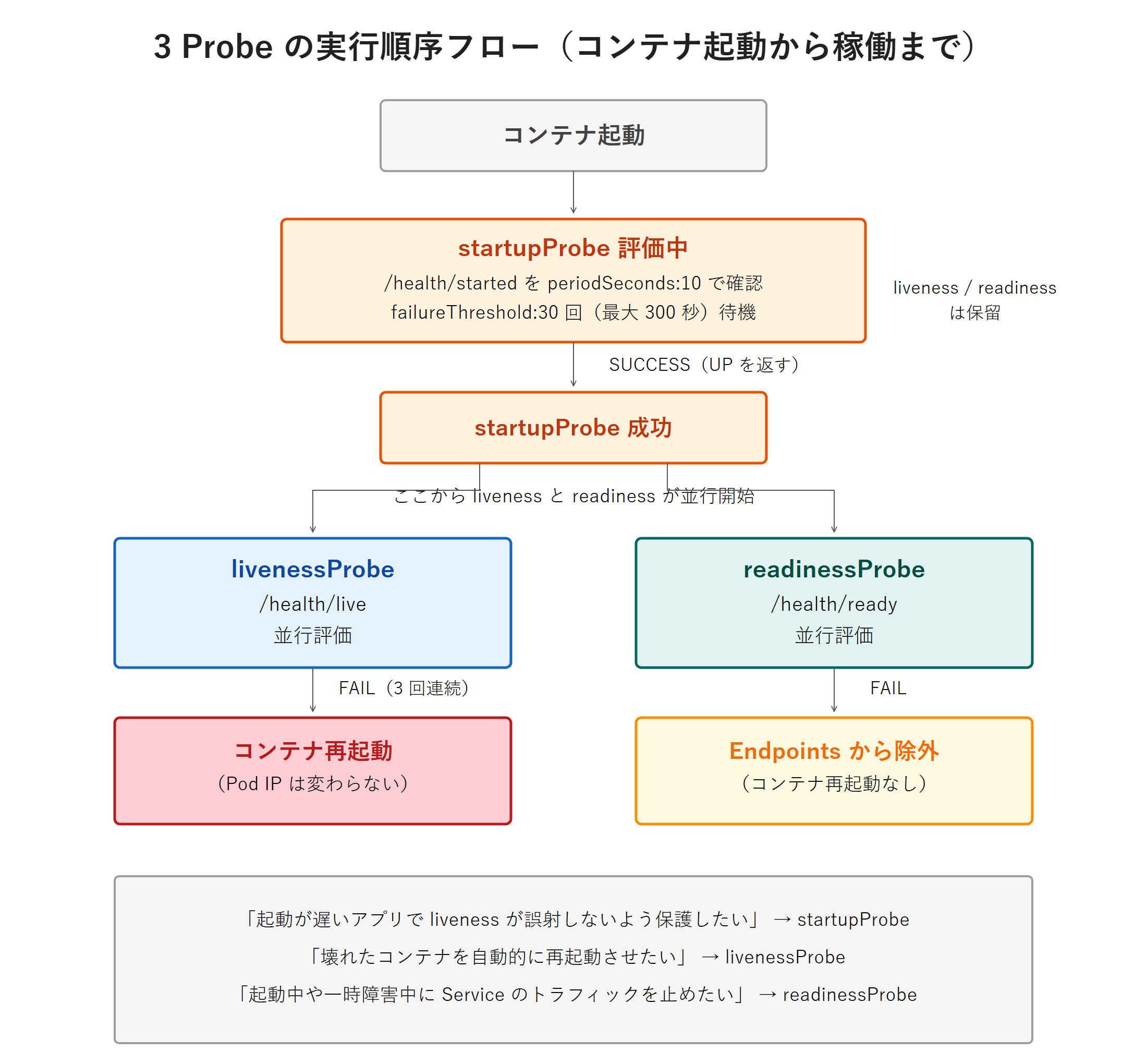
Probe デバッグ実践
Probe の設定ミスは現場で頻出します。代表例として、livenessProbe を誤ったポートに向けてしまった場合を再現します。アプリ自体は正常なのに liveness が通らず、Pod が再起動を繰り返して CrashLoopBackOff になります。
わざと liveness のポートを 9090(何も待ち受けていない)に変えます。実行コマンド:
$ kubectl patch deployment fanclub-backend --type=json \
-p='[{"op":"replace","path":"/spec/template/spec/containers/0/livenessProbe/httpGet/port","value":9090}]'
$ kubectl get pod -l app=fanclub-backend -wここで怖いのは、誤っているのが liveness だけで readiness(8080)は通る点です。新 Pod はいったん Ready になるためロールアウトが進み、旧 Pod は置き換えられて消えます。その後 liveness(9090)が約 30 秒で失敗し、新 Pod が再起動を繰り返して RESTARTS が増え、CrashLoopBackOff に陥ります(-w は Ctrl-C で抜けます)。log-shipper サイドカーは生き続けるので READY は 1/2 のまま、backend だけが再起動を繰り返します。「readiness は通るのに liveness の設定ミスで本番が不安定化する」——これが liveness 誤設定の怖さです(readiness が失敗するなら maxUnavailable: 0 がロールアウトを止めて旧 Pod を守りますが、今回は readiness が通るためすり抜けます)。原因を describe の Events で確認します。
実行コマンド:
$ kubectl describe pod -l app=fanclub-backend | grep -A1 Events -m1
$ kubectl describe pod -l app=fanclub-backend | grep -iE "Liveness|Killing"実行結果(例):spec.containers{backend} の liveness が接続拒否で失敗し、backend コンテナだけが再起動されている(log-shipper サイドカーは無事)ことが分かります。
Warning Unhealthy ... spec.containers{backend}: Liveness probe failed: Get "http://10.244.82.50:9090/health/live": dial tcp 10.244.82.50:9090: connect: connection refused
Normal Killing ... spec.containers{backend}: Container backend failed liveness probe, will be restarted「アプリが壊れたのか、Probe の設定ミスか」を切り分けるには kubectl logs --previous(1 つ前のコンテナのログ)が有効です。複数コンテナの Pod なので -c backend でコンテナを指定します(省略すると「a container name must be specified」エラーになります)。実行コマンド:
$ POD=$(kubectl get pod -l app=fanclub-backend -o name | head -1)
$ kubectl logs "$POD" -c backend --previous | grep -i "ready in"実行結果(例):前のコンテナは正常に起動していました(ready in が出ている)。つまりアプリは健全で、原因は Probe の設定(誤ポート)だと分かります。さらに調べたいときは kubectl debug で一時コンテナを足してネットワークを確認できます(第6回参照)。
Payara Micro 7.2026.4 (build 7) ready in 11,494 (ms)原因が分かったら、正しいマニフェスト(liveness は 8080)を再適用して復旧します。実行コマンド:
$ kubectl apply -f backend-deploy.yaml
$ kubectl rollout status deployment/fanclub-backend実行結果(例):正しい Probe の Pod に入れ替わり、復旧します。
deployment "fanclub-backend" successfully rolled outやってみよう
- 単体 Pod を削除し、
backend-deploy.yaml(Deployment + Init/Sidecar 継承 + 3 Probe)を適用してrollout statusで完了を確認し、Pod がREADY 2/2になることを確認する。 kubectl delete pod -l app=fanclub-backendで Pod を消し、ReplicaSet が自動で作り直す(自己回復)ことを確認する。kubectl set envでロールアウトを起こし、rollout status/history/undoを実行する。- liveness を誤ポート 9090 に変えて CrashLoopBackOff を再現し、
describeの Events とlogs --previousで「Probe 設定ミス」と切り分け、正しい manifest で復旧する。
理解度チェック
次の各文が正しいか(○)誤りか(×)を判断してください。解答は下にまとめています。
- Deployment は ReplicaSet を介して Pod を管理し、Pod を削除しても自動で再生成する。
- Deployment の Pod は Job と同じく、処理が終わると再起動されず終了する。
- readinessProbe が失敗した Pod は、Service の転送先から外される。
- startupProbe は、起動の遅いアプリで liveness の誤射(早すぎる再起動)を防ぐ。
maxUnavailable: 0のローリングアップデートは、新 Pod が Ready になってから旧 Pod を消す。- liveness が誤ポートを指していると、アプリが正常でも Pod が再起動を繰り返して CrashLoopBackOff になりうる。
- CrashLoopBackOff の調査では
kubectl describeの Events とkubectl logs --previousが有効である。
解答
- 1. ○:Deployment→ReplicaSet→Pod。自己回復する。
- 2. ×:Deployment は常駐ワークロード。Pod が消えれば作り直す(終了させない)。完了型は Job。
- 3. ○:readiness 失敗=受付不可として Service から切り離す。
- 4. ○:startup 成功まで liveness/readiness を待たせる。Payara の長い起動を吸収。
- 5. ○:maxUnavailable:0 + maxSurge:1 でダウンタイムなしの入れ替え。
- 6. ○:アプリ正常でも Probe 設定ミスで再起動ループ→CrashLoopBackOff。
- 7. ○:Events で失敗理由、
--previousで前コンテナのログを確認する。
まとめ
本記事では Backend を単体 Pod から Deployment に移行し、ReplicaSet による自己回復を得ました。3 種の Probe(liveness は再起動・readiness は転送可否・startup は起動猶予)を設計し、Payara の約 11 秒の起動を startupProbe で吸収しました。ローリングアップデート(maxSurge / maxUnavailable・rollout status / history / undo)でダウンタイムなしの更新と巻き戻しを行い、誤ポートの liveness で起きる CrashLoopBackOff を describe と logs --previous で「Probe 設定ミス」と切り分けました。イメージは 0.3.0 のまま、運用面だけを強化できました。
次回予告
次回(第13回)は、ローリング以外のデプロイ戦略 Blue/Green・Canary・Recreate を実装して比較します。Service のセレクタ切り替えやレプリカ比率で、リスクを抑えたリリースを体験します。
シリーズ一覧
第1部:コンテナと Docker
- 第1回 コンテナ技術概念 + Docker 環境準備
- 第2回 Docker 基本操作
- 第3回 Dockerfile + マルチステージ + JDK 25 / Payara Micro イメージビルド
- 第4回 コンテナレジストリ + イメージタグ戦略 + Trivy スキャン
第2部:Kubernetes 基礎
第3部:アプリリソース
- 第7回 Pod + Multi-container パターン
- 第8回 Service とネットワーキング
- 第9回 ストレージ(PVC + StatefulSet)+ PostgreSQL DB 追加
- 第10回 ConfigMap + Secret + ServiceAccount 基礎
- 第11回 Job + CronJob + DaemonSet
第4部:ワークロード戦略
- 第12回 Deployment + 3 Probe + Rolling Update + Probe デバッグ実践 ← 今ここ
- 第13回 Deployment 戦略補完(Blue/Green + Canary + Recreate)
- 第14回 ResourceQuota + LimitRange + Multi-tenant Namespace
