
新卒インフラエンジニア向け Kubernetes 実践教科書(第2巻 CKA 編)の第3回です。動作確認バージョン: AlmaLinux 10.1 / HAProxy 3.0.5 / K8s v1.35.5(2026-05-22 時点・k8s-lb / k8s-cp-01 実機検証済)。第2回では k8s-cp-01 に kubeadm v1.35 をインストールし、シングルノードクラスタを起動しました。k8s-lb には最小限の HAProxy パススルー設定(CP-01 のみ)を入れました。第3回では、その「最小」設定を HA 本格設計に作り込みます。CP×3 を backend に登録し、stats ページとヘルスチェックを有効にします。あわせて HA クラスタの根幹となる etcd quorum と Raft コンセンサスアルゴリズムを学びます。第3回が終わると、第4回の kubeadm join(CP-02/03 + WL-01/02 参加)に向けた準備が整います。
- 今ここマップ(第3回 / 全16回 / 第1部)
- 第3回のスコープ — 第2回「最小パススルー」から HA 設計へ
- なぜ HA が必要か — SPOF の脅威と可用性の考え方
- Control Plane HA アーキテクチャ(stacked etcd・CP×3)
- etcd quorum と Raft — 障害耐性の仕組みと偶数ノード非推奨の理由
- HAProxy HA 設計 — frontend stats + k8s-api・backend CP×3・roundrobin・tcp-check
- やってみよう① — k8s-lb HAProxy を HA 設定に更新 + stats ページ確認
- やってみよう② — etcd quorum 計算演習
- HA 用 kubeadm-config.yaml の設計確認(第4回 join への布石)
- まとめ・現場ヒヤリハット・理解度チェック
- シリーズ一覧
今ここマップ(第3回 / 全16回 / 第1部)
今ここマップ(第2巻 16 回中の現在位置):
今ここ: 第3回 / 全16回(第1部:クラスタ構築)
▓▓▓░░░░░░░░░░░░░ 19%
第1部(クラスタ構築): ■■■□□ 3/5 回(進行中)
第2部(ワークロード管理): □□□ 0/3 回
第3部(ネットワーク): □□□ 0/3 回
第4部(ストレージ): □ 0/1 回
第5部(監視・運用): □□ 0/2 回
第6部(トラブルシュート): □□ 0/2 回第3回で学ぶことは次の 5 点です。これがそのまま今回の学習目標になります。
- kubeadm HA クラスタのトポロジ(stacked etcd)と
controlPlaneEndpointの役割を理解する - etcd quorum と Raft の仕組みを理解し、N ノードの quorum 計算・障害耐性・偶数ノードが非推奨な理由を説明できる
- k8s-lb の haproxy.cfg を HA 本格設計版(CP×3 backend・stats・tcp-check・roundrobin)に更新し、
haproxy -cで検証後に reload できる - HAProxy stats ページ(
http://192.168.1.124:9000/stats)で CP-01 UP / CP-02/03 DOWN の状態を確認し、第4回 join 後に UP になる理由を説明できる - 第4回の
kubeadm join --control-planeに向けて、kubeadm-config.yaml のcontrolPlaneEndpoint設定と--upload-certsの有効期限を理解する
第3回終了時の達成状態を整理します。第4回の HA クラスタ構築の前提になる状態です。
- k8s-lb の haproxy.cfg が HA 本格設計版に更新されている(CP×3 backend・stats・tcp-check)
- HAProxy stats ページ(
http://192.168.1.124:9000/stats)で CP-01 UP / CP-02/03 DOWN の状態を確認済み - etcd quorum の計算式(
⌊N/2⌋ + 1)と偶数ノード非推奨の理由を説明できる - 第4回の
kubeadm join --control-planeに向けた kubeadm-config.yaml の設計を把握している
第3回のスコープ — 第2回「最小パススルー」から HA 設計へ
具体的な設定に入る前に、第2回・第3回・第4回の役割分担を整理します。今回「何をどこまでやるか」を把握してから手を動かすと、作業の目的が明確になります。
第2回〜第4回の役割分担
第2回から第4回は「HA クラスタを作り上げる 3 回連続のシリーズ」です。第2回でシングル CP クラスタを起動し、第3回で LB を HA 設計に育て、第4回で全ノードを参加させて HA クラスタを完成させます。3 回を通じた役割分担を次の表に整理します。
| 回 | k8s-lb での作業 | k8s-cp での作業 | この回が終わると |
|---|---|---|---|
| 第2回(完了) | 最小パススルー(:6443 → k8s-cp-01 のみ) | k8s-cp-01: kubeadm init + Calico CNI | シングルノードクラスタ稼働 |
| 第3回(本回) | HA 本格設計(CP×3 backend・stats・tcp-check) | haproxy.cfg 更新のみ(CP-02/03 は未 join) | 第4回 join の準備完了 |
| 第4回(次回) | stats ページで全 backend UP 確認 | k8s-cp-02/03: kubeadm join –control-plane / k8s-wl-01/02: kubeadm join | 5 ノード HA クラスタ完成 |
第3回で「やること」と「やらないこと」
設計解説と実機作業が混在する回のため、スコープを明確にします。
| やること | やらないこと |
|---|---|
| haproxy.cfg を HA 版に書き換える(CP×3 backend・stats 追加) | k8s-cp-02/03 の kubeadm join(→ 第4回) |
| stats ページで UP/DOWN 状態を確認する | k8s-wl-01/02 の構築(→ 第4回) |
| etcd quorum の計算・Raft の仕組みを学ぶ | Calico CNI の追加設定(→ 第4回) |
| kubeadm-config.yaml の設計を再確認する | gateway-https frontend の設定(→ 第11回) |
第3回終了時点での各 VM の状態
第3回が終わったとき、各 VM がどういう状態になっているかを先に確認します。この表が「ゴール」です。
| VM | 第3回終了時の状態 |
|---|---|
| k8s-lb(192.168.1.124) | HAProxy HA 設計版 haproxy.cfg 稼働中 |
| k8s-cp-01(192.168.1.125) | 稼働中(kubeadm init 済み・シングル CP) |
| k8s-cp-02(192.168.1.126) | VM 稼働中だが未 join(HAProxy stats で DOWN 表示) |
| k8s-cp-03(192.168.1.127) | VM 稼働中だが未 join(HAProxy stats で DOWN 表示) |
| k8s-wl-01/02 | VM 稼働中だが未 join(第4回で join) |
CP-02/03 が HAProxy stats で DOWN 表示になるのは想定どおりです。haproxy.cfg に backend として記載されていますが、6443 ポートを LISTEN しているプロセス(kube-apiserver)が存在しないため、tcp-check が失敗して DOWN になります。第4回で kubeadm join --control-plane を実行すると kube-apiserver が起動し、stats で UP に変わります。DOWN 表示を見て「設定が間違っている」と焦る必要はありません。
なぜ HA が必要か — SPOF の脅威と可用性の考え方
HAProxy の設定を変える前に、「なぜ HA が必要なのか」を理解します。HA(High Availability・高可用性)構成の必要性は、SPOF という概念から説明できます。
SPOF とは何か
SPOF(Single Point of Failure)は「単一障害点」と訳します。そのコンポーネントが停止すると、それだけでシステム全体が停止するポイントのことです。
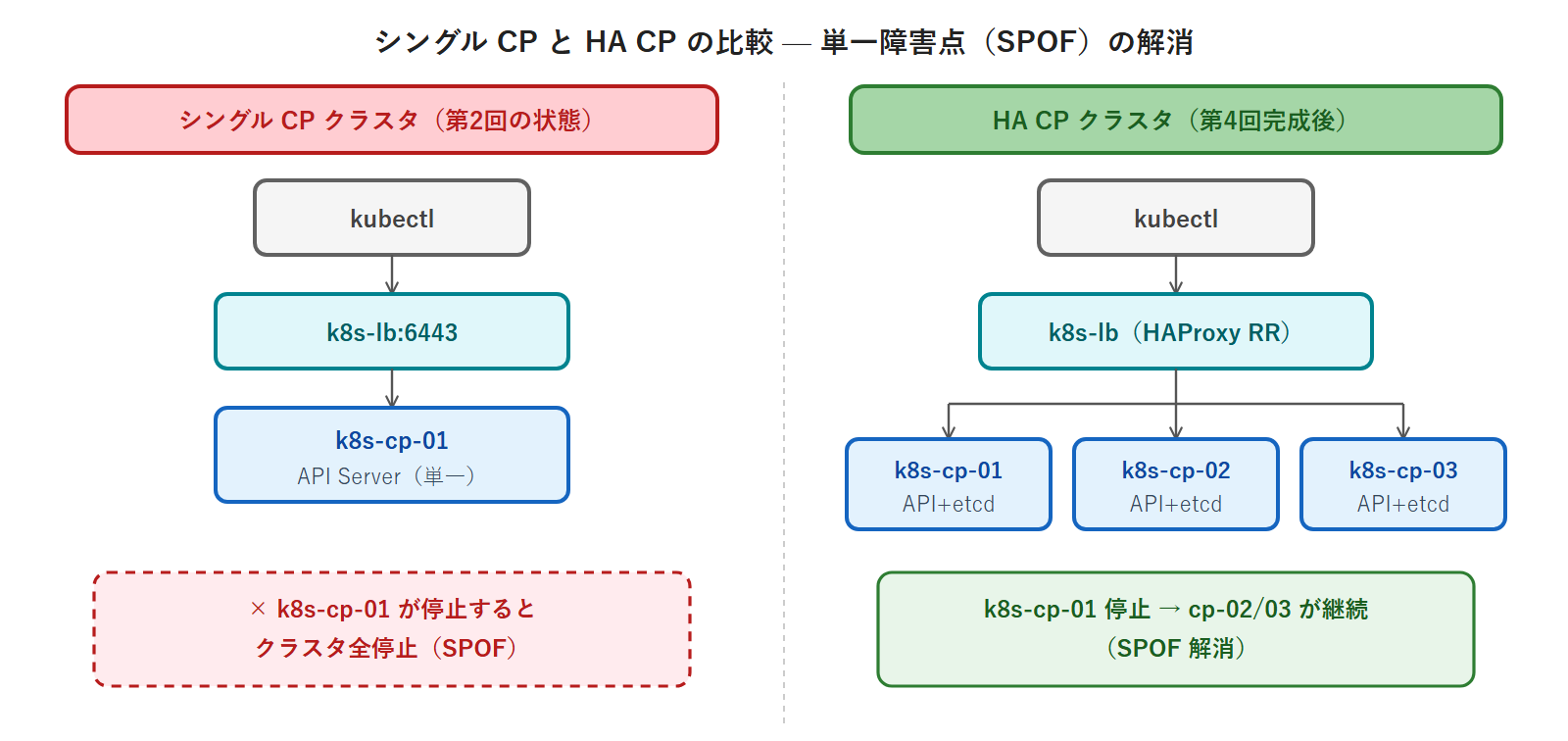
第2回が終わった時点のクラスタは、k8s-cp-01 が SPOF です。k8s-cp-01 が OS 障害・ハードウェア障害・メンテナンス停止によって停止すると、クラスタ全体が停止します。k8s-lb が 6443 に受け取った接続を k8s-cp-01 の 6443 にしか転送しないからです。
kube-apiserver が停止すると何が起きるか
kube-apiserver は Kubernetes クラスタの中枢です。apiserver が停止すると次のことが起きます。これは CKA 試験で問われる頻出の挙動です。
kubectlコマンドがすべて失敗する(kubectl は API Server 経由でクラスタを操作するため)- 新規 Pod のスケジューリングが停止する(kube-scheduler が API Server に依存するため)
- 既存 Pod・コンテナは引き続き動作する(kubelet は API Server なしでも既存コンテナを維持する)
- etcd への書き込みが停止する(kube-apiserver が唯一の etcd クライアント)
特に「既存 Pod は止まらない」という点は試験でよく問われます。API Server が落ちてもすでに動いているアプリは止まりません。止まるのは「新しい操作・新しい Pod の作成」です。本番環境で API Server 障害が発生したとき、「アプリは動いているのに kubectl が通らない」という状況がこれです。
HA 構成で SPOF を解消する
HA 構成では Control Plane Node を 3 台に増やし、HAProxy がラウンドロビンで接続を振り分けます。1 台の CP ノードが停止しても残り 2 台でクラスタが継続動作します。
可用性の定量化 — 99.9% と 99.99% の違い
HA 構成が「必要かどうか」を判断する基準の一つが可用性の目標値(SLA/SLO)です。可用性は年間の稼働率として表現されます。
| 可用性 | 許容停止時間(年間) | シングル CP の典型的リスク |
|---|---|---|
| 99% | 87.6 時間 | — |
| 99.9% | 8.76 時間 | 単一 CP でも頑張れる上限 |
| 99.99% | 52.6 分 | HA 構成が事実上必須 |
| 99.999% | 5.26 分 | HA + 追加自動化が必要 |
シングル CP クラスタで年間 8 時間以内の停止に収めることは難しくありません。しかし 99.99%(年間 52 分以内)を目標とするサービスでは、CP ノードの計画メンテナンスだけでも停止時間が積み上がります。HA 構成は「高可用性の第一歩」であり、「完全無停止」を保証するものではありません。CP が 3 台になっても、同時に 2 台が障害を起こせばクラスタは停止します。HA はリスクを下げる構成であり、ゼロリスクではないことを理解しておきます。
Control Plane HA アーキテクチャ(stacked etcd・CP×3)
HA クラスタの全体像を理解します。kubeadm HA には 2 つのトポロジがあります。本シリーズで採用する stacked etcd と、対比として知っておくべき external etcd です。
2 つのトポロジ比較
| トポロジ | 構成 | 最小ノード数 | 本シリーズの扱い |
|---|---|---|---|
| stacked etcd(本シリーズ採用) | etcd が各 CP ノード上で同居 | 3 CP ノード | 第3〜4回で構築 |
| external etcd | CP ノードと etcd ノードを分離 | 3 CP + 3 etcd = 6 ノード | 解説のみ(本シリーズ対象外) |
stacked etcd を選ぶ理由は 3 つあります。セットアップが簡素・ノード数が少ない・CKA 試験で問われる標準的なトポロジである、という点です。external etcd は etcd クラスタを独立してスケールしたい大規模環境向けです。etcd の書き込みが多く CP ノードとリソースを分離したい場合に有効ですが、必要なノード数が倍増します。本シリーズの学習環境(9 VM 構成)では stacked etcd が現実的です。
Stacked etcd の構成図
stacked etcd では etcd が各 CP ノードに「同居(stacked)」します。以下の構成図で関係を確認します。
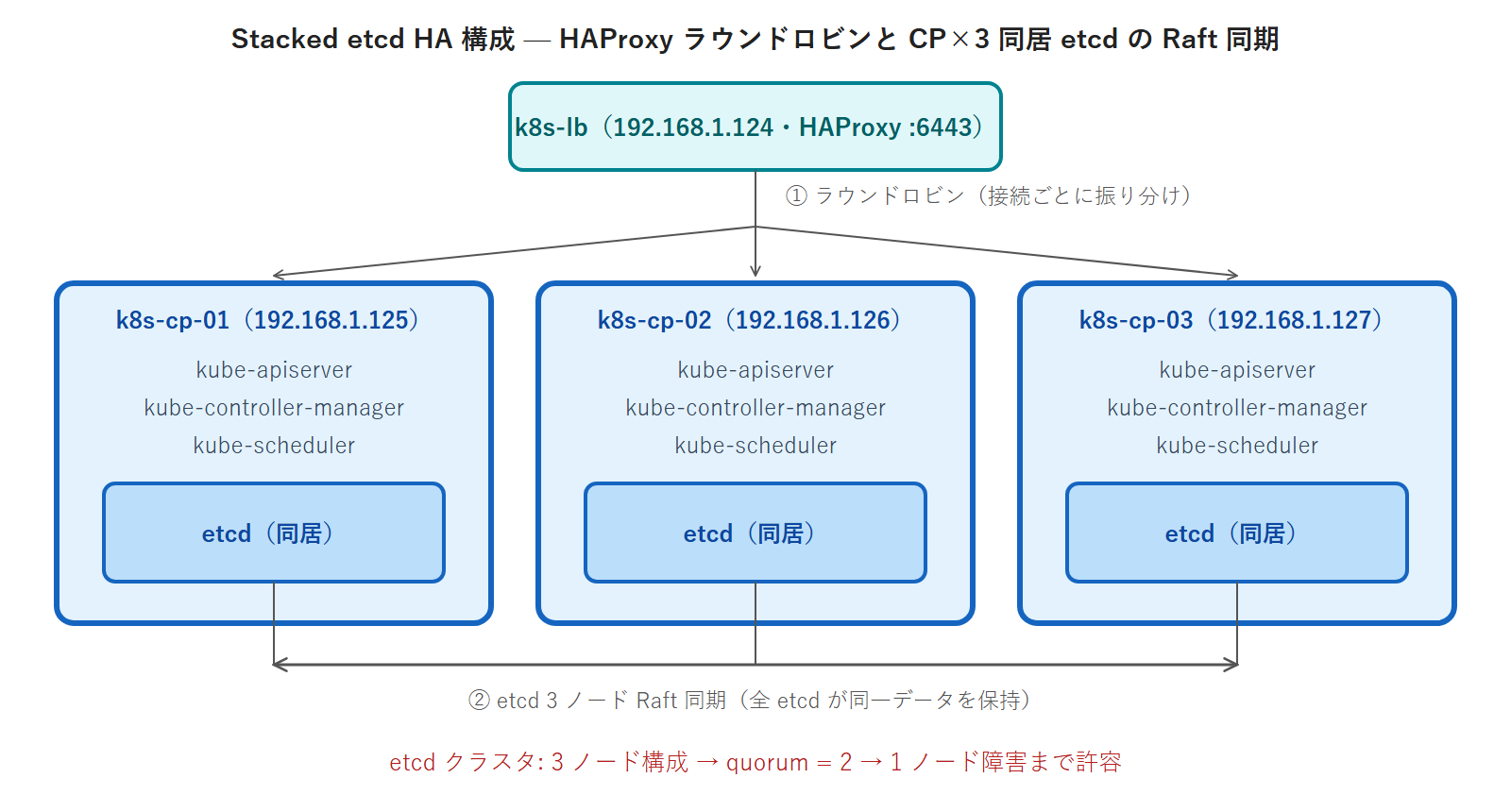
各 CP ノードには 4 つの Control Plane コンポーネントが Static Pod として稼働します。Static Pod は /etc/kubernetes/manifests/ に配置された YAML ファイルを kubelet が直接起動・管理するものです。etcd もこの仕組みで動作します。kubeadm はこれらの Static Pod マニフェストを自動生成します。
controlPlaneEndpoint の役割(第2回設定済み・再確認)
controlPlaneEndpoint は、クラスタの全コンポーネントが API Server に接続する際の「共通エントリポイント」です。本シリーズでは k8s-lb:6443 を指定しています。
この設定があることで、kubelet・kube-controller-manager・kube-scheduler・kubeadm join のいずれも k8s-lb:6443 を経由して API Server に接続します。HAProxy がラウンドロビンで CP ノードに転送するため、どの CP ノードが応答しても同じ結果が得られます。
変更時のコストを覚えておきます。controlPlaneEndpoint を init 後に変更すると、API Server の TLS 証明書に含まれる SAN(Subject Alternative Name)の再生成が必要になります。これは本番稼働中クラスタでは大掛かりな作業です。第2回でこの値を最初から k8s-lb:6443 に設定したのはこのためです。
controlPlaneEndpoint: "k8s-lb:6443"第2回の kubeadm-config.yaml にすでにこの値が設定されているため、第3回以降は確認するだけです。第4回で k8s-cp-02/03 が kubeadm join k8s-lb:6443 を実行するとき、この controlPlaneEndpoint が join 先として機能します。
CP 障害時の挙動
HA クラスタ完成後(第4回以降)に k8s-cp-01 が停止した場合の動作を整理します。
- HAProxy の tcp-check が k8s-cp-01:6443 への接続失敗を検出し、k8s-cp-01 を DOWN マークする
- 以降の接続は k8s-cp-02・k8s-cp-03 にのみ転送される
- etcd: 3 ノードのうち 2 ノード稼働 = quorum(2)を満たす → etcd 継続動作
- 既存 Pod は kubelet が維持する(kubelet は API Server なしでもコンテナを維持する)
- CP-01 復旧後: HAProxy が tcp-check で UP 検出 → ラウンドロビンに自動復帰
この挙動のポイントは「自動検出・自動復帰」です。HAProxy の tcp-check が定期的にヘルスチェックを行うため、管理者が手動で設定変更する必要がありません。障害から復旧した CP ノードは自動でラウンドロビンに戻ります。
etcd quorum と Raft — 障害耐性の仕組みと偶数ノード非推奨の理由
HA クラスタで最も重要な概念の一つが etcd quorum です。「なぜ CP は 3 台なのか」「なぜ偶数ではいけないのか」という問いに答えられるようになることが、この節の目標です。
etcd と Raft の概要
etcd は分散 key-value store です。Kubernetes のすべての「状態」(Node / Pod / ConfigMap / Secret 等)をここに保存します。kubectl で見えるすべての情報は、最終的には etcd に格納されたデータから読み取られます。
etcd は Raft コンセンサスアルゴリズムを採用しています。複数の etcd インスタンスが同じデータを持つようにするための合意形成の仕組みです。Raft では各メンバーが次の 3 つのいずれかの役割を持ちます。
- Leader: 書き込みリクエストを受け付け、Follower にログエントリを複製する
- Follower: Leader からエントリを受け取り、自身のログに追記する
- Candidate: Leader が不在の場合に立候補し、過半数の票で Leader になる
書き込みが確定するには、quorum(多数決成立数)以上のメンバーから応答が必要です。quorum を維持できない状況(例: 過半数のメンバーが停止)では、書き込みが停止します。読み取りは継続できますが、etcd クラスタとしては「書き込み停止 = 機能停止」と同義です。
Quorum の計算式と障害耐性の表
quorum の計算式は次のとおりです。
quorum(多数決成立数)= ⌊N/2⌋ + 1
障害耐性 = ⌊(N-1)/2⌋この式をさまざまなメンバー数に適用した結果を表にします。
| メンバー数(N) | quorum | 障害耐性 | 備考 |
|---|---|---|---|
| 1 | 1 | 0 | 障害耐性なし |
| 2 | 2 | 0 | 障害耐性なし(1 台でも落ちると停止) |
| 3 | 2 | 1 | 本シリーズ採用(1 台障害まで許容) |
| 4 | 3 | 1 | 3 ノードと耐性同じ(コスト増のみ) |
| 5 | 3 | 2 | 大規模本番向け(2 台障害まで許容) |
| 7 | 4 | 3 | 最大規模構成 |
本シリーズは 3 CP ノード(stacked etcd 3 ノード)構成です。quorum=2・障害耐性=1 ノードです。3 台のうち 1 台が停止しても etcd クラスタは継続動作します。2 台が同時に停止すると etcd が停止し、kube-apiserver も停止します。
偶数ノードが非推奨な理由
「可用性を上げるために etcd を 4 ノードに増やす」という提案が現場でたまに出ます。これは誤った判断です。理由は 2 つあります。
1. コスト増に見合わない: N=4 の quorum=3、障害耐性=1。N=3 の障害耐性と同じです。ノードを 1 台増やしてもリソースコストが増えるだけで、障害耐性は向上しません。3 ノードから 5 ノードに増やすと障害耐性が 1 → 2 に向上しますが、4 ノードへの変更は全く意味がありません。
2. Split-brain リスクが増加する: ネットワーク分断(Network Partition)が発生した場合、偶数ノードでは両側の partition がそれぞれ「同数」のノードを持つ可能性があります。たとえば 4 ノードが 2:2 に分断された場合、どちらの partition も多数決(quorum=3)を満たせません。etcd クラスタ全体が書き込みを停止する「split-brain」状態になります。
奇数ノードでは分断が発生しても「多い方」の partition が必ず多数決を取れます。3 ノードが 2:1 に分断されると、2 ノード側が quorum(2)を満たし継続動作できます。1 ノード側は quorum を取れないため書き込みを停止しますが、これはデータの整合性を守るための正しい挙動です。
実践的な結論: etcd クラスタは 3 または 5(奇数)で構成します。「可用性向上」を理由に 4 ノードにする提案は断ります。5 ノードが必要な場合(2 台同時障害まで許容したい場合)は 5 ノードにします。
CKA 試験での出題傾向
CKA の D1 ドメイン(Cluster Architecture, Installation and Configuration・配点 25%)では、etcd quorum 計算と障害耐性の概念が出題されます。「3 ノード etcd でのノード障害数の上限は何か」という問題形式が頻出です。計算式(⌊N/2⌋ + 1)と N=3 の場合の値(quorum=2・耐性=1)を確実に答えられるようにしておきます。etcd メンバーの追加・削除操作(etcdctl member add/remove)は第5回で扱います。
HAProxy HA 設計 — frontend stats + k8s-api・backend CP×3・roundrobin・tcp-check
etcd quorum の概念を理解したところで、HAProxy の HA 設計に入ります。第2回で入れた最小パススルー設定と、第3回で作る HA 設計版の差分を確認してから、設定の詳細を解説します。
第2回の最小設定と第3回の HA 設計の差分
| 設定項目 | 第2回(最小) | 第3回(HA 設計版) |
|---|---|---|
frontend stats | なし | bind *:9000 / mode http / stats enable / stats uri /stats |
frontend k8s-api | bind *:6443 / mode tcp | 同じ(変更なし) |
backend k8s-cp-api | server k8s-cp-01 192.168.1.125:6443 check のみ | CP-01〜03 の 3 サーバ + balance roundrobin + option tcp-check |
frontend gateway-https | なし | なし(第11回で追加) |
| firewalld 9000/tcp | 未開放 | 開放(本回で追加) |
haproxy.cfg 全量
第3回で設定する haproxy.cfg の全量です。frontend gateway-https(:443 → Traefik)は第11回(Gateway API + Traefik 設置)で追加します。第3回には含めません。
global
log /dev/log local0
maxconn 4000
defaults
log global
timeout connect 5s
timeout client 10m
timeout server 10m
frontend stats
bind *:9000
mode http
stats enable
stats uri /stats
frontend k8s-api
bind *:6443
mode tcp
default_backend k8s-cp-api
backend k8s-cp-api
mode tcp
option tcp-check
balance roundrobin
server k8s-cp-01 192.168.1.125:6443 check
server k8s-cp-02 192.168.1.126:6443 check
server k8s-cp-03 192.168.1.127:6443 check第11回で frontend gateway-https(:443 → traefik-https)を追加します。現時点では含めません。
各設定の解説
global / defaults セクション: log /dev/log local0 は rsyslog 経由のログ出力設定です。maxconn 4000 は最大同時接続数の制限です。timeout connect 5s はバックエンドサーバへの接続確立タイムアウト、timeout client/server 10m はクライアント・サーバ側のアイドルタイムアウトです。API Server の watch ストリーム(kubectl の -w・controller-manager の reconcile)は数分〜長時間 keep-alive するため、ここを短くすると watch が再接続を繰り返してクラスタ運用に悪影響を与えます。kubeadm 公式の HAProxy リファレンス設定でも 10m 程度が採用されています。
frontend stats セクション: bind *:9000 で 9000 番ポートをすべてのインタフェースで受け付けます。mode http は HTTP モードです(stats ページは HTTP で提供するため)。stats enable で統計機能を有効化し、stats uri /stats でアクセスパスを /stats に設定します。ブラウザから http://192.168.1.124:9000/stats でアクセスすると、backend サーバの UP/DOWN・セッション数・応答時間を確認できる Web UI が表示されます。本番環境では stats auth user:password を追加して認証を設けますが、本シリーズは演習環境のため認証なしで設定します。
frontend k8s-api セクション: bind *:6443 で 6443 番ポートを受け付けます。mode tcp は TCP レイヤパススルーです。HAProxy は TLS を復号せず透過転送します。kube-apiserver の TLS 証明書の検証はクライアント(kubectl 等)が行います。API Server LB では mode tcp が唯一の正しい選択肢です。mode http を使うと HAProxy が TLS を終端しようとし、証明書設定が複雑になるため推奨されません。
backend k8s-cp-api セクション: balance roundrobin は接続ごとに CP-01 → CP-02 → CP-03 → CP-01 と順番に振り分けるアルゴリズムです。kubeadm HA では全 CP ノードが同じ etcd クラスタを参照するため、どのノードに転送しても結果は同一です。セッション維持(sticky session)は不要です。
option tcp-check は TCP 接続確立でヘルスチェックを行う設定です。6443 ポートに対して TCP 接続が成立すれば UP、接続拒否・タイムアウトなら DOWN と判定します。CP-02/03 は未 join(kube-apiserver 未起動)のため、第3回段階では DOWN 表示になります。これは想定内の状態です。第4回で kubeadm join --control-plane を実行して kube-apiserver が起動すると、次のヘルスチェックで UP になります。
server 行の IP アドレス指定について: server k8s-cp-01 192.168.1.125:6443 check のように IP アドレスで指定します。ホスト名(k8s-cp-01)を使わない理由は、HAProxy がホスト名解決に失敗する場合があるためです。HAProxy は backend サーバのホスト名解決を起動時に一度だけ行います。DNS が不安定な場合や起動タイミングによっては解決に失敗し、backend が UNAVAIL 状態になります。IP アドレスを直接指定すれば DNS への依存がなくなり、この問題を回避できます。詳細はヒヤリハットで後述します。
firewalld 9000/tcp 開放の必要性
第2回で 6443/tcp は開放済みです。stats ページ(9000/tcp)は第3回で新規に開放します。SELinux については、9000 番ポートは http_port_t に既定で含まれるため semanage port の追加設定は不要です。haproxy_connect_any ブール値も第2回で設定済みのため、第3回では追加設定は不要です。
やってみよう① — k8s-lb HAProxy を HA 設定に更新 + stats ページ確認
演習①です。k8s-lb の /etc/haproxy/haproxy.cfg を HA 設計版に書き換え、設定検証・reload・stats ページ確認を行います。作業場所は k8s-lb(192.168.1.124)です。k8s-ops から ssh developer@192.168.1.124 で接続し、root 作業を行います。
現在の haproxy.cfg を確認する
まず第2回の最小設定(SP_vol2-pre-03 の状態)を確認します。
実行コマンド:
# cat /etc/haproxy/haproxy.cfg実行結果(第2回最小設定・backend は k8s-cp-01 のみ):
global
log /dev/log local0
maxconn 4000
defaults
log global
timeout connect 5s
timeout client 10m
timeout server 10m
frontend k8s-api
bind *:6443
mode tcp
default_backend k8s-cp-api
backend k8s-cp-api
mode tcp
server k8s-cp-01 192.168.1.125:6443 checkfrontend stats がなく、backend に k8s-cp-01 しかないのが第2回最小設定です。これをこれから HA 設計版に書き換えます。
HA 設計版の haproxy.cfg に書き換える
ヒアドキュメントで全量を書き換えます。
実行コマンド:
# cat > /etc/haproxy/haproxy.cfg << 'EOF'
global
log /dev/log local0
maxconn 4000
defaults
log global
timeout connect 5s
timeout client 10m
timeout server 10m
frontend stats
bind *:9000
mode http
stats enable
stats uri /stats
frontend k8s-api
bind *:6443
mode tcp
default_backend k8s-cp-api
backend k8s-cp-api
mode tcp
option tcp-check
balance roundrobin
server k8s-cp-01 192.168.1.125:6443 check
server k8s-cp-02 192.168.1.126:6443 check
server k8s-cp-03 192.168.1.127:6443 check
EOFヒアドキュメント(<< 'EOF')を使うと、シングルクォートで囲んだ終端文字列(EOF)によりシェル変数の展開が抑制されます。$ を含む文字列を安全に書き込めます。frontend gateway-https(:443 → Traefik)は第11回で追加します。この時点では含めません。
設定ファイルの構文検証
reload の前に必ず構文検証を行います。設定に誤りがあっても reload がエラーになるだけで既存設定は継続しますが、事前に検証する習慣をつけます。
実行コマンド:
# haproxy -c -f /etc/haproxy/haproxy.cfg
# echo exit:$?実行結果(構文エラーなしの場合):
exit:0haproxy -c は設定ファイルの構文チェックのみを行い、実際には起動しません。HAProxy 3.0 系では構文が正しい場合は何も出力せず終了コード 0 を返すため、echo exit:$? で exit:0 を確認します。構文エラーがある場合は該当行とエラー内容が出力され、終了コードが非ゼロになります。よくある間違いは IP アドレスや行のインデント(スペース vs タブ)の誤りです。
HAProxy のサービス reload
構文検証が通ったら HAProxy を reload します。restart ではなく reload を使う理由は、reload がグレースフル(既存接続を切断せずに設定を反映する)だからです。restart は既存の TCP 接続をすべて切断します。本番稼働中の API Server LB を restart すると、kubectl の watch 接続や kube-controller-manager の通信が切れる可能性があります。
実行コマンド:
# systemctl reload haproxy実行コマンド(reload 後の状態確認):
# systemctl status haproxy実行結果:
● haproxy.service - HAProxy Load Balancer
Loaded: loaded (/usr/lib/systemd/system/haproxy.service; enabled; ...)
Active: active (running) since ...Active が active (running) であれば reload 成功です。reload 後に Active: failed になった場合は設定ファイルに問題があります。journalctl -u haproxy --no-pager | tail -20 でエラーメッセージを確認します。
firewalld で 9000/tcp を開放する
stats ページのポート(9000/tcp)を firewalld で開放します。
実行コマンド:
# firewall-cmd --permanent --add-port=9000/tcp
# firewall-cmd --reload実行コマンド(開放確認):
# firewall-cmd --list-ports実行結果:
6443/tcp 9000/tcp6443/tcp と 9000/tcp の両方が表示されれば開放済みです。--permanent フラグを付けないと、OS 再起動で設定が消えます。--permanent + firewall-cmd --reload をセットで実行する習慣をつけます。
stats ページをブラウザまたは curl で確認する
k8s-ops から curl で stats ページに接続できるかを確認します。
実行コマンド(k8s-ops で実行):
$ curl -s "http://192.168.1.124:9000/stats;csv" | grep k8s-cp | cut -d, -f1,2,18実行結果(CP-01 が UP・CP-02/03 が DOWN であることを確認):
k8s-cp-api,k8s-cp-01,UP
k8s-cp-api,k8s-cp-02,DOWN
k8s-cp-api,k8s-cp-03,DOWN
k8s-cp-api,BACKEND,UPHAProxy の stats ページは URL に ;csv を付けると CSV 形式で出力されます。上記コマンドは CSV の 1 列目(pxname)・2 列目(svname)・18 列目(status)だけを抜き出しています。k8s-cp-01 が UP、k8s-cp-02・k8s-cp-03 が DOWN、backend 全体(BACKEND)は 1 台でも UP があれば UP です。ホスト OS のブラウザから http://192.168.1.124:9000/stats(;csv なし)を開くと、カラフルな HAProxy 統計 UI で同じ状態を視覚的に確認できます。
DOWN 表示は k8s-cp-02/03 に kube-apiserver が未起動のため正常な状態です。「DOWN が出ているから設定が間違っている」という判断は誤りです。第4回で kubeadm join --control-plane を実行して kube-apiserver が起動すると、stats ページで UP に変わります。この変化がそのまま「HA クラスタが完成した」証拠になります。
k8s-ops からの kubectl 疎通確認
HAProxy HA 設定後も k8s-ops から kubectl が通ることを確認します。CP-02/03 が DOWN のため、HAProxy は全接続を CP-01 に転送します。
実行コマンド(k8s-ops で実行):
$ k get nodes実行結果(CP-01 のみ Ready の状態):
NAME STATUS ROLES AGE VERSION
k8s-cp-01 Ready control-plane 5h v1.35.5HAProxy が CP-01 に正しく転送できていることを確認できます。CP-02/03 は DOWN のためラウンドロビンから除外され、全接続が CP-01 に転送されます。これは option tcp-check によるヘルスチェックが正しく機能している結果です。
以上で演習①は完了です。k8s-lb の HAProxy が HA 設計版に更新され、stats ページで CP-01 UP / CP-02/03 DOWN(第4回 join まで正常な状態)が確認できました。
やってみよう② — etcd quorum 計算演習
演習②です。quorum の計算式を使い、さまざまな etcd クラスタ構成で障害耐性を求めます。CKA 試験で出題される典型的なパターンを練習します。計算自体は簡単ですが、「なぜその数になるか」まで答えられることが目標です。
問題(4 問)
次の 4 問を解きます。回答を見る前に自分で計算してみてください。計算式は quorum = ⌊N/2⌋ + 1、障害耐性 = ⌊(N-1)/2⌋ です。
問 1: etcd クラスタが 3 ノード構成のとき、クラスタを継続動作させるための最少稼働ノード数(quorum)はいくつか。また、同時に障害を許容できるノード数は最大何台か。
問 2: 5 ノード etcd クラスタで 2 台が同時に障害を起こした。クラスタは稼働を継続できるか。その理由を答えよ。
問 3: etcd クラスタを「より高い可用性のために」4 ノードに増やす提案がある。3 ノード構成と比べて障害耐性はどう変わるか。偶数ノードにすることの問題点を答えよ。
問 4: 本シリーズの 3 CP ノード(stacked etcd)構成で、k8s-cp-01 が停止した場合に etcd クラスタはどうなるか。k8s-cp-02 も追加で停止した場合はどうか。
回答と解説
問 1 回答: quorum = ⌊3/2⌋ + 1 = 1 + 1 = 2。最少稼働ノード数は 2。障害耐性 = ⌊(3-1)/2⌋ = ⌊1⌋ = 1。同時に障害を許容できるのは最大 1 台です。3 台のうち 1 台が停止しても残り 2 台が quorum を満たし、クラスタは継続動作します。2 台が同時に停止すると稼働は 1 台となり、quorum(2)を満たせないためクラスタは書き込みを停止します。
問 2 回答: 継続可能です。5 ノードのうち 2 台が停止すると稼働ノードは 3 台。5 ノードの quorum = ⌊5/2⌋ + 1 = 2 + 1 = 3。稼働 3 台 = quorum(3)を満たすため、クラスタは動作を継続します。5 ノード構成の障害耐性 = ⌊(5-1)/2⌋ = 2。2 台まで同時障害を許容できます。
問 3 回答: 4 ノードの quorum = ⌊4/2⌋ + 1 = 2 + 1 = 3。障害耐性 = ⌊(4-1)/2⌋ = ⌊1.5⌋ = 1。3 ノード構成と障害耐性は同じ(1 台)です。コストが増えるだけで可用性向上はありません。加えて、偶数ノードではネットワーク分断時に両 partition が同数のノードを持つ(たとえば 2:2 に分断)と、双方が quorum(3)を取れず全停止(split-brain)になるリスクがあります。3 ノードから 4 ノードへの変更は「コスト増・リスク増・耐性向上なし」という三重に意味のない変更です。
問 4 回答:
- k8s-cp-01 停止: etcd は 2/3 で稼働。quorum(2)を満たす。etcd 継続動作・kube-apiserver も CP-02/03 で継続動作。
- k8s-cp-02 も追加停止: etcd は 1/3 で稼働。quorum(2)を満たせない。etcd 停止 → kube-apiserver も停止(API Server は etcd への書き込みが必要なため)。ただし既存 Pod は kubelet が維持するため、動いているアプリは停止しません。
計算演習まとめ
quorum 計算は 1 分以内で解けます。CKA 試験では etcd バックアップ・リストア(第5回)と組み合わせた形式で出題されることが多いです。「3 ノード構成を前提として、同時障害許容は 1 台まで」という数字を目安として押さえておきます。本シリーズの 3 CP ノード構成でこの数字が意味することは、「1 台の CP ノードを止めてメンテナンスしても、残り 2 台でクラスタが動き続ける」ということです。
HA 用 kubeadm-config.yaml の設計確認(第4回 join への布石)
HAProxy の設定が完了したところで、第4回の kubeadm join --control-plane に向けた kubeadm-config.yaml の設計を確認します。第2回で作成済みのファイルを読み取り、HA 設計の観点で各フィールドを理解します。
第2回で作成済みの kubeadm-config.yaml を確認する
k8s-cp-01 に ssh して確認します。
実行コマンド(k8s-cp-01 で実行):
# cat /root/kubeadm-config.yaml実行結果(第2回で作成済み・全量):
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
kubernetesVersion: v1.35.5
controlPlaneEndpoint: "k8s-lb:6443"
networking:
podSubnet: "10.244.0.0/16"
serviceSubnet: "10.96.0.0/12"
---
apiVersion: kubeadm.k8s.io/v1beta4
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: "192.168.1.125"
bindPort: 64432 つのドキュメントが --- で区切られた YAML 形式です。ClusterConfiguration がクラスタ全体の設定、InitConfiguration がこのノード固有の設定です。
HA 設計の観点で各フィールドを再確認する
| フィールド | 値 | HA 設計での意味 |
|---|---|---|
controlPlaneEndpoint | k8s-lb:6443 | 全 CP ノードが共有するエンドポイント。CP-02/03 の join 時も kubeadm join k8s-lb:6443 と指定する |
kubernetesVersion | v1.35.5 | バージョンピン留め済み。CP-02/03 も同じバージョンで join する |
podSubnet | 10.244.0.0/16 | Calico が使用する Pod CIDR。全 CP・WL ノードで同じ CIDR を使用する |
localAPIEndpoint.advertiseAddress | 192.168.1.125 | CP-01 の実 IP。CP-02/03 の join 時は各ノードの IP に変わる(CP-02 は 192.168.1.126、CP-03 は 192.168.1.127) |
apiVersion: kubeadm.k8s.io/v1beta4 は K8s v1.35 に対応した API バージョンです。v1beta3 は Deprecated になっているため、v1beta4 を使います。
–upload-certs の有効期限と再アップロード方法
第2回の kubeadm init --upload-certs で、CP-02/03 が証明書を自動取得できるように証明書を etcd にアップロードしました。この証明書の有効期限は 2 時間です。
第3回から第4回の間隔が 2 時間を超える場合(複数日に分けて作業する場合など)、第4回の kubeadm join --control-plane 前に証明書の再アップロードが必要です。再アップロードのコマンドを以下に示します。
実行コマンド(k8s-cp-01 で実行・第4回 join 直前に実行する):
# kubeadm init phase upload-certs --upload-certs実行結果(新しい certificate-key が発行される):
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx実際の certificate-key 値は第4回の join 直前にこのコマンドを実行して確定します。出力された新しい certificate-key を使って第4回の join コマンドを実行します。有効期限切れのまま join を試みると、証明書取得が失敗して join が途中で止まります。
第4回で実行する join コマンドのプレビュー
第4回では k8s-cp-02/03 でそれぞれ次のコマンドを実行します。第3回では実行しません。「こういうコマンドを次回実行する」という布石として確認します。
# kubeadm join k8s-lb:6443 \
--token <token> \
--discovery-token-ca-cert-hash sha256:<hash> \
--control-plane \
--certificate-key <cert-key> \
--apiserver-advertise-address 192.168.1.126--apiserver-advertise-address に各 CP ノードの実 IP を指定します。CP-02 は 192.168.1.126、CP-03 は 192.168.1.127 です。<token> と <hash> は第2回の kubeadm init 出力か、kubeadm token create --print-join-command で再取得できます。<cert-key> は上記の --upload-certs 再アップロードで得た値を使います。
まとめ・現場ヒヤリハット・理解度チェック
まとめと次回予告
第3回で学んだことをまとめます。
- kubeadm HA クラスタの stacked etcd トポロジでは、etcd が各 CP ノードに同居する。3 CP ノード構成が最小推奨であり、本シリーズで採用するトポロジである
- etcd quorum =
⌊N/2⌋ + 1。3 ノード構成では quorum=2・障害耐性=1 ノード。1 台の CP ノードを止めてメンテナンスしても、残り 2 台でクラスタが継続動作する - 偶数ノードは 1 つ下の奇数ノードと障害耐性が同じうえ split-brain リスクもあるため非推奨。etcd クラスタは 3 または 5(奇数)で構成する
- HAProxy の TCP モード(
mode tcp)+option tcp-check+balance roundrobinが API Server LB の標準構成。mode httpは TLS パススルーができないため NG frontend stats(:9000)で HAProxy の backend UP/DOWN をリアルタイム確認できる。CP-02/03 未 join 段階では DOWN が正常。第4回 join 後に UP になるcontrolPlaneEndpoint: k8s-lb:6443は kubeadm init 時から設定済み。変更には証明書 SAN 再生成が必要なため、最初から LB アドレスを指定することがベストプラクティス--upload-certsの有効期限は 2 時間。複数日に分けて作業する場合は第4回 join 前にkubeadm init phase upload-certs --upload-certsで再アップロードが必要
第3回で押さえた HA 設計のポイントを表で整理します。
| 設計ポイント | 理由 |
|---|---|
| etcd は 3 または 5(奇数)ノード | 偶数は耐性向上なし・split-brain リスク増加 |
| HAProxy mode tcp(API Server LB) | TLS パススルーのため。mode http は TLS 終端が必要になり複雑 |
| backend に IP アドレスを使用 | ホスト名は DNS 依存で起動時に失敗リスク。IP 直指定で回避 |
| 設定反映は reload を使う(restart を避ける) | restart は既存接続を切断。reload はグレースフルに設定を反映 |
| controlPlaneEndpoint を最初から設定 | 後から変更すると証明書 SAN の再生成が必要な大掛かりな作業 |
次回(第4回)は本シリーズの最大の山場「kubeadm HA クラスタ構築」です。k8s-cp-02/03 に kubeadm join --control-plane を実行して Control Plane ×3 を完成させ、k8s-wl-01/02 を Workload Node として参加させます。HAProxy stats ページで全 backend が UP になることを確認し、第1巻で構築した fanclub-api を kind クラスタから kubeadm HA クラスタへ移行します。
現場ヒヤリハット
ヒヤリハット①(必須): backend の設定にホスト名を使ったら名前解決失敗で HAProxy が起動しなかった
状況: haproxy.cfg の server 行にホスト名(server k8s-cp-01 k8s-cp-01:6443 check)を記述した。haproxy -c の構文チェックは通過したが、systemctl start haproxy の直後に backend が全部 DOWN になり、しばらくすると UNAVAIL 状態になった。
原因: HAProxy は backend サーバのホスト名解決を起動時に一度だけ行います。本環境では alma-proxy の dnsmasq が DNS を提供していますが、HAProxy の起動タイミングで dnsmasq が未応答だった(または /etc/hosts に登録されていなかった)ため、名前解決に失敗して backend が UNAVAIL になりました。haproxy -c は設定ファイルの構文を検査するだけで、DNS 解決は行いません。このため構文チェックは通っても実際の起動で失敗します。
対処: server 行には必ず IP アドレスを使用します(server k8s-cp-01 192.168.1.125:6443 check)。HAProxy の DNS 動的解決は追加設定が必要で、基本設定では初回起動時の静的解決のみです。IP アドレスを使えば DNS への依存をなくせます。ホスト名を使いたい場合は /etc/hosts に登録する方法もありますが、IP アドレス直指定の方が確実です。
本記事の haproxy.cfg はすべて IP アドレスで記述しています(192.168.1.125:6443 等)。この理由がこのヒヤリハットです。設定ファイルを手書きで書く場合も、コピーペーストで書き換える場合も、server 行のホスト名・IP を間違えやすいです。設定後に必ず haproxy -c と stats ページの確認を行います。
ヒヤリハット②: 偶数ノード構成にして「可用性が上がった」と誤解した
状況: 「etcd ノードを 3 から 4 に増やすと可用性が上がる」という判断で、本番環境の etcd クラスタを 4 ノードに変更した。
実態: 障害耐性は 3 ノードと同じ「1 台まで」のままです。コストが増えただけです。さらにネットワーク分断が発生したとき、各側が 2 ノードずつ持つと双方が quorum(3)を取れず全体停止(split-brain)するリスクが増加しました。
対処: etcd は奇数(3 / 5 / 7)で構成します。可用性を上げるには 5 ノード構成にします(障害耐性 2 ノード)。4 ノードへの増設は「耐性は増えないのに管理対象が増え、split-brain リスクも増える」という三重の負担です。本シリーズの演習環境で使う 3 CP ノード構成でも、この判断基準を覚えておきます。
理解度チェック(○×形式・7 問)
以下の 7 問に○か×で答えてください。答えと解説は下に記載しています。
問 1: kubeadm HA クラスタの stacked etcd トポロジでは、etcd と Control Plane コンポーネントが同一ノード上で稼働する
問 2: 3 ノード etcd クラスタで 2 台が同時に停止した場合、クラスタは書き込みを継続できる
問 3: 偶数ノード(4 台)の etcd クラスタは、奇数ノード(3 台)よりも障害耐性が高い
問 4: HAProxy の mode http を API Server LB に使用すると、TLS の復号が必要になるため推奨されない
問 5: HAProxy stats ページで backend が DOWN と表示された場合、必ずその backend のサーバに障害が発生している
問 6: controlPlaneEndpoint は kubeadm init 後でも簡単に変更できる
問 7: kubeadm の --upload-certs オプションで etcd にアップロードされた証明書の有効期限は 2 時間である
— 答えと解説 —
問 1: ○ — stacked etcd では etcd インスタンスが各 Control Plane Node 上で Static Pod として稼働します。etcd と kube-apiserver・kube-controller-manager・kube-scheduler が同じノードに同居するのが stacked etcd の特徴です。
問 2: × — 3 ノード etcd の quorum = ⌊3/2⌋ + 1 = 2 です。2 台が停止すると稼働は 1 台となり、quorum(2)を満たせません。etcd クラスタは書き込みを停止します(読み取りは一部可能な場合もありますが、実質的に機能停止です)。
問 3: × — 4 ノードの quorum = ⌊4/2⌋ + 1 = 3、障害耐性 = ⌊(4-1)/2⌋ = 1 です。3 ノード構成と障害耐性は同じ(1 台)です。コストが増えるだけで可用性は向上しません。偶数ノードは split-brain リスクも増加します。
問 4: ○ — API Server は TLS を自身で終端するため、HAProxy では TCP レイヤパススルー(mode tcp)を使います。mode http を使うと HAProxy が TLS 終端を行う必要があり、証明書の設定が複雑になります。CKA 試験・本番環境ともに mode tcp が標準です。
問 5: × — 今回のように kube-apiserver が未起動(未 join)の場合も DOWN になります。DOWN はヘルスチェックが失敗している状態を示すものであり、原因はさまざまです。第4回で kubeadm join --control-plane 実行後に kube-apiserver が起動すると UP に変わります。DOWN がすべて障害を意味するわけではありません。
問 6: × — controlPlaneEndpoint を init 後に変更すると、API Server の TLS 証明書に含まれる SAN の再生成が必要です。本番稼働中クラスタではすべての CP ノードでの証明書更新・コンポーネント再起動が必要な大掛かりな作業になります。これを避けるために kubeadm init 時に最初から LB のエンドポイントを指定するのがベストプラクティスです。
問 7: ○ — --upload-certs で etcd にアップロードされた証明書は 2 時間で期限切れになります。複数日に分けて作業する場合は、第4回 join の直前に kubeadm init phase upload-certs --upload-certs を実行して新しい certificate-key を取得します。
シリーズ一覧
第1部:クラスタ構築
- 第1回 第2巻スコープ + CKA 試験形式紹介 + kubeadm 概要 + kubeadm vs RKE2/k0s/OKD 概観
- 第2回 kubeadm シングルノード起動(pkgs.k8s.io + kubeadm init + Calico CNI)+ alma-proxy whitelist 構築
- 第3回 kubeadm HA 設計 + HAProxy LB(API Server LB 構成) ← 今ここ
- 第4回 kubeadm HA クラスタ構築(CP×3 + WL×2)+ fanclub-api HA 移行
- 第5回 etcd backup/restore(etcdutl)+ ノード drain/uncordon
第2部:ワークロード管理
- 第6回 kubeadm upgrade + ノード drain/cordon + ミニトラブルシュート演習
- 第7回 Pod スケジューリング(taint/toleration/affinity/anti-affinity/PriorityClass)
- 第8回 HPA + ResourceQuota + LimitRange
第3部:ネットワーク
- 第9回 Service 詳細 + MetalLB(LoadBalancer 動作確認)
- 第10回 NetworkPolicy 詳細 + Calico/Cilium 比較 + ミニトラブルシュート演習
- 第11回 Gateway API + Traefik + cert-manager + CoreDNS(HTTPS 公開完成)
第4部:ストレージ
第5部:監視・運用
- 第13回 Prometheus + Grafana + Loki + Fluent Bit + fanclub-api 監視ダッシュボード
- 第14回 Helm + Kustomize でクラスタコンポーネント install + ArgoCD GitOps + Velero backup
