
新卒インフラエンジニア向け「Kubernetes 実践教科書① CKAD アプリケーション開発編」の第13回です。第12回では Backend を Deployment 化し、ローリングアップデートで無停止更新を体験しました。今回はローリング以外のデプロイ戦略——Recreate・Blue/Green・Canary——を実装し、ダウンタイム・リソース・ロールバック速度のトレードオフを手を動かして比べます。
動作確認バージョン:kind v0.31.0(K8s v1.35.0)/ kubectl v1.35.6 / fanclub-backend:0.3.0 ・ 0.3.1 / busybox:1.37 / postgres:18(2026-06-28 実機検証時点)
今ここマップ(全 19 回中の現在地)
現在地は第 4 部「ワークロード戦略」の第 13 回です。第12回のローリングアップデートに続き、デプロイ戦略の引き出しを増やします。
- 第 1 部 コンテナと Docker(第 1〜4 回)
- 第 2 部 Kubernetes 基礎(第 5〜6 回)
- 第 3 部 アプリリソース(第 7〜11 回)
- 第 4 部 ワークロード戦略(第 12〜14 回)← 今ここ
- 第 5 部 セキュリティ基礎(第 15〜16 回)
- 第 6 部 パッケージ管理と HTTPS 公開(第 17〜19 回)
この回のゴール
- Recreate / Blue/Green / Canary を実装し、3 戦略の動きを説明できる。
- 各戦略のトレードオフ(ダウンタイム / リソース消費 / ロールバック速度)を比較できる。
kubectl patchで Service のセレクタを切り替え、レプリカ比でトラフィック割合を調整できる。
デプロイ戦略の全体像
Deployment の更新方法は strategy だけではありません。Service のセレクタやレプリカ比を組み合わせると、目的に応じた切り替え方ができます。代表的な 4 つを押さえます。
- RollingUpdate(第12回):少しずつ入れ替える既定戦略。無停止だが、更新中は新旧が混在する。
- Recreate:旧 Pod を全部消してから新 Pod を起動する。ダウンタイムが出るが、新旧を混在させたくないとき(破壊的なスキーマ変更など)に使う。
- Blue/Green:旧版(Blue)と新版(Green)を2 つ並べておき、Service のセレクタを一気に切り替える。切り戻しもセレクタを戻すだけで速い。
- Canary:新版を少数だけ混ぜ、レプリカ比でトラフィックの一部を新版へ流して様子を見る。
本シリーズの学習環境(kind 単一ノード・CPU 2 コア)では Pod を何十個も並べられません。そこで本回はレプリカ数を小さくし、各 Deployment の requests.cpu を一時的に 100m に下げて複数戦略を同居させます(本番の値や大規模なレプリカ比は概念として補足します)。デモが終わったら最後に本番相当へ戻します。
版を見分ける準備:0.3.1 をビルドする
Blue/Green や Canary では「いまどの版が応答したか」を確かめたくなります。現在の Backend(0.3.0)には版を返す口がないので、バージョンを返す GET /api/version を足した 0.3.1 を作ります。第3回で用意したソース一式は developer のホーム ~/fanclub-api(一般ユーザー所有)にあります。次のファイルを ~/fanclub-api/src/main/java/com/example/fanclub/VersionResource.java として追加します。
package com.example.fanclub;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import java.util.Map;
@Path("/version")
@Produces(MediaType.APPLICATION_JSON)
public class VersionResource {
@GET
public Response version() {
String v = System.getenv().getOrDefault("APP_VERSION", "0.3.1");
return Response.ok(Map.of("version", v)).build();
}
}ベースパスは第3回の AppConfig で /api に固定済みなので、このクラスは GET /api/version として公開されます。環境変数 APP_VERSION があればそれを、なければ既定の 0.3.1 を返します。イメージをビルドして登録レジストリへ push します。実行コマンド:
$ cd ~/fanclub-api
$ docker build -t k8s-registry:5000/fanclub-backend:0.3.1 .
$ docker push k8s-registry:5000/fanclub-backend:0.3.1実行結果(例):依存はキャッシュ済みなので短時間で完了します。
0.3.1: digest: sha256:caf2cc59... size: 856これで 0.3.0(版を返さない=/api/version は 404)と 0.3.1(200 で版を返す)の 2 つが揃いました。コード変更を伴うので 0.3.0 → 0.3.1 とタグを上げます(中身が変わらない回はタグを据え置く方針でした)。この差で「どちらの版に届いたか」を判別します。
Recreate 戦略(ダウンタイムを体験する)
まずは Recreate です。本番の fanclub-backend を止めないよう、使い捨ての別 Deployment(ラベル app: fanclub-backend-rc・Service には載せない)で挙動だけ観察します。ここは「全入れ替えでダウンタイムが出る」点だけを見たいので、Init Container・Sidecar・liveness/startup は省いた最小構成にしています(本番の fanclub-backend は第12回のフル構成のままで、この後の Blue/Green 以降では継承します)。次を recreate-demo.yaml として作成します(developer 所有・root 不要)。
apiVersion: apps/v1
kind: Deployment
metadata:
name: fanclub-backend-recreate
labels:
app: fanclub-backend-rc
spec:
replicas: 2
strategy:
type: Recreate
selector:
matchLabels:
app: fanclub-backend-rc
template:
metadata:
labels:
app: fanclub-backend-rc
spec:
serviceAccountName: fanclub-backend
automountServiceAccountToken: false
containers:
- name: backend
image: k8s-registry:5000/fanclub-backend:0.3.0
ports:
- containerPort: 8080
envFrom:
- configMapRef:
name: fanclub-config
- secretRef:
name: fanclub-db-secret
readinessProbe:
httpGet:
path: /health/ready
port: 8080
periodSeconds: 10
failureThreshold: 3
resources:
requests:
memory: "480Mi"
cpu: "100m"
limits:
memory: "640Mi"
cpu: "600m"適用して Ready を待ち、その後 0.3.1 へ更新します。実行コマンド:
$ kubectl apply -f recreate-demo.yaml
$ kubectl rollout status deployment/fanclub-backend-recreate
$ kubectl set image deployment/fanclub-backend-recreate backend=k8s-registry:5000/fanclub-backend:0.3.1
$ kubectl get deployment fanclub-backend-recreate -w実行結果(例):更新の瞬間、READY が一度 0 になり(旧 2 Pod を全終了 → 新 Pod の起動完了を待つ)、しばらくして 2 に戻ります。この「全部落ちてから立ち上がる」間がダウンタイムです(-w は Ctrl-C で抜けます)。
NAME READY UP-TO-DATE AVAILABLE
fanclub-backend-recreate 2/2 2 2
fanclub-backend-recreate 0/2 2 0
fanclub-backend-recreate 0/2 2 0
fanclub-backend-recreate 2/2 2 2確認できたら片付けます。実行コマンド:
$ kubectl delete -f recreate-demo.yamlBlue/Green デプロイ
Blue/Green は、旧版(Blue=0.3.0)と新版(Green=0.3.1)を2 本同時に立てておき、Service のセレクタを Blue から Green へ一気に向け替える方式です。第12回の fanclub-backend Deployment を、Blue と Green の 2 本に作り替えます。まず Blue を developer のホームに fanclub-backend-blue.yaml として作成します(一般ユーザー所有・root 不要。以降の green / stable / canary もこのファイルをコピーして作るので、すべて同じ ~/ 配下に置きます)。第12回の構成(Init Container・Sidecar・3 Probe・applog ボリューム)をそのまま引き継ぎ、ラベルに track: blue を足し、requests.cpu だけ 100m に下げています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: fanclub-backend-blue
labels:
app: fanclub-backend
track: blue
spec:
replicas: 1
selector:
matchLabels:
app: fanclub-backend
track: blue
template:
metadata:
labels:
app: fanclub-backend
track: blue
spec:
serviceAccountName: fanclub-backend
automountServiceAccountToken: false
initContainers:
- name: wait-for-db
image: busybox:1.37
command:
- sh
- -c
- 'until nslookup fanclub-db.default.svc.cluster.local >/dev/null 2>&1; do echo "waiting for fanclub-db..."; sleep 2; done; echo "fanclub-db resolved"'
- name: log-shipper
image: busybox:1.37
restartPolicy: Always
command:
- sh
- -c
- 'echo "sidecar started"; tail -F /var/log/app/app.log 2>/dev/null || sleep infinity'
volumeMounts:
- name: applog
mountPath: /var/log/app
containers:
- name: backend
image: k8s-registry:5000/fanclub-backend:0.3.0
ports:
- containerPort: 8080
envFrom:
- configMapRef:
name: fanclub-config
- secretRef:
name: fanclub-db-secret
startupProbe:
httpGet:
path: /health/started
port: 8080
failureThreshold: 30
periodSeconds: 10
livenessProbe:
httpGet:
path: /health/live
port: 8080
periodSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /health/ready
port: 8080
periodSeconds: 10
failureThreshold: 3
resources:
requests:
memory: "512Mi"
cpu: "100m"
limits:
memory: "768Mi"
cpu: "1000m"
volumeMounts:
- name: applog
mountPath: /var/log/app
volumes:
- name: applog
emptyDir: {}Green は Blue をコピーして、名前・track・イメージだけ変えれば作れます。実行コマンド:
$ cp fanclub-backend-blue.yaml fanclub-backend-green.yaml
$ sed -i 's/-blue/-green/; s/track: blue/track: green/; s|fanclub-backend:0.3.0|fanclub-backend:0.3.1|' fanclub-backend-green.yaml第12回の fanclub-backend Deployment を削除し、Blue と Green を適用します(Service fanclub-backend 自体は第8回のものをそのまま使い、セレクタだけ切り替えます)。実行コマンド:
$ kubectl delete deployment fanclub-backend
$ kubectl apply -f fanclub-backend-blue.yaml
$ kubectl apply -f fanclub-backend-green.yaml
$ kubectl wait --for=condition=available deployment/fanclub-backend-blue deployment/fanclub-backend-green --timeout=180sService のセレクタを track: blue に向けます。実行コマンド:
$ kubectl patch service fanclub-backend -p '{"spec":{"selector":{"app":"fanclub-backend","track":"blue"}}}'
$ kubectl run c --rm -i --restart=Never --image=curlimages/curl:latest -- \
curl -s -o /dev/null -w "version=%{http_code}\n" http://fanclub-backend:8080/api/version実行結果(例):Blue(0.3.0)は /api/version を持たないので 404 です。
version=404セレクタを track: green に切り替えます。track は同じキーの値を上書きするだけなので、この patch で即時に向き先が変わります。実行コマンド:
$ kubectl patch service fanclub-backend -p '{"spec":{"selector":{"app":"fanclub-backend","track":"green"}}}'
$ kubectl run c --rm -i --restart=Never --image=curlimages/curl:latest -- \
curl -s http://fanclub-backend:8080/api/version実行結果(例):Green(0.3.1)に切り替わり、版が返ります。CRUD も問題なく動きます。
{"version":"0.3.1"}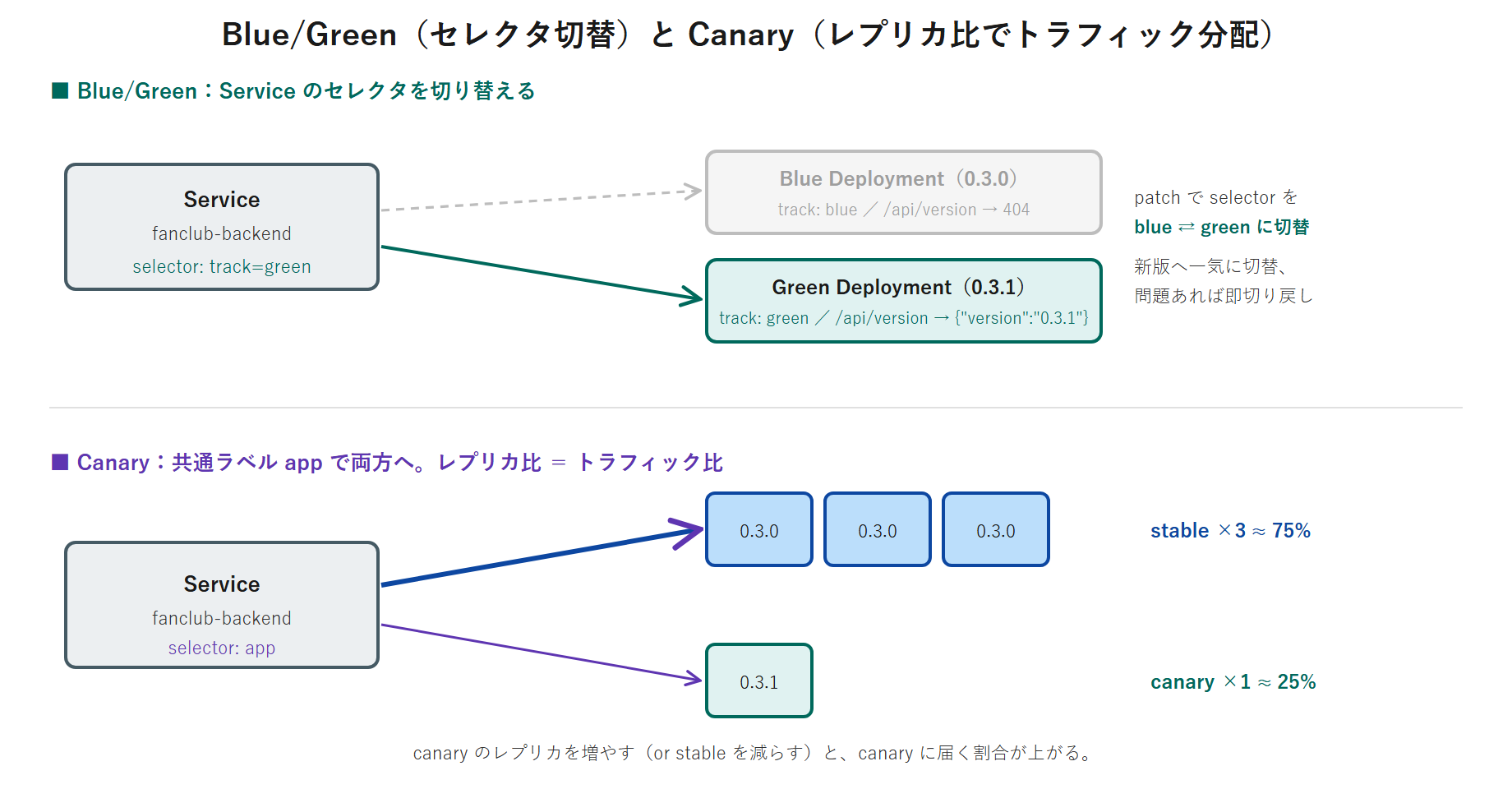
切り戻しはセレクタを blue に戻すだけです。Green に不具合が見つかってもすぐ戻せます。実行コマンド:
$ kubectl patch service fanclub-backend -p '{"spec":{"selector":{"app":"fanclub-backend","track":"blue"}}}'Blue/Green は「新旧を丸ごと用意して一気に切り替える」ぶん、切替・切り戻しが速い反面、2 版分のリソースを同時に使うのが弱点です。確認できたら次の Canary に進むため、Blue と Green を削除します。実行コマンド:
$ kubectl delete deployment fanclub-backend-blue fanclub-backend-greenCanary リリース
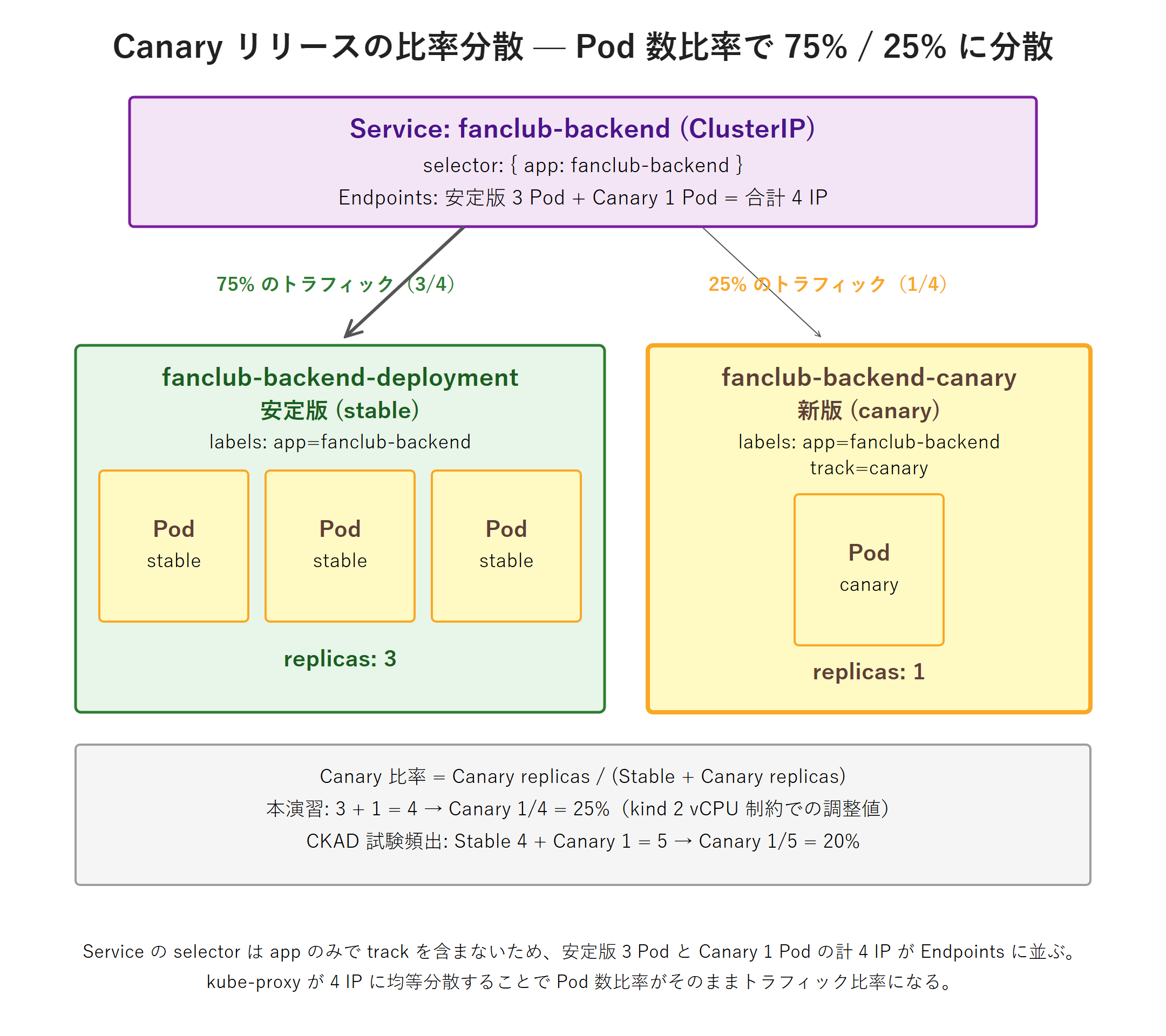
Canary は、安定版(stable)を多めに、新版(canary)を少しだけ並べ、両方を同じ Service の配下に入れて一部のトラフィックを新版へ流す方式です。振り分けは特別な機能ではなく、Ready な Pod 数の比で決まります(kube-proxy が各 Pod へほぼ均等に分配)。共通ラベル app: fanclub-backend を両者に付け、識別用に track: stable / track: canary を足します。
stable は Blue(0.3.0)を、canary は Green(0.3.1)をコピーして作ります。実行コマンド:
$ cp fanclub-backend-blue.yaml fanclub-backend-stable.yaml
$ sed -i 's/-blue/-stable/; s/track: blue/track: stable/; s/replicas: 1/replicas: 3/' fanclub-backend-stable.yaml
$ cp fanclub-backend-green.yaml fanclub-backend-canary.yaml
$ sed -i 's/-green/-canary/; s/track: green/track: canary/' fanclub-backend-canary.yaml
$ kubectl apply -f fanclub-backend-stable.yaml
$ kubectl apply -f fanclub-backend-canary.yaml
$ kubectl wait --for=condition=available deployment/fanclub-backend-stable deployment/fanclub-backend-canary --timeout=200sService のセレクタを app: fanclub-backend だけに広げ、stable・canary の両方へ届くようにします。ここで注意点があります。直前の Blue/Green で track: blue が残っているので、単純に app を指定するだけでは track が消えません(kubectl patch の既定はキーをマージするため)。不要になった track は null で明示的に外します。実行コマンド:
$ kubectl patch service fanclub-backend --type=merge \
-p '{"spec":{"selector":{"app":"fanclub-backend","track":null}}}'
$ kubectl get service fanclub-backend -o jsonpath='{.spec.selector}{"\n"}'実行結果(例):セレクタが app だけになりました。
{"app":"fanclub-backend"}Service の宛先(エンドポイント)に stable 3 + canary 1 の計 4 Pod が並んでいるかを確認します。kubectl get endpoints は v1.33 以降で非推奨になったため、EndpointSlice を見ます。実行コマンド:
$ kubectl get endpointslices -l kubernetes.io/service-name=fanclub-backend実行結果(例):宛先は計 4 つ(stable 3 + canary 1)です。ENDPOINTS 列は 3 つまで表示され、残りは + N more... と省略されます。
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
fanclub-backend-abcde IPv4 8080 10.244.82.54,10.244.82.55,10.244.82.56 + 1 more... 60s計測用の Pod を 1 つ立て、その中から /api/version を 40 回叩いて版ごとの応答数を数えます。0.3.1(canary)は版を返し、0.3.0(stable)は 404 になるので、その数でトラフィック割合がわかります(default の Service はセッションアフィニティが無く、接続ごとに分散します)。実行コマンド:
$ kubectl run loadtest --rm -i --restart=Never --image=curlimages/curl:latest --quiet -- \
sh -c 'for i in $(seq 1 40); do curl -s -o /dev/null -w "%{http_code}\n" http://fanclub-backend:8080/api/version; done' | sort | uniq -c実行結果(例):4 Pod 中 1 つが canary なので、おおむね 4 分の 1(約 25%)が 200(canary=0.3.1)に届きます。試行回数が少ないと割合はぶれます。
10 200
30 404※上の例では 200 が canary、404 が stable です(200 の本文が {"version":"0.3.1"})。canary を増やしたい(割合を上げたい)ときは canary のレプリカを増やすか、stable を減らします。たとえば stable を 2 に減らすと canary の比率は約 33% に上がります。実行コマンド:
$ kubectl scale deployment fanclub-backend-stable --replicas=2このように レプリカ比 = おおよそのトラフィック比です。本番では数十レプリカで「10% → 30% → 100%」と段階的に広げますが、本シリーズの 2 コアノードでは Pod 数に上限があるため、ここでは小さな比率で原理を確認しています。
戦略の使い分け
- RollingUpdate:通常はこれで十分。無停止で、追加リソースも少ない(第12回)。
- Recreate:新旧を混ぜられない更新(破壊的なスキーマ変更など)。ダウンタイムを許容できるときだけ。
- Blue/Green:切替・切り戻しの速さが要るとき。2 版分のリソースを使える前提。
- Canary:新版を少しずつ試して様子を見たいとき。観測(メトリクス)と組み合わせると効果的。
本番では、Blue/Green や Canary を自動化する Argo Rollouts のようなツールがよく使われます(重み付けや自動解析つきの段階リリースができます)。本巻では概念紹介にとどめ、ここまでに学んだ「Deployment・Service・セレクタ・ラベル」の組み合わせで戦略の土台を理解しておきます。
後片付けと統合
検証が済んだので、新版 0.3.1 を正式採用し、第12回と同じ形の単一 fanclub-backend Deployment に戻します(学習用に下げていた requests.cpu も本番相当の 250m へ戻します)。第12回で作った backend-deploy.yaml のイメージを 0.3.1 に書き換えて再適用すれば、自己回復・3 Probe・Init/Sidecar はそのまま、版だけ上がった状態になります。実行コマンド:
$ kubectl delete deployment fanclub-backend-stable fanclub-backend-canary
$ sed -i 's|fanclub-backend:0.3.0|fanclub-backend:0.3.1|' backend-deploy.yaml
$ kubectl apply -f backend-deploy.yaml
$ kubectl patch service fanclub-backend --type=merge \
-p '{"spec":{"selector":{"app":"fanclub-backend","track":null}}}'
$ kubectl rollout status deployment/fanclub-backend最後に、単一 Deployment(2/2)に戻り、版が 0.3.1・CRUD も動くことを確認します。実行コマンド:
$ kubectl get deployment fanclub-backend
$ kubectl run c --rm -i --restart=Never --image=curlimages/curl:latest -- \
curl -s http://fanclub-backend:8080/api/version
$ kubectl run c --rm -i --restart=Never --image=curlimages/curl:latest -- \
curl -s -o /dev/null -w "members=%{http_code}\n" http://fanclub-backend:8080/api/members実行結果(例):
NAME READY UP-TO-DATE AVAILABLE
fanclub-backend 1/1 1 1
{"version":"0.3.1"}
members=200これで Backend は第12回と同じ構成のまま、版だけ 0.3.1 に進みました。会員データ(第9・11回で入れた 3 件)も PVC に残ったままです。
やってみよう
VersionResource.javaを追加して0.3.1をビルド・push し、0.3.0(404)と0.3.1(版を返す)の差を作る。- Recreate の Deployment を更新し、
READYが一度0になる(ダウンタイム)ことを-wで観察する。 - Blue(0.3.0)/ Green(0.3.1)を立て、Service セレクタを
track: blue → greenに切り替えて応答が404 → {"version":"0.3.1"}に変わることを確認し、blueに切り戻す。 - stable(3)+ canary(1)を共通ラベルで並べ、セレクタを
track: nullでappだけに広げ、/api/versionを 40 回叩いて canary の割合(約 25%)を数える。 backend-deploy.yamlを0.3.1にして単一fanclub-backendへ統合し、戦略用 Deployment を片付ける。
理解度チェック
次の各文が正しいか(○)誤りか(×)を判断してください。解答は下にまとめています。
- Recreate は旧 Pod を全て終了してから新 Pod を起動するため、更新中にダウンタイムが発生する。
- Blue/Green では Service のセレクタを切り替えることで新版へ一気に向き先を変えられる。
- Blue/Green のロールバックは、セレクタを旧版(blue)に戻すだけでよい。
- Canary のトラフィック割合は、Service の
weightフィールドに割合を書いて指定する。 - Canary では、新版(canary)のレプリカを増やすほど新版へ届くトラフィックの割合が増える。
kubectl get endpointsは v1.35 でも推奨される宛先確認コマンドである。- Service のセレクタを
kubectl patchでマージするとき、不要になったラベルキーは自動的に消える。 - Recreate は本番の無停止リリースに最も適した戦略である。
解答
- 1. ○:全終了 → 起動の間が空くためダウンタイムが出る。
- 2. ○:セレクタの向き先を blue → green に変えるだけで切り替わる。
- 3. ○:セレクタを blue に戻せば即座に切り戻せる。
- 4. ×:標準 Service に
weightはない。割合はレプリカ比で決まる(重み付けは Gateway API や Argo Rollouts の領域)。 - 5. ○:レプリカ比 = おおよそのトラフィック比。
- 6. ×:
kubectl get endpointsは v1.33+ で非推奨。kubectl get endpointslicesを使う。 - 7. ×:マージでは消えない。
track: nullのように明示して外す。 - 8. ×:Recreate はダウンタイムを伴う。無停止なら RollingUpdate / Blue/Green。
まとめ
本記事では、ローリング以外の 3 つのデプロイ戦略を実装しました。Recreate は全入れ替えでダウンタイムを伴い、Blue/Green は 2 版を並べてセレクタで一気に切替・切り戻し、Canary は共通ラベルとレプリカ比で一部トラフィックを新版へ流します。版の判別には 0.3.1 で足した /api/version を使い、最後は第12回と同じ形の単一 fanclub-backend(版だけ 0.3.1)へ統合しました。戦略の正体は、これまで学んだ Deployment・Service・ラベル・セレクタの組み合わせです。
次回予告
次回(第14回)は、Namespace で環境を分け、ResourceQuota と LimitRange で「Namespace 全体の上限」「Pod 既定値」を制御します。今回 CPU で苦労した「リソースの取り合い」を、ルールで管理する回です。
シリーズ一覧
第1部:コンテナと Docker
- 第1回 コンテナ技術概念 + Docker 環境準備
- 第2回 Docker 基本操作
- 第3回 Dockerfile + マルチステージ + JDK 25 / Payara Micro イメージビルド
- 第4回 コンテナレジストリ + イメージタグ戦略 + Trivy スキャン
第2部:Kubernetes 基礎
第3部:アプリリソース
- 第7回 Pod + Multi-container パターン
- 第8回 Service とネットワーキング
- 第9回 ストレージ(PVC + StatefulSet)+ PostgreSQL DB 追加
- 第10回 ConfigMap + Secret + ServiceAccount 基礎
- 第11回 Job + CronJob + DaemonSet
第4部:ワークロード戦略
- 第12回 Deployment + 3 Probe + Rolling Update + Probe デバッグ実践
- 第13回 Deployment 戦略補完(Blue/Green + Canary + Recreate)← 今ここ
- 第14回 ResourceQuota + LimitRange + Multi-tenant Namespace
