
新卒インフラエンジニア向けLinuC 101 試験対策シリーズの第10回です。前回はパイプの仕組みを扱いました。今回はそのパイプの上に流す3つの主役コマンド ── grep / sed / awk と、これらの土台となる正規表現を学びます。
サーバーで扱うのはほとんどがテキストです。ログ、設定ファイル、コマンド出力 ── これらを目視で追うには量も速度も足りません。本記事の3コマンドと正規表現を組み合わせれば、ログの絞り込み・設定の一括書き換え・列指向の集計が、数十文字のワンライナーで片付きます。
環境前提
- ディストリビューション: AlmaLinux 9.6(Sage Margay)
- シェル: bash 5.1.8
- ユーザー:
developer(sudo NOPASSWD設定済み) - 関連VM:
linuc-alma(10.0.10.132) - 演習用ディレクトリ
~/linuc-text/を作成 → 末尾でクリーンアップ - 題材として
/etc/passwd(読み取り専用)を活用
今ここマップ
LinuC 101 試験対策シリーズ(全12回)
第1回 Linuxの起動・接続・停止
第2回 ブートプロセスの仕組み
第3回 systemdマスター講座
第4回 プロセス管理とハードウェア基礎
第5回 仮想マシンとコンテナの基礎
第6回 パッケージ管理マスター
第7回 ファイル操作の実践
第8回 パーミッション・所有者・特殊権限
第9回 コマンドライン・リダイレクト・パイプ
▶ 第10回 テキスト処理(grep / sed / awk) ← いまここ
第11回 vi/vim 入門
第12回 ディスク・パーティション・ファイルシステムこの記事で身につくこと
grepで-i-v-n-c-r-l-E-Fを使い分けられるsedで置換(s/pat/rep/g)・削除(/pat/d)・抽出(-n '/pat/p')ができるawkで列参照($1$NF)・組み込み変数(NRNF)・BEGIN/ENDブロックが使えるsort/uniq/cut/tr/head/tail/wcをパイプで組み合わせられる- BRE(基本正規表現)と ERE(拡張正規表現)の文法と違いを説明できる
第1章:なぜテキスト処理を学ぶのか
Linux の運用で扱うデータは、ほぼすべてテキストです。/var/log 配下のログ、/etc 配下の設定、ps や journalctl の出力 ── どれも改行区切りのテキストです。
10万行のログから「直近1時間で発生したエラーだけ」を抜き出す、500個のサーバーで設定ファイルの1行を一括変更する、アクセスログから接続元IPの上位10件を集計する ── どれもエディタで開いて目で追うのは現実的ではありません。これらをパイプとテキスト処理コマンドの組み合わせで片付けるのが Linux 流の作法です。
役割分担
| コマンド | 役割 | 典型用途 |
|---|---|---|
grep | 行のフィルタ(マッチした行を残す/捨てる) | 「ERROR を含む行だけ抽出」 |
sed | ストリームエディタ(置換・削除・抽出) | 「全行の foo を bar に置換」 |
awk | 列指向プログラミング言語 | 「3列目が 1000 以上の行の1列目」 |
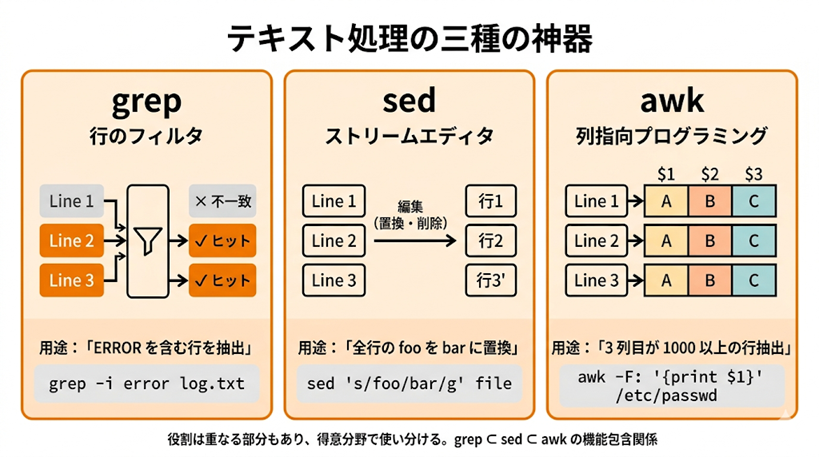
3つは役割が重なる部分もありますが、得意分野が異なります。同じことを複数のツールでやれることが多いので、最初は無理に使い分けようとせず、得意な道具で書けば十分です。
第2章:grep ── 行のフィルタ
まず作業ディレクトリとサンプルログを準備します。linuc-almaで実行:
$ rm -rf ~/linuc-text
$ mkdir -p ~/linuc-text
$ cat > ~/linuc-text/sample.log <<'EOF'
2026-05-10 08:00:01 INFO Service started
2026-05-10 08:01:15 ERROR Connection refused
2026-05-10 08:02:33 WARN Slow query detected
2026-05-10 08:03:47 INFO Health check OK
2026-05-10 08:05:22 ERROR Disk full
EOF<<'EOF' はヒアドキュメント。'EOF' をクォートしているので変数展開せず、改行を含む複数行をそのままファイルに書き込めます。
2.1 基本の使い方
linuc-almaで実行:
$ grep ERROR ~/linuc-text/sample.log実行結果:
2026-05-10 08:01:15 ERROR Connection refused
2026-05-10 08:05:22 ERROR Disk fullgrep PATTERN FILE で、ファイル内の各行のうち PATTERN を含む行だけ表示。標準入力から受け取ることもでき、cat file | grep pat がパイプの王道です。
2.2 主要オプション
| オプション | 意味 | 典型用途 |
|---|---|---|
-i | 大文字小文字を無視 | 「ERROR でも error でも拾う」 |
-v | 反転(マッチしない行) | コメント行除外(grep -v '^#') |
-n | 行番号付き表示 | ファイルのどこにあるか把握 |
-c | マッチ件数のみ | 「ERROR が何件あったか」 |
-r | ディレクトリを再帰的に | 「src/ 配下から TODO を探す」 |
-l | マッチしたファイル名のみ | 「どのファイルに含まれているか」 |
-A N / -B N / -C N | マッチ行の前後 N 行も表示 | エラーの前後文脈を見る |
-w | 単語境界マッチ | 「foo が foobar にヒットしないように」 |
-E | 拡張正規表現(ERE) | + ? \| () をそのまま使う |
-F | 固定文字列(正規表現を使わない) | 「a.b.c をリテラルで検索」 |
linuc-almaで実行:
$ grep -i error ~/linuc-text/sample.log
$ grep -v INFO ~/linuc-text/sample.log
$ grep -n ERROR ~/linuc-text/sample.log
$ grep -c ERROR ~/linuc-text/sample.log実行結果(-n と -c の例):
# grep -n ERROR の出力
2:2026-05-10 08:01:15 ERROR Connection refused
5:2026-05-10 08:05:22 ERROR Disk full
# grep -c ERROR の出力
22.3 OR 検索(ERE)
「ERROR または WARN を含む行」のような OR 検索は、拡張正規表現の | を使います。grep -E(または egrep)を指定。
linuc-almaで実行:
$ grep -E 'ERROR|WARN' ~/linuc-text/sample.log実行結果:
2026-05-10 08:01:15 ERROR Connection refused
2026-05-10 08:02:33 WARN Slow query detected
2026-05-10 08:05:22 ERROR Disk fullBRE(grep の既定)でも \| でエスケープすれば同じことができますが、ERE の方が読みやすいので OR を含むパターンでは -E 推奨です。
📖 試験Tipsボックス:grep のオプション
主題:1.03.2 + 1.03.4(重要度:高)
出題パターン:「マッチしない行を出すオプションは?」「大文字小文字を無視するのは?」「拡張正規表現を使うコマンドは?」「再帰的にディレクトリを探すには?」
暗記ポイント
-v反転 /-i大小無視 /-n行番号 /-c件数-r再帰 /-lファイル名のみ /-w単語境界-A N後ろN行 /-B N前N行 /-C N前後N行-EERE /-F(またはfgrep)固定文字列- 標準入力にも対応:
cat file | grep pat
第3章:sed ── ストリームエディタ
sed は Stream EDitor の略。標準入力(またはファイル)から行を読み、編集し、標準出力に流します。1ファイルを1パスで処理するのが基本動作です。
3.1 置換 ── s/pat/rep/g
s コマンドが置換。s/古い/新しい/フラグ の形式。フラグ g を付けると行内の全箇所、付けないと各行最初の1個だけ置換します。
linuc-almaで実行:
$ sed 's/ERROR/[ERR]/g' ~/linuc-text/sample.log実行結果:
2026-05-10 08:00:01 INFO Service started
2026-05-10 08:01:15 [ERR] Connection refused
2026-05-10 08:02:33 WARN Slow query detected
2026-05-10 08:03:47 INFO Health check OK
2026-05-10 08:05:22 [ERR] Disk full区切り文字は / 以外も使えます。パスを置換するときは s|/old/path|/new/path|g のように | を区切りにすると、エスケープなしで書けて読みやすくなります。
3.2 行削除と抽出
/pat/d でパターンマッチした行を削除(出力しない)。linuc-almaで実行:
$ sed '/INFO/d' ~/linuc-text/sample.log実行結果:
2026-05-10 08:01:15 ERROR Connection refused
2026-05-10 08:02:33 WARN Slow query detected
2026-05-10 08:05:22 ERROR Disk full抽出は -n(既定の自動出力を抑制)と p(明示出力)の組み合わせ。linuc-almaで実行:
$ sed -n '/ERROR/p' ~/linuc-text/sample.log実行結果:
2026-05-10 08:01:15 ERROR Connection refused
2026-05-10 08:05:22 ERROR Disk full結果は grep ERROR と同じですが、sed は同時に置換や削除も組み合わせられる点で柔軟です。
3.3 行範囲指定
2,4 のように行番号で範囲指定もできます。linuc-almaで実行:
$ sed -n '2,4p' ~/linuc-text/sample.log実行結果:
2026-05-10 08:01:15 ERROR Connection refused
2026-05-10 08:02:33 WARN Slow query detected
2026-05-10 08:03:47 INFO Health check OK$ で最終行を表せます:sed -n '$p' は最終行のみ出力。
3.4 ファイル直接編集 ── -i.bak の作法
-i オプションでファイルを直接書き換えられます。本番ファイルに対しては必ず -i.bak でバックアップを残すのが鉄則です。
linuc-almaで実行:
$ cp ~/linuc-text/sample.log ~/linuc-text/sample2.log
$ sed -i.bak 's/Service/SERVICE/' ~/linuc-text/sample2.log
$ diff ~/linuc-text/sample2.log.bak ~/linuc-text/sample2.log実行結果:
1c1
< 2026-05-10 08:00:01 INFO Service started
---
> 2026-05-10 08:00:01 INFO SERVICE startedsample2.log.bak に元の内容、sample2.log に変更後の内容。diff で差分を確認できます。-i 単独(バックアップなし)は本番では避けてください。第8章で実害事例を扱います。
📖 試験Tipsボックス:sed の主要操作
主題:1.03.2(重要度:高)
出題パターン:「行内すべて置換するフラグは?」「行を削除するコマンドは?」「ファイルを直接編集するオプションは?」
暗記ポイント
s/pat/rep/g全置換(gなしは行内最初のみ)/pat/d行削除-n '/pat/p'抽出(grep 相当)-n '1,5p'行範囲指定-i.bak直接編集(バックアップ付き)/-i単独は本番避ける- 区切り文字は
/以外も使用可:s|old|new|g
第4章:awk ── 列指向の処理
awk は単なるコマンドではなく、小さなプログラミング言語です。「行を読んで、各行を空白で区切り、列単位で処理する」のが基本動作です。
4.1 列の参照 ── $NF
linuc-almaで実行:
$ awk '{print $1, $4}' ~/linuc-text/sample.log実行結果:
2026-05-10 Service
2026-05-10 Connection
2026-05-10 Slow
2026-05-10 Health
2026-05-10 Disk$1 は1列目、$4 は4列目(0始まりではなく1始まり)。$0 は行全体、$NF は最終列を指します。
4.2 区切り文字 ── -F
/etc/passwd はコロン区切り。-F: で区切り文字を指定します。linuc-almaで実行:
$ awk -F: '{print $1, $NF}' /etc/passwd | head -3実行結果:
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin1列目(ユーザー名)と最終列(ログインシェル)が見えます。$NF を使うと「列数が違っても最後の列」を取れて頑強です。
4.3 条件付きアクション
条件式で行を絞り込めます。「UID(3列目)が 1000 以上の行」を抽出してみます。linuc-almaで実行:
$ awk -F: '$3 >= 1000 {print $1, $3}' /etc/passwd実行結果:
nobody 65534
developer 1000UID 1000 以上が「人間ユーザーの目印」(nobody はシステム用の例外で 65534)。AlmaLinux 9 のミニマル構成では developer ひとりだけが実質的な人間ユーザーということがわかります。
4.4 BEGIN / END ブロック
処理の前と後に1回だけ実行するブロックが BEGIN{} と END{}。集計に使います。
linuc-almaで実行:
$ awk -F: 'BEGIN{c=0} $NF == "/bin/bash" {c++} END{print "bash users:", c}' /etc/passwd実行結果:
bash users: 2bash をログインシェルに持つユーザーは 2 人(root と developer)。BEGIN で初期化、本体ブロックで条件マッチした行を数え、END で合計を出力。
4.5 連想配列で集計
awk の連想配列を使うと、グルーピング集計ができます。
linuc-almaで実行:
$ awk -F: '{count[$NF]++} END{for(s in count) print count[s], s}' /etc/passwd | sort -rn実行結果:
14 /sbin/nologin
2 /usr/sbin/nologin
2 /bin/bash
1 /sbin/shutdown
1 /sbin/halt
1 /bin/syncシェル別のユーザー数。nologin(ログイン不可)が大半を占めるのが、現代の Linux サーバーの典型構成です。「サービス用にユーザーを作るが、対話シェルでログインさせない」という運用設計が見えます。
📖 試験Tipsボックス:awk の主要要素
主題:1.03.2(重要度:高)
出題パターン:「区切り文字を指定するオプションは?」「最後のフィールドを参照する書き方は?」「現在の行番号を表す変数は?」
暗記ポイント
-F:区切り文字(既定はスペース・タブ)- 列参照:
$0(全体) /$1(1列目) /$NF(最終列) - 組み込み変数:
NR(現在の行番号) /NF(現在の行のフィールド数) - 条件付きアクション:
'$3 >= 1000 {print $1}' BEGIN{}(処理前1回)/END{}(処理後1回)- 連想配列:
{count[$NF]++}でグルーピング集計
第5章:補助コマンド ── パイプの仲間たち
grep / sed / awk と組み合わせると効果が出る、シンプルな道具たち。
5.1 sort ── 並べ替え
-n数値ソート(既定の文字列比較では10<2になってしまう)-r逆順-k NN 列目で-t:区切り文字(コロン)
linuc-almaで実行:
$ sort -t: -k3 -n /etc/passwd | head -5実行結果:
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologinUID 順に並びました。
5.2 uniq ── 重複除去(事前ソート必須)
uniq は連続する重複行を1つにまとめます。離れて出現する重複は対象外なので、必ず事前に sort“);そろえてから渡すのが定石。-c で件数付き。
linuc-almaで実行:
$ awk -F: '{print $NF}' /etc/passwd | sort | uniq -c実行結果:
2 /bin/bash
1 /bin/sync
1 /sbin/halt
14 /sbin/nologin
1 /sbin/shutdown
2 /usr/sbin/nologin4.5 で awk の連想配列で書いた集計と同じ結果が得られます。同じことを違う道具で書けるのが Unix 流。
5.3 cut ── フィールド切り出し
linuc-almaで実行:
$ cut -d: -f1,3 /etc/passwd | head -5実行結果:
root:0
bin:1
daemon:2
adm:3
lp:4cut は awk '{print $1, $3}' より軽量。フィールドの単純抽出だけなら cut が手早いです。
5.4 tr ── 文字単位の変換
linuc-almaで実行:
$ echo "Hello World 2026" | tr 'a-z' 'A-Z'実行結果:
HELLO WORLD 2026tr -d ' ' でスペース削除、tr -s '\n' で連続改行を1個に圧縮、など使い方が多彩です。
5.5 head / tail / wc / nl
head -N先頭N行 /tail -N末尾N行 /tail -f末尾追従(ログ監視)wc -l行数 /-w単語数 /-cバイト数nl行番号付与(cat -nと類似)
linuc-almaで実行:
$ wc -l ~/linuc-text/sample.log
$ wc -w ~/linuc-text/sample.log実行結果:
5 /home/developer/linuc-text/sample.log
27 /home/developer/linuc-text/sample.log第6章:正規表現 ── BRE と ERE の文法
grep / sed / awk すべてが扱う共通の言語が正規表現(regular expression)です。Linux/UNIX 系のツールが採用するのは大きく分けて2系統。
- BRE(Basic Regular Expression):
grepとsedの既定 - ERE(Extended Regular Expression):
grep -E/egrep/awk
6.1 共通のメタ文字
| メタ文字 | 意味 | 例 |
|---|---|---|
. | 任意の1文字 | a.c → abc a1c など |
* | 直前の0回以上 | ab*c → ac abc abbc |
^ | 行頭 | ^root → 行頭が root |
$ | 行末 | bash$ → 行末が bash |
[abc] | 文字クラス(いずれか1文字) | [abc] → a または b または c |
[^abc] | 否定 | [^abc] → a/b/c 以外 |
[a-z] | 範囲 | [a-z] → 小文字英字 |
6.2 BRE と ERE の差
| 意味 | BRE | ERE |
|---|---|---|
| 1回以上 | \+ | + |
| 0または1回 | \? | ? |
| OR | \| | | |
| グループ化 | \(...\) | (...) |
| n回 | \{n\} | {n} |
覚え方:BRE は古典的でバックスラッシュが必要、ERE は現代的でそのまま書ける。両方を試して結果が同じになることを確認します。
linuc-almaで実行:
$ grep '^[a-z]\+:' /etc/passwd | head -3
$ grep -E '^[a-z]+:' /etc/passwd | head -3実行結果(両方とも同じ):
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin6.3 POSIX 文字クラス
ロケールに依存しない移植性の高い記法。[[:digit:]](数字)、[[:alpha:]](英字)、[[:space:]](空白)など。
linuc-almaで実行:
$ printf 'abc\n123\nxyz789\n' | grep -E '[[:digit:]]+'実行結果:
123
xyz789数字を1個以上含む行のみ抽出。abc は数字を含まないので落ちます。
6.4 実用:電話番号パターン
linuc-almaで実行:
$ echo "Phone: 03-1234-5678" | grep -E '[0-9]+-[0-9]+-[0-9]+'実行結果:
Phone: 03-1234-5678「数字 1個以上 – 数字 1個以上 – 数字 1個以上」のパターン。これに -o をつけるとマッチした部分だけ抜き出せます(03-1234-5678 のみ)。
📖 試験Tipsボックス:BRE と ERE の差
主題:1.03.4(重要度:高)
出題パターン:「+ や ? をバックスラッシュなしで使うには?」「BRE で1回以上を表す書き方は?」
暗記ポイント
- BRE:
grepsed既定 - ERE:
grep -Eegrepawk - 共通:
.*^$[] - BRE で要エスケープ:
\+\?\|\(\)\{\} - ERE はそのまま:
+?|(){} - POSIX 文字クラス:
[[:digit:]][[:alpha:]][[:space:]]
第7章:現場での使いどころ
- サービスログから直近のエラーだけ:
journalctl --since "1 hour ago" | grep -i error - 設定ファイルから有効行のみ:
grep -v '^\s*#' /etc/ssh/sshd_config | grep -v '^$'(コメント行と空行を除外) - bash ユーザー一覧:
awk -F: '$NF == "/bin/bash" {print $1}' /etc/passwd - アクセスログのIPアドレス頻度:
awk '{print $1}' access.log | sort | uniq -c | sort -rn | head - 設定ファイル一括置換:
sudo sed -i.bak 's/PermitRootLogin yes/PermitRootLogin no/' /etc/ssh/sshd_config(変更前にdiffで確認、変更後にsshd -tで構文チェック) - ある単語を含むファイルだけ列挙:
grep -rl 'TODO' src/ - ログ容量の合算:
du -h /var/log/*.log | awk '{sum+=$1} END {print sum"MB"}'(簡易)
第8章:ヒヤリハット ── sed -i で本番設定を破壊
⚠️ sed -i で SSH 設定を破壊し、ログイン不能
新人J君は、本番Webサーバーの SSH 設定を変更するため、sudo sed -i 's/PermitRootLogin yes/PermitRootLogin no/' /etc/sshd_config を実行しました(注:正しいパスは /etc/ssh/sshd_config)。タイポにより、ファイルが見つからないエラーで終了 ── と思いきや、別の sed コマンドで意図しない正規表現が効いて設定値が壊れた状態に。systemctl reload sshd 直後にログインできなくなり、コンソールアクセスも整っていなかったため復旧に半日を要しました。
教訓:
-i単独ではなく 必ず-i.bakでバックアップを残す- 本番反映前に
diff before afterで差分を目で確認 - 設定変更後は
sshd -t、nginx -t、visudo -cなど構文チェッカーで事前検証 - SSH 設定変更時は別ターミナルで現セッションを維持したまま reload。新規接続が成功するまで現セッションを切らない
- コンソールアクセス手段(Hyper-V、IPMI、クラウドコンソール)を事前に確保
類似事例:awk の区切り文字指定漏れで意図しない出力 → 集計値が誤って出る → ダッシュボードの数字を信じてしまう。本番データに対する変換は、必ず手元でサンプル実行してから本番に流すのが鉄則です。
やってみよう
linuc-alma にログインしている前提で、演習1〜4を順に実行してください。
演習1:grep の基礎
rm -rf ~/linuc-text && mkdir -p ~/linuc-text- サンプルログ作成(本文 第2章のヒアドキュメント)
grep ERROR ~/linuc-text/sample.loggrep -i error ~/linuc-text/sample.loggrep -v INFO ~/linuc-text/sample.loggrep -n ERROR ~/linuc-text/sample.loggrep -c ERROR ~/linuc-text/sample.loggrep -E 'ERROR|WARN' ~/linuc-text/sample.log
演習2:sed の基礎
sed 's/ERROR/[ERR]/g' ~/linuc-text/sample.logsed '/INFO/d' ~/linuc-text/sample.logsed -n '/ERROR/p' ~/linuc-text/sample.logsed -n '2,4p' ~/linuc-text/sample.logcp ~/linuc-text/sample.log ~/linuc-text/sample2.logsed -i.bak 's/Service/SERVICE/' ~/linuc-text/sample2.logdiff ~/linuc-text/sample2.log.bak ~/linuc-text/sample2.log
演習3:awk の基礎
awk '{print $1, $4}' ~/linuc-text/sample.logawk -F: '{print $1, $NF}' /etc/passwd | head -3awk -F: '$3 >= 1000 {print $1, $3}' /etc/passwdawk -F: 'BEGIN{c=0} $NF == "/bin/bash" {c++} END{print "bash users:", c}' /etc/passwdawk -F: '{count[$NF]++} END{for(s in count) print count[s], s}' /etc/passwd | sort -rn
演習4:補助コマンドと正規表現
awk -F: '{print $NF}' /etc/passwd | sort | uniq -ccut -d: -f1,3 /etc/passwd | head -5echo "Hello World 2026" | tr 'a-z' 'A-Z'grep -E '^[a-z]+:' /etc/passwd | head -3echo "Phone: 03-1234-5678" | grep -E '[0-9]+-[0-9]+-[0-9]+'printf 'abc\n123\nxyz789\n' | grep -E '[[:digit:]]+'- クリーンアップ:
rm -rf ~/linuc-text
分からないオプションは man grep、man sed、man gawk(または man awk)で調べる習慣を身につけてください。GNU の info ドキュメント(info grep など)はさらに詳細です。
理解度チェック
○か×で答えてください。回答と解説は次回冒頭で振り返ります。
grep -v ERROR fileは ERROR を含む行だけを出力する。sed 's/foo/bar/' fileは file 内の全行で foo の出現すべてを bar に置換する。awk -F: '{print $NF}' /etc/passwdは各ユーザーのログインシェルを表示する。- BRE で「1回以上」を表すには
\+、ERE では+をそのまま書く。 uniqは離れて出現する重複も検出してまとめる。
解答
- 1. ×
-vは反転。ERROR を含まない行を出力 - 2. × フラグ
gなしは各行最初の1個だけ。全部置換するにはs/foo/bar/g - 3. ○
$NFは最終フィールド。/etc/passwdの最終列はログインシェル - 4. ○ BRE では
\+、ERE では+。OR|やグループ化()も同様にエスケープ要否が異なる - 5. ×
uniqは連続する重複のみ。離れた重複もまとめたいなら事前にsortが必要
次回予告
第11回は「vi/vim 入門:現場で使えるエディタ操作」です。リモートサーバーで使えるエディタは限られており、vi(vim)は事実上の標準です。新卒エンジニアが最初に挫折するポイントでもあるので、最低限の操作(i で挿入、Esc でノーマル、:wq で保存終了)から段階的に積み上げます。本記事の sed 知識(行編集の発想)が vim の :s/pat/rep/g でそのまま活きます。
LinuC 101 試験対策シリーズ 全12回
- 第1回 Linuxの起動・接続・停止:systemctl・login・shutdownの基本
- 第2回 ブートプロセスの仕組み:BIOS/UEFI → GRUB → systemd の流れ
- 第3回 systemdマスター講座:サービス管理・unitファイル・ターゲット
- 第4回 プロセス管理とハードウェア基礎(ps, top, lsblk, lspci, lsusb)
- 第5回 仮想マシンとコンテナの基礎:KVM・Docker・Podman 入門
- 第6回 パッケージ管理マスター:dnf / apt / rpm / dpkg の実践
- 第7回 ファイル操作の実践:cp, mv, find, リンク, FHS
- 第8回 パーミッション・所有者・特殊権限(SUID/SGID/Sticky)
- 第9回 コマンドライン・リダイレクト・パイプの基礎
- 第10回 テキスト処理の三種の神器:grep / sed / awk + 正規表現(本記事)
- 第11回 vi/vim 入門:現場で使えるエディタ操作
- 第12回 ディスク・パーティション・ファイルシステム(fdisk, mkfs, mount, LVM)
