
新卒インフラエンジニア向け Kubernetes 実践教科書(第2巻 CKA 編)の第8回です。動作確認バージョン: AlmaLinux 10.1 / K8s v1.35.5 / metrics-server v0.8.1 / kubeadm v1.35.5(2026-05-24 時点)
- 今ここマップ(第8回 / 全16回 / 第2部完走)
- 第8回のスコープと設計判断 — 3 つの Namespace で安全に演習する
- metrics-server とは — HPA と kubectl top の前提コンポーネント
- HPA v2 の仕組みと spec.metrics のリソースタイプ
- ResourceQuota の使い方 — Namespace 全体のリソース上限を管理する
- LimitRange の使い方 — Pod・コンテナ単位のデフォルトリソース制限
- やってみよう①: metrics-server インストール(kubeadm 対応版)
- やってみよう②: HPA で php-apache をスケールアウトさせる
- Step 1: hpa-demo Namespace の作成
- Step 2: php-apache Deployment と Service の作成
- Step 3: HPA の作成(autoscaling/v2・CPU 50%)
- Step 4: load-generator を起動して負荷をかける
- Step 5: HPA の変化を観察する
- Step 5 補足: kubectl describe hpa でスケーリング状態を詳しく確認する
- Step 6: load-generator を停止してスケールダウンを観察する
- Step 7: hpa-demo Namespace を削除してクリーンアップ
- 演習②の振り返り
- やってみよう③: ResourceQuota + LimitRange で Namespace リソース制御
- Step 1: quota-demo Namespace の作成
- Step 2: ResourceQuota の適用
- Step 3: LimitRange の適用
- Step 4: 正常 Pod の作成確認(requests/limits 明示指定)
- Step 5: 上限超過 Pod の作成拒否確認
- Step 6: requests 未指定 Pod への LimitRange デフォルト値付与確認
- Step 6 補足: LimitRange の max を超えた場合の動作確認
- Step 7: ResourceQuota の最終使用量確認
- Step 8: quota-demo Namespace を削除してクリーンアップ
- 演習③の振り返り
- まとめ・現場ヒヤリハット・理解度チェック
- シリーズ一覧
今ここマップ(第8回 / 全16回 / 第2部完走)
今ここ: 第8回 / 全16回(第2部:ワークロード管理)
▓▓▓▓▓▓▓▓░░░░░░░░ 50%
第1部(クラスタ構築): ■■■■■ 5/5 回(完了)
第2部(ワークロード管理): ■■■ 3/3 回(完了)← 今ここ
第3部(ネットワーク): □□□ 0/3 回
第4部(ストレージ): □ 0/1 回
第5部(監視・運用): □□ 0/2 回
第6部(トラブルシュート): □□ 0/2 回第7回では taint/toleration・nodeAffinity・podAntiAffinity・PriorityClass による Pod スケジューリングを完走しました。第8回は CKA D2「Workloads and Scheduling」の後半——リソース管理の 3 つのコンポーネント(metrics-server / HPA / ResourceQuota + LimitRange)を扱います。なお kubectl v1.35 では kubectl autoscale --cpu-percent フラグが deprecated(廃止予告)状態のため、本回演習では --cpu='70%' 形式での指定を推奨します。
「Pod が CPU 使用率によって自動的に増減する」「Namespace に CPU・メモリの上限を設ける」という 2 つの要求は、本番クラスタ運用で必ず直面する課題です。今回は実機で確認することで理解を定着させます。
第8回は第2部「ワークロード管理」の最終回です。第8回を終えると第2部 3 回(第6〜8回)が完了し、進捗が 50% に達します。
本回の 3 演習は独立した Namespace で実施します。既存の fanclub-api(fanclub Namespace)には一切触れません。演習①の metrics-server インストールだけは全クラスタ共通で kube-system Namespace に適用されますが、これは第9回以降でも継続利用する前提コンポーネントです。
第8回終了時の達成状態:
kubectl top nodes/kubectl top podsが動作する(metrics-server インストール済み)- php-apache に HPA を設定し、
kubectl run load-generatorで負荷をかけてレプリカが自動増加することを実機で確認できた kubectl describe hpaで TARGETS(現在 CPU% / ターゲット%)と REPLICAS の変化を読み取れるquota-demoNamespace に ResourceQuota を設定し、超過 Pod がForbiddenで拒否されることを確認できた- LimitRange で requests/limits のデフォルト値が自動付与されることを確認できた
第8回のスコープと設計判断 — 3 つの Namespace で安全に演習する
本セクションでは、第8回の学習内容と演習設計の判断背景を説明します。「何を学ぶか」と同時に「なぜこの設計にしたか」を理解することで、実務での同様の判断に応用できます。
第8回で「やること」と「やらないこと」
| やること | やらないこと |
|---|---|
| metrics-server インストール(全クラスタ共通) | metrics-server の TLS 正式設定(本番向け・別途学習) |
| HPA(CPU ベース・autoscaling/v2) | カスタムメトリクス HPA(Prometheus Adapter 等) |
| ResourceQuota(CPU/メモリ/Pod 数上限) | ResourceQuota の scope 全種(Terminating/BestEffort 等) |
| LimitRange(Container type・default/max/min) | LimitRange の Pod type / PVC type |
| 全演習を専用 Namespace で実施・終了時削除 | fanclub-api Deployment の変更 |
演習 Namespace の設計
今回の演習は 2 つの専用 Namespace を使います。既存の fanclub Namespace(fanclub-api 稼働中)には一切触れません。
| Namespace | 役割 | 削除タイミング |
|---|---|---|
hpa-demo | HPA 演習(php-apache + load-generator) | 演習②完了後に削除 |
quota-demo | ResourceQuota + LimitRange 演習 | 演習③完了後に削除 |
fanclub(既存) | fanclub-api 稼働中・変更なし | 変更なし |
設計判断の背景
判断① HPA 演習は php-apache 公式デモで実施する
HPA 演習を hpa-demo Namespace に新規作成する php-apache(公式デモイメージ registry.k8s.io/hpa-example)で実施します。fanclub-api には一切触れません。registry.k8s.io/hpa-example は kubernetes.io 公式ウォークスルーで使われる標準デモ Deployment であり、CKA 試験準備として最適です。php-apache は CPU 負荷を受け付けやすい設計で、負荷生成の動作確認が容易です。
判断② ResourceQuota / LimitRange 演習は quota-demo Namespace で実施する
ResourceQuota と LimitRange の演習は quota-demo Namespace 内で実施します。演習③完了後に kubectl delete namespace quota-demo で完全クリーンアップします。Namespace 削除 1 コマンドでクリーンアップが完結し、第9回以降の演習環境を汚染しません。
判断③ 負荷生成は kubectl run busybox ループを使う
負荷生成は kubectl run load-generator + busybox:1.28 ループを使います。CKA 試験で kubectl run + busybox + ループが標準的な負荷生成パターンです。--rm オプションで演習終了後に Pod が自動削除されるため、手動クリーンアップが不要です。
第8回終了時点の各 VM 状態
| VM | 第8回終了時の状態 |
|---|---|
| k8s-cp-01〜03 | 変更なし(metrics-server Pod が kube-system で稼働) |
| k8s-wl-01〜02 | 変更なし(fanclub-api 稼働継続) |
| k8s-ops | hpa-demo / quota-demo Namespace 削除済み |
metrics-server は kube-system Namespace にインストールされるため、演習クリーンアップ後も残存します。第9回以降の kubectl top で継続利用できます。
metrics-server とは — HPA と kubectl top の前提コンポーネント
metrics-server は Kubernetes クラスタ内のリソース使用量(CPU・メモリ)をリアルタイムに収集して Metrics API として提供するコンポーネントです。kubectl top nodes / kubectl top pods の動作、そして HPA のスケーリング判断は、いずれも metrics-server が提供する Metrics API に依存しています。
Kubernetes の指標収集アーキテクチャ
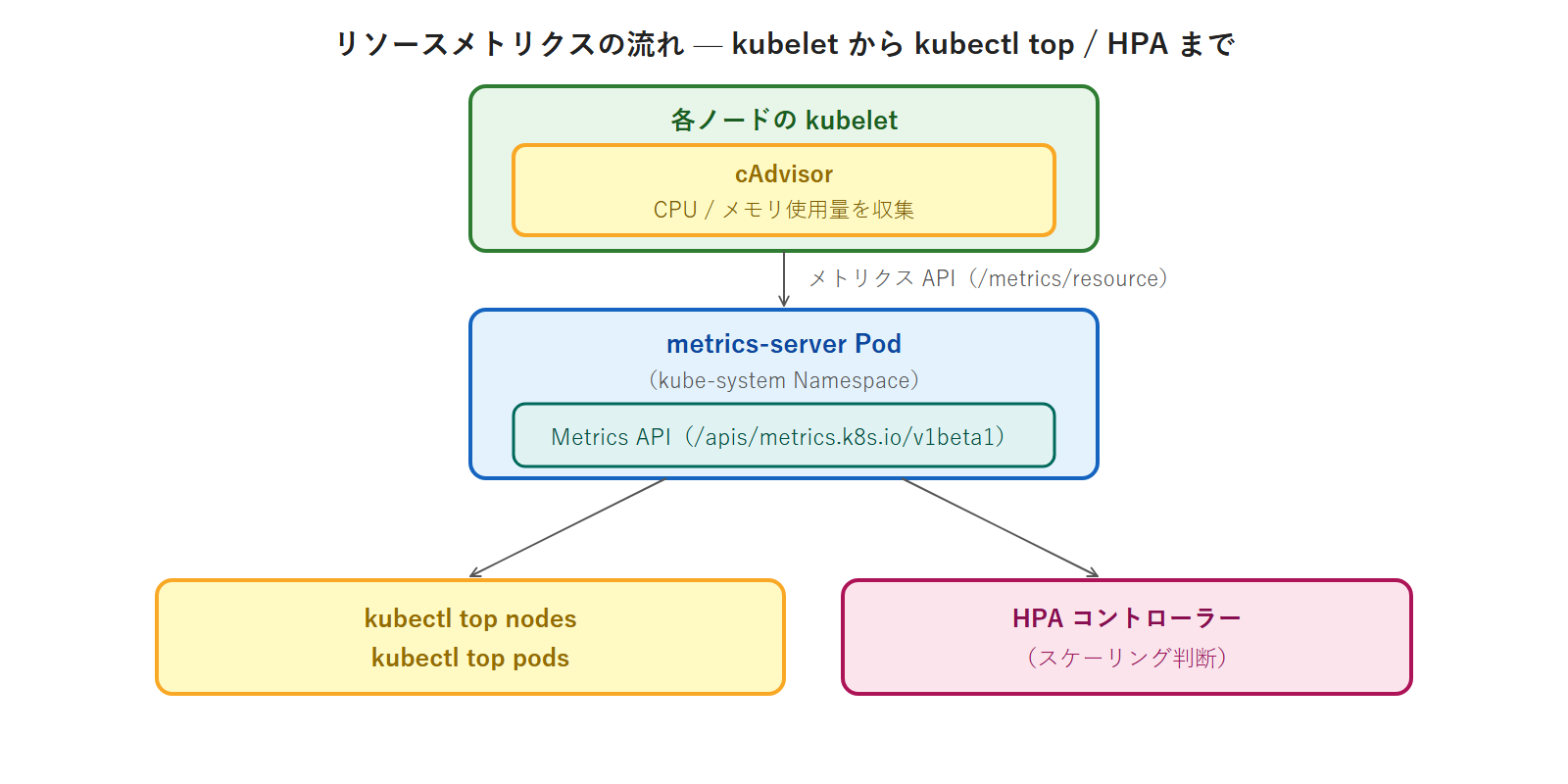
各ノードの kubelet に組み込まれた cAdvisor が CPU・メモリの使用量を収集し、metrics-server がそれを集約して Metrics API として公開します。HPA コントローラーはこの Metrics API を 15 秒間隔でポーリングして Pod のスケール数を決定します。
kubeadm 環境では metrics-server が未インストール
kubeadm はクラスタの基盤(kube-apiserver / etcd / scheduler / controller-manager / kube-proxy / CoreDNS)のみを構築します。metrics-server はクラスタに含まれないため、別途インストールが必要です。
metrics-server が未インストールの状態で kubectl top nodes を実行すると、次のエラーが返ります。
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)Metrics API(/apis/metrics.k8s.io/v1beta1)を提供するコンポーネントが存在しないため、API サーバーが「サービス利用不可」と応答します。このエラーは metrics-server をインストールすることで解消されます。
kubelet TLS の問題と解決策
kubeadm 環境では kubelet が自己署名 TLS 証明書を使用します。metrics-server はデフォルトで kubelet の TLS 証明書を検証しようとするため、証明書検証エラーが発生します。
| 状況 | 説明 |
|---|---|
| kubeadm デフォルト | kubelet は自己署名証明書を使用(CA に署名されていない) |
| metrics-server のデフォルト動作 | kubelet TLS 証明書を検証しようとする → x509 エラー |
| 解決策(検証環境) | --kubelet-insecure-tls フラグでスキップ |
| 解決策(本番環境) | kubelet に適切な CA 署名証明書を配布 |
本番環境での metrics-server は --kubelet-insecure-tls を使わない
このフラグは中間者攻撃への脆弱性を招きます。本番環境では kubelet の TLS 証明書を Kubernetes クラスタ CA で署名し、metrics-server が正規の証明書検証を行うよう設定してください。本回の演習設定はあくまで検証・学習目的の設定です。
–kubelet-preferred-address-types の役割
components.yaml の Deployment args には --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname が含まれています。これは metrics-server が kubelet に接続する際のアドレス解決順序を指定するフラグです。
InternalIP → ExternalIP → Hostname の順で kubelet のアドレスを解決するkubeadm 環境では外部 IP を持たないオンプレ構成のため、InternalIP が優先されます。この設定はデフォルトのまま変更不要です。
metrics-server のバージョンと Kubernetes 対応
本回で使用する metrics-server は v0.8.1(2025-01-29 リリース・Go v1.24.12)です。v0.8.x は Kubernetes 1.31 以上に対応しており、本巻の K8s v1.35 では問題なく動作します。
Metrics API と Resource Metrics Pipeline の関係
Kubernetes のメトリクス収集には 2 つのパイプラインが存在します。
| パイプライン | 提供 API | 目的 | コンポーネント例 |
|---|---|---|---|
| Resource Metrics Pipeline | /apis/metrics.k8s.io/v1beta1 | CPU/メモリの現在値(HPA / kubectl top 用) | metrics-server |
| Custom Metrics Pipeline | /apis/custom.metrics.k8s.io/v1beta2 | アプリ固有のメトリクス(HTTP req/s 等) | Prometheus Adapter |
本回で扱うのは Resource Metrics Pipeline(metrics-server)のみです。Prometheus Adapter を使ったカスタムメトリクス HPA は CKA の試験範囲外であり、第3巻(CKS 巻)の応用トピックとして扱います。
Resource Metrics Pipeline の特徴は「短期間の現在値のみを保持する」ことです。metrics-server はデフォルト 15 秒間隔でデータを収集しますが、過去の履歴を保持しません。長期的なメトリクス保存・分析には Prometheus が必要です(第2巻第13回で扱います)。
インストール方式の比較(components.yaml vs Helm chart)
metrics-server のインストール方法は 2 種類あります。本回では CKA 試験の kubectl apply ベースに合わせて components.yaml 方式を採用します。
| 方式 | コマンド例 | 本回での採用 | 理由 |
|---|---|---|---|
| components.yaml | kubectl apply -f components.yaml | ○(採用) | CKA 試験は kubectl apply ベース・手順がシンプル |
| Helm chart | helm install metrics-server metrics-server/metrics-server --version X.X.X | ✗(本回は不採用) | Helm を使う場合はバージョンピン留めが必要 |
実務では Helm chart でのインストールが管理しやすいケースもありますが、CKA 試験環境は Helm が利用できない場合もあるため、kubectl apply による YAML 操作を習得しておくことが重要です。
kubectl top の出力を読む
metrics-server インストール後に利用できる kubectl top コマンドの出力の読み方を整理します。
kubectl top nodes の出力:
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-cp-01 150m 3% 1024Mi 25%
k8s-wl-01 200m 5% 1500Mi 18%CPU(cores): 現在の CPU 消費量(ミリコア単位)。1000m = 1 コアCPU%: ノードの総 CPU キャパシティに対する利用率MEMORY(bytes): 現在のメモリ消費量(MiB 単位)MEMORY%: ノードの総メモリキャパシティに対する利用率
kubectl top pods の出力:
NAME CPU(cores) MEMORY(bytes)
php-apache-6d4bfd5786-z9kpx 436m 20MiCPU(cores): Pod 内の全コンテナの CPU 消費量の合計MEMORY(bytes): Pod 内の全コンテナのメモリ消費量の合計(RSS ベース)
kubectl top pods -A で全 Namespace の Pod を確認できます。特定 Namespace だけ確認したい場合は kubectl top pods -n <namespace> を使います。--sort-by=cpu または --sort-by=memory オプションを追加すると、CPU またはメモリ使用量の多い順にソートされます。
実行コマンド:
$ kubectl top pods -A --sort-by=cpu実行結果:
NAMESPACE NAME CPU(cores) MEMORY(bytes)
fanclub fanclub-api-fanclub-api-bbbfdf9bf-xk2pq 10m 128Mi
fanclub fanclub-api-fanclub-api-bbbfdf9bf-zk9xt 9m 124Mi
kube-system calico-node-4xvnk 8m 80Mi
kube-system metrics-server-7c66d7b9d6-8jxpz 7m 16Mi
kube-system coredns-5d78c9d5f-7q8rp 5m 20MiCPU 消費量の多い Pod が上位に表示されます。トラブルシュート時の「どの Pod が CPU を食っているか」の調査で活用できます。
HPA v2 の仕組みと spec.metrics のリソースタイプ
HPA(HorizontalPodAutoscaler)は Deployment / ReplicaSet のレプリカ数を、メトリクスの値に応じて自動で増減させる Kubernetes のコンポーネントです。CPU 使用率が高くなれば Pod を増やし、低くなれば Pod を減らすことで、負荷変動に対応した自動スケーリングを実現します。
HPA のスケーリングサイクル

HPA コントローラーは Metrics API から現在の CPU 使用率を取得し、「現在のレプリカ数 × (現在 CPU% / ターゲット CPU%)」の計算式で目標レプリカ数(desiredReplicas)を算出します。算出した値が minReplicas を下回れば minReplicas に、maxReplicas を上回れば maxReplicas にクランプされます。
具体例: 現在 1 レプリカ、CPU 使用率 218%、ターゲット 50% の場合
desiredReplicas = ceil(1 × (218 / 50)) = ceil(4.36) = 5計算上は 5 ですが、maxReplicas 10 の範囲内なので 5 レプリカへのスケールアップが実行されます。
HPA の評価間隔と制御パラメータ
HPA コントローラーはデフォルト 15 秒間隔(--horizontal-pod-autoscaler-sync-period)でメトリクスを評価します。ただし、実際にスケーリングが発生するまでには複数の間隔をまたぐことがあります。
| パラメータ | デフォルト値 | 意味 |
|---|---|---|
| 評価間隔(sync-period) | 15 秒 | HPA コントローラーがメトリクスを取得・評価する間隔 |
| スケールアップ stabilizationWindowSeconds | 0 秒 | スケールアップは即時実行 |
| スケールダウン stabilizationWindowSeconds | 300 秒(5 分) | 5 分間の安定を確認してからスケールダウン |
| Pods type ポリシー(scaleUp) | 4 Pods/60s | 60 秒あたり最大 4 Pod 増加 |
| Percent type ポリシー(scaleUp) | 100%/60s | 60 秒あたり最大 100% 増加(2 倍) |
スケールアップのデフォルトポリシーでは「60 秒あたり 4 Pod 増加」と「60 秒あたり 100% 増加(2 倍)」のうち大きい方が選ばれます(selectPolicy: Max)。1 レプリカから始まると 60 秒で最大 2 レプリカ(100% 増加)に、次の 60 秒でさらに最大 4 レプリカに増加します。maxReplicas の範囲内で段階的に増加します。
spec.metrics の 5 種類
HPA v2 の spec.metrics では 5 種類のメトリクスタイプを指定できます。CKA 試験で必ず習得が必要なのは Resource タイプです。
| type | 基準となるメトリクス | 典型例 | CKA 試験重要度 |
|---|---|---|---|
| Resource | Pod の CPU/メモリ requests に対する利用率 | CPU 50% | 最重要(頻出) |
| Pods | Pod ごとのカスタムメトリクス | HTTP req/sec | 概念理解のみ |
| Object | K8s オブジェクトのメトリクス | Ingress req/sec | 概念理解のみ |
| External | クラスタ外のメトリクス | CloudWatch キュー深さ | 概念理解のみ |
| ContainerResource | 特定コンテナの CPU/メモリ | Sidecar CPU | 参考程度 |
Resource タイプは Pod の resources.requests.cpu(または resources.requests.memory)を基準値として、現在の使用量との比率(利用率)でスケーリングを判断します。このため、スケール対象の Pod に resources.requests.cpu が設定されていることが HPA 動作の前提条件です。
HPA v2 マニフェストの構造
本回演習で使用する php-apache 用の HPA v2 マニフェストです。各フィールドの意味を確認してください。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: hpa-demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50scaleTargetRef: スケール対象の Deployment を指定。apiVersion: apps/v1を必ず明記するminReplicas: スケールダウン時の最小レプリカ数。負荷がゼロでもこの数以下にはならないmaxReplicas: スケールアップ時の最大レプリカ数。コスト制御の上限として機能するmetrics[].type: Resource: CPU/メモリの利用率を基準とするaverageUtilization: 50: 全 Pod の平均 CPU 利用率が requests に対して 50% を超えたらスケールアップ
behavior フィールドによるスケーリング挙動の制御
HPA v2 では spec.behavior フィールドでスケールアップ・スケールダウンの挙動を細かく制御できます。デフォルト値を理解しておくことが CKA 試験でも重要です。
| フィールド | scaleUp デフォルト | scaleDown デフォルト | 実務的意味 |
|---|---|---|---|
stabilizationWindowSeconds | 0 秒(即時) | 300 秒(5 分) | スケールダウンの急激な変動を防ぐ安定化ウィンドウ |
selectPolicy | Max(最大増加) | Min(最小削減) | 安全側に倒す設計 |
スケールダウンのデフォルト安定化ウィンドウが 300 秒(5 分)であることは重要です。負荷が下がってもすぐにレプリカが減少しない理由がこれです。フラッピング(急激な増減の繰り返し)を防ぐための設計です。
autoscaling/v2 と autoscaling/v1 の違い
autoscaling/v1 は CPU のみ対応・behavior フィールドなしの旧バージョンです。autoscaling/v2 は K8s v1.23 で安定(Stable)となり、現在は v2 が標準です。CKA 試験では autoscaling/v2 の記述が求められます。kubectl get hpa -o yaml で確認すると autoscaling/v1 形式で表示される場合がありますが、これは後方互換 API であり実体は v2 として動作します。
HPA が動作するための前提条件
- metrics-server がインストール済みであること(Metrics API が利用可能な状態)
- スケール対象の Pod に
resources.requests.cpuが設定されていること(未設定の場合 HPA は計算できない) - HPA の
scaleTargetRefの name と Deployment の名前が一致していること
HPA のスケーリング計算を詳しく理解する
HPA のスケーリング計算式は一見シンプルですが、実際の動作を理解するためにいくつかの具体例を確認します。
設定: minReplicas=1 / maxReplicas=10 / targetAverageUtilization=50%
| 現在のレプリカ数 | 現在の平均 CPU 利用率 | 計算式 | desiredReplicas(計算値) | クランプ後 | アクション |
|---|---|---|---|---|---|
| 1 | 0% | ceil(1 × 0/50) = 0 | 0 | 1(minReplicas) | 変更なし |
| 1 | 218% | ceil(1 × 218/50) = 5 | 5 | 5 | スケールアップ 1→5 |
| 7 | 48% | ceil(7 × 48/50) = 7 | 7 | 7 | 変更なし(安定) |
| 7 | 0%(負荷停止後) | ceil(7 × 0/50) = 0 | 0 | 1(minReplicas) | スケールダウン 7→1(5分後) |
この計算式から、ターゲット利用率を低く設定すると必要なレプリカ数が多くなることがわかります。例えば targetAverageUtilization を 20% に設定した場合、CPU 60% の負荷に対して ceil(1 × 60/20) = 3 レプリカが必要と計算されます。ターゲット利用率は CPU のバースト余裕を考慮して 50〜70% が一般的な設定です。
kubectl describe hpa の出力を読む
HPA のトラブルシュート時に kubectl describe hpa の出力を読めることが重要です。
Name: php-apache
Namespace: hpa-demo
Labels: <none>
Annotations: <none>
CreationTimestamp: Sun, 24 May 2026 10:00:00 +0900
Reference: Deployment/php-apache
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 218% (436m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 5 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 5
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SucceededRescale 2m horizontal-pod-autoscaler New size: 5; reason: cpu resource utilization (percentage of request) above targetMetrics行: 現在の CPU 利用率(218%)とターゲット(50%)が確認できる。218% とはリクエスト(200m)に対して 436m(= 200m × 2.18)消費していることを意味するConditions: HPA の動作状態を確認できる。ScalingActiveがTrueなら Metrics API からデータを正常取得しているEvents: スケーリングが実行されたタイミングと理由が記録される。トラブルシュート時は Events を最初に確認する
HPA がスケーリングしない場合の診断フロー

ResourceQuota の使い方 — Namespace 全体のリソース上限を管理する
ResourceQuota は Namespace 単位でリソースの上限を設定するオブジェクトです。マルチテナント環境において、特定の Namespace が過剰なリソースを消費して他の Namespace に影響を与えることを防ぎます。
ResourceQuota の動作イメージ

ResourceQuota は Namespace への新しい Pod 作成リクエストを受けた際に、現在の使用量(Used)が上限(Hard)を超えないかをチェックします。超過する場合は Forbidden エラーで作成を拒否します。
主要フィールドの一覧
| フィールド | 意味 | 本回で使う |
|---|---|---|
requests.cpu | Namespace 全体の CPU requests 合計上限 | ○ |
requests.memory | Namespace 全体のメモリ requests 合計上限 | ○ |
limits.cpu | Namespace 全体の CPU limits 合計上限 | ○ |
limits.memory | Namespace 全体のメモリ limits 合計上限 | ○ |
pods | Pod 総数上限(状態に関わらず全 Pod を対象) | ○ |
persistentvolumeclaims | PVC 総数上限 | 説明のみ |
services / services.nodeports | Service / NodePort Service 数上限 | 説明のみ |
count/deployments.apps | Deployment 数上限 | 説明のみ |
scope(スコープ)の概念
ResourceQuota には scopes フィールドで適用対象の Pod を絞り込む機能があります。CKA 試験でよく出題されるスコープを確認してください。
| scope | 対象 Pod | 主な使いどころ |
|---|---|---|
BestEffort | requests/limits 未設定の Pod | BestEffort Pod 数だけを制限したい場合 |
NotBestEffort | requests/limits 設定済みの Pod | 一般的な本番ワークロードの上限設定 |
Terminating | activeDeadlineSeconds 設定 Pod | Job / CronJob のリソース上限 |
NotTerminating | activeDeadlineSeconds なし Pod | 常時稼働型アプリの上限設定 |
scopes を指定しない場合はすべての Pod に適用されます(本回演習のパターン)。
本回演習で使う ResourceQuota マニフェスト
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
namespace: quota-demo
spec:
hard:
requests.cpu: "1"
requests.memory: "1Gi"
limits.cpu: "2"
limits.memory: "2Gi"
pods: "5"このマニフェストでは quota-demo Namespace 全体に対して、CPU requests の合計を 1 コア以内、メモリ requests の合計を 1Gi 以内、Pod 総数を 5 個以内に制限します。
ResourceQuota の状態確認コマンド
kubectl describe resourcequota で Hard(上限)と Used(現在使用量)を確認できます。
Name: compute-quota
Namespace: quota-demo
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
pods 0 5
requests.cpu 0 1
requests.memory 0 1GiPod を作成するたびに Used の値が増加します。Used が Hard に近づいたら新規 Pod 作成が拒否される前兆であるため、kubectl describe resourcequota で定期的に確認する習慣が重要です。
ResourceQuota が適用されるタイミングと注意点
ResourceQuota は「Pod 作成時のアドミッションコントロール段階」で評価されます。既存の稼働中 Pod には遡及適用されません。これは LimitRange と同様の動作です。
| タイミング | ResourceQuota の動作 |
|---|---|
| 新規 Pod 作成リクエスト | 現在の Used + 要求値 が Hard を超えないかチェック → 超過で拒否 |
| 既存稼働中 Pod | 影響なし(ResourceQuota 設定前から動いている Pod はそのまま) |
| Pod 削除 | Used から削除された Pod のリソース値が差し引かれる |
| Pod の OOMKilled / CrashLoop | Pod オブジェクトが存在する限り Used としてカウントされる |
「ResourceQuota を設定したら既存 Pod が消えてしまった」という事故は起きません。ただし既存 Pod が大量に resources を消費している状態で ResourceQuota を設定すると、新規 Pod の作成がすぐに拒否される可能性があります。新しい Namespace に ResourceQuota を設定する場合は、既存リソースの Used を確認してから Hard の値を決定してください。
ResourceQuota の確認コマンドと運用上の注意
ResourceQuota を運用する際によく使うコマンドを整理します。
kubectl get resourcequota -n <namespace>
→ Namespace 内のすべての ResourceQuota オブジェクトを一覧表示
kubectl describe resourcequota <name> -n <namespace>
→ Used / Hard を確認(最も重要な確認コマンド)
kubectl describe resourcequota -n <namespace>
→ Namespace 内のすべての ResourceQuota を describe で表示(複数ある場合に便利)本番運用での注意点を 2 点示します。
注意点①: ResourceQuota の Hard 値は余裕を持って設定する
Deployment の Rolling Update 時は一時的に Pod 数が増加します(maxSurge のデフォルトは 1 つ追加)。ResourceQuota の pods の Hard 値が現在の Pod 数ギリギリに設定されている場合、Rolling Update 中に新規 Pod の作成が拒否されてデプロイが停止する事態が発生します。Rolling Update を考慮して「通常運用の Pod 数 + maxSurge 分」の余裕を持った Hard 値を設定してください。
注意点②: Namespace を削除すると ResourceQuota も削除される
ResourceQuota は Namespace スコープのリソースです。kubectl delete namespace を実行すると、Namespace 内の ResourceQuota も一緒に削除されます。演習③のクリーンアップで kubectl delete namespace quota-demo を実行した際に ResourceQuota も一括削除されたのはこの理由です。
ResourceQuota の count/* 書式 — オブジェクト数の上限設定
ResourceQuota では CPU/メモリだけでなく、Kubernetes オブジェクトの数も制限できます。
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-quota
namespace: quota-demo
spec:
hard:
count/deployments.apps: "5"
count/services: "10"
count/configmaps: "20"
count/secrets: "20"
persistentvolumeclaims: "5"count/ プレフィックスを使うことで任意の Kubernetes オブジェクト種別の数を制限できます。マルチテナント環境で Namespace ごとに「Deployment は最大 5 個まで」のようなルールを設ける際に有効です。
LimitRange の使い方 — Pod・コンテナ単位のデフォルトリソース制限
LimitRange は個々の Pod・コンテナ・PVC に対してデフォルトのリソース値(requests/limits)を設定したり、許容範囲の上限・下限を定めたりするオブジェクトです。ResourceQuota が「Namespace 全体の合計上限」を管理するのに対し、LimitRange は「個々のリソースの上下限とデフォルト値」を管理します。
ResourceQuota と LimitRange の使い分け
| 観点 | ResourceQuota | LimitRange |
|---|---|---|
| 適用範囲 | Namespace 全体の合計 | 個々の Pod / コンテナ / PVC |
| 主な目的 | フェアな資源配分・上限設定 | デフォルト値の自動付与・逸脱防止 |
| requests なし Pod の扱い | ResourceQuota があると拒否される | LimitRange があれば自動付与される |
| 組み合わせ | ResourceQuota + LimitRange がセット推奨 | 単独でも有効 |
LimitRange の type 別フィールド
| type | default(limit) | defaultRequest(request) | max | min | maxLimitRequestRatio |
|---|---|---|---|---|---|
Container | ○ | ○ | ○ | ○ | ○ |
Pod | ✗ | ✗ | ○(Pod 全体の上限) | ○ | ✗ |
PersistentVolumeClaim | ✗ | ✗ | ○(ストレージ上限) | ○(ストレージ下限) | ✗ |
本回の演習では Container type を使います。default(limits のデフォルト)と defaultRequest(requests のデフォルト)を設定することで、requests/limits を指定しないコンテナにも自動でリソース制限が付与されます。
本回演習で使う LimitRange マニフェスト
apiVersion: v1
kind: LimitRange
metadata:
name: compute-limits
namespace: quota-demo
spec:
limits:
- type: Container
default:
cpu: 500m
memory: 512Mi
defaultRequest:
cpu: 100m
memory: 128Mi
max:
cpu: "1"
memory: 1Gi
min:
cpu: 50m
memory: 64Midefault: requests/limits を指定しないコンテナへの limits デフォルト値(CPU 500m / memory 512Mi)defaultRequest: requests を指定しないコンテナへの requests デフォルト値(CPU 100m / memory 128Mi)max: コンテナが指定できる limits の最大値。これを超えた limits を指定すると作成が拒否されるmin: コンテナが指定できる requests の最小値。これを下回ると作成が拒否される
LimitRange + ResourceQuota の組み合わせ効果
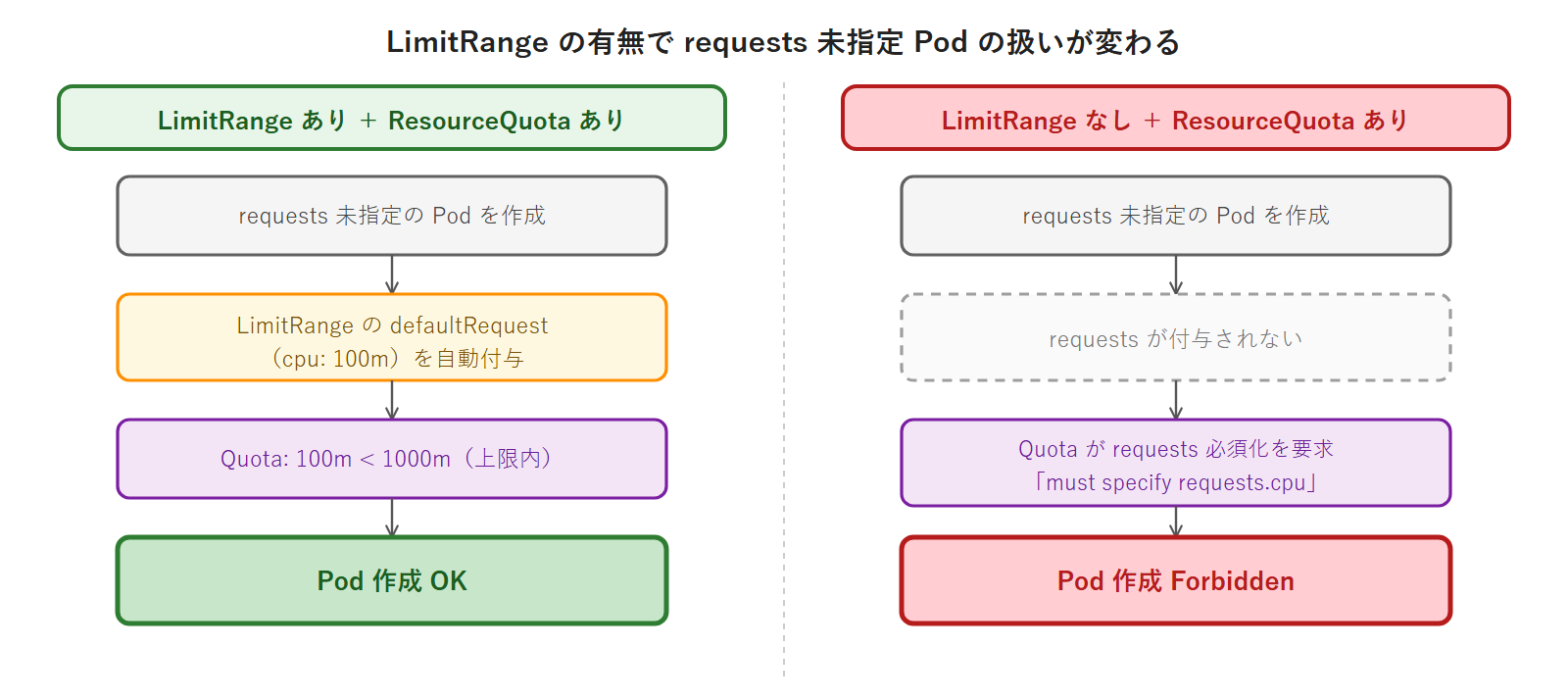
ResourceQuota に requests.cpu が設定されている Namespace では、Pod の resources.requests.cpu が必須になります。LimitRange を設定しておくことで requests 未指定 Pod にもデフォルト値が自動付与され、Pod が意図せず拒否される事態を防げます。
LimitRange と HPA の連携
HPA が CPU 使用率を計算する際、Pod の resources.requests.cpu を基準値として使用します。LimitRange の defaultRequest.cpu を設定しておくと、requests 未指定 Pod にも自動で値が付与されて HPA が正常動作します。ただし本回の HPA 演習(演習②)では php-apache に requests を明示指定するため、LimitRange への依存はありません。
LimitRange の maxLimitRequestRatio(比率制限)
LimitRange の maxLimitRequestRatio フィールドは、limits と requests の比率の上限を設定します。これは「limits が requests の何倍まで許容するか」を制御するフィールドです。
Kubernetes では requests はスケジューリングの保証値、limits はバースト時の上限値として動作します。requests を下回るリソース使用では他の Pod に影響せず、limits を超えると CPU はスロットリング・メモリは OOMKilled が発生します。この requests と limits の関係を理解しておくことが、適切な maxLimitRequestRatio 設定の前提です。
apiVersion: v1
kind: LimitRange
metadata:
name: ratio-limits
namespace: quota-demo
spec:
limits:
- type: Container
maxLimitRequestRatio:
cpu: 4この設定では limits.cpu / requests.cpu の比率が 4 を超えるコンテナは作成拒否されます。例えば requests.cpu: 100m の場合、limits.cpu は最大 400m(= 100m × 4)まで許容されます。500m を指定すると拒否されます。
この設定が有用な理由: requests はスケジューリングの基準値(実際に確保するリソース)、limits はバースト時の上限値です。limits/requests 比率が大きすぎると、ノードがオーバーコミット状態になり OOM(メモリ不足)が発生しやすくなります。maxLimitRequestRatio でバースト倍率を制限することで、ノードの安定性を維持できます。
LimitRange が適用されないケース
LimitRange にはいくつかの適用外ケースがあります。実務での誤解を防ぐために把握しておいてください。
| ケース | LimitRange の動作 | 備考 |
|---|---|---|
| 既存 Pod(LimitRange 設定前から稼働) | 適用されない(遡及なし) | 新規 Pod 作成時のみ評価される |
| 同じ Namespace に複数の LimitRange | すべての LimitRange が評価される(最も厳しい値が適用) | デフォルト値は非決定的になる可能性あり。1 つのみ推奨 |
| limits を明示した Pod | 明示値が使われる(LimitRange の default は無視) | max/min チェックは実施される |
| max を超える limits を指定 | 作成拒否(max cpu, 500m exceeded エラー) | Pod 作成時のアドミッションで検証 |
ResourceQuota があるのに Pod が作れない場合の確認手順
kubectl describe resourcequota で Hard と Used を確認します。Used が Hard に近い場合は Namespace のリソースが枯渇しています。次に kubectl describe pod <name> の Events を確認します。exceeded quota が表示されている場合はリソース上限超過、must specify requests が表示されている場合は LimitRange を設定して requests のデフォルト値を付与するか、Pod の requests を明示指定することで解決できます。
実務でよく使う LimitRange 設定パターン
本番環境の Namespace に設定する LimitRange のパターンを 2 つ示します。
パターン①: 軽量アプリ向け(フロントエンド・静的サイト等)
spec:
limits:
- type: Container
default:
cpu: 200m
memory: 256Mi
defaultRequest:
cpu: 50m
memory: 64Mi
max:
cpu: 500m
memory: 512Mi
min:
cpu: 10m
memory: 32Miパターン②: バックエンド API 向け(Java / Jakarta EE 等メモリ消費が多いアプリ)
spec:
limits:
- type: Container
default:
cpu: "1"
memory: 1Gi
defaultRequest:
cpu: 250m
memory: 512Mi
max:
cpu: "2"
memory: 2Gi
min:
cpu: 100m
memory: 256Mifanclub-api の Backend(Payara Micro + JDK 25)は Java プロセスのためメモリ消費が大きく、パターン②に近い設定が適しています。本回では演習の明確化のため quota-demo Namespace を使いましたが、将来的に fanclub Namespace に LimitRange を設定する場合はバックエンドのメモリ特性を考慮した値を設定してください。
やってみよう①: metrics-server インストール(kubeadm 対応版)
components.yaml に --kubelet-insecure-tls を追加して metrics-server をインストールし、kubectl top が動作することを確認します。
metrics-server のインストールは 1 回だけ実施します。インストール後は kube-system Namespace に常駐するため、演習②③が終わって各 Namespace を削除した後も metrics-server は残存します。
本演習の推定所要時間は 10〜15 分です。metrics-server Pod の起動に 30〜90 秒かかる点に注意してください。
作業場所: k8s-ops(developer ユーザー)
演習シナリオ:
① metrics-server が未インストールであることを確認(エラー確認)
② components.yaml をダウンロード
③ Deployment の args に --kubelet-insecure-tls を追加
④ kubectl apply で適用
⑤ metrics-server Pod の起動確認(Running 状態)
⑥ kubectl top nodes / kubectl top pods で動作確認Step 1: metrics-server 未インストールの確認
実行コマンド:
$ kubectl top nodes実行結果:
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)Metrics API が利用不可の状態であることを確認します。このエラーが表示されれば metrics-server 未インストールが確認できました。
Step 2: components.yaml をダウンロード
実行コマンド:
$ curl -L -O https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml実行結果:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 8529 100 8529 0 0 14238 0 --:--:-- --:--:-- --:--:-- 14259カレントディレクトリに components.yaml が作成されます。
Step 3: Deployment の args に –kubelet-insecure-tls を追加
まず現在の args セクションを確認します。
実行コマンド:
$ grep -A 10 "args:" components.yaml実行結果:
args:
- --cert-dir=/tmp
- --secure-port=10250
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15ssed コマンドで --metric-resolution=15s の行の後に --kubelet-insecure-tls を追加します。この sed は --metric-resolution=15s 行の先頭インデントをキャプチャ(\1)して、追加行に同じインデントを付与します。components.yaml は releases/latest のため upstream のバージョンによって args のインデント幅(8 スペース / 10 スペース等)が変わることがありますが、この書き方なら既存行と必ず同じインデントで挿入されるため、インデント不一致による --metric-resolution のパースエラー(metrics-server の CrashLoopBackOff)を避けられます。インデント幅を決め打ちで追記すると、ずれた場合に metrics-server Pod が invalid argument ... for "--metric-resolution" flag で起動しません。
実行コマンド:
$ sed -i -E 's|^([[:space:]]*)(- --metric-resolution=15s.*)$|\1\2\n\1- --kubelet-insecure-tls|' components.yaml実行結果:
(出力なし・正常終了)追加されたことを確認します。
実行コマンド:
$ grep -A 12 "args:" components.yaml実行結果:
args:
- --cert-dir=/tmp
- --secure-port=10250
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls--kubelet-insecure-tls が追加されていることを確認します。
Step 4: kubectl apply で適用
実行コマンド:
$ kubectl apply -f components.yaml実行結果:
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io createdServiceAccount・ClusterRole・ClusterRoleBinding・Service・Deployment・APIService の 9 リソースが作成されます。
Step 5: metrics-server Pod の起動確認
実行コマンド:
$ kubectl get pods -n kube-system -l k8s-app=metrics-server -w実行結果:
NAME READY STATUS RESTARTS AGE
metrics-server-7c66d7b9d6-8jxpz 0/1 Pending 0 5s
metrics-server-7c66d7b9d6-8jxpz 0/1 ContainerCreating 0 8s
metrics-server-7c66d7b9d6-8jxpz 1/1 Running 0 60sREADY が 1/1・STATUS が Running になったら Ctrl+C でウォッチを終了します。起動まで 30〜90 秒かかります。
Step 6: kubectl top で動作確認
実行コマンド:
$ kubectl top nodes実行結果:
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-cp-01 150m 3% 1024Mi 25%
k8s-cp-02 120m 3% 980Mi 24%
k8s-cp-03 130m 3% 1010Mi 25%
k8s-wl-01 200m 5% 1500Mi 18%
k8s-wl-02 180m 4% 1400Mi 17%実行コマンド:
$ kubectl top pods -A実行結果:
NAMESPACE NAME CPU(cores) MEMORY(bytes)
fanclub fanclub-api-fanclub-api-bbbfdf9bf-xk2pq 10m 128Mi
fanclub fanclub-api-fanclub-api-bbbfdf9bf-zk9xt 9m 124Mi
kube-system calico-node-4xvnk 20m 80Mi
kube-system coredns-5d78c9d5f-7q8rp 5m 20Mi
kube-system metrics-server-7c66d7b9d6-8jxpz 8m 16Mikubectl top が正常に動作し、fanclub Namespace の Pod も含めた全 Namespace のリソース使用状況が確認できました。
演習①の振り返り
- metrics-server をインストールする前後で
kubectl top nodesの挙動が変わることを確認した。インストール前はServiceUnavailableエラー、インストール後は正常にリソース使用量が表示される - kubeadm 環境では
--kubelet-insecure-tlsフラグなしでは metrics-server が起動してもx509エラーで Metrics API に応答できない。フラグ追加が必須ステップ kubectl get pods -n kube-system -l k8s-app=metrics-serverでラベルによる Pod の絞り込みができることを確認した- metrics-server は
kube-systemNamespace にインストールされる。演習 Namespace(hpa-demo/quota-demo)を削除した後も kube-system の metrics-server は残存し、第9回以降でもkubectl topを継続利用できる kubectl get apiservice v1beta1.metrics.k8s.ioで AVAILABLE がTrueになっていることを確認した。この APIService が Metrics API のエントリポイントとして機能しているkubectl top pods -A --sort-by=cpuのようなオプションを使ってリソース使用量の多い Pod を絞り込む方法を習得した
補足: APIService の確認
metrics-server のインストール時に作成された apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io は、Kubernetes API サーバーに Metrics API を登録するリソースです。この登録があることで、kubectl top や HPA が /apis/metrics.k8s.io/v1beta1 エンドポイントにアクセスできます。
実行コマンド:
$ kubectl get apiservice v1beta1.metrics.k8s.io実行結果:
NAME SERVICE AVAILABLE AGE
v1beta1.metrics.k8s.io kube-system/metrics-server True 5mAVAILABLE が True であれば Metrics API が正常に応答できる状態です。False の場合は metrics-server Pod のログを確認してください。
やってみよう②: HPA で php-apache をスケールアウトさせる
php-apache Deployment に HPA v2 を設定し、kubectl run で負荷をかけてレプリカが自動増加することを実機で確認します。負荷停止後のスケールダウンも観察します。
作業場所: k8s-ops(developer ユーザー)
推定所要時間: 20〜30 分(スケールダウン待ち 5 分を含む)
注意事項: Step 4 の kubectl run -it load-generator コマンドは対話型シェルを起動します。HPA の変化観察(Step 5)は別のターミナルウィンドウやタブで実施してください。2 枚のターミナルを開いておくことを推奨します。
演習シナリオ:
① hpa-demo Namespace を作成
② php-apache Deployment と Service を作成
③ HPA(autoscaling/v2)を作成
④ kubectl run で load-generator を起動(CPU 負荷をかける)
⑤ kubectl get hpa --watch でスケールアウトを観察
⑥ load-generator を停止してスケールダウンを観察
⑦ hpa-demo Namespace を削除してクリーンアップStep 1: hpa-demo Namespace の作成
実行コマンド:
$ kubectl create namespace hpa-demo実行結果:
namespace/hpa-demo createdStep 2: php-apache Deployment と Service の作成
マニフェストファイル php-apache.yaml を作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
namespace: hpa-demo
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
namespace: hpa-demo
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache実行コマンド:
$ kubectl apply -f php-apache.yaml実行結果:
deployment.apps/php-apache created
service/php-apache createdPod が Running になったことを確認します。
実行コマンド:
$ kubectl get pods -n hpa-demo実行結果:
NAME READY STATUS RESTARTS AGE
php-apache-6d4bfd5786-z9kpx 1/1 Running 0 30sStep 3: HPA の作成(autoscaling/v2・CPU 50%)
マニフェストファイル php-apache-hpa.yaml を作成します。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: hpa-demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50実行コマンド:
$ kubectl apply -f php-apache-hpa.yaml実行結果:
horizontalpodautoscaler.autoscaling/php-apache createdHPA の状態を確認します。metrics-server からデータを取得するまで 30〜60 秒ほどかかります。
実行コマンド:
$ kubectl get hpa -n hpa-demo実行結果:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 60sTARGETS 列が 0%/50%(現在 CPU%/ターゲット%)と表示されれば、metrics-server からのデータ取得が正常に動作しています。
TARGETS が <unknown>/50% と表示される場合は、metrics-server がまだデータを取得できていない状態です。1〜2 分待ってから再度確認してください。それでも解消しない場合は kubectl get pods -n kube-system | grep metrics-server で Pod の状態を確認します。
Step 4: load-generator を起動して負荷をかける
このコマンドは対話型シェルを起動します。コマンド実行後は Ctrl+C で停止します。
実行コマンド:
$ kubectl run -it load-generator --rm --image=busybox:1.28 --restart=Never -n hpa-demo -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"busybox の sh 内でループが始まり、php-apache に継続的にリクエストが送信されます。このコマンドは対話型セッションを占有するため、HPA の変化観察は別の端末(またはターミナルの別タブ)で行います。
Step 5: HPA の変化を観察する
別の端末で HPA のウォッチを実行します。
実行コマンド:
$ kubectl get hpa -n hpa-demo --watch実行結果:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 2m
php-apache Deployment/php-apache 218%/50% 1 10 1 2m30s
php-apache Deployment/php-apache 218%/50% 1 10 5 2m45s
php-apache Deployment/php-apache 89%/50% 1 10 5 3m
php-apache Deployment/php-apache 51%/50% 1 10 7 3m15s
php-apache Deployment/php-apache 48%/50% 1 10 7 3m30s負荷がかかるにつれて TARGETS の CPU% が上昇し、50% を超えるとレプリカ数が増加します。スケールアップは即時(stabilizationWindowSeconds: 0)のため、数十秒でレプリカが増加します。
スケールアウト後の Pod 一覧を確認します。
実行コマンド:
$ kubectl get pods -n hpa-demo実行結果:
NAME READY STATUS RESTARTS AGE
php-apache-6d4bfd5786-z9kpx 1/1 Running 0 5m
php-apache-6d4bfd5786-8prxt 1/1 Running 0 2m
php-apache-6d4bfd5786-j2qnk 1/1 Running 0 2m
php-apache-6d4bfd5786-ks7vb 1/1 Running 0 2m
php-apache-6d4bfd5786-m4rwp 1/1 Running 0 90s
php-apache-6d4bfd5786-n8tpz 1/1 Running 0 90s
php-apache-6d4bfd5786-r3kwx 1/1 Running 0 90s7 Pod が Running になっていることが確認できます。
Step 5 補足: kubectl describe hpa でスケーリング状態を詳しく確認する
スケールアウト中に kubectl describe hpa を実行すると、スケーリングの詳細な状態と Events が確認できます。
実行コマンド:
$ kubectl describe hpa php-apache -n hpa-demo実行結果(スケールアウト中の状態):
Name: php-apache
Namespace: hpa-demo
Labels: <none>
CreationTimestamp: Sun, 24 May 2026 10:05:00 +0900
Reference: Deployment/php-apache
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 218% (436m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 5 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 5
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SucceededRescale 30s horizontal-pod-autoscaler New size: 5; reason: cpu resource utilization (percentage of request) above targetEvents の New size: 5; reason: cpu resource utilization (percentage of request) above target からスケールアップの理由が確認できます。CKA 試験のトラブルシュート問題でも、kubectl describe hpa の Events 確認が基本手順です。
Step 6: load-generator を停止してスケールダウンを観察する
load-generator を実行している端末で Ctrl+C を押して停止します。--rm オプションにより load-generator Pod は自動削除されます。
スケールダウン安定化ウィンドウ(デフォルト 5 分)が経過するまでレプリカ数は維持されます。5〜10 分後に確認します。
実行コマンド:
$ kubectl get hpa -n hpa-demo実行結果(5〜10 分後にスケールダウン完了):
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 15mREPLICAS が 1(minReplicas)に戻ったことを確認します。負荷停止直後ではなく、5 分の安定化ウィンドウ経過後にスケールダウンが実行されます。
Step 7: hpa-demo Namespace を削除してクリーンアップ
実行コマンド:
$ kubectl delete namespace hpa-demo実行結果:
namespace "hpa-demo" deletedhpa-demo Namespace 内のすべてのリソース(Deployment・Service・HPA・Pod)が一括削除されます。
演習②の振り返り
- HPA の TARGETS(現在 CPU% / ターゲット%)の変化を実機で観察できた。TARGETS 列の数値が上昇するにつれて REPLICAS が増加するプロセスを確認した
- スケールアップは即時(stabilizationWindowSeconds: 0)、スケールダウンはデフォルト 5 分後(stabilizationWindowSeconds: 300)であることを確認した
registry.k8s.io/hpa-exampleは CPU を大量消費するサーバーであるため、busybox の wget ループで短時間に 50% を超えることを確認した--rmオプションにより load-generator Pod は停止後に自動削除された。CKA 試験でもkubectl run --rmによる一時 Pod 実行は頻出パターン- 実際の本番アプリ(fanclub-api のような Deployment)にも同様の HPA を設定して CPU 使用率に応じた自動スケーリングを実現できる
やってみよう③: ResourceQuota + LimitRange で Namespace リソース制御
ResourceQuota と LimitRange を quota-demo Namespace に設定し、超過 Pod の作成拒否・デフォルト値の自動付与を実機で確認します。
作業場所: k8s-ops(developer ユーザー)
演習シナリオ:
① quota-demo Namespace を作成
② ResourceQuota を設定
③ LimitRange を設定
④ 正常 Pod(requests/limits 指定)の作成確認
⑤ 上限超過 Pod の作成拒否確認
⑥ requests 未指定 Pod への LimitRange デフォルト値付与確認
⑦ kubectl describe resourcequota で最終使用量確認
⑧ quota-demo Namespace を削除してクリーンアップStep 1: quota-demo Namespace の作成
実行コマンド:
$ kubectl create namespace quota-demo実行結果:
namespace/quota-demo createdStep 2: ResourceQuota の適用
マニフェストファイル compute-quota.yaml を作成します。
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
namespace: quota-demo
spec:
hard:
requests.cpu: "1"
requests.memory: "1Gi"
limits.cpu: "2"
limits.memory: "2Gi"
pods: "5"実行コマンド:
$ kubectl apply -f compute-quota.yaml実行結果:
resourcequota/compute-quota createdResourceQuota の初期状態を確認します。
実行コマンド:
$ kubectl describe resourcequota compute-quota -n quota-demo実行結果:
Name: compute-quota
Namespace: quota-demo
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
pods 0 5
requests.cpu 0 1
requests.memory 0 1Gi初期状態では Used がすべて 0 です。Pod を作成するたびに Used が増加します。
Step 3: LimitRange の適用
マニフェストファイル compute-limits.yaml を作成します。
apiVersion: v1
kind: LimitRange
metadata:
name: compute-limits
namespace: quota-demo
spec:
limits:
- type: Container
default:
cpu: 500m
memory: 512Mi
defaultRequest:
cpu: 100m
memory: 128Mi
max:
cpu: "1"
memory: 1Gi
min:
cpu: 50m
memory: 64Mi実行コマンド:
$ kubectl apply -f compute-limits.yaml実行結果:
limitrange/compute-limits createdLimitRange の設定内容を確認します。
実行コマンド:
$ kubectl describe limitrange compute-limits -n quota-demo実行結果:
Name: compute-limits
Namespace: quota-demo
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 50m 1 100m 500m -
Container memory 64Mi 1Gi 128Mi 512Mi -Default Request(requests のデフォルト)と Default Limit(limits のデフォルト)が設定されています。requests/limits を指定しないコンテナにはこれらの値が自動付与されます。
Step 4: 正常 Pod の作成確認(requests/limits 明示指定)
マニフェストファイル quota-test-pod-ok.yaml を作成します。
apiVersion: v1
kind: Pod
metadata:
name: quota-test-pod-ok
namespace: quota-demo
spec:
containers:
- name: nginx
image: 192.168.1.123:5000/nginx:1.27
resources:
requests:
cpu: 200m
memory: 256Mi
limits:
cpu: 400m
memory: 512Mi実行コマンド:
$ kubectl apply -f quota-test-pod-ok.yaml実行結果:
pod/quota-test-pod-ok createdResourceQuota の Used が増加したことを確認します。
実行コマンド:
$ kubectl describe resourcequota compute-quota -n quota-demo実行結果:
Name: compute-quota
Namespace: quota-demo
Resource Used Hard
-------- ---- ----
limits.cpu 400m 2
limits.memory 512Mi 2Gi
pods 1 5
requests.cpu 200m 1
requests.memory 256Mi 1Girequests.cpu の Used が 200m、limits.cpu の Used が 400m、pods の Used が 1 に増加しました。
Step 5: 上限超過 Pod の作成拒否確認
requests.cpu: 1000m を指定した Pod を作成し、Quota 超過で拒否されることを確認します。現在 Used が 200m のため、1000m を追加すると合計 1200m となり上限(1000m)を超過します。
マニフェストファイル quota-test-pod-exceed.yaml を作成します。
apiVersion: v1
kind: Pod
metadata:
name: quota-test-pod-exceed
namespace: quota-demo
spec:
containers:
- name: nginx
image: 192.168.1.123:5000/nginx:1.27
resources:
requests:
cpu: 1000m
memory: 900Mi
limits:
cpu: 1000m
memory: 1Gi実行コマンド:
$ kubectl apply -f quota-test-pod-exceed.yaml実行結果:
Error from server (Forbidden): error when creating "quota-test-pod-exceed.yaml": pods "quota-test-pod-exceed" is forbidden: exceeded quota: compute-quota, requested: requests.cpu=1,requests.memory=900Mi, used: requests.cpu=200m,requests.memory=256Mi, limited: requests.cpu=1,requests.memory=1Giexceeded quota: compute-quota エラーが返ります。エラーメッセージには「requested(要求値)」「used(現在使用量)」「limited(上限)」が明示されているため、どのリソースが何を超過したかを即座に把握できます。
このエラーの読み方: requested は今回の Pod が要求した値(cpu: 1000m は等価の 1 に正規化表示されます)、used は既存 Pod の使用量の合計、limited は Namespace の上限です。本 Pod は CPU とメモリの両方が上限を超えるため、両リソースがまとめて拒否理由に列挙されます。CPU は 200m + 1000m = 1200m が上限 1000m(=1)を超過し、メモリも 256Mi + 900Mi = 1156Mi が上限 1Gi(1024Mi)を超過しています。複数リソースが同時に超過した場合、エラーメッセージにはカンマ区切りで該当リソースがすべて並びます。
ResourceQuota が有効になっている Namespace での Pod 作成エラーは、必ずこの形式のメッセージで通知されます。CKA 試験でトラブルシュート問題が出た際、このメッセージを見たら「ResourceQuota 超過」と判断できます。
Step 6: requests 未指定 Pod への LimitRange デフォルト値付与確認
requests/limits を指定しない Pod を作成し、LimitRange のデフォルト値が自動付与されることを確認します。
マニフェストファイル quota-test-pod-noreq.yaml を作成します。
apiVersion: v1
kind: Pod
metadata:
name: quota-test-pod-noreq
namespace: quota-demo
spec:
containers:
- name: nginx
image: 192.168.1.123:5000/nginx:1.27実行コマンド:
$ kubectl apply -f quota-test-pod-noreq.yaml実行結果:
pod/quota-test-pod-noreq createdLimitRange が defaultRequest(cpu: 100m / memory: 128Mi)を自動付与したため、ResourceQuota のチェックをパスして Pod が作成されました。付与されたリソース設定を確認します。
実行コマンド:
$ kubectl get pod quota-test-pod-noreq -n quota-demo -o jsonpath='{.spec.containers[0].resources}'実行結果:
{"limits":{"cpu":"500m","memory":"512Mi"},"requests":{"cpu":"100m","memory":"128Mi"}}マニフェストに resources を一切記述していないにもかかわらず、LimitRange の defaultRequest(requests: cpu 100m / memory 128Mi)と default(limits: cpu 500m / memory 512Mi)が自動付与されています。
Step 6 補足: LimitRange の max を超えた場合の動作確認
LimitRange の max(cpu: "1")を超える limits を指定したコンテナは作成拒否されます。以下で動作を確認します。
マニフェストファイル quota-test-pod-overlimit.yaml を作成します(limits.cpu に max の 1000m を超える 1200m を指定)。
apiVersion: v1
kind: Pod
metadata:
name: quota-test-pod-overlimit
namespace: quota-demo
spec:
containers:
- name: nginx
image: 192.168.1.123:5000/nginx:1.27
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 1200m
memory: 512Mi実行コマンド:
$ kubectl apply -f quota-test-pod-overlimit.yaml実行結果:
Error from server (Forbidden): error when creating "quota-test-pod-overlimit.yaml": pods "quota-test-pod-overlimit" is forbidden: [maximum cpu usage per Container is 1, but limit is 1200m]LimitRange の max(CPU 1 = 1000m)を超える limits.cpu(1200m)を指定したため、maximum cpu usage per Container is 1, but limit is 1200m エラーで拒否されました。このエラーは ResourceQuota の exceeded quota とは異なる形式であるため、見分け方を覚えてください。
exceeded quota: compute-quota→ ResourceQuota の合計上限超過maximum cpu usage per Container is X, but limit is Y→ LimitRange の max 超過minimum cpu usage per Container is X, but request is Y→ LimitRange の min を下回る requests 指定must specify requests.cpu→ ResourceQuota があるのに requests.cpu 未指定(LimitRange なし)
CKA 試験のトラブルシュート問題でこれらのエラーメッセージが出た場合、kubectl describe pod の Events を確認してエラー種別を特定し、ResourceQuota か LimitRange かを区別して対処してください。
Step 7: ResourceQuota の最終使用量確認
2 Pod が稼働している状態での ResourceQuota 使用量を確認します。
実行コマンド:
$ kubectl describe resourcequota compute-quota -n quota-demo実行結果:
Name: compute-quota
Namespace: quota-demo
Resource Used Hard
-------- ---- ----
limits.cpu 900m 2
limits.memory 1Gi 2Gi
pods 2 5
requests.cpu 300m 1
requests.memory 384Mi 1Giquota-test-pod-ok(requests.cpu: 200m)+ quota-test-pod-noreq(LimitRange 自動付与: 100m)= requests.cpu Used 300m となっています。
Step 8: quota-demo Namespace を削除してクリーンアップ
実行コマンド:
$ kubectl delete namespace quota-demo実行結果:
namespace "quota-demo" deletedquota-demo Namespace 内のすべてのリソース(ResourceQuota・LimitRange・Pod)が一括削除されます。
クリーンアップが完了したことを確認します。
実行コマンド:
$ kubectl get namespace実行結果:
NAME STATUS AGE
default Active 30d
fanclub Active 7d
kube-node-lease Active 30d
kube-public Active 30d
kube-system Active 30dquota-demo Namespace が一覧から消えたことを確認します。fanclub Namespace は変更なく稼働中です。
metrics-server が kube-system で引き続き動作していることも確認します。
実行コマンド:
$ kubectl top nodes実行結果:
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-cp-01 148m 3% 1018Mi 24%
k8s-cp-02 118m 2% 976Mi 23%
k8s-cp-03 129m 3% 1008Mi 24%
k8s-wl-01 195m 4% 1490Mi 18%
k8s-wl-02 177m 4% 1395Mi 17%演習 Namespace を削除した後も kubectl top nodes が正常動作しています。metrics-server は kube-system に残存しており、第9回以降でも継続利用できます。
演習③の振り返り
- ResourceQuota の Hard と Used の変化を
kubectl describe resourcequotaでリアルタイムに確認できた。Pod 作成のたびに Used が増加する動作を観察した - Quota 超過時のエラーメッセージ(
exceeded quota: compute-quota, requested: ..., used: ..., limited: ...)には required/used/limited が明示されており、原因診断に役立つ - LimitRange を設定することで、requests/limits 未指定の Pod にも自動でリソース制限が付与されることを確認した。jsonpath で実際に付与された値を確認できた
- ResourceQuota + LimitRange はセットで設定することが推奨される理由を実機で理解した。LimitRange なしに ResourceQuota(requests.cpu 設定)のみ設定すると、requests 未指定 Pod が全拒否される「トラップ」になる
- LimitRange の max を超える limits を指定したコンテナは
maximum cpu usage per Container is X, but limit is Yエラーで拒否されることを確認した。このエラーは ResourceQuota のexceeded quotaと形式が異なるため、見分け方を習得した - 演習③で作成したすべてのリソース(ResourceQuota・LimitRange・Pod)は
kubectl delete namespace quota-demoの 1 コマンドで一括削除できた
まとめ・現場ヒヤリハット・理解度チェック
第8回のまとめ
第8回で習得した内容を整理します。
- metrics-server は kubeadm 環境に別途インストールが必要で、
--kubelet-insecure-tlsフラグを追加することで kubelet の自己署名証明書問題を回避できる。kubectl top nodes/kubectl top podsの動作は metrics-server に依存する - HPA v2(
autoscaling/v2)で CPUaverageUtilizationを指定したスケーリングを設定できる。スケールアップは即時・スケールダウンはデフォルト 5 分の安定化ウィンドウがある - ResourceQuota で Namespace 全体のリソース上限(CPU / メモリ / Pod 数)を管理できる。
kubectl describe resourcequotaで Used / Hard を確認する習慣が重要 - LimitRange で Container のデフォルト requests / limits を設定でき、requests 未指定 Pod にも自動で値が付与される
- ResourceQuota と LimitRange はセットで設定することが推奨される。ResourceQuota のみだと requests 未指定 Pod が全拒否される
第2部「ワークロード管理」完走:
第8回の完了で第2部(第6〜8回)が完走しました。第2部では「クラスタアップグレード → Pod スケジューリング → リソース管理」の順で CKA D2(Workloads and Scheduling・15%)に対応しました。
第8回で学んだ設計パターンのまとめ
本回で学習した 3 機構の関係性を整理します。
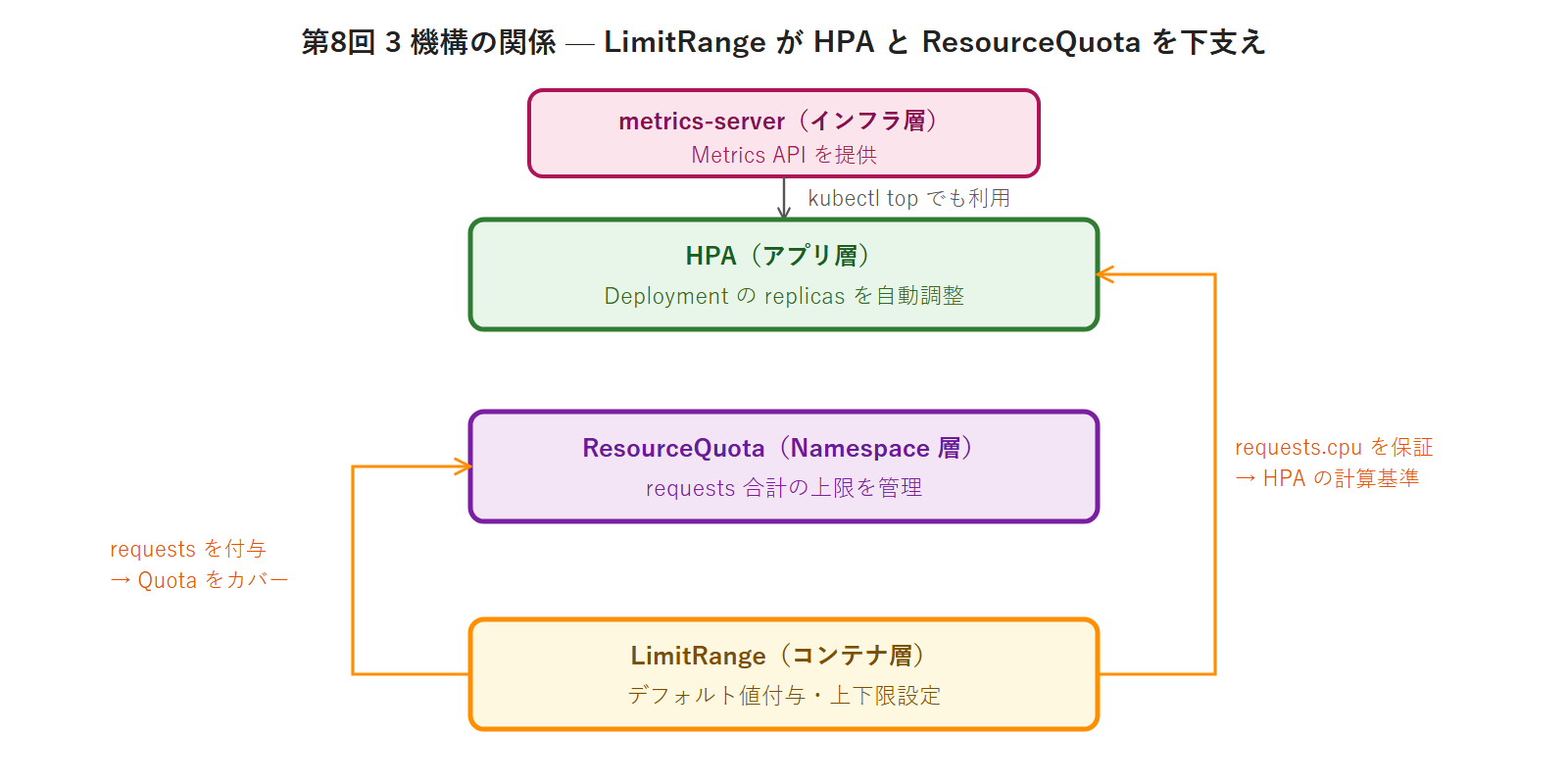
3 機構はそれぞれ独立して動作しますが、LimitRange は他の 2 機構を「つなぐ」役割を持っています。「metrics-server なし → HPA が動かない」「ResourceQuota あり + LimitRange なし → Pod が全拒否」という連携を理解することが実務での安定運用の鍵です。
実務での推奨設定パターン
本番 Kubernetes クラスタで新しい Namespace を作成する際の推奨設定順序を示します。
【新規 Namespace の推奨セットアップ順序】
Step 1: Namespace 作成
kubectl create namespace <ns>
Step 2: LimitRange を先に設定(ResourceQuota より先に設定すること)
kubectl apply -f limitrange.yaml -n <ns>
理由: ResourceQuota 設定後に LimitRange を適用しても、
ResourceQuota 設定直後から Pod 作成が拒否される可能性がある
Step 3: ResourceQuota を設定
kubectl apply -f resourcequota.yaml -n <ns>
Step 4: 設定確認
kubectl describe limitrange -n <ns>
kubectl describe resourcequota -n <ns>
Step 5: テスト Pod で動作確認
kubectl run test --image=192.168.1.123:5000/nginx:1.27 -n <ns>
kubectl get pod test -n <ns> -o jsonpath='{.spec.containers[0].resources}'
→ LimitRange のデフォルト値が付与されていることを確認
kubectl delete pod test -n <ns>LimitRange を ResourceQuota より先に適用する理由は、ResourceQuota 設定後はすぐに requests/limits の検証が始まるためです。LimitRange のデフォルト値が付与されていない状態で ResourceQuota が有効になると、既存の Pod 追加がすぐに拒否される事態が発生します。
第8回で学んだ内容と CKA D2 の対応関係
| CKA D2 Competency(v1.35 Curriculum) | 第8回での対応箇所 |
|---|---|
| Configure resource limits and policies | H2-3〜H2-6(概念)/ H2-7〜H2-9(実践演習) |
| Understand Kubernetes API primitives | HPA v2 / ResourceQuota / LimitRange の apiVersion・kind |
| Deploy and configure network load balancer | (第9回・MetalLB) |
CKA D2 の「Configure resource limits and policies」に対する第8回のカバレッジは次のとおりです。
- Pod の resources.requests / resources.limits の設定: 演習②③の YAML マニフェストで実践済み
- HPA による自動スケーリング(CPU ベース): 演習②で実機確認済み
- ResourceQuota による Namespace リソース管理: 演習③で実機確認済み
- LimitRange によるデフォルトリソース設定: 演習③で実機確認済み
- metrics-server のインストール(kubectl apply ベース): 演習①で実機確認済み
CKA 試験の D2 ドメイン(15%)はクラスタの日常運用に直結する重要領域です。試験当日は「autoscaling/v2 の YAML を書く」「kubectl describe resourcequota で Used/Hard を読む」「LimitRange の defaultRequest を設定する」の 3 操作が確実にできるよう、本回の演習を繰り返し手を動かして定着させてください。
次回予告
第9回では Service 詳細と MetalLB を扱います。ClusterIP / NodePort / LoadBalancer / ExternalName の動作原理を深く理解し、MetalLB を導入してオンプレ kubeadm 環境でも LoadBalancer type Service が動作することを実機で確認します。
第8回まで(第2部完走)でクラスタを「動かす」土台が完成しました。第9回からの第3部「ネットワーク」では、クラスタ内外のトラフィックをどのように制御するかを学びます。Service 種別の使い分け・MetalLB による LoadBalancer 実現・NetworkPolicy によるトラフィック制限・Gateway API による高度なルーティングと、実務で日常的に扱うネットワーク設定を順に習得します。
第9回は CKA D3(Services and Networking・20%)の開始回です。D3 は CKA の最大ドメインであり、試験全体の 20% を占めます。第3部 3 回(第9〜11回)でこのドメインに対応します。
CKA 試験対策ポイント
本回で学習した内容は CKA D2「Configure resource limits and policies」に対応します。試験でよく出題されるパターンを整理します。
CKA 頻出パターン①: HPA の作成
試験では「Deployment X に対して CPU 使用率 Y% を超えたら最大 Z レプリカまでスケールする HPA を作成せよ」という形式が出題されます。以下のポイントを押さえてください。
apiVersion: autoscaling/v2(v1 ではなく v2)scaleTargetRef.apiVersion: apps/v1(必須・省略不可)metrics[].type: Resource+resource.name: cpu+target.type: Utilization+target.averageUtilization: <値>- HPA の Namespace はスケール対象の Deployment と同じ Namespace に作成する
CKA 頻出パターン②: ResourceQuota の確認と対応
試験では「Namespace X に Pod を作成しようとしたが失敗する。原因を調査して解決せよ」という形式が出題されます。ResourceQuota が原因の場合の手順を覚えてください。
kubectl describe resourcequota -n <namespace>
→ Used が Hard に近い項目を確認
→ 超過している場合: 不要な Pod を削除するか、Quota の Hard 値を引き上げる(管理者権限が必要)
kubectl describe pod <failing-pod> -n <namespace>
→ Events に exceeded quota または must specify が表示されているか確認CKA 頻出パターン③: LimitRange の設定確認
試験では「Namespace X に LimitRange を設定して、コンテナのデフォルト CPU requests を Y に設定せよ」という形式が出題されます。
- LimitRange の
spec.limits[].typeは大文字始まり(Container) defaultRequestが requests のデフォルト、defaultが limits のデフォルト- LimitRange 作成後に
kubectl describe limitrangeで設定値を必ず確認する
試験で参照できる公式ドキュメント URL をブックマークしておくことを推奨します。
- HPA ウォークスルー(php-apache デモ): https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
- ResourceQuota: https://kubernetes.io/docs/concepts/policy/resource-quotas/
- LimitRange: https://kubernetes.io/docs/concepts/policy/limit-range/
- metrics-server: https://github.com/kubernetes-sigs/metrics-server
現場ヒヤリハット① metrics-server が Running なのに kubectl top が動かない
状況: kubeadm で構築したクラスタに metrics-server を公式ドキュメントの手順(components.yaml をそのまま apply)でインストールした。kubectl get pods -n kube-system では metrics-server Pod が Running になっているにもかかわらず、kubectl top nodes を実行すると ServiceUnavailable エラーが続く。
原因: metrics-server は kubelet の TLS 証明書を検証しようとするが、kubeadm 環境の kubelet は自己署名証明書を使用しているため検証に失敗する。kubectl logs -n kube-system <metrics-server-pod> を確認すると x509: cannot validate certificate for <NodeIP> エラーが記録されている。Pod が Running でも Metrics API が正常応答できない状態。
対処: metrics-server Deployment の args に --kubelet-insecure-tls を追加して再 apply する(kubectl edit deployment metrics-server -n kube-system または YAML を修正して kubectl apply)。
教訓: kubeadm 環境に metrics-server をインストールする場合、--kubelet-insecure-tls の追加は必須ステップです。Pod が Running でも Metrics API が動作しない場合は kubectl logs でエラーを確認する習慣をつけてください。
現場ヒヤリハット② ResourceQuota の requests.cpu のみを設定したら Pod が全部作れなくなった
状況: staging Namespace に ResourceQuota を設定する際、CPU のリクエスト上限(requests.cpu: "2")のみを設定した。その後、既存の Deployment をスケールアウトしようとしたら「must specify requests.cpu」というエラーで Pod が作成できなくなった。
原因: ResourceQuota が requests.cpu を追跡している場合、Kubernetes は Namespace 内の各 Pod(コンテナ)に requests.cpu の指定を要求します。quota が追跡している資源(ここでは requests.cpu)を集計するには、各 Pod がその値を明示している必要があるためです。requests.cpu を指定しない Pod は「must specify requests.cpu」で拒否されます(limits.cpu は要求されません)。LimitRange が設定されていない場合、requests のデフォルト値が付与されないため、requests.cpu 未指定の Pod 作成が全拒否されます。
対処: (a) Pod(Deployment の Pod テンプレート)に requests.cpu を明示する、または (b) LimitRange の defaultRequest を追加してコンテナのデフォルト requests を自動付与する。LimitRange を併設しておくのがベストプラクティスです。
教訓: ResourceQuota を設定する際は、LimitRange とセットで設定してください。requests.cpu だけを設定した ResourceQuota は、LimitRange なしだと Pod 作成を全拒否する「トラップ」になります。新しい Namespace に ResourceQuota を設定したら、必ず requests/limits を指定した Pod で動作確認してください。
理解度チェック
第8回の理解度を ○× 形式の 7 問で確認します。まず問題を読み、自分なりに答えを出してから解説を読んでください。
- 問 1: kubeadm で構築した Kubernetes クラスタには、metrics-server がデフォルトでインストールされている
- 問 2: HPA v2(
autoscaling/v2)は CPU だけでなくメモリや外部メトリクスにも対応している - 問 3: HPA の
behavior.scaleDown.stabilizationWindowSecondsのデフォルト値は 0 秒(即時スケールダウン)である - 問 4: ResourceQuota の
pods: "5"は、Namespace 内の Running 状態の Pod 数を 5 個以下に制限する - 問 5: LimitRange の
defaultRequestを設定すると、resources.requestsを指定しないコンテナにもデフォルト値が自動付与される - 問 6:
requests.cpuを設定した ResourceQuota があるとき、LimitRange なしでrequests.cpu未指定の Pod を作成しようとすると Pod は作成できない - 問 7: HPA が CPU 使用率でスケーリングを判断する際、Pod の
resources.limits.cpuの値を基準として使用する
問 1: × — metrics-server は別途インストールが必要です。kubeadm はクラスタ基盤(kube-apiserver / etcd / scheduler / controller-manager / kube-proxy / CoreDNS)のみを構築し、metrics-server は含まれません。インストールしていない状態で kubectl top nodes を実行すると ServiceUnavailable エラーが返ります。
問 2: ○ — spec.metrics に Resource(CPU/メモリ)/ Pods / Object / External / ContainerResource の 5 種が指定可能です。CPU・メモリ以外にも Prometheus 等のカスタムメトリクスや CloudWatch などの外部メトリクスを基準にスケーリングできます。CKA 試験では Resource タイプ(CPU averageUtilization)を確実に書けることが最重要です。
問 3: × — デフォルトは 300 秒(5 分)です。スケールダウン時の急激な変動(フラッピング)を防ぐための安定化ウィンドウです。スケールアップのデフォルトが 0 秒(即時)であるのと対照的です。負荷が下がっても 5 分間はレプリカ数が維持されることを実機の演習②で確認しました。
問 4: × — Running に限らず、すべての状態の Pod(Pending / Running / Succeeded / Failed 等)の合計数を制限します。pods: "5" は Namespace 内に存在できる Pod オブジェクトの総数の上限です。
問 5: ○ — LimitRange の defaultRequest を設定すると、Pod マニフェストに resources.requests を書かなくてもコンテナにデフォルト値が自動付与されます。演習③の Step 6 で jsonpath を使って実際に付与された値を確認しました。
問 6: ○ — ResourceQuota が requests.cpu を追跡している場合、Kubernetes は各 Pod に requests.cpu の指定を要求します。LimitRange による requests のデフォルト値が付与されていない状態では、requests.cpu を明示しない Pod は「must specify requests.cpu」エラーで拒否されます(limits.cpu は要求されません)。これがヒヤリハット②のパターンです。
問 7: × — resources.requests.cpu を基準として使用します。HPA は「現在の CPU 使用量 / requests.cpu」の比率(利用率)でスケーリングを判断します。requests が設定されていない Pod では HPA が利用率を計算できないため、スケール対象の Deployment には必ず resources.requests.cpu を設定してください。limits.cpu は CPU の上限値(バースト上限)であり、HPA の計算基準には使われません。例えば requests.cpu が 200m で現在 CPU が 436m 消費している場合、利用率は (436 ÷ 200) × 100 = 218% となります。
第8回の理解度チェックを通じて、本回の 3 機構(metrics-server / HPA / ResourceQuota + LimitRange)の重要な概念を復習できました。試験前日に本チェックを再度解いて知識の定着を確認してください。
シリーズ一覧
第1部:クラスタ構築
- 第1回 第2巻スコープ + CKA 試験形式紹介 + kubeadm 概要 + kubeadm vs RKE2/k0s/OKD 概観
- 第2回 kubeadm シングルノード起動(pkgs.k8s.io + kubeadm init + Calico CNI)+ alma-proxy whitelist 構築
- 第3回 kubeadm HA 設計 + HAProxy LB(API Server LB 構成)
- 第4回 kubeadm HA クラスタ構築(CP×3 + WL×2)+ fanclub-api HA 移行
- 第5回 etcd backup/restore(etcdutl)+ ノード drain/uncordon
第2部:ワークロード管理
- 第6回 kubeadm upgrade + ノード drain/cordon + ミニトラブルシュート演習
- 第7回 Pod スケジューリング(taint/toleration/affinity/anti-affinity/PriorityClass)
- 第8回 HPA + ResourceQuota + LimitRange ← 今ここ
第3部:ネットワーク
- 第9回 Service 詳細 + MetalLB(LoadBalancer 動作確認)
- 第10回 NetworkPolicy 詳細 + Calico/Cilium 比較 + ミニトラブルシュート演習
- 第11回 Gateway API + Traefik + cert-manager + CoreDNS(HTTPS 公開完成)
第4部:ストレージ
第5部:監視・運用
- 第13回 Prometheus + Grafana + Loki + Fluent Bit + fanclub-api 監視ダッシュボード
- 第14回 Helm + Kustomize でクラスタコンポーネント install + ArgoCD GitOps + Velero backup
