
新卒インフラエンジニア向け Kubernetes 実践教科書(第2巻 CKA 編)の第1回です。動作確認バージョン: K8s v1.35.5 / kubectl v1.35.5 / Helm v4.1.4 / AlmaLinux 10.1(2026-05-19 時点・k8s-ops 実機検証済)。第1巻(CKAD 編)を完走し、kind 上で fanclub-api が動く状態から第2巻がスタートします。第2巻では、本番想定の HA クラスタを kubeadm で自力構築し、CKA(Certified Kubernetes Administrator)受験準備を完成させます。第1回はオリエンテーション回として、全体像・試験形式・kubeadm の概要を把握します。
今ここマップ(第1回 / 全16回 / 第1部)
今ここマップ(第2巻 16 回中の現在位置):
今ここ: 第1回 / 全16回(第1部:クラスタ構築)
▓░░░░░░░░░░░░░░░ 6%
第1部(クラスタ構築): ■□□□□ 1/5 回(進行中)
第2部(ワークロード管理): □□□ 0/3 回
第3部(ネットワーク): □□□ 0/3 回
第4部(ストレージ): □ 0/1 回
第5部(監視・運用): □□ 0/2 回
第6部(トラブルシュート): □□ 0/2 回第1回を終えると、以下を把握した状態になります。
- 第2巻で何を学ぶかを全体像(16 回構成・6 部構成・fanclub-api HA 移行物語)で把握できる
- CKA 試験の形式(2 時間・Performance-based・合格 66%・Killer.sh 模擬試験)と CKAD との違いを説明できる
- CKA 5 ドメイン(D1〜D5・配点 25/15/20/10/30%)と第2巻の対応回を把握できる
- kubeadm の役割(K8s 公式クラスタ構築ツール)と主要サブコマンド・標準パスを説明できる
- kubeadm / RKE2 / k0s / OKD の使いどころを概観し、本巻が kubeadm 主軸である 3 つの理由を説明できる
第2巻の完走マイルストーン(第16回完了時の達成基準)を確認します。これが第2巻全体を通じた学習目標です。
- kubeadm HA クラスタ(Control Plane ×3 + Workload Node ×2)を自力構築できた
- kubeadm upgrade plan/apply によるクラスタバージョンアップができた
- etcdctl による etcd backup/restore を自力実施できた
- fanclub-api が Longhorn + ArgoCD GitOps + Prometheus 監視付きで稼働している
- Velero でクラスタバックアップが取れている
- Control Plane 障害・Workload Node 障害・NetworkPolicy 問題・CrashLoopBackOff を診断できた
- CKA 5 ドメインを全回で体験した
第2巻の全体像 — 16回・6部構成と fanclub-api HA 移行物語
第2巻の最終ゴール
第2巻の最終ゴールは、kubeadm による本番想定 HA クラスタ(Control Plane ×3 + Workload Node ×2)を自力構築し、CKA 受験準備を完成させることです。Kubestronaut 5 冠(CKAD + CKA + CKS + KCNA + KCSA)への第2関門突破という位置づけです。
第1巻では「アプリを動かす」ことを学びました。第2巻では視点が転換します。「クラスタ自体を構築・管理する」という管理者視点です。具体的には次の問いに答えられるようになることが目標です。
- kubeadm init / join を使ってクラスタをゼロから構築できるか
- etcd のバックアップと復元を自力でできるか
- クラスタのバージョンアップを kubeadm upgrade で安全に実施できるか
- Control Plane が落ちたとき原因を特定して復旧できるか
- NetworkPolicy や RBAC でクラスタのアクセス制御を設計できるか
これらはすべて CKA 試験の出題範囲であり、実際のクラスタ管理者が日常的に直面する業務でもあります。第2巻の 16 回を通じて、試験と実務の両方に対応する力を身につけます。
6部構成の概観
第2巻は 6 つの部に分かれています。各部のテーマと主なゴールを示します。
| 部 | テーマ | 回 | 主なゴール |
|---|---|---|---|
| 第1部 | クラスタ構築 | 第1〜5回 | kubeadm HA クラスタ構築 + fanclub-api HA 移行 |
| 第2部 | ワークロード管理 | 第6〜8回 | kubeadm upgrade + スケジューリング + HPA |
| 第3部 | ネットワーク | 第9〜11回 | MetalLB + NetworkPolicy + Gateway API |
| 第4部 | ストレージ | 第12回 | Longhorn + fanclub-db ボリューム移行 |
| 第5部 | 監視・運用 | 第13〜14回 | Prometheus + GitOps(ArgoCD) |
| 第6部 | トラブルシュート | 第15〜16回 | CP/etcd/WL/Network 障害診断 |
各部の内容を補足します。
第1部(第1〜5回):クラスタ構築
本巻の核心です。第1回(本回)はオリエンテーション、第2回でシングルノードクラスタを kubeadm で起動し、第3回で HA 設計(HAProxy による API Server 冗長化)、第4回でフル HA クラスタ(CP×3 + WL×2)を構築して fanclub-api を移行します。第5回では etcd のバックアップと復元を扱います。第1部を完了した時点で、本番を意識した HA クラスタの構築能力を習得します。
第2部(第6〜8回):ワークロード管理
クラスタのバージョンアップ(kubeadm upgrade)、Pod スケジューリング(taint/toleration/nodeSelector/affinity)、HPA による自動スケーリングを扱います。第6回は kubeadm upgrade と合わせてトラブルシュートの入門演習も行います。管理者としてクラスタのバージョンを維持し、ワークロードが意図通りのノードに配置されるよう制御する能力を習得します。
第3部(第9〜11回):ネットワーク
MetalLB による LoadBalancer の実現、NetworkPolicy の詳細、Gateway API + CoreDNS + Traefik の構成を扱います。第1巻で学んだ NetworkPolicy の概念を管理者視点でより深く掘り下げます。外部からのアクセスをどう制御するかという、クラスタ公開に不可欠な知識を習得します。
第4部(第12回):ストレージ
Longhorn による分散ストレージ構築と、fanclub-db のボリューム移行を扱います。PV/PVC/StorageClass の仕組みを実機で確認します。ノード障害が発生してもデータが失われない分散ストレージ設計を理解します。
第5部(第13〜14回):監視・運用
kube-prometheus-stack(Prometheus + Grafana + Alertmanager)と Loki + Fluent Bit によるログ収集、ArgoCD による GitOps 化と Velero バックアップを扱います。「クラスタが今どういう状態か」を常時把握し、変更を Git で管理するというプロダクション運用の基本を習得します。
第6部(第15〜16回):トラブルシュート
CKA 試験の最重要ドメイン(D5: 30%)に直結する演習です。Control Plane + etcd 障害診断(第15回)と Workload Node + Network + App の複合障害診断(第16回)を扱い、第2巻の完走宣言を行います。「壊れた状態から直す」という管理者の実務力の総仕上げです。
fanclub-api HA 移行物語
第2巻は fanclub-api の「成長物語」でもあります。第1巻完走時点での状態と、第2巻を通じた変遷を整理します。
第1巻完走時点:kind クラスタ(k8s-ops 上で動く Docker コンテナ)上に fanclub-api(Frontend + Backend + PostgreSQL 18)が稼働しています。https://fanclub.local から CRUD 操作が動作することを確認した状態です。しかし kind クラスタは単一ノードであり、ノード障害があればサービスが停止します。本番用途には適しません。
第2巻での変遷を次のロードマップで示します。
[第1巻完走時点]
kind クラスタ(単一ノード・Docker コンテナ)
└ fanclub-api(Frontend + Backend + PostgreSQL 18)
└ https://fanclub.local で CRUD 操作可能
└ kubectl v1.35.0 / Helm v4.1.4 / kind v0.31.0
↓ 第2回: kubeadm シングルノードクラスタ起動
[第2回完了時点]
kubeadm クラスタ(k8s-cp-01 シングルノード)
└ Calico CNI インストール済
└ kind クラスタは削除済(第1回末尾で実施)
↓ 第3〜4回: HA クラスタ構築 + fanclub-api 移行
[第4回完了時点]
kubeadm HA クラスタ(CP×3 + WL×2)
└ fanclub-api が kind → kubeadm HA クラスタへ移行完了
└ MetalLB + Gateway API で外部アクセス可能
└ Control Plane 1 台が落ちてもサービス継続
↓ 第12回: Longhorn 分散ストレージ
[第12回完了時点]
kubeadm HA クラスタ + Longhorn
└ fanclub-db が PV → Longhorn ボリュームへ移行
└ Workload Node 障害時もデータ損失なし
↓ 第13〜14回: 監視 + GitOps
[第14回完了時点]
kubeadm HA クラスタ + Longhorn + Prometheus + ArgoCD GitOps + Velero
↓ 第15〜16回: トラブルシュート演習
[第2巻完走時点(第16回)]
本番想定 HA クラスタ + 監視 + GitOps + Velero バックアップ完備
CKA 受験準備完了第1巻で作った fanclub-api は、第4回で本番想定の HA クラスタへ移行します。第12回以降はその状態をさらに強化し、第2巻完走時点では監視・GitOps・バックアップを備えた本格的な運用環境が整います。
第1巻から第2巻への視点転換
第1巻(CKAD 編)と第2巻(CKA 編)の違いを一言で表すと、「アプリを動かす視点」から「クラスタを管理する視点」への転換です。
| 観点 | 第1巻(CKAD) | 第2巻(CKA) |
|---|---|---|
| 主な問い | このアプリをどう K8s 上で動かすか | このクラスタをどう構築・維持するか |
| 主な操作対象 | Pod / Deployment / Service / Helm Chart | kubeadm / etcd / RBAC / kubelet / Static Pod |
| インフラ層への関心 | クラスタは「あるもの」として使う | クラスタを「作り・壊し・直す」 |
| 障害対応 | アプリ Pod が起動しない原因を調べる | Control Plane が落ちた原因を調べて復旧する |
| 前提環境 | kind クラスタ(既存) | kubeadm で自力構築した HA クラスタ |
第1巻で種を蒔き、第2巻でその土台(クラスタ)を自分で作るというイメージです。第1巻の知識は第2巻でも活きます。NetworkPolicy の設計・Helm による管理・Gateway API の設定など、第1巻で学んだことはすべて第2巻の演習でも使います。「アプリを動かした経験があるからこそ、クラスタ管理者としての勘所がわかる」という学習効果があります。
第2巻が第1巻の知識をどう活用するかの具体例を示します。
| 第1巻で学んだ内容 | 第2巻での活用場面 |
|---|---|
| kubectl の基本操作(get / describe / logs / apply) | 第2回〜 kubeadm クラスタの状態確認・トラブルシュートで毎回使う |
| NetworkPolicy の概念 | 第10回 NetworkPolicy 詳細演習・第16回 Network トラブルシュート |
| Helm v4 の使い方 | 第11回 Traefik インストール・第13回 kube-prometheus-stack・第14回 ArgoCD |
| Gateway API + Traefik | 第11回 Gateway API の HA 構成・第4回 fanclub-api 外部公開 |
| PV/PVC の基礎 | 第12回 Longhorn StorageClass での動的プロビジョニング |
| fanclub-api の Helm Chart | 第4回 HA クラスタへの移行・第14回 ArgoCD GitOps 化 |
第1巻で使ったコマンドや概念は第2巻でも繰り返し登場します。第1巻の復習として第2巻を活用することもできます。特に Helm の使い方と Gateway API の設定は第2巻でさらに深化するため、第1巻の内容が定着していると第2巻の演習がより短時間で進みます。
CKA 試験形式と CKAD との違い
CKA 試験概要
CKA(Certified Kubernetes Administrator)は Linux Foundation が提供する Kubernetes 管理者向けの認定資格です。一次ソースは training.linuxfoundation.org/certification/certified-kubernetes-administrator-cka/ です。試験の概要を整理します。
| 項目 | 内容 |
|---|---|
| 試験名 | Certified Kubernetes Administrator(CKA) |
| 試験形式 | Performance-based(実技・ブラウザ端末で kubectl・kubeadm 実操作) |
| 試験時間 | 2 時間 |
| 合格点 | 66% |
| 問題数 | 15〜20 問程度 |
| 試験バージョン | Kubernetes v1.35 対応 |
| 有効期限 | 3 年 |
| 模擬試験 | Killer.sh(2 回付属・本番より難易度高め) |
| 試験中参照可 | kubernetes.io/docs・github.com/kubernetes |
| 試験申込 | training.linuxfoundation.org |
CKA は択一式(多肢選択)ではなく、実際に kubectl コマンドを打って作業を完成させる Performance-based 形式です。ブラウザ上で提供される端末(ターミナル)から、指示された通りにクラスタを操作・修正・構築して問題を解きます。
試験時間は 2 時間で、問題数は 15〜20 問程度です。各問題には配点の重みがあり、合計スコアの 66% 以上を取ると合格です。資格の有効期限は 3 年で、更新には再受験または Linux Foundation の更新プログラムを利用します。
試験環境の特徴として、受験者は複数の K8s クラスタ(問題ごとに異なるクラスタコンテキスト)を扱います。問題の先頭に kubectl config use-context xxx と書かれていることが多く、最初にコンテキストを切り替えてから作業する習慣が重要です。コンテキスト切り替えを忘れると、全く別のクラスタを操作してしまいます。
Killer.sh の活用方法
CKA の受験申込に含まれる模擬試験 Killer.sh は、本番試験より難易度が高く設定されています。Killer.sh での得点が低くても悲観する必要はありません。重要なのは「解けなかった問題の解法を徹底的に復習する」ことです。
Killer.sh の活用ポイントを整理します。
- 模擬試験は 2 回分付属している。1 回目は「現状把握」として時間内に解き、2 回目は復習後の「確認テスト」として使う
- 解けなかった問題・時間がかかりすぎた問題は、必ず解答解説を読んで手順を確認する
- 特に D5(Troubleshooting)の問題は、原因特定のアプローチを言語化して整理する
- Killer.sh のセッションは試験終了後も数時間使用できる。制限時間後も環境を確認できる
- Killer.sh は本番より問題数が多い。全問解けなくても本番では時間が余るケースがある
第2巻の 16 回は Killer.sh の演習問題と対応するよう設計しています。第2回以降で kubeadm の実操作を繰り返すことで、試験本番での操作を体に染み込ませることが目的です。
試験中に参照できる公式ドキュメント
CKA 試験中は kubernetes.io/docs と github.com/kubernetes の参照が許可されています。これは重要な点です。コマンドの細かいオプションやマニフェストの書き方を全て暗記する必要はありません。ただし、ドキュメントを検索しながら作業するため「どのページのどこに何が書いてあるか」を把握しておくことが時間節約に直結します。
試験中によく参照するページの代表例を挙げます。
| 用途 | 参照先 URL(kubernetes.io/docs/) |
|---|---|
| kubeadm init | setup/production-environment/tools/kubeadm/create-cluster-kubeadm/ |
| kubeadm upgrade | tasks/administer-cluster/kubeadm/kubeadm-upgrade/ |
| etcd backup | tasks/administer-cluster/configure-upgrade-etcd/ |
| RBAC | reference/access-authn-authz/rbac/ |
| NetworkPolicy | concepts/services-networking/network-policies/ |
| kubeadm join | reference/setup-tools/kubeadm/kubeadm-join/ |
第2巻の演習ではこれらのページを参照しながら作業する習慣をつけます。試験本番と同じ環境(ドキュメント参照あり)で練習することが本番対策として有効です。ブックマークを活用する読者は、上記のページを事前に登録しておくと試験中の検索時間を短縮できます。
CKAD との比較
CKAD(Certified Kubernetes Application Developer)と CKA の違いを整理します。どちらも Performance-based で 2 時間・合格点 66% という共通点がありますが、対象者とテーマが根本的に異なります。
| 観点 | CKAD | CKA |
|---|---|---|
| 対象者 | アプリ開発者 | クラスタ管理者 |
| 主なテーマ | Pod/Deployment/Service/Helm | kubeadm/etcd/RBAC/トラブルシュート |
| 試験時間 | 2 時間 | 2 時間 |
| 合格点 | 66% | 66% |
| 重要ドメイン | アプリ設定・ワークロード | トラブルシュート(30%) |
| クラスタ構築 | 出題なし(クラスタは与えられる) | kubeadm init/join が出題される |
| etcd 操作 | 出題なし | etcdctl バックアップ・復元が出題される |
| 前提知識 | 基礎的な K8s 操作 | CKAD 相当のアプリ運用知識 |
最も重要な違いは、CKA では「壊れたクラスタを直す」問題が多く出ることです。Control Plane コンポーネントが起動していない状態からの復旧、kubelet が停止したノードの修復、証明書の期限切れ対応など、クラスタ管理者でなければ経験しない問題が中心になります。
もう一つの重要な違いはスコープです。CKAD では「既存のクラスタにアプリをデプロイする」という前提で問題が設計されています。クラスタは動いている状態で与えられます。CKA では「クラスタ自体を構築・修復する」ことが求められます。土台を作る作業と、その土台の上でアプリを動かす作業の違いです。
受験の順序については、CKAD(アプリ開発)を先に受験し、クラスタ操作に慣れてから CKA(クラスタ管理)に進む順序が推奨されます。本シリーズも第1巻(CKAD)→ 第2巻(CKA)という順序で設計しています。
Kubestronaut 5 冠を目指す場合の受験順序を整理します。
| 順序 | 資格 | 形式 | 本シリーズ対応 |
|---|---|---|---|
| 1 | CKAD | Performance-based(実技) | 第1巻完走後に受験 |
| 2 | CKA | Performance-based(実技) | 第2巻完走後に受験 |
| 3 | CKS | Performance-based(実技) | 第3巻完走後に受験 |
| 4 | KCNA | 多肢選択式(択一) | 自習(1 ヶ月程度) |
| 5 | KCSA | 多肢選択式(択一) | 自習(1 ヶ月程度) |
CKS は CKA の取得を前提としているため、必ず CKA 取得後に受験します。KCNA・KCSA は多肢選択式のため、実技試験の合間に自習で取得可能です。5 冠すべてを有効期限内(3 年)に保持すると、Linux Foundation から Kubestronaut として認定されます。
試験申込の流れについて補足します。CKA の申込は training.linuxfoundation.org から行います。購入後にシステムチェック(ブラウザ互換性・カメラ・マイクの確認)を事前に実施します。試験は PSI Secure Browser というアプリを使ったリモートオンライン試験です。受験時は静かな個室が必要で、机の上を片付け、身分証明書を手元に用意します。試験時間の 15 分前から接続開始できます。
試験当日の注意点として、別モニターの使用に制限があります(試験プロバイダーの規定に従う)。第2巻ではこれらの試験環境を意識した上で、コマンドを手で打つ練習を繰り返します。特に長いコマンドの入力速度は試験の時間効率に直結します。
CKA 5ドメイン詳細と第2巻カリキュラムの対応
5ドメインと配点・対応回の全体表
CKA 試験は 5 つのドメイン(出題分野)に分かれています。各ドメインの配点と第2巻での対応回を示します。
| ドメイン | 配点 | 第2巻対応回 | 本巻での扱い |
|---|---|---|---|
| D1: Cluster Architecture, Installation and Configuration | 25% | 第1〜6回・第14回 | 主要範囲を扱う |
| D2: Workloads and Scheduling | 15% | 第7〜8回(第1巻継続復習含む) | 主要範囲を扱う |
| D3: Services and Networking | 20% | 第9〜11回 | 主要範囲を扱う |
| D4: Storage | 10% | 第12回 | 主要範囲を扱う |
| D5: Troubleshooting | 30% | 第13〜16回 | 主要範囲を扱う |
第2巻は CKA 5 ドメインを全て網羅します。特に配点の大きい D1(25%)と D5(30%)を重点的に扱います。D1 + D5 だけで 55% を占めるため、この 2 ドメインで高得点を取ることが合格の鍵になります。
D1: Cluster Architecture, Installation and Configuration(25%)
D1 は kubeadm によるクラスタ構築・etcd 管理・RBAC・kubeconfig・kubeadm upgrade を含むドメインです。第2巻の前半(第1〜6回)と第14回がこのドメインに対応します。
D1 で問われる主な操作項目を挙げます(項目名は試験版の改訂で表現が変わる場合があるため、最新の公式 Curriculum を必ず確認してください)。
- Manage role based access control(RBAC)— 第2回以降で扱う(本シリーズでは個別の RBAC 演習回は設けず、各回で必要な ServiceAccount / Role / RoleBinding を実機操作時に都度扱う方針。本格的な RBAC 専門演習は CKS 編(第3巻)の認可・ポリシー回で扱う)
- Use Kubeadm to install a basic cluster — 第2回で実施
- Manage a highly-available Kubernetes cluster — 第3〜4回で実施
- Provision underlying infrastructure to deploy a Kubernetes cluster — 第2〜4回で実施
- Perform a version upgrade on a Kubernetes cluster using Kubeadm — 第6回で実施
- Implement etcd backup and restore — 第5回で実施
RBAC については第2回以降で順次扱います。kubeadm init / join / upgrade は第2・4・6回、etcd backup / restore は第5回が中心です。D1 は第2巻の前半を通じて継続的に習得するドメインです。
D1 の学習ポイントとして、kubeadm が使う設定ファイルの場所・コンポーネントの起動方法・証明書の管理方法を理解することが重要です。これらは「クラスタが壊れたときにどこを見るか」に直結し、D5 の Troubleshooting でも参照する知識です。
D1 を理解する上で重要な概念として「etcd と API Server の関係」があります。Kubernetes クラスタの状態はすべて etcd に保存されています。kube-apiserver が etcd の唯一の読み書きインタフェースであり、他のコンポーネント(controller-manager・scheduler・kubelet)は kube-apiserver 経由でのみ状態を参照・変更します。この設計が CKA の D1 と D5 の問題設計の基盤になっています。
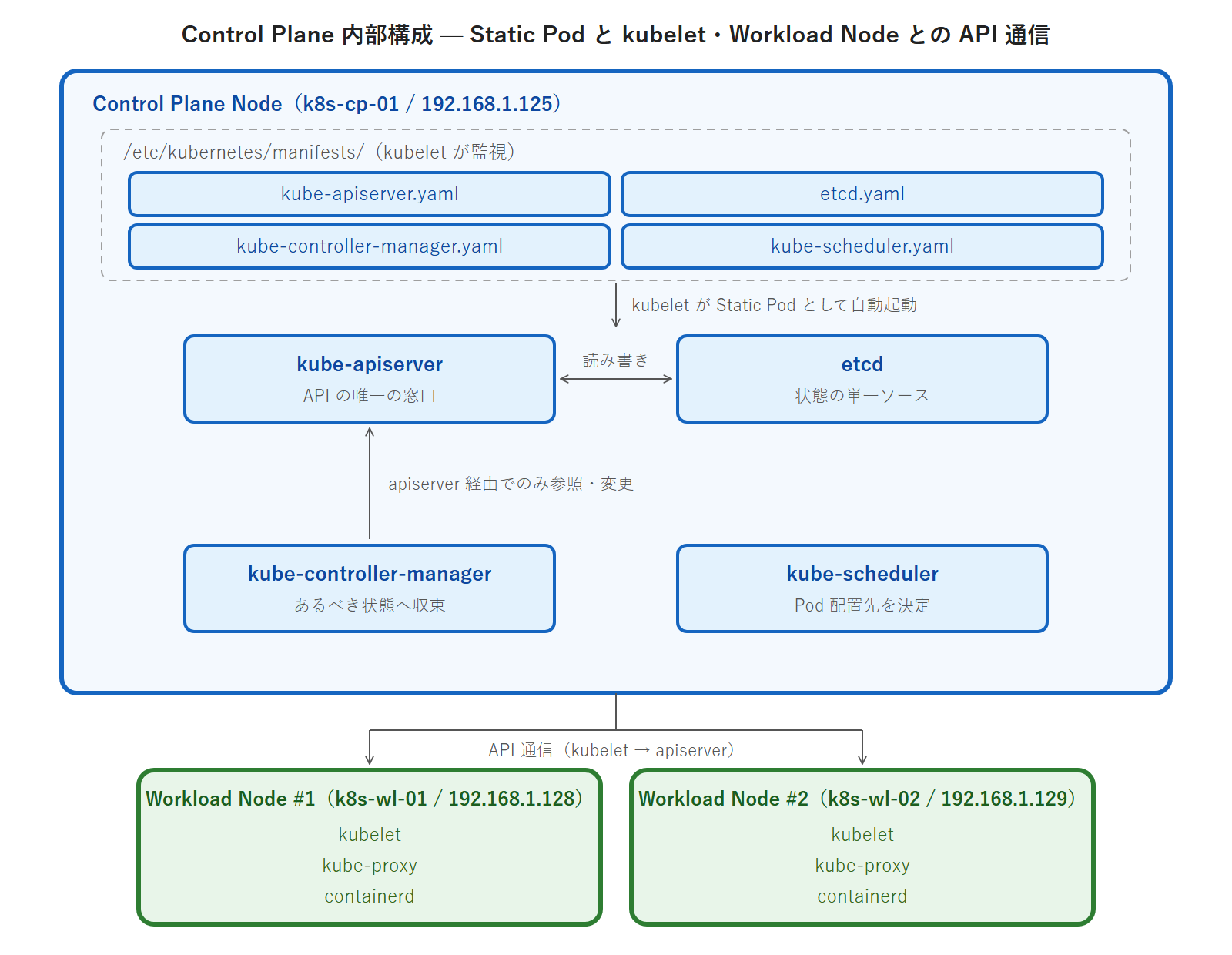
kubeadm init を実行すると、上図の kube-apiserver・etcd・kube-controller-manager・kube-scheduler が Static Pod として /etc/kubernetes/manifests/ に配置されます。kubelet がこのディレクトリを監視して各 Static Pod を自動起動します。このため、Control Plane の起動はノード上の kubelet が動いていることが前提です。kubelet が停止していると Static Pod も起動しないという関係は、D5 のトラブルシュートで重要な診断ポイントになります。
D2: Workloads and Scheduling(15%)
D2 は Deployment・HPA・スケジューリング(taint/toleration/affinity)を含むドメインです。第7〜8回がこのドメインに対応します。
D2 で問われる主な操作項目を挙げます(項目名は試験版の改訂で表現が変わる場合があるため、最新の公式 Curriculum を必ず確認してください)。
- Understand deployments and how to perform rolling update and rollbacks — 第1巻復習 + 第7回
- Use ConfigMaps and Secrets to configure applications — 第1巻復習
- Know how to scale applications — 第8回(HPA)
- Understand the primitives used to create robust, self-healing, application deployments — 第7〜8回
- Understand how resource limits can affect Pod scheduling — 第8回(ResourceQuota / LimitRange)
- Awareness of manifest management and common templating tools — 第14回(Helm / Kustomize)
CKAD との違いを具体的に説明します。CKAD では「Deployment を作って Rolling Update を設定する」程度の操作でした。CKA では「特定のノードに特定の Pod が配置されるよう taint と toleration を設定する」「ResourceQuota でクラスタ全体のリソース使用を制御する」といった、管理者が行う設定が求められます。
第7回(スケジューリング)と第8回(HPA / ResourceQuota / LimitRange)がこのドメインに対応します。第1巻で学んだ Deployment・Pod の知識を前提として、管理者視点の設定に焦点を当てます。
D3: Services and Networking(20%)
D3 は Service 詳細・NetworkPolicy・CoreDNS・Gateway API を含むドメインです。第9〜11回がこのドメインに対応します。
D3 で問われる主な操作項目を挙げます(項目名は試験版の改訂で表現が変わる場合があるため、最新の公式 Curriculum を必ず確認してください)。
- Understand host networking configuration on the cluster nodes — 第9〜10回
- Understand connectivity between Pods — 第10回(NetworkPolicy)
- Understand ClusterIP, NodePort, LoadBalancer service types and endpoints — 第9回
- Know how to use Ingress controllers and Ingress resources — 第11回(Gateway API / Traefik)※ 旧 Ingress リソース(
networking.k8s.io/v1Ingress)は ingress-nginx の EOL(2026-03)後も標準仕様として残存しているが、本シリーズは後継規格である Gateway API を採用。CKA 試験では「Ingress を作成」と「Gateway / HTTPRoute を作成」の両方が出題される可能性があるため、両者の役割対応(Ingress → HTTPRoute / IngressClass → GatewayClass)を理解しておくと安心 - Know how to configure and use CoreDNS — 第11回
- Choose an appropriate container network interface plugin — 第2回(Calico)
CKA での D3 の特徴として、ネットワークの「なぜ動かないか」を診断する能力が問われます。Service の DNS 名が解決できない・特定の Pod 間通信が遮断されている・CoreDNS が起動していないといった状態を素早く特定して修正できるかどうかです。
第1巻で学んだ NetworkPolicy の概念はここで重要な土台になります。第2巻では NetworkPolicy をより複雑なシナリオで使いこなす演習を行います。
D4: Storage(10%)
D4 は PV/PVC/StorageClass を含むドメインです。第12回(Longhorn 構築)がこのドメインに対応します。配点は 10% と小さいですが、確実に得点できるよう準備します。
D4 で問われる主な操作項目を挙げます(項目名は試験版の改訂で表現が変わる場合があるため、最新の公式 Curriculum を必ず確認してください)。
- Implement storage classes and dynamic volume provisioning — 第12回(Longhorn StorageClass)
- Configure volume types, access modes and reclaim policies — 第12回
- Manage persistent volumes claims primitive — 第12回
- Know how to configure applications with persistent storage — 第12回(fanclub-db 移行)
第12回では Longhorn による分散ストレージを構築した上で、fanclub-db のデータボリュームを Longhorn に移行します。この過程で PV/PVC/StorageClass の仕組みを実機で深く理解できます。
CKA 試験での D4 の出題パターンとして多いのは、「PVC を作って Pod にマウントする」という操作です。StorageClass の動的プロビジョニングが設定済みの状態で、PVC を作成し Pod の spec.volumes に設定するという手順です。第12回でこのパターンを実機で習得します。
D5: Troubleshooting(30%)— 最重要ドメイン

D5 は CKA 5 ドメインの中で最も配点が高く、30% を占めます。Control Plane 障害・etcd 復旧・Workload Node 復旧・アプリ診断が出題されます。第13〜16回に集中配分しています。
D5 で問われる主な操作項目を挙げます(項目名は試験版の改訂で表現が変わる場合があるため、最新の公式 Curriculum を必ず確認してください)。
- Evaluate cluster and node logging — 第13回(Loki + Fluent Bit)
- Understand how to monitor applications — 第13回(Prometheus + Grafana)
- Manage container stdout & stderr logs — 第13回
- Troubleshoot application failure — 第15〜16回
- Troubleshoot cluster component failure — 第15回(Control Plane / etcd)
- Troubleshoot networking — 第16回(NetworkPolicy / CoreDNS)
D5 の配点が 30% である理由は、管理者の実業務で最も頻繁に求められるスキルだからです。クラスタは必ず壊れます。Control Plane の kubelet が停止する、etcd のディスクが枯渇する、ノードが NotReady になる——これらのインシデントに迅速に対応できるかどうかが、管理者の実力を問うポイントです。
D5 の出題内容の代表例を挙げます。
- kube-apiserver が起動しない原因を Static Pod の設定から特定して修正する
- etcd のスナップショットから特定のバージョンに復元する
- NotReady になった Workload Node の kubelet を復旧する
- CrashLoopBackOff になっている Pod のログから原因を特定する
- 誤った NetworkPolicy により通信が遮断されている問題を解決する
- Node が NotReady になっていてその原因を
kubectl describe nodeやjournalctl -u kubeletで特定する
第2巻の後半 4 回(第13〜16回)はこのドメインに直結します。特に第15回(Control Plane + etcd トラブルシュート)と第16回(Workload Node + Network + App トラブルシュート)は、CKA 試験の D5 問題と同じ形式で演習を設計しています。
D5 対策の核心は「手順を体に染み込ませること」です。初めて見る障害でも「まずこのコマンドで状態確認、次にこのログを見る」という診断フローを自然に実行できる状態を目指します。第2巻の演習を通じて、この診断フローを身につけます。
D5 の診断フローの基本形を紹介します。
D5 基本診断フロー(CKA 試験でよく使う流れ)
[Step 1] クラスタ全体の状態を確認
$ kubectl get nodes
$ kubectl get pods -A
[Step 2] 問題のあるコンポーネントの詳細を確認
$ kubectl describe node <node-name>
$ kubectl describe pod <pod-name> -n <namespace>
[Step 3] ログを確認
$ kubectl logs <pod-name> -n <namespace>
# journalctl -u kubelet -n 50
# journalctl -u containerd -n 50
[Step 4] Static Pod の設定を確認(Control Plane 障害の場合)
# cat /etc/kubernetes/manifests/kube-apiserver.yaml
# cat /etc/kubernetes/manifests/etcd.yaml
[Step 5] 修正 → 状態確認を繰り返すこの診断フローは第15〜16回の演習で繰り返し実践します。CKA 試験では時間が限られているため、このフローを迷わず実行できることが高得点への道につながります。
kubeadm の役割と主要サブコマンド・標準パス
kubeadm の位置づけ
kubeadm は Kubernetes の公式クラスタブートストラップツールです。公式ドキュメント(kubernetes.io/docs/setup/production-environment/tools/kubeadm/)に詳細が記載されており、CKA 公式 Curriculum v1.35 には「Create and manage Kubernetes clusters using kubeadm」と明記されています。
kubeadm が担う最大の役割は「素の Kubernetes クラスタ」の構築です。kubeadm が作るクラスタには kube-apiserver・etcd・kube-scheduler・kube-controller-manager という Kubernetes の中核コンポーネントが含まれますが、CNI(Container Network Interface)・StorageClass・LoadBalancer は含まれません。これらは別途導入が必要です。
この設計思想は重要です。kubeadm は「素の K8s を作るツール」であり、それ以外の選択(どの CNI を使うか、どのストレージを使うか)は運用者が判断します。第2巻では、kubeadm で作ったクラスタに Calico / MetalLB / Longhorn / Traefik などを順次追加していきます。
Kubernetes クラスタの主要コンポーネントを整理します。kubeadm が配置するものとそうでないものを明確に把握することは、CKA 試験でも直接役立ちます。
| コンポーネント | 種別 | kubeadm による配置 | 第2巻での対応 |
|---|---|---|---|
| kube-apiserver | Control Plane | Static Pod として配置 | 第2回〜 |
| etcd | Control Plane | Static Pod として配置 | 第2回〜 |
| kube-controller-manager | Control Plane | Static Pod として配置 | 第2回〜 |
| kube-scheduler | Control Plane | Static Pod として配置 | 第2回〜 |
| kubelet | 全ノード | systemd サービスとして稼働(kubeadm は設定するが配置は別) | 第2回〜 |
| kube-proxy | 全ノード(DaemonSet) | kubeadm が DaemonSet として配置 | 第2回〜 |
| CNI(Calico 等) | 全ノード | 配置しない(別途必要) | 第2回で Calico を導入 |
| CoreDNS | Deployment(kube-system) | kubeadm が配置 | 第2回〜 |
kubeadm が担う領域と担わない領域
kubeadm の責任範囲を図式化して整理します。
kubeadm が担う領域
├ init : Control Plane 初期化(kube-apiserver / etcd / scheduler / controller-manager の Static Pod 配置)
├ join : ノード参加(Control Plane 追加 / Workload Node 参加)
├ upgrade: クラスタバージョンアップ(upgrade plan → upgrade apply)
├ reset : クラスタ解体(ノード初期化・cleanup)
├ token : join トークン管理(発行・一覧・削除)
└ certs : 証明書管理(更新・確認)
kubeadm が担わない領域(別途導入が必要)
├ CNI : Calico / Flannel 等(第2回で Calico を導入)
├ StorageClass : Longhorn 等(第12回で Longhorn を導入)
├ LoadBalancer : MetalLB 等(第9回で MetalLB を導入)
└ Ingress/Gateway: Traefik 等(第11回で Traefik を導入)この「kubeadm が作るもの」と「別途作るもの」の区別は、CKA 試験でも直接問われます。例として「kubeadm init を実行したが Pod 間通信ができない」という状況は、CNI をインストールしていないことが原因です。このような「当然できるはずのことができない」状況を素早く診断するためにも、責任範囲の理解が重要です。
CNI なしの状態では、ノードは NotReady のままになります。kubectl get nodes で確認するとすべてのノードが NotReady と表示されます。この状態から Calico をインストールすることで初めてノードが Ready になります。この流れを第2回で実機で確認します。
主要サブコマンド一覧
kubeadm の主要サブコマンドと、第2巻での対応回を示します。
| サブコマンド | 役割 | 対応回 |
|---|---|---|
kubeadm init | Control Plane Node 初期化 | 第2回 |
kubeadm join | ノード参加(CP 追加・WL 参加) | 第4回 |
kubeadm upgrade plan | アップグレード可能バージョン確認 | 第6回 |
kubeadm upgrade apply | クラスタアップグレード実施 | 第6回 |
kubeadm reset | ノード初期化・クラスタ解体 | 第4回(再構成時) |
kubeadm token create | join トークン発行 | 第4回 |
kubeadm certs check-expiration | 証明書有効期限確認 | 本回で概要(CKA 出題) |
これらのサブコマンドは第2巻の各回で実機操作します。第1回の時点では概要として把握しておけば十分です。第2回以降で実際に手を動かしながら定着させます。
サブコマンドのヘルプは kubeadm help や kubeadm init --help で確認できます。試験中もドキュメントと合わせて参照できます。特によく使うオプションを挙げます。
| コマンド例 | 用途 |
|---|---|
kubeadm init --control-plane-endpoint <VIP:6443> | HA クラスタ向け VIP 指定での init |
kubeadm init --pod-network-cidr=10.244.0.0/16 | Pod CIDR 指定(本シリーズは 10.244.0.0/16 を採用・第2回) |
kubeadm join <IP:6443> --token <token> --discovery-token-ca-cert-hash <hash> | Workload Node の join |
kubeadm join <IP:6443> --token <token> --control-plane --certificate-key <key> | Control Plane Node の join(HA 構成) |
CKA 試験に直結する標準パス
kubeadm が作るクラスタには、CKA 試験で必ず登場する標準パスがあります。この内容は第2巻を通じて繰り返し登場するため、今の時点で把握しておきます。
1. Static Pod manifest ディレクトリ:/etc/kubernetes/manifests/
kubeadm は Control Plane のコンポーネント(kube-apiserver・etcd・kube-controller-manager・kube-scheduler)を Static Pod として配置します。Static Pod は通常の Pod と異なり、kubelet がこのディレクトリを監視して直接起動します。このディレクトリ内の YAML ファイルを変更すると、kubelet が自動的に Pod を再起動します。
/etc/kubernetes/manifests/
├ kube-apiserver.yaml ← kube-apiserver の起動設定
├ etcd.yaml ← etcd の起動設定・データディレクトリ設定
├ kube-controller-manager.yaml
└ kube-scheduler.yamlCKA 試験では「kube-apiserver が起動しない」「etcd が落ちている」という問題でこのディレクトリの設定を確認・修正することが求められます。このパスを知らないと問題の取り掛かりすらできません。第15回のトラブルシュート演習でこのディレクトリを集中的に扱います。
2. 管理者 kubeconfig:/etc/kubernetes/admin.conf
kubeadm init が完了すると、クラスタへのアクセス情報(kubeconfig)が /etc/kubernetes/admin.conf に生成されます。このファイルを作業端末(k8s-ops)にコピーすることで、リモートから kubectl を使えるようになります。
第2巻では k8s-cp-01 で kubeadm init を実行した後、この admin.conf を k8s-ops の ~/.kube/config にコピーする手順を実施します(第2回)。この手順は CKA 試験でも「kubeconfig を設定して kubectl を使えるようにする」問題として出題されることがあります。
標準パス一覧をまとめます。
| パス | 内容 | 用途 |
|---|---|---|
/etc/kubernetes/manifests/ | Static Pod manifest | Control Plane コンポーネントの設定・トラブルシュート |
/etc/kubernetes/admin.conf | クラスタ管理者の kubeconfig | kubectl からのクラスタアクセス |
/etc/kubernetes/pki/ | クラスタ証明書・CA | 証明書の確認・更新 |
/var/lib/etcd/ | etcd のデータディレクトリ | etcd バックアップ・復元 |
/etc/kubernetes/ | kubeconfig ファイル群 | 各コンポーネントの認証情報 |
kubeadm はクラスタアーキテクチャを透明に学べるツール
kubeadm を使う教育的な価値は「Kubernetes の内部構造が見える」点にあります。
RKE2 や k0s は「1 コマンドでクラスタが立ち上がる」便利さを提供します。しかしその分、内部で何が起きているかが見えにくくなります。kubeadm では、CNI は自分でインストールし、LoadBalancer も自分で選び、StorageClass も自分で構築します。この「自分で選んでインストールする」プロセスが、Kubernetes の構成要素を 1 つずつ理解する機会になります。
CKA 試験はこの「透明性」を直接問います。「この問題でなぜ Pod 間通信ができないのか」「なぜ kube-apiserver が起動しないのか」を答えるには、クラスタの内部構造を理解している必要があります。kubeadm で手を動かすことで、試験と実務の両方で必要な「クラスタの中身の理解」が身につきます。
第2巻では kubeadm の各コマンドを実行するたびに「なぜこのオプションが必要か」「このコマンドで何が変わるか」を意識しながら進めます。単にコマンドをコピーして実行するのではなく、「このパラメータはどのコンポーネントの設定に反映されるか」を考える習慣が、CKA 試験での応用力につながります。
kubeadm と containerd の関係についても整理しておきます。kubeadm は Kubernetes のコンポーネント(コントロールプレーン・kubelet 等)のセットアップを担当します。containerd はコンテナランタイムとして Pod 内のコンテナを実際に起動・停止する役割を持ちます。kubeadm init を実行する前に containerd を正しく設定しておく必要があります。特に重要な設定が SystemdCgroup = true です。
containerd の設定で SystemdCgroup を有効にしないと、kubelet と containerd の cgroup ドライバが一致せず、ノードが正常に起動しません。第2回では containerd の設定ファイル(/etc/containerd/config.toml)に SystemdCgroup = true を追記する手順を実施します。これは kubeadm クラスタの構築で最初につまずきやすいポイントの一つです。
kubeadm token の仕組みについても補足します。kubeadm init が完了すると、Workload Node が join する際に必要なトークンが発行されます。このトークンはデフォルトで 24 時間後に失効します。第4回でノードを追加する際にトークンが失効していた場合は、kubeadm token create --print-join-command で新しいトークンを発行します。この操作は CKA 試験の「既存クラスタにノードを追加する」問題でも求められることがあります。
kubeadm が管理する証明書(/etc/kubernetes/pki/)は、デフォルトで 1 年間有効です。期限切れが近づくと kubeadm certs check-expiration で確認でき、kubeadm certs renew all で更新できます。なお kubeadm upgrade apply の実行時にも証明書は自動的に更新されるため、定期的にアップグレードしているクラスタでは期限切れになりにくい設計です。本シリーズでは証明書更新を単独の演習としては扱いませんが、CKA 試験範囲のためコマンド自体を把握しておいてください。
kubeadm vs RKE2 / k0s / OKD — ディストロ比較と kubeadm を選ぶ3つの理由
Kubernetes ディストロとは何か
「Kubernetes ディストロ(ディストリビューション)」とは、Kubernetes のコアに追加の機能・設定・ツールを組み合わせてパッケージングしたものです。Linux のディストリビューション(AlmaLinux・Ubuntu・Debian 等)と同じ考え方で、「どの Kubernetes ディストロを使うか」によってクラスタの構築方法・管理方法・対応サポートが変わります。
現在(2026年5月時点)の主な K8s ディストロと比較をまとめます。
| ディストロ | 特徴 | 主なユースケース | 本シリーズでの扱い |
|---|---|---|---|
| kubeadm | 公式ツール・素の K8s・CNI 等は別途 | CKA 試験・学習・標準 K8s 構築 | 第2巻の主軸 |
| RKE2 | SUSE/Rancher 系・FIPS 対応・Canal CNI 同梱 | Rancher 管理エンタープライズ環境・FIPS 要件あり | 別シリーズ(予定) |
| k0s | 軽量・シングルバイナリ・最小リソース | エッジ環境・リソース制約の強い本番環境 | 別シリーズ(予定) |
| OKD / OpenShift | Red Hat エンタープライズ・独自 CRI/ルーティング | Red Hat 系本番環境 | 別シリーズ(予定) |
| kind | Docker コンテナで K8s 擬似クラスタ | ローカル開発・CI | 第1巻で使用(本回で削除) |
各ディストロの詳細と現場での位置づけ
RKE2(Rancher Kubernetes Engine 2)
SUSE/Rancher が開発する K8s ディストロです。政府・金融など FIPS 140-2 準拠が求められる環境での採用実績があります。Canal CNI(Flannel + Calico の組み合わせ)が同梱されており、Rancher による GUI 管理との組み合わせが強みです。
設定ファイルは /etc/rancher/rke2/config.yaml に配置されるなど、kubeadm とは管理体系が異なります。サービスの起動は systemd 経由で rke2-server(Control Plane)・rke2-agent(Workload Node)として管理されます。
RKE2 が採用されやすい現場の例:Rancher によるマルチクラスタ管理が必要な場合、FIPS 対応が義務化されている政府系システム、SUSE のサポートを受けたい場合などです。
k0s
Mirantis が開発する軽量 K8s ディストロです。シングルバイナリで動作し、最小構成で 512 MB RAM から動かせます。エッジコンピューティング・工場内 IoT システムなど、リソース制約が厳しい環境での採用が増えています。
k0s install controller でコントローラとして登録し、k0s install worker でワーカーとして登録します。kubeadm のように CNI を別途インストールする必要がある点は共通ですが、設定管理の方法が異なります。
k0s が採用されやすい現場の例:Industrial IoT・リソースが限られた VM 環境・Mirantis のサポートを受けたい場合などです。
OKD / OpenShift
Red Hat が開発する K8s ディストロです。OpenShift Container Platform の上流コミュニティ版が OKD です。独自の CRI(CRI-O)・ルーティング(Route リソース)・認証(OAuth)を持ち、エンタープライズ機能を豊富に備えています。
Kubernetes の標準 Ingress の代わりに OpenShift Route リソースを使うなど、独自の拡張が多いため、kubeadm / RKE2 / k0s とは操作体系が大きく異なります。Red Hat のサポートを受けた本番環境での採用実績が豊富です。
OKD / OpenShift が採用されやすい現場の例:Red Hat Enterprise Linux を中心としたインフラ、IBM Cloud / AWS での OpenShift Dedicated 利用、Red Hat のフルサポートが必要な場合などです。
これらのディストロはそれぞれ現場で重要な役割を持っています。ただし本シリーズのスコープは「CKA 対応の kubeadm」であり、他ディストロは別シリーズで扱う予定です。
kubeadm を本巻の主軸とする3つの理由
本シリーズで kubeadm を主軸とする理由を 3 つに整理します。
理由1:CKA 試験は kubeadm 操作を直接問う
CKA 公式 Curriculum v1.35 に「Create and manage Kubernetes clusters using kubeadm」と明記されています。試験では kubeadm init によるクラスタ構築、kubeadm join によるノード追加、kubeadm upgrade によるバージョンアップが直接出題されます。
RKE2 や k0s の操作だけでは、CKA 試験で問われる kubeadm の出題範囲をカバーできません。試験と教材の手順を一致させることで、学習効率が上がります。第2巻の手順は CKA 試験問題と同じ操作を使うため、「演習 = 試験対策」として機能します。
理由2:クラスタアーキテクチャを最も透明に理解できる
kubeadm は CNI・StorageClass・LoadBalancer を自分でインストールするため、Kubernetes の構成要素が 1 つずつ可視化されます。「なぜ Pod 間通信ができないのか」「なぜノードが Ready にならないのか」を理解するには、各コンポーネントの役割を把握している必要があります。
RKE2 / k0s / OKD は「一括インストール」の利便性を提供しますが、その分だけ内部の動きが見えにくくなります。kubeadm で手を動かすことで、K8s の内部構造を学びながらクラスタを構築できます。「なぜこのコマンドが必要か」を理解しながら進めることが、管理者としての問題解決力の土台になります。
理由3:標準パスが試験に直結する
kubeadm が作るクラスタは /etc/kubernetes/manifests/(Static Pod)・/etc/kubernetes/admin.conf(kubeconfig)という Kubernetes 公式の標準パスを使います。これらは CKA 試験で直接問われます。
RKE2 の場合、設定は /etc/rancher/rke2/ に配置されます。OpenShift の場合は独自の管理体系があります。試験で混乱しないためにも、kubeadm の標準パスを軸に学習することが合理的です。また標準パスを覚えることで、将来的に他ディストロを扱う際の「比較の基準」としても機能します。
この 3 つの理由から、本シリーズは kubeadm を主軸として採用しています。RKE2・k0s・OKD はそれぞれ現場で重要なディストロですが、「CKA 対応の K8s 管理者を育成する」という本巻のゴールに最も合致するのが kubeadm です。
第2巻 9VM 構成と構築ロードマップ
9VM 構成の全体像
第2巻では第1巻の 2 VM 構成(k8s-ops + k8s-registry)から、本番想定の 9 VM 構成に拡張します。第1回の時点では第1巻から継続する 3 VM が稼働しており、第2回以降に新しい VM が順次追加されます。
9 VM の全体像を次に示します。
| VM 名 | IP | vCPU / RAM | 役割 | 導入回 |
|---|---|---|---|---|
| alma-proxy | 192.168.1.121 | 1 / 1 GB | DNS / NTP / Squid プロキシ | 第1巻から継続 |
| k8s-ops | 192.168.1.122 | 2 / 6 GB | 作業端末(kubectl・Helm v4 等) | 第1巻から継続 |
| k8s-registry | 192.168.1.123 | 2 / 2 GB | Docker Registry | 第1巻から継続 |
| k8s-lb | 192.168.1.124 | 1 / 1 GB | HAProxy(API Server LB) | 第2回 |
| k8s-cp-01 | 192.168.1.125 | 2 / 4 GB | Control Plane Node #1(kubeadm init) | 第2回 |
| k8s-cp-02 | 192.168.1.126 | 2 / 4 GB | Control Plane Node #2(kubeadm join –control-plane) | 第4回 |
| k8s-cp-03 | 192.168.1.127 | 2 / 4 GB | Control Plane Node #3(kubeadm join –control-plane) | 第4回 |
| k8s-wl-01 | 192.168.1.128 | 4 / 8 GB | Workload Node #1(kubeadm join) | 第4回 |
| k8s-wl-02 | 192.168.1.129 | 4 / 8 GB | Workload Node #2(kubeadm join) | 第4回 |
ノード呼称について補足します。本シリーズでは K8s v1.20+ の公式呼称に従い、「Control Plane Node」(略称 CP)と「Workload Node」(略称 WL)を使います。「Master Node」「Worker Node」という旧称は使いません。コマンド出力やホスト名では略称(k8s-cp-01 等)を使います。これは CKA 試験の公式ドキュメントでも同じ呼称が使われているためです。
各 VM の選定理由を補足します。
- alma-proxy:企業ネットワークでよく使われる「プロキシ経由のインターネットアクセス」を再現するために必須。DNS サーバとして全 VM の名前解決を担当し、NTP サーバとして時刻同期も担当する
- k8s-ops:作業端末。kubectl / Helm v4 / kind(削除後も残す)/ Maven / JDK 25 が導入済み。第2巻では kubeadm クラスタの
admin.confをここに配置してリモート操作する - k8s-registry:fanclub-api のコンテナイメージを保存するプライベートレジストリ。kubeadm クラスタの Workload Node から参照する
- k8s-lb:HAProxy による API Server の負荷分散。Control Plane が 3 台あると、kubectl はどこにリクエストを送るか迷います。k8s-lb が 192.168.1.124:6443 に来たリクエストを k8s-cp-01〜03 の 6443 ポートに振り分けます
- k8s-cp-01〜03:Control Plane Node 3 台による HA 構成。etcd も 3 台で Raft コンセンサスを形成します(過半数の 2 台が稼働していればクラスタ継続可能)
- k8s-wl-01〜02:Workload Node 2 台。fanclub-api の Pod はここで稼働します。4 vCPU / 8 GB と CP より大きいスペックにしているのは、アプリ Pod + kube-prometheus-stack のリソース要件のためです
ネットワーク構成
第2巻の VM は 2 つのネットワークセグメントに接続されています。
| ネットワーク | アドレス | 用途 | 接続 VM |
|---|---|---|---|
| External(管理) | 192.168.1.0/24 | 全 VM の管理アクセス・Hyper-V ホストから SSH | 全 9 VM |
| Internal(予備) | 10.0.10.0/24 | 将来のストレージ通信・レプリケーション分離用の予備セグメント(本巻のクラスタ通信では未使用) | k8s-cp-01〜03・k8s-wl-01〜02 |
ネットワーク構成の概要です。k8s-cp と k8s-wl は 2 NIC 構成(External 192.168.1.x + Internal 10.0.10.x)です。本シリーズでは構成をシンプルに保つため、kubeadm の advertiseAddress・ノードの InternalIP・Calico のトンネル端点をいずれも External 側(eth0・192.168.1.x)に統一します(第2回で設定)。Internal ネットワーク(10.0.10.0/24・eth1)は、将来ストレージ通信やレプリケーションを管理トラフィックから分離するための予備セグメントとして用意しており、本巻のクラスタ通信では使用しません。
alma-proxy を通じたインターネットアクセスの設定についても、第2回で詳しく扱います。パッケージインストール(pkgs.k8s.io)やコンテナイメージのプル(registry.k8s.io)はすべて alma-proxy の whitelist に登録したうえで行います。これは企業ネットワークでの K8s 運用を再現した設計です。
DNS と NTP は alma-proxy が担当します。K8s クラスタのノードは alma-proxy を NTP サーバとして使い、時刻同期を行います。etcd は時刻がずれると正常動作しないため(Raft アルゴリズムのタイムアウト判定に影響)、NTP の設定は第2回の重要チェック項目です。
etcd の HA 構成(3 ノード)について補足します。etcd は Raft コンセンサスアルゴリズムを使って分散一貫性を保ちます。ノード数が奇数であることが重要で、3 ノードの場合は 2 ノード以上が稼働していればクラスタが継続動作します(quorum = 2)。逆に 2 ノードしか構成しない場合、1 台が落ちると quorum を失いクラスタが停止します。このため HA etcd は必ず 3 台以上(奇数)で構成します。
| etcd ノード数 | quorum(最低稼働台数) | 許容障害台数 | 推奨 |
|---|---|---|---|
| 1 | 1 | 0(冗長性なし) | 開発・学習のみ |
| 3 | 2 | 1 | 本番 HA の最小構成(本巻) |
| 5 | 3 | 2 | 大規模本番環境 |
第2巻では 3 ノード構成(k8s-cp-01〜03 の各 etcd)を採用します。1 台の Control Plane Node が障害になっても、残り 2 台で quorum を維持できるため、クラスタは継続して動作します。第5回の etcd 演習でこの仕組みを実機で確認します。
構築ロードマップ
第2回以降、各回でどの VM が追加されどの作業が行われるかを示します。
[第1回(本回)時点の稼働 VM]
alma-proxy(192.168.1.121): DNS / NTP / Squid プロキシ
k8s-ops (192.168.1.122): 作業端末(kind クラスタは本回末尾で削除)
k8s-registry(192.168.1.123): Docker Registry
[第2回] k8s-lb(192.168.1.124)+ k8s-cp-01(192.168.1.125)追加
→ alma-proxy whitelist に pkgs.k8s.io / projectcalico.docs.tigera.io を追加(registry.k8s.io は登録済み)
→ pkgs.k8s.io から kubeadm / kubelet / kubectl v1.35.x インストール
→ containerd の SystemdCgroup = true 設定(/etc/containerd/config.toml)
→ kubeadm init でシングルノードクラスタ起動
→ Calico CNI インストール(kubectl apply)
→ admin.conf を k8s-ops へ転送(~/.kube/config)
⇒ kubectl get nodes で k8s-cp-01 が Ready になることを確認
[第3回] k8s-lb の HAProxy 設定
→ HAProxy の frontend / backend 設定(VIP: 192.168.1.124:6443 → cp-01〜03:6443)
→ k8s-cp-02/03 向けの事前準備
⇒ HAProxy stats で接続確認
[第4回] k8s-cp-02(192.168.1.126)・k8s-cp-03(192.168.1.127)
+ k8s-wl-01(192.168.1.128)・k8s-wl-02(192.168.1.129)追加
→ kubeadm init --upload-certs で証明書共有
→ kubeadm join --control-plane(CP ×2 追加)
→ kubeadm join(WL ×2 追加)
→ fanclub-api を kind → kubeadm HA クラスタへ移行
⇒ kubectl get nodes で 5 ノード(CP×3 + WL×2)全 Ready を確認
[第5回] etcd 管理
→ etcdctl snapshot save でバックアップ
→ etcdctl snapshot restore で復元演習
→ ノード追加・削除(kubectl drain / kubectl delete node)
[第6回〜] クラスタ運用・kubeadm upgrade・監視・GitOps・トラブルシュート第1回時点の読者環境と注意事項
現時点(第1回)では k8s-ops に kind クラスタが稼働中です。後述の「やってみよう」演習で kind クラスタの現状を確認し、本回末尾で kind クラスタを削除します。第2回から新 VM の追加が始まります。
Vagrant + VirtualBox で環境を構築している読者向けの補足です。Vagrantfile は第2回に向けて k8s-lb と k8s-cp-01 の 2 VM 追加を記述します。スペック(vCPU / RAM)は表の値が最低要件です。ホストマシンのリソースが不足する場合は、k8s-cp の RAM を 4 GB → 2 GB に下げても第4回までは動作します。ただし第13回以降の kube-prometheus-stack 導入時に不足する可能性があります。
Hyper-V 環境で構築している読者へ:本シリーズの検証環境は Beelink SER7 × 2 台(各 64 GB RAM)の Hyper-V 環境です。9 VM の合計 RAM は 38 GB(1+6+2+1+4×3+8×2 = 38 GB)で、これを 2 台のホストに分散配置しています。1 台のホストにすべての VM を集約する場合は、OS のオーバーヘッドを含めてホストマシンに 48 GB 以上の RAM を確保することを目安にしてください。
やってみよう: 第1巻 kind クラスタの現状確認と次回準備
第1回は概念・オリエンテーション回です。実際の kubeadm 操作は第2回以降です。本演習は「第1巻の完了状態を確認し、第2巻スタートの準備を整える」という読み取り中心の演習です。k8s-ops で作業します。
ステップ 1:kubectl で kind クラスタの状態を確認する
まず第1巻で構築した kind クラスタが正常に稼働していることを確認します。k8s-ops にログインして実行します。
実行コマンド:
$ kubectl get nodes -o wide実行結果:
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
kind-control-plane Ready control-plane 11d v1.35.0 172.18.0.2 <none> Debian GNU/Linux 12 (bookworm) 6.12.0-124.55.3.el10_1.x86_64 containerd://2.2.0kind クラスタが 1 ノード(kind-control-plane)で稼働していることを確認します。確認するポイントは 3 点です。
- STATUS が
Readyであること(NotReady の場合は kind クラスタが正常に稼働していない) - VERSION が
v1.35.0であること(第2巻で同じバージョンを kubeadm でインストールする) - CONTAINER-RUNTIME が
containerd://2.2.0であること(kubeadm クラスタでも containerd を使用する)
次に kubectl のバージョンを確認します。
実行コマンド:
$ kubectl version実行結果:
Client Version: v1.35.0
Kustomize Version: v5.7.1
Server Version: v1.35.0Client Version(kubectl)と Server Version(K8s API Server)の両方が v1.35.0 であることを確認します。Kustomize Version は v5.7.1 です。第2巻では同じ v1.35 系を kubeadm でインストールします。なお冒頭の動作確認バージョンに記した kubectl v1.35.5 は第2巻の作業端末 k8s-ops に導入した版で、ここで表示される v1.35.0 は第1巻完走時点の kind クラスタおよび kubectl の版です。
kind クラスタの一覧も確認します。
実行コマンド:
$ kind get clusters実行結果:
kindクラスタ名「kind」が 1 つ稼働しています。これが第1巻で構築した kind クラスタです。kind クラスタは k8s-ops 上の Docker コンテナとして稼働しているため、docker ps でも確認できます(補足確認として実行してみてください)。
ステップ 2:CKA 公式 Curriculum v1.35 の5ドメインを確認する
ブラウザで次の URL を開き、CKA の試験概要ページを確認します。
https://training.linuxfoundation.org/certification/certified-kubernetes-administrator-cka/
確認するポイントは次の通りです。
- 試験バージョン(Kubernetes v1.35 と記載されていること)
- 合格点(66%)
- Killer.sh 模擬試験が 2 回付属すること
- Curriculum PDF のリンクから 5 ドメインと配点を確認する(D5 Troubleshooting が 30% と最大配点であることに注目)
Linux Foundation の試験ページは定期的に更新されます。本書で説明したバージョン・配点と異なる場合は、最新の公式情報を優先してください。特に試験バージョンは年に 1〜2 回更新されます(2026年5月時点で v1.35 が現行バージョン)。
Curriculum PDF を開いたら、各ドメインの下に列挙されている具体的なスキル項目も確認することを推奨します。「どのような操作が問われるか」を把握しておくことで、第2巻の各回での学習に方向性が生まれます。
なお training.linuxfoundation.org は試験の申込・事前確認用のページであり、試験本番中に参照できるのは kubernetes.io/docs と github.com/kubernetes のみです。試験概要や Curriculum の確認は受験前のいまのうちに済ませておきます。
ステップ 3:次回に向けて kind クラスタを削除する
第2巻では kubeadm クラスタを使用します。第1巻で構築した kind クラスタは削除して、次回の kubeadm 環境への切り替えを準備します。kind クラスタを残したままでも第2巻を進めることは技術的には可能ですが、リソース(RAM・CPU)を解放し作業環境を整理するため削除します。
実行コマンド:
$ kind delete cluster実行結果:
Deleting cluster "kind" ...
Deleted nodes: ["kind-control-plane"]kind クラスタが削除されました。「kind」という名前のクラスタが削除され、「kind-control-plane」という Docker コンテナが停止・削除されました。kind delete cluster は同時に ~/.kube/config から kind クラスタのコンテキスト(context)も削除します。そのため削除後に kubectl get nodes を実行すると、現在のコンテキストが未設定の状態となりエラーが返ります。
実行コマンド:
$ kubectl get nodes実行結果:
E0519 20:57:56.854287 2143507 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp [::1]:8080: connect: connection refused"
E0519 20:57:56.854668 2143507 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp [::1]:8080: connect: connection refused"
E0519 20:57:56.856029 2143507 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp [::1]:8080: connect: connection refused"
E0519 20:57:56.856308 2143507 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp [::1]:8080: connect: connection refused"
E0519 20:57:56.857661 2143507 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"http://localhost:8080/api?timeout=32s\": dial tcp [::1]:8080: connect: connection refused"
The connection to the server localhost:8080 was refused - did you specify the right host or port?これは正常な動作です。kind delete cluster によって ~/.kube/config から kind のコンテキストが削除され、現在のコンテキスト(current-context)が未設定になりました。コンテキストが未設定のとき、kubectl は接続先を判断できず、レガシーなデフォルト値である localhost:8080 へ接続を試みます。そこには API Server が存在しないため connection refused となります。冒頭の E0519... で始まる行は同じ内容が数行繰り返し出力されますが、これも想定どおりの挙動です。このエラーが返ることを確認できれば、kind クラスタの削除が完了しています。
第2回以降で kubeadm クラスタを構築し、/etc/kubernetes/admin.conf を k8s-ops に転送して ~/.kube/config に配置することで、再び kubectl get nodes が動作するようになります。このとき kubectl の接続先は、kubeadm が生成した kubeconfig に記載された 192.168.1.124:6443(k8s-lb の API Server エンドポイント)になります。
演習まとめ
今回の演習で完了したことをまとめます。
- 第1巻完走状態の kind クラスタ(K8s v1.35.0・kubectl v1.35.0・containerd 2.2.0)を確認した
- CKA 公式 Curriculum v1.35 の試験概要ページで 5 ドメインと配点を確認した(D5 Troubleshooting が 30% 最大配点)
- kind クラスタを削除し、第2回(kubeadm シングルノード起動)の準備が整った
次回(第2回)では k8s-lb と k8s-cp-01 の 2 VM を追加し、pkgs.k8s.io から kubeadm / kubelet / kubectl v1.35.x をインストールして kubeadm init を実行します。alma-proxy の whitelist に pkgs.k8s.io と Calico のドキュメント配信元 projectcalico.docs.tigera.io を追加する作業も含みます。
まとめ・現場ヒヤリハット・理解度チェック
まとめと次回予告
第1回で学んだことをまとめます。
- 第2巻は kubeadm で本番想定 HA クラスタを自力構築し、CKA 受験準備を完成させる 16 回・6 部構成。fanclub-api は第4回で kind → kubeadm HA クラスタへ移行する
- CKA 試験は 2 時間・Performance-based(実技)・合格 66%・Killer.sh 模擬試験 2 回付属。試験中は kubernetes.io/docs を参照できる
- D5(Troubleshooting)は配点 30% の最重要ドメイン。後半 4 回(第13〜16回)に集中配分している
- kubeadm は K8s 公式ブートストラップツール。主要サブコマンドは init / join / upgrade / reset / token / certs。CNI / StorageClass / LoadBalancer は別途導入が必要
/etc/kubernetes/manifests/(Static Pod)と/etc/kubernetes/admin.conf(kubeconfig)が CKA 標準パス。第2回以降で繰り返し登場する- kubeadm を選ぶ 3 つの理由:CKA 試験直結・クラスタアーキテクチャの透明性・標準パスが試験に直結
- 第2巻は 9 VM 構成(第1巻継続 3 VM + 新規 6 VM)。第2回から k8s-lb + k8s-cp-01 の追加が始まる
次回(第2回)では、いよいよ kubeadm によるクラスタ構築が始まります。pkgs.k8s.io からの kubeadm / kubelet / kubectl v1.35.x インストール・containerd の SystemdCgroup 設定・kubeadm init によるシングルノードクラスタ起動・Calico CNI インストールまでを一気に進めます。alma-proxy の whitelist に pkgs.k8s.io と Calico のドキュメント配信元 projectcalico.docs.tigera.io を追加する作業も含みます。第2回完了後に kubectl get nodes が成功する瞬間が、kubeadm 学習の最初の達成感になります。
第2巻 16 回を通じて身につく力を整理します。これらのスキルは CKA 試験だけでなく、実際のクラスタ管理業務でも使えます。
| スキルカテゴリ | 具体的な能力 | 対応ドメイン |
|---|---|---|
| クラスタ構築 | kubeadm で HA クラスタをゼロから構築できる | D1(25%) |
| クラスタ運用 | etcd backup/restore・証明書管理・バージョンアップができる | D1(25%) |
| ワークロード管理 | taint/toleration/affinity・HPA・ResourceQuota を設定できる | D2(15%) |
| ネットワーク管理 | NetworkPolicy・CoreDNS・Gateway API を設計・修復できる | D3(20%) |
| ストレージ管理 | PV/PVC/StorageClass・Longhorn での分散ストレージを構築できる | D4(10%) |
| 障害診断・復旧 | CP 障害・etcd 障害・Node 障害・Network 障害を診断して復旧できる | D5(30%) |
これらの能力は CKA 試験対策としてだけでなく、実際のクラスタ管理業務でも直接使えます。第2巻を完走した時点で「クラスタを自分で作り・動かし続ける」という管理者としての基本的な力が身についた状態になります。
現場ヒヤリハット — CKAD 合格後に CKA を甘く見て時間切れになるパターン
CKAD に合格した後、「CKA も同じ感覚で行けるだろう」と想定して試験に臨み、時間内に終わらないケースがあります。
CKAD と CKA の最大の違いは D5(Troubleshooting)が配点 30% を占める点です。CKAD では壊れたクラスタを直す問題はほぼ出ませんが、CKA では Control Plane コンポーネントの障害復旧・etcd バックアップ・kubelet が起動しないノードの修復といった「クラスタ管理者にしか分からない問題」が出題されます。
また kubeadm の実操作(kubeadm init でのクラスタ構築・kubeadm upgrade apply でのアップグレード)は CKAD には出題されません。試験中に初めて kubeadm init を打つ、という状態では合格は難しいです。
時間切れのもう一つの原因として、「kubectl config use-context の切り忘れ」があります。CKA 試験では複数クラスタを扱うため、問題ごとにコンテキストを切り替える必要があります。切り忘れると全く別のクラスタを操作してしまい、時間を無駄にします。第2巻の演習では複数コンテキストを意識した操作を習慣づけます。
対策は「手順を体に染み込ませる」ことです。第2巻の 16 回で kubeadm init から始まる一連の操作を繰り返します。特に Killer.sh 模擬試験は本番より難易度が高いため、解けなかった問題を徹底的に復習することが CKA 合格への最短経路になります。
学習時間の目安についても触れます。第2巻は全 16 回で構成されています。1 回あたりの演習時間は 2〜3 時間を目安にしてください。特に第2・4・5・6・15・16回はコマンドの入力量が多く、慣れるまでは 3〜4 時間かかることもあります。Killer.sh の模擬試験は 2 時間のセッションを丸ごと使う前提で時間を確保してください。第2巻完走まで 40〜60 時間の学習時間を目安とします。
理解度チェック(○×形式・6問)
以下の 6 問に○か×で答えてください。答えと解説は下に記載しています。
問1:CKA 試験は択一式(多肢選択)形式である
問2:kubeadm upgrade を実行するだけでクラスタのアップグレードが完結する
問3:kubeadm が構築するクラスタには Calico CNI が最初から含まれる
問4:CKA 試験中は kubernetes.io/docs を参照できる
問5:/etc/kubernetes/manifests/ は kubeadm が Static Pod manifest を配置するディレクトリである
問6:D5(Troubleshooting)は CKA 5 ドメインの中で配点が最も高い
— 答えと解説 —
問1:× — CKA は Performance-based の実技試験です。ブラウザ端末で kubectl / kubeadm を直接操作して問題を解きます。択一式(多肢選択)は KCNA / KCSA が該当します。
問2:× — kubeadm upgrade plan → kubeadm upgrade apply でコントロールプレーンはアップグレードできますが、各ノードの drain / kubelet アップグレード / uncordon も必要です。本シリーズの OS は AlmaLinux 10.1 のため、ノードのアップグレードは kubeadm upgrade node でノード設定を更新し、dnf で kubelet パッケージを更新(versionlock の一時解除が必要)し、systemctl restart kubelet で再起動する流れになります。詳細は第6回で扱います。
問3:× — kubeadm が作るクラスタには CNI は含まれません。CNI は別途 kubectl apply でインストールが必要です。CNI なしではノードが NotReady のままになります。第2回で Calico をインストールします。
問4:○ — CKA 試験中は kubernetes.io/docs と github.com/kubernetes の参照が許可されています。コマンドのオプションやマニフェストの書き方は公式ドキュメントを参照しながら解けます。
問5:○ — kubeadm は Control Plane コンポーネント(kube-apiserver / etcd / kube-controller-manager / kube-scheduler)の Static Pod manifest をこのディレクトリに配置します。kubelet がこのディレクトリを監視して Pod を自動起動します。
問6:○ — D5(Troubleshooting)は 30% で、5 ドメイン中最大の配点です。D1(25%)・D3(20%)・D2(15%)・D4(10%)と続きます。第2巻後半 4 回がこのドメインに集中配分されています。
シリーズ一覧
第1部:クラスタ構築
- 第1回 第2巻スコープ + CKA 試験形式紹介 + kubeadm 概要 + kubeadm vs RKE2/k0s/OKD 概観 ← 今ここ
- 第2回 kubeadm シングルノード起動(pkgs.k8s.io + kubeadm init + Calico CNI)+ alma-proxy whitelist 構築
- 第3回 kubeadm HA 設計 + HAProxy LB(API Server LB 構成)
- 第4回 kubeadm HA クラスタ構築(CP×3 + WL×2)+ fanclub-api HA 移行
- 第5回 etcd backup/restore(etcdutl)+ ノード drain/uncordon
第2部:ワークロード管理
- 第6回 kubeadm upgrade + ノード drain/cordon + ミニトラブルシュート演習
- 第7回 Pod スケジューリング(taint/toleration/affinity/anti-affinity/PriorityClass)
- 第8回 HPA + ResourceQuota + LimitRange
第3部:ネットワーク
- 第9回 Service 詳細 + MetalLB(LoadBalancer 動作確認)
- 第10回 NetworkPolicy 詳細 + Calico/Cilium 比較 + ミニトラブルシュート演習
- 第11回 Gateway API + Traefik + cert-manager + CoreDNS(HTTPS 公開完成)
第4部:ストレージ
第5部:監視・運用
- 第13回 Prometheus + Grafana + Loki + Fluent Bit + fanclub-api 監視ダッシュボード
- 第14回 Helm + Kustomize でクラスタコンポーネント install + ArgoCD GitOps + Velero backup
