
新卒インフラエンジニア向け「Kubernetes 実践教科書① CKAD アプリケーション開発編」の第11回です。第10回で設定を ConfigMap / Secret に外部化しました。ここまでのワークロードは Pod / StatefulSet のように常駐するものでした。今回は 一度きりの Job、定期実行の CronJob、全ノードに 1 つずつ配置する DaemonSet を学び、fanclub-api に DB マイグレーション Job・サマリーレポート CronJob・ログコレクタ DaemonSet を追加します。
動作確認バージョン:kind v0.31.0(K8s v1.35.0)/ kubectl v1.35.6 / fanclub-backend:0.3.0 / postgres:18 / busybox:1.37(2026-06-27 実機検証時点)
今ここマップ(全 19 回中の現在地)
現在地は第 3 部「アプリリソース」の第 11 回です。第 3 部の最後として、バッチ系のワークロードを押さえます。
- 第 1 部 コンテナと Docker(第 1〜4 回)
- 第 2 部 Kubernetes 基礎(第 5〜6 回)
- 第 3 部 アプリリソース(第 7〜11 回)← 今ここ
- 第 4 部 ワークロード戦略(第 12〜14 回)
- 第 5 部 セキュリティ基礎(第 15〜16 回)
- 第 6 部 パッケージ管理と HTTPS 公開(第 17〜19 回)
この回のゴール
- Job / CronJob / DaemonSet を用途に合わせて選択し、実装できる。
- Job の
backoffLimit/restartPolicy/ttlSecondsAfterFinishedを説明できる。 - 冪等なマイグレーション Job、定期レポート CronJob、ログコレクタ DaemonSet を fanclub-api に追加できる。
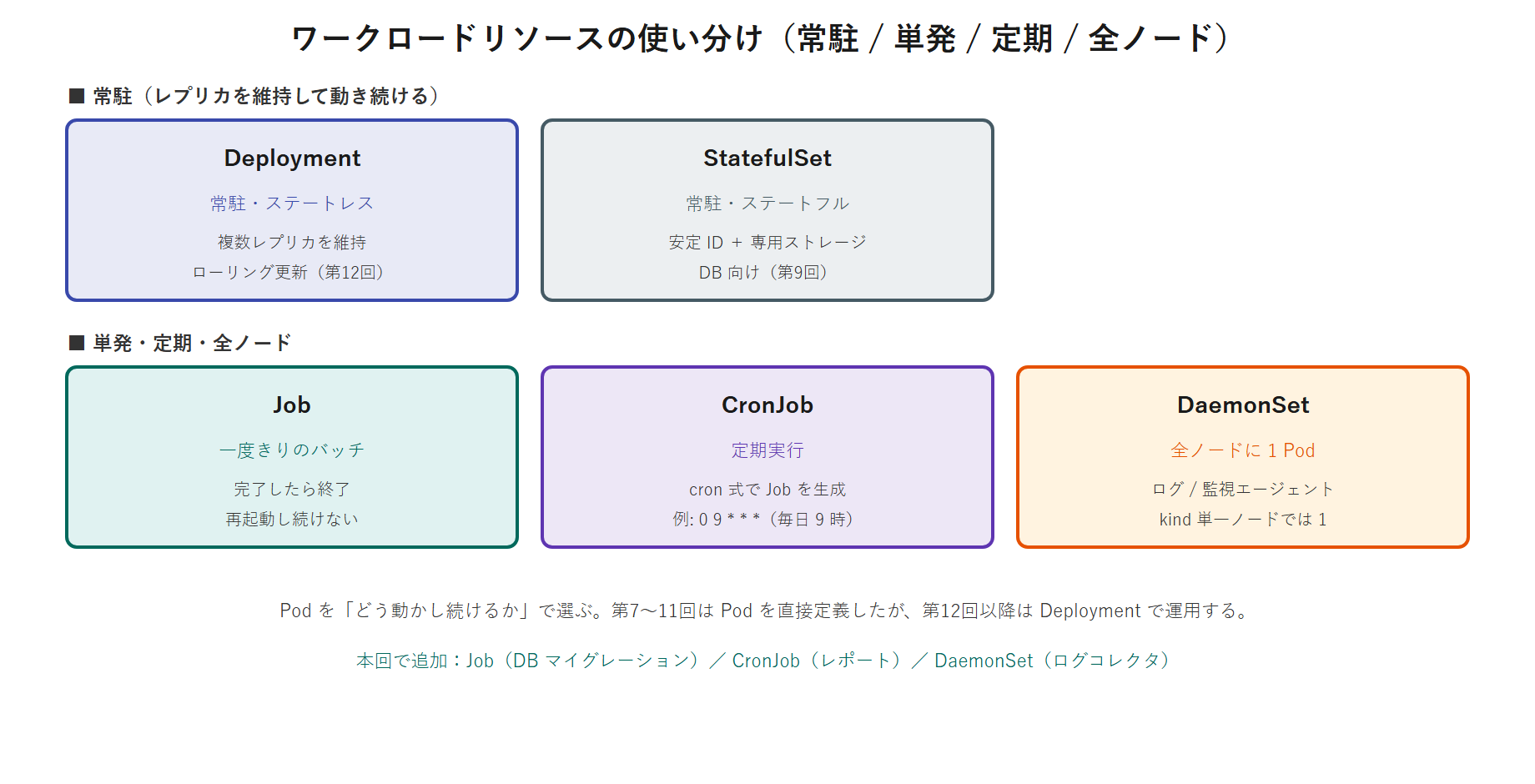
ワークロードリソースの全体像
「Pod をどう動かし続けるか」を担うのがワークロードリソースです。常駐・単発・定期・全ノードで使い分けます。
- Deployment(常駐・ステートレス):Web/API などをレプリカ維持・ローリングアップデート(第12回)。
- StatefulSet(常駐・ステートフル):DB など。安定 ID + 専用ストレージ(第9回)。
- Job(単発):一度きりのバッチ。完了したら終了し、再起動し続けない。
- CronJob(定期):cron スケジュールで Job を定期生成。
- DaemonSet(全ノード):対象ノードごとに 1 Pod(ログ/監視エージェント等)。
Job(一度きりのバッチ)
Job は処理を最後まで実行して完了させるワークロードです。Deployment と違い、完了した Pod を再起動し続けません。主なフィールドは次のとおりです。
completions:成功させたい実行回数(既定 1)。parallelism:同時実行数。backoffLimit:失敗時のリトライ上限。超えると Job は失敗扱いになる。restartPolicy:Job ではNeverかOnFailureのみ。Alwaysは指定できません(apply で弾かれます)。ttlSecondsAfterFinished:完了/失敗した Job を一定秒後に自動削除(後片付け)。
CronJob(定期実行)
CronJob は schedule の cron 式に従って Job を定期生成します。cron 式は 分 時 日 月 曜日 の 5 フィールドで、例えば 0 9 * * * は「毎日 9:00」です。
concurrencyPolicy:前回の実行が終わっていないときの挙動。Allow(既定)/Forbid(重複させない)/Replace。startingDeadlineSeconds:開始が遅れた場合に実行を諦める猶予。- スケジュールを待たずに今すぐ試したいときは、
kubectl create job <名前> --from=cronjob/<CronJob名>で手動実行できます。
DaemonSet(全 Workload Node へ 1 Pod)
DaemonSet は対象ノードごとに必ず 1 つ Pod を配置します。ノードが増えれば自動で 1 Pod 追加されます。ログ収集エージェントやノード監視のように「各ノードに 1 つ要る」ものに使います。
nodeSelector/affinity:配置するノードを限定する。tolerations:taint の付いたノード(Control Plane 等)にも配置したい場合に付ける。- 本回の kind は単一ノードなので DaemonSet の Pod は 1 つです(複数ノードでの本番ログ基盤 Fluent Bit は第2巻で扱います)。
fanclub-api への適用
DB マイグレーション Job
members テーブル自体は第9回の初期化(initdb)で作成済みです。ここではその後のスキーマ/データ移行を Job で実演します。移行は冪等(何度実行しても同じ結果)にするのが鉄則です。今回は「列の追加(ADD COLUMN IF NOT EXISTS)」と「シードデータ投入(ON CONFLICT DO NOTHING)」を行います。DB 接続情報は第10回で作った ConfigMap / Secret を envFrom で再利用します(設定外部化の恩恵)。
次のマニフェストを developer のホームに fanclub-db-migrate.yaml として作成します(一般ユーザー所有のファイルで、kubectl apply はクラスタへ送るだけなので root 権限は不要です)。マイグレーションは postgres:18 イメージの psql で実行します。
apiVersion: batch/v1
kind: Job
metadata:
name: fanclub-db-migrate
spec:
backoffLimit: 3
ttlSecondsAfterFinished: 300
template:
spec:
restartPolicy: Never
containers:
- name: migrate
image: postgres:18
envFrom:
- configMapRef:
name: fanclub-config
- secretRef:
name: fanclub-db-secret
command:
- sh
- -c
- |
set -e
echo "migration start"
PGPASSWORD="$DB_PASSWORD" psql -h "$DB_HOST" -U "$DB_USER" -d "$DB_NAME" -v ON_ERROR_STOP=1 \
-c "ALTER TABLE members ADD COLUMN IF NOT EXISTS updated_at TIMESTAMP" \
-c "INSERT INTO members (name,email,plan) VALUES ('鈴木花子','hanako@example.com','standard'),('佐藤一郎','ichiro@example.com','free') ON CONFLICT (email) DO NOTHING"
echo "migration done"restartPolicy: Never:失敗時は新しい Pod でリトライ(backoffLimit: 3まで)。ttlSecondsAfterFinished: 300:完了 5 分後に Job を自動削除。envFromで第10回のfanclub-config/fanclub-db-secretを再利用し、psqlに$DB_HOST等を渡します。
実行コマンド:
$ kubectl apply -f fanclub-db-migrate.yaml
$ kubectl get job fanclub-db-migrate
$ kubectl logs job/fanclub-db-migrate実行結果(例):Job が Complete になり、ログに INSERT 0 2(2 件追加)が出ます。
NAME STATUS COMPLETIONS DURATION AGE
fanclub-db-migrate Complete 1/1 3s 4s
migration start
ALTER TABLE
INSERT 0 2
migration done冪等性を確認します。Job をいったん削除して同じものを再適用すると、ADD COLUMN IF NOT EXISTS と ON CONFLICT DO NOTHING により、追加は INSERT 0 0(0 件)になり、会員数は増えません。完了 Job は ttlSecondsAfterFinished: 300 で 5 分後に自動削除されるため、すでに消えている場合に備えて削除には --ignore-not-found を付けます。
実行コマンド:
$ kubectl delete job fanclub-db-migrate --ignore-not-found
$ kubectl apply -f fanclub-db-migrate.yaml
$ kubectl logs job/fanclub-db-migrate | grep INSERT実行結果(例):
INSERT 0 0シードされた会員はブラウザ / API からも見えます。/api/members に 3 件(山田太郎・鈴木花子・佐藤一郎)が並びます。
実行コマンド:
$ kubectl run c1 --rm -i --restart=Never --image=curlimages/curl:latest -- \
curl -s http://fanclub-backend:8080/api/members実行結果(例・実際は 1 行で返りますが読みやすく改行しています):
[{"createdAt":"2026-06-27T00:04:07.560548","email":"taro@example.com","id":1,"name":"山田太郎","plan":"premium"},
{"createdAt":"2026-06-27T09:47:02.547117","email":"hanako@example.com","id":2,"name":"鈴木花子","plan":"standard"},
{"createdAt":"2026-06-27T09:47:02.547117","email":"ichiro@example.com","id":3,"name":"佐藤一郎","plan":"free"}]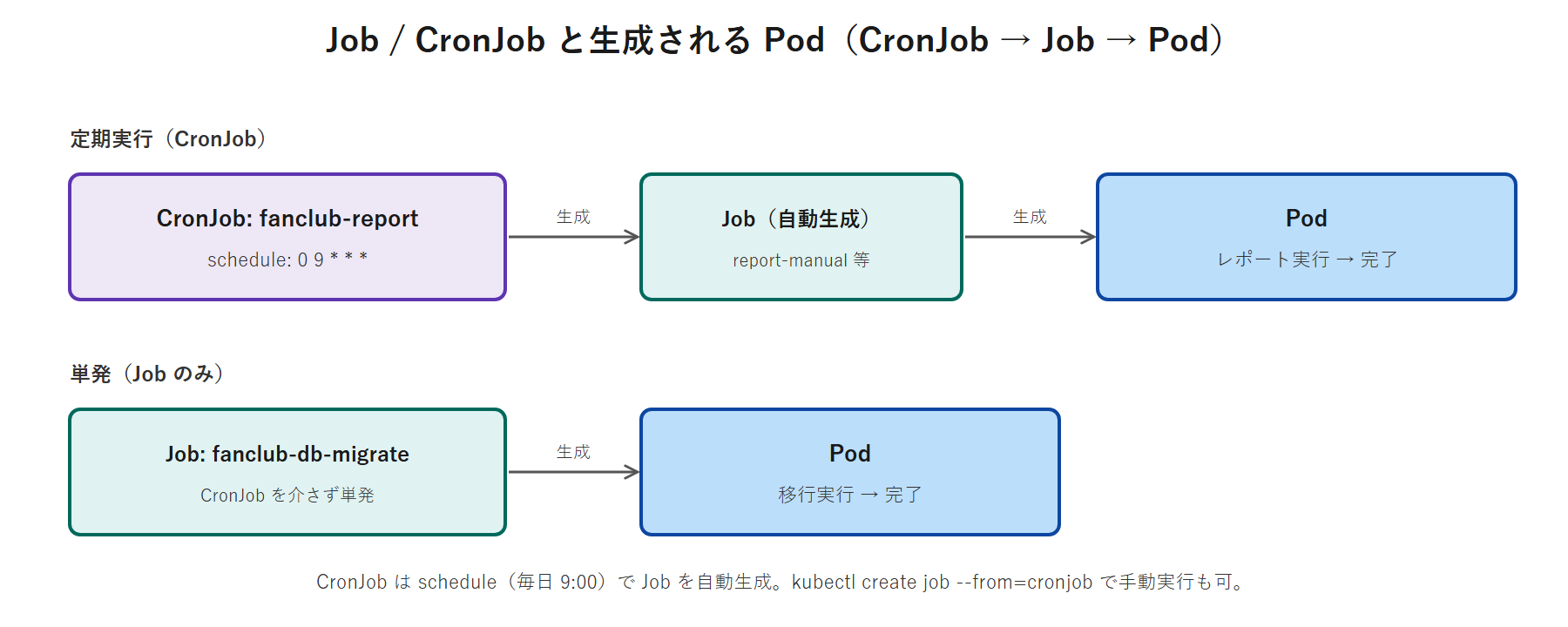
会員サマリーレポート CronJob
毎朝 9:00 にプラン別の会員数を集計する CronJob を作ります。次を developer のホームに fanclub-report.yaml として作成します(一般ユーザー所有・root 不要)。
apiVersion: batch/v1
kind: CronJob
metadata:
name: fanclub-report
spec:
schedule: "0 9 * * *"
concurrencyPolicy: Forbid
jobTemplate:
spec:
backoffLimit: 2
ttlSecondsAfterFinished: 300
template:
spec:
restartPolicy: OnFailure
containers:
- name: report
image: postgres:18
envFrom:
- configMapRef:
name: fanclub-config
- secretRef:
name: fanclub-db-secret
command:
- sh
- -c
- |
echo "=== 会員サマリーレポート ==="
PGPASSWORD="$DB_PASSWORD" psql -h "$DB_HOST" -U "$DB_USER" -d "$DB_NAME" \
-c "SELECT plan, count(*) AS members FROM members GROUP BY plan ORDER BY plan"9:00 を待たずに動作確認するため、CronJob から手動で Job を作って実行します。実行コマンド:
$ kubectl apply -f fanclub-report.yaml
$ kubectl get cronjob fanclub-report
$ kubectl create job report-manual --from=cronjob/fanclub-report
$ kubectl logs job/report-manual実行結果(例):プラン別の集計が出力されます。
=== 会員サマリーレポート ===
plan | members
----------+---------
free | 1
premium | 1
standard | 1
(3 rows)ログコレクタ DaemonSet(模擬)
各ノードに 1 つ配置するログコレクタを busybox で模擬します。次を developer のホームに fanclub-logcollector.yaml として作成します(一般ユーザー所有・root 不要)。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fanclub-logcollector
spec:
selector:
matchLabels:
app: fanclub-logcollector
template:
metadata:
labels:
app: fanclub-logcollector
spec:
containers:
- name: logcollector
image: busybox:1.37
command:
- sh
- -c
- 'echo "log collector started on $(hostname)"; while true; do sleep 3600; done'
resources:
requests:
memory: "16Mi"
cpu: "10m"
limits:
memory: "64Mi"
cpu: "50m"実行コマンド:
$ kubectl apply -f fanclub-logcollector.yaml
$ kubectl get daemonset fanclub-logcollector
$ kubectl get pods -l app=fanclub-logcollector -o wide実行結果(例):単一ノードの kind では DESIRED=1 で 1 Pod が配置されます。
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fanclub-logcollector 1 1 1 1 1 <none> 60s
NAME READY STATUS RESTARTS AGE IP NODE
fanclub-logcollector-vqstz 1/1 Running 0 60s 10.244.82.3 kind-control-planeやってみよう
fanclub-db-migrate.yaml(Job)を作成・適用し、CompleteとログのINSERT 0 2を確認する。- Job を削除して再適用し、
INSERT 0 0(冪等)と会員数が増えないことを確認する。 fanclub-report.yaml(CronJob)を作成し、kubectl create job --from=cronjob/fanclub-reportで手動実行してプラン別集計を確認する。fanclub-logcollector.yaml(DaemonSet)を作成し、ノードごとに 1 Pod 配置されることを確認する。kubectl get job,cronjob,daemonsetで 3 種のワークロードが揃ったことを確認する。
理解度チェック
次の各文が正しいか(○)誤りか(×)を判断してください。解答は下にまとめています。
- Job は処理を完了させるワークロードで、完了後に Pod を再起動し続けない。
- Job の
restartPolicyにはAlwaysを指定できる。 ttlSecondsAfterFinishedで完了した Job を自動削除できる。- CronJob の
scheduleは cron 式で定期実行のタイミングを指定する。 - CronJob はスケジュールの時刻が来るまで手動では実行できない。
- DaemonSet は対象ノードごとに 1 つの Pod を配置する。
- 第10回で作った ConfigMap / Secret は、Job / CronJob からも
envFromで再利用できる。
解答
- 1. ○:Job は完了したら終了する(Deployment のように再起動し続けない)。
- 2. ×:Job は
NeverかOnFailureのみ。Alwaysは不可。 - 3. ○:完了/失敗 Job を一定秒後に自動削除する。
- 4. ○:
分 時 日 月 曜日の 5 フィールドで指定する。 - 5. ×:
kubectl create job --from=cronjob/...で手動実行できる。 - 6. ○:ノードごとに 1 Pod。kind 単一ノードでは 1 つ。
- 7. ○:
configMapRef/secretRefで同じ設定を再利用できる。
まとめ
本記事では、常駐とは異なるワークロードとして Job(単発)・CronJob(定期)・DaemonSet(全ノード 1 Pod)を学びました。fanclub-api には、冪等な DB マイグレーション Job(backoffLimit / ttlSecondsAfterFinished / restartPolicy: Never)、プラン別集計の CronJob(手動トリガで確認)、ログコレクタ DaemonSet を追加しました。DB 接続情報は第10回の ConfigMap / Secret を envFrom でそのまま再利用でき、設定外部化の効果も確認できました。これで第 3 部「アプリリソース」は完了です。
次回予告
次回(第12回)から第 4 部「ワークロード戦略」に入ります。Backend を Deployment 化し、3 種の Probe(liveness / readiness / startup)とローリングアップデート、Probe のデバッグを学びます。
シリーズ一覧
第1部:コンテナと Docker
- 第1回 コンテナ技術概念 + Docker 環境準備
- 第2回 Docker 基本操作
- 第3回 Dockerfile + マルチステージ + JDK 25 / Payara Micro イメージビルド
- 第4回 コンテナレジストリ + イメージタグ戦略 + Trivy スキャン
第2部:Kubernetes 基礎
第3部:アプリリソース
- 第7回 Pod + Multi-container パターン
- 第8回 Service とネットワーキング
- 第9回 ストレージ(PVC + StatefulSet)+ PostgreSQL DB 追加
- 第10回 ConfigMap + Secret + ServiceAccount 基礎
- 第11回 Job + CronJob + DaemonSet ← 今ここ
第4部:ワークロード戦略
- 第12回 Deployment + 3 Probe + Rolling Update + Probe デバッグ実践
- 第13回 Deployment 戦略補完(Blue/Green + Canary + Recreate)
- 第14回 ResourceQuota + LimitRange + Multi-tenant Namespace
