
新卒インフラエンジニア向け Kubernetes 実践教科書(第2巻 CKA 編)の第2回です。
動作確認バージョン: AlmaLinux 10.1 (Heliotrope Lion・kernel 6.12.0-124.56.5.el10_1) / K8s v1.35.5 / kubeadm・kubelet・kubectl v1.35.5 / containerd.io v2.2.4 / Calico v3.32.0 / HAProxy 3.0.5(2026-05-21 時点・k8s-cp-01 / k8s-lb 実機検証済)。
第1回ではオリエンテーションとして第2巻の全体像・CKA 試験形式・kubeadm の概要を把握し、第1巻で使った kind クラスタを削除しました。第2回からは本番想定クラスタの構築が始まります。
今回は Control Plane Node #1(k8s-cp-01)に kubeadm v1.35 をインストールし、シングルノードクラスタを起動します。alma-proxy の whitelist 拡張から始まり、OS 前提設定・containerd 設定・kubeadm init・Calico CNI インストールまでを通しで構築します。
この回が終わると kubectl get nodes でシングルノードが Ready 表示されます。
- 今ここマップ(第2回 / 全16回 / 第1部)
- 第2回のスコープと前提 — k8s-lb・k8s-cp-01 の初期状態
- 事前準備 — k8s-ops から各ノードへ SSH 公開鍵を配布する
- やってみよう① — alma-proxy whitelist 拡張(pkgs.k8s.io / projectcalico.docs.tigera.io)
- k8s-cp-01 の前提設定(proxy・dnf update・swap・カーネルモジュール・sysctl)
- containerd インストールと SystemdCgroup 設定
- kubeadm / kubelet / kubectl のインストール(pkgs.k8s.io・バージョンピン留め)
- k8s-lb 最小 HAProxy パススルー設定(第2回スコープ確認)
- やってみよう② — kubeadm init 実行(kubeadm-config.yaml v1beta4・–upload-certs)
- やってみよう③ — admin.conf を k8s-ops へ転送・alias k=kubectl 導入
- Calico CNI インストールとノード Ready 確認
- まとめ・現場ヒヤリハット・理解度チェック
- シリーズ一覧
今ここマップ(第2回 / 全16回 / 第1部)
今ここマップ(第2巻 16 回中の現在位置):
今ここ: 第2回 / 全16回(第1部:クラスタ構築)
▓▓░░░░░░░░░░░░░░ 12%
第1部(クラスタ構築): ■■□□□ 2/5 回(進行中)
第2部(ワークロード管理): □□□ 0/3 回
第3部(ネットワーク): □□□ 0/3 回
第4部(ストレージ): □ 0/1 回
第5部(監視・運用): □□ 0/2 回
第6部(トラブルシュート): □□ 0/2 回第2回で学ぶことは次の 5 点です。これがそのまま今回の学習目標になります。
- alma-proxy の Squid whitelist に
pkgs.k8s.ioとprojectcalico.docs.tigera.ioを追加し、k8s-cp-01 が Kubernetes パッケージを取得できる状態を作る - k8s-cp-01 に proxy 設定・swap 無効化・カーネルモジュール・sysctl・containerd(SystemdCgroup=true)を設定し、kubeadm init の前提条件を整える
- pkgs.k8s.io から kubelet / kubeadm / kubectl v1.35 をインストールし、dnf versionlock でバージョンをピン留めする
- k8s-lb に最小 HAProxy パススルー設定(6443 frontend → k8s-cp-01:6443 backend)を入れ、
kubeadm init --config kubeadm-config.yaml --upload-certsでシングルノードクラスタを起動する /etc/kubernetes/admin.confを k8s-ops に転送し、Calico CNI をインストールしてkubectl get nodesで Ready 確認する。alias k=kubectlを導入する
第2回終了時の達成状態を整理します。次回(第3回)以降の前提になる状態です。
- alma-proxy の whitelist に pkgs.k8s.io / projectcalico.docs.tigera.io が追加されている
- k8s-cp-01 に kubeadm v1.35 / kubelet v1.35 / kubectl v1.35 がインストール済み、かつ versionlock でピン留め済み
- k8s-lb に最小 HAProxy パススルー設定(6443 → k8s-cp-01:6443)が入っている
- k8s-cp-01 でシングルノードクラスタが起動し、Calico CNI が稼働している
- k8s-ops から
kubectl get nodesで k8s-cp-01 が Ready 表示される
今回は本番運用で踏み外してはいけないガードレールが 5 か所登場します。swap・SystemdCgroup・バージョンピン留め・controlPlaneEndpoint・カーネルモジュールの 5 つです。それぞれ「なぜこの設定が必要か」を本文中で必ず明示します。手順を機械的にコピーするだけでは、本番環境で再起動した瞬間にクラスタが壊れます。理由まで理解しながら進めてください。
第2回のスコープと前提 — k8s-lb・k8s-cp-01 の初期状態
具体的なコマンドに入る前に、今回「何を・どの VM で・どの順番で構築するのか」を整理します。フル構築回は手順が長くなるため、全体像を先に把握しておくと迷いません。
第2回で作業する VM 一覧
第2巻は全 9 VM 構成ですが、第2回で触るのは次の 4 VM です。残りの k8s-registry・k8s-cp-02/03・k8s-wl-01/02 は第2回では操作しません。
| VM | IP | 役割 | 第2回での作業 |
|---|---|---|---|
| alma-proxy | 192.168.1.121 | DNS / NTP / Squid プロキシ | whitelist 拡張 |
| k8s-ops | 192.168.1.122 | 作業端末 | admin.conf 受け取り・alias 設定・Calico apply |
| k8s-lb | 192.168.1.124 | HAProxy LB | 最小パススルー設定 |
| k8s-cp-01 | 192.168.1.125 | Control Plane Node #1 | フル構築(OS 設定・containerd・kubeadm・init) |
作業の起点は k8s-ops です。k8s-ops から SSH で各 VM に接続して作業します。SSH 経路はワークステーション → k8s-ops(192.168.1.122)→ 各 VM という 2 段構成です。k8s-cp-01 へは ssh developer@192.168.1.125 で接続します。developer ユーザーは全 cp/wl ノードで NOPASSWD の sudo が設定済みのため、root 作業は sudo を付けて実行します。
k8s-cp-01 の初期状態
k8s-cp-01 は素の AlmaLinux Minimal Install 直後の状態です。Kubernetes 関連は何も入っていません。第2回の前提スナップショット SP_vol2-pre-02 時点の初期値と、今回の作業で何をどう変更するかを表に整理します。
| 項目 | 初期値 | 第2回での変更 |
|---|---|---|
| OS | AlmaLinux 10.0(Purple Lion) | dnf update で 10.1(Heliotrope Lion)に更新 |
| kubeadm / kubelet / kubectl | 未導入 | pkgs.k8s.io から v1.35 をインストール |
| containerd | 未導入 | dnf でインストール + SystemdCgroup=true |
| swap | 有効(約 3.9 GB) | swapoff -a + /etc/fstab 編集 |
| カーネルモジュール | overlay / br_netfilter 未ロード | /etc/modules-load.d/k8s.conf で設定 |
| NIC | eth0 192.168.1.125/24 + eth1 10.0.10.125/24(2 NIC) | そのまま使用 |
| SELinux | Enforcing | Enforcing のまま維持 |
| プロキシ設定 | なし | /etc/profile.d/proxy.sh / /etc/dnf/dnf.conf に設定 |
初期 OS が 10.0 になっているのは、第2巻環境の構築時点が 10.0 だったためです。本巻の動作確認基準は AlmaLinux 10.1 のため、今回の前提設定の中で dnf update を実施して 10.1 に揃えます。
第2回の構築フロー全体図
今回触る 4 VM と、k8s-cp-01 の構築レイヤーの関係を図で示します。下から順に積み上げる構築です。
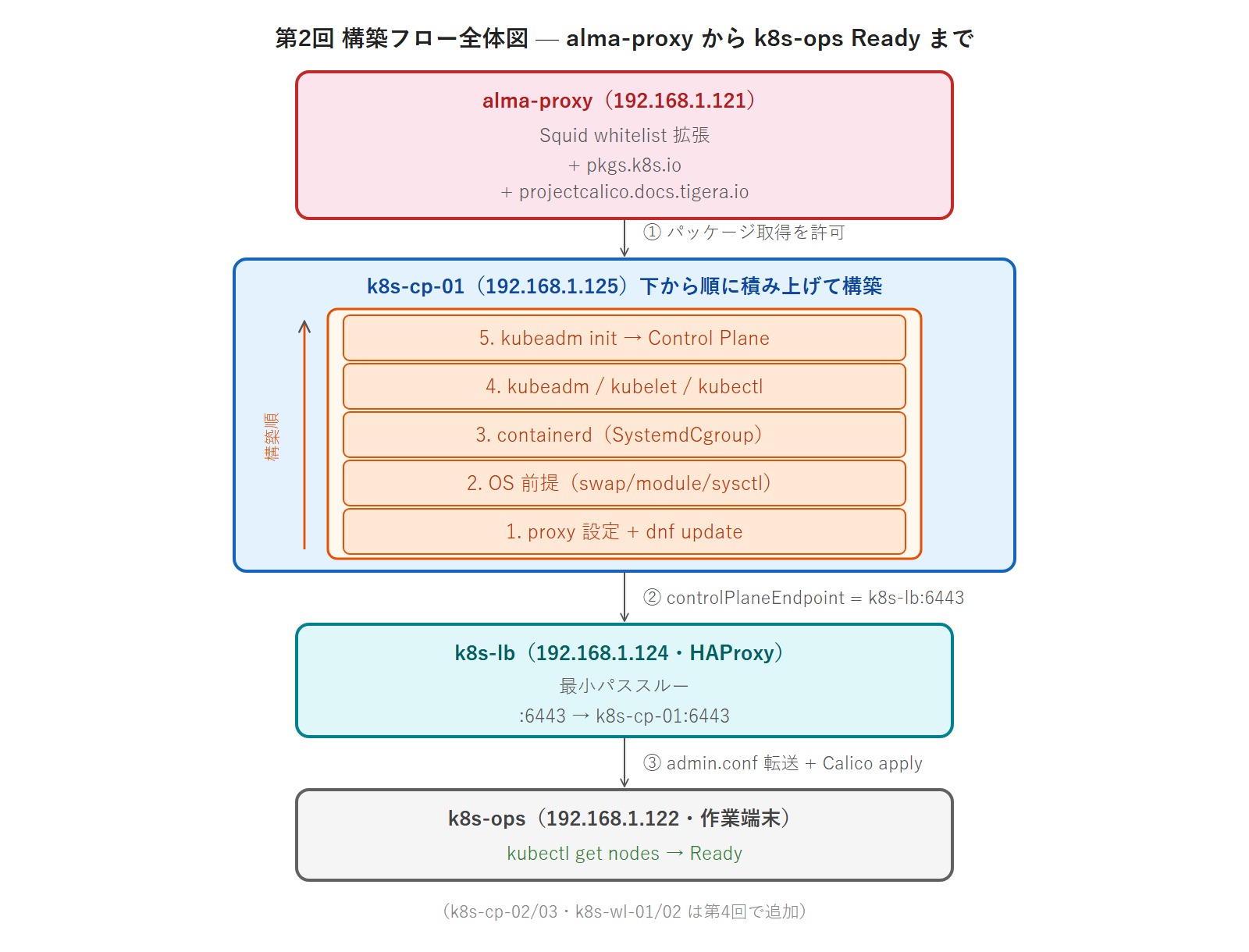
この図のとおり、k8s-cp-01 の構築は OS 前提設定 → containerd → kubeadm パッケージ → kubeadm init という積み上げ式です。下のレイヤーが完成していないと上のレイヤーは動きません。たとえば containerd の SystemdCgroup が誤っていると、その上の kubeadm init が途中で失敗します。順番を守ることが重要です。
第2回〜第4回の役割分担
第2回はシングルノードクラスタの起動までを行います。HA クラスタ(CP×3 + WL×2)の完成は第4回です。第2回から第4回までの役割分担を整理します。
[第2回] k8s-lb: 最小パススルー設定(6443 → k8s-cp-01:6443 のみ)
k8s-cp-01: kubeadm init でシングルノードクラスタ起動
↓
[第3回] k8s-lb: HAProxy HA 設計(CP×3 backend・stats・ヘルスチェック)
kubeadm-config.yaml の HA 設計
↓
[第4回] k8s-cp-02/03: kubeadm join --control-plane
k8s-wl-01/02: kubeadm join(Workload Node 参加)
→ 5 ノード HA クラスタ完成・fanclub-api HA 移行第2回は k8s-lb に「最小限」の設定しか入れません。stats ページや CP×3 の backend は第3回(HAProxy HA 設計の専門回)で作り込みます。第2回で k8s-lb を最小限だけ触る理由は次の項目で説明します。
controlPlaneEndpoint を今から設定する理由
これが今回 1 つ目の本番ガードレールです。kubeadm init では controlPlaneEndpoint というフィールドで「外部から API Server に接続する際のエンドポイント」を指定できます。今回はこれを k8s-lb:6443 に設定します。
第2回時点では Control Plane が k8s-cp-01 の 1 台しかありません。であれば controlPlaneEndpoint を指定せず、k8s-cp-01 の IP を直接エンドポイントにする方が一見シンプルに見えます。しかし、それは本番アンチパターンです。
controlPlaneEndpoint は kubeadm init の実行時にしか素直に設定できません。後から変更するには、API Server の TLS 証明書に含まれる SAN(Subject Alternative Name)を作り直す必要があります。SAN にはクラスタが受け付けるホスト名や IP が列挙されており、ここに新しいエンドポイントを追加するには証明書の再生成・各コンポーネントの再起動が必要です。本番稼働中のクラスタでこれを行うのは大掛かりな作業で、ダウンタイムのリスクも伴います。
第4回で k8s-cp-02/03 を kubeadm join --control-plane で追加するとき、join 先のエンドポイントは controlPlaneEndpoint です。最初から k8s-lb:6443 をエンドポイントにしておけば、第4回の HA 化は証明書を作り直さずに進められます。CKA でも「HA クラスタを構築する」際は controlPlaneEndpoint を最初から付けるのが定石です。第2回時点では k8s-lb の向き先が CP 1 台だけですが、エンドポイントを LB に向けておくこと自体に意味があります。
この設計判断のために、第2回で k8s-lb に最小パススルー設定を入れます。kubeadm init が controlPlaneEndpoint: k8s-lb:6443 を解決できるよう、k8s-lb の 6443 が k8s-cp-01 の 6443 に転送される状態を先に作っておく必要があるからです。
事前準備 — k8s-ops から各ノードへ SSH 公開鍵を配布する
第2回以降では k8s-ops(作業端末)から alma-proxy・k8s-cp-01〜03・k8s-wl-01〜02・k8s-lb の各ノードへ ssh developer@<ホスト> 形式で接続し、コマンドを実行します。第1巻時点では k8s-ops は kind クラスタの操作端末として使うだけで、他ノードへの SSH 鍵は配布されていません。第2回の各ステップに入る前に、k8s-ops で鍵ペアを生成し、各ノードの ~developer/.ssh/authorized_keys に公開鍵を登録します。この作業は第2巻全体で 1 回だけ実施すれば、第3回以降は鍵認証で透過的に接続できます。
実行コマンド(k8s-ops 上・developer 権限・鍵が未生成の場合のみ):
$ test -f ~/.ssh/id_ed25519 || ssh-keygen -t ed25519 -N "" -f ~/.ssh/id_ed25519 -C "developer@k8s-ops"
$ cat ~/.ssh/id_ed25519.pub続いて公開鍵を 7 ノードへ配布します。各ノードに対して ssh-copy-id を実行し、初回はパスワード(環境構築時に設定した developer のパスワード)を入力します。StrictHostKeyChecking=accept-new で初回ホスト鍵を自動承認します。実行コマンド:
$ for ip in 192.168.1.121 192.168.1.124 192.168.1.125 192.168.1.126 192.168.1.127 192.168.1.128 192.168.1.129; do
ssh-copy-id -o StrictHostKeyChecking=accept-new developer@$ip
done各ノードで「Number of key(s) added: 1」が表示されれば成功です。動作確認として 7 ノードに無パスワード SSH で hostname を叩きます。実行コマンド:
$ for ip in 192.168.1.121 192.168.1.124 192.168.1.125 192.168.1.126 192.168.1.127 192.168.1.128 192.168.1.129; do
echo -n "$ip: "; ssh -o BatchMode=yes developer@$ip hostname
done全 7 ノードのホスト名が返れば SSH 鍵セットアップ完了です。以降の演習はパスワード入力なしで進められます。
やってみよう① — alma-proxy whitelist 拡張(pkgs.k8s.io / projectcalico.docs.tigera.io)
最初の演習です。alma-proxy の Squid whitelist に Kubernetes パッケージリポジトリと Calico マニフェスト配信元の 3 ドメインを追加します。本シリーズの検証環境は企業ネットワークを再現するため、すべての外部通信が Squid プロキシの whitelist 方式を通ります。whitelist に登録されていないドメインへのアクセスは遮断されます。kubeadm パッケージを取得するには、まず通り道を開ける必要があります。
作業場所は alma-proxy(192.168.1.121)です。k8s-ops から ssh developer@192.168.1.121 で接続し、root 作業を行います。
ステップ 1:現在の whitelist を確認する
まず現状の whitelist を確認します。Squid の設定では /etc/squid/whitelist.txt を許可ドメインリストとして読み込んでいます。
実行コマンド:
# cat /etc/squid/whitelist.txt実行結果(抜粋・既存登録ドメインを確認):
.almalinux.org
repo.almalinux.org
download.docker.com
github.com
raw.githubusercontent.com
dl.k8s.io
.quay.io
.ghcr.io
registry.k8s.io
get.helm.sh第1巻と第2巻の準備で登録済みのドメインが並んでいます。注目すべきは registry.k8s.io・dl.k8s.io・.quay.io・.ghcr.io がすでにあることです。registry.k8s.io は Kubernetes のコンテナイメージ配信元で、kubeadm が pull する kube-apiserver・etcd 等のイメージはここから取得します。つまりイメージの通り道はすでに開いています。一方、kubeadm 本体の RPM パッケージを配る pkgs.k8s.io がリストにありません。これが今回追加するドメインです。
ステップ 2:pkgs.k8s.io と関連ドメインを追記する
3 ドメインを whitelist ファイルに追記します。pkgs.k8s.io は HTTP リダイレクトで実体である CDN ホスト prod-cdn.packages.k8s.io に転送されるため、両方を許可する必要があります。CDN ホストを忘れると dnf が CONNECT tunnel failed, response 403 でメタデータ取得に失敗します。
実行コマンド:
# echo 'pkgs.k8s.io' >> /etc/squid/whitelist.txt
# echo 'prod-cdn.packages.k8s.io' >> /etc/squid/whitelist.txt
# echo 'projectcalico.docs.tigera.io' >> /etc/squid/whitelist.txt追記されたことを確認します。
実行コマンド:
# grep -E 'pkgs.k8s.io|packages.k8s.io|projectcalico' /etc/squid/whitelist.txt実行結果:
pkgs.k8s.io
prod-cdn.packages.k8s.io
projectcalico.docs.tigera.ioステップ 3:squid を設定リロードする
whitelist ファイルを書き換えただけでは Squid に反映されません。設定リロードが必要です。squid -k reconfigure はサービスを停止せずに設定を読み直すコマンドです。稼働中の接続を切断しないため、本番でも安全に実行できます。
実行コマンド:
# squid -k reconfigure実行結果:
2026/05/20 23:03:38| Processing Configuration File: /etc/squid/squid.conf (depth 0)
2026/05/20 23:03:38| Set Current Directory to /var/spool/squid2 行(Processing Configuration File / Set Current Directory)が出れば正常です。既存 whitelist にサブドメイン重複(例: repo.almalinux.org と .almalinux.org の併存)がある場合は WARNING 行が追加で表示されますが、今回追加した 2 行とは無関係なので無視して構いません。
Squid が正常に稼働していることを確認します。
実行コマンド:
# systemctl status squid実行結果(active (running) であることを確認):
● squid.service - Squid caching proxy
Loaded: loaded (/usr/lib/systemd/system/squid.service; enabled; preset: disabled)
Active: active (running) since Mon 2026-05-04 18:53:45 JST; 2 weeks 2 days ago
Invocation: ce02835cd71a4d59aa85350ad79d1965
Docs: man:squid(8)Active が active (running) であれば whitelist 拡張は完了です。
補足(実機で遭遇しやすい落とし穴):Squid のバージョンや設定によっては、squid -k reconfigure だけでは whitelist.txt(ファイル参照型の dstdomain ACL)に追記したドメインが反映されないことがあります。追加したドメイン(例: pkgs.k8s.io)への curl が HTTP/1.1 403 Forbidden になり、dnf makecache が失敗する場合は、sudo systemctl restart squid で完全再起動してから再確認してください。access.log に TCP_DENIED/403 CONNECT pkgs.k8s.io:443 が記録されていれば ACL 未反映のサインです(既存ドメインは許可されるのに新規追加分だけ拒否される、という症状で切り分けられます)。再起動は稼働中の接続を一時切断しますが、本回の構築フェーズでは影響は限定的です。
追加した 3 ドメインの役割
今回追加した 3 ドメインの役割を整理します。
pkgs.k8s.io— kubeadm / kubelet / kubectl の公式 RPM リポジトリ。2024年3月に Google ホストの旧リポジトリ(packages.cloud.google.com)が完全廃止されたため、現在は唯一の公式 RPM 取得元。この回の構築はこのドメインが通らないと始まらないprod-cdn.packages.k8s.io—pkgs.k8s.ioがリダイレクトする CDN 配信ホスト。リポジトリのメタデータとパッケージ実体はここから配信されるため、pkgs.k8s.ioと必ずセットで whitelist 登録するprojectcalico.docs.tigera.io— Calico のドキュメントとマニフェスト配信元。Calico CNI のインストールマニフェスト(calico.yaml)に関連するドメイン
Calico の実体である calico.yaml は GitHub の raw.githubusercontent.com から取得し、Calico コンテナイメージは .quay.io または .ghcr.io から取得されます。これらはすべて whitelist に登録済みのため、CNI インストールも問題なく進みます。kubeadm がコントロールプレーンコンポーネント(kube-apiserver 等)を pull する registry.k8s.io も登録済みです。今回の追加は pkgs.k8s.io という 1 つの抜けを埋める作業がメインです。
alma-proxy の whitelist 拡張が完了しました。次のセクションから k8s-cp-01 の前提設定に入ります。
k8s-cp-01 の前提設定(proxy・dnf update・swap・カーネルモジュール・sysctl)
ここから k8s-cp-01 の構築に入ります。このセクションは「kubeadm init を実行できる状態まで OS を整える」工程です。手順は多いですが、一つひとつに kubeadm が正しく動くための理由があります。作業場所は k8s-cp-01 です。k8s-ops から ssh developer@192.168.1.125 で接続します。
プロキシ設定(/etc/profile.d/proxy.sh・/etc/dnf/dnf.conf)
k8s-cp-01 はインターネットへ直接出られません。すべての外部通信を alma-proxy(192.168.1.121:3128)経由にする必要があります。シェル環境変数として http_proxy / https_proxy / no_proxy を設定します。
ここが今回の最重要ガードレールです。no_proxy には「プロキシを経由しないアドレス」を列挙します。社内 IP レンジ(192.168.1.0/24・10.0.10.0/24)、Kubernetes の Service CIDR(10.96.0.0/12)・Pod CIDR(10.244.0.0/16)、クラスタ内ドメイン(.svc・.cluster.local)に加え、クラスタを構成する全ノードのホスト名(k8s-lb・k8s-cp-01〜03・k8s-wl-01〜02 など)を必ず含めます。
ホスト名を含めることが、なぜ IP レンジを含めるだけでは不十分なのか。理由は kubeadm init の挙動にあります。kubeadm init をプロキシ環境変数付き(sudo -E)で実行すると、kubeadm は http_proxy / https_proxy / no_proxy を kube-apiserver・kube-controller-manager・kube-scheduler の Static Pod、および kube-proxy DaemonSet の環境変数として自動的に埋め込みます。これらのコンポーネントは API Server へ controlPlaneEndpoint に設定したホスト名 k8s-lb:6443 で接続します。プログラムのプロキシ判定はホスト名の文字列で no_proxy を照合するため、no_proxy に IP レンジ 192.168.1.0/24 があっても、ホスト名 k8s-lb がマッチせず接続が alma-proxy 経由になります。alma-proxy は whitelist 外の内部ホストへの接続を 403 Forbidden で拒否するため、kube-proxy がサービスルーティングを構成できず、CNI も起動せず、クラスタが Ready になりません。
この障害は「kube-proxy のログに Forbidden が出続ける」「ノードが NotReady のまま」という形で現れますが、原因が Kubernetes の RBAC ではなくプロキシ設定にあるため発見が難しい落とし穴です。no_proxy に全ノードのホスト名を入れておけば確実に回避できます。
実行コマンド(k8s-cp-01 で root 作業):
# cat > /etc/profile.d/proxy.sh << 'EOF'
export http_proxy=http://192.168.1.121:3128
export https_proxy=http://192.168.1.121:3128
export no_proxy=localhost,127.0.0.1,192.168.1.0/24,10.0.10.0/24,10.96.0.0/12,10.244.0.0/16,.svc,.cluster.local,k8s-lb,k8s-ops,k8s-registry,k8s-cp-01,k8s-cp-02,k8s-cp-03,k8s-wl-01,k8s-wl-02,alma-proxy
EOF
# source /etc/profile.d/proxy.shdnf もプロキシを経由させます。/etc/dnf/dnf.conf に proxy 行を追記します。
実行コマンド:
# echo 'proxy=http://192.168.1.121:3128' >> /etc/dnf/dnf.confプロキシ設定が効いているか、whitelist 登録済みのドメインへの疎通で確認します。
実行コマンド:
# curl -sI https://pkgs.k8s.io/ | head -n 1実行結果(プロキシ経由の CONNECT 確立を示す行が返れば疎通成功):
HTTP/1.1 200 Connection establishedこれは Squid(alma-proxy)が HTTPS の CONNECT メソッドに対して返す応答です。HTTP/1.1 200 Connection established は「プロキシが target ホスト(pkgs.k8s.io)への TCP トンネルを確立した」という意味で、これが返れば proxy 経由で pkgs.k8s.io に到達できる状態が確認できます。
dnf update(AlmaLinux 10.0 → 10.1 へ更新)
k8s-cp-01 の初期 OS は AlmaLinux 10.0 です。本巻の動作確認基準である 10.1 に揃えるため、dnf update を実行します。
実行コマンド:
# dnf update -y更新が完了したら OS バージョンを確認します。
実行コマンド:
# cat /etc/almalinux-release実行結果:
AlmaLinux release 10.1 (Heliotrope Lion)※ 2026年5月下旬以降に dnf update を実行した場合、AlmaLinux 10.2(Lavender Lion)に更新される場合があります。本シリーズは AlmaLinux 10.1 / 10.2 のいずれでも同手順で動作確認しています。
AlmaLinux 10.1 のコードネームは「Heliotrope Lion」です。マイナーバージョンごとにコードネームが付きます(10.0 は Purple Lion)。
dnf update ではカーネルも更新される場合があります。新しいカーネルを有効化するには再起動が必要です。再起動が必要かどうかを確認するコマンドを実行します。
実行コマンド:
# dnf needs-restarting -rAlmaLinux 10 Minimal Install には独立した needs-restarting コマンド(dnf-utils 提供)は含まれないため、dnf needs-restarting サブコマンド形式で実行します。
実行結果(再起動が必要な場合・更新内容により対象は変動):
起動以降にコアライブラリーまたはサービスがアップデートされました:
* linux-firmware
* microcode_ctl
* systemd
これらのアップデートを完全に活用するには、再起動が必要です。
詳細情報: https://access.redhat.com/solutions/27943カーネル更新を含む場合は reboot で再起動し、再ログイン後に作業を続行します。動作確認バージョンに記載するカーネル番号は、再起動後の実機値で確定します。本記事の動作確認バージョン欄が「kernel 6.12.x」のように記載されている場合、x は実機検証で確定した値です。
swap 無効化(kubeadm / kubelet 起動の必須要件)
これが今回 2 つ目の本番ガードレールです。Kubernetes の kubelet は swap が有効な状態だと正常に動作しません。kubelet は Pod に割り当てたメモリ量を正確に管理する必要があり、swap によってメモリがディスクへ退避されると、その前提が崩れるためです。kubeadm の preflight check も swap を検出するとエラーにします。したがって、kubeadm init の前に swap を無効化する必要があります。
まず実行中の swap を無効化します。
実行コマンド:
# swapoff -aここで重要なのは、swapoff -a だけでは不十分という点です。swapoff -a は「今この瞬間の swap を無効化する」コマンドであり、再起動すると /etc/fstab の設定に従って swap が復活します。再起動後も swap を無効に保つには、/etc/fstab の swap 行をコメントアウトする必要があります。
実行コマンド(/etc/fstab の swap エントリをコメントアウト・再起動後も無効化を維持):
# sed -i.bak '/swap/s/^/#/' /etc/fstabこのコマンドは /etc/fstab 内の swap を含む行の先頭に # を付けてコメントアウトします。-i.bak により編集前のファイルが /etc/fstab.bak として保存されるため、誤った場合は復元できます。
AlmaLinux 10.x では systemd-fstab-generator が起動時に /etc/fstab の swap エントリから動的に dev-disk-by\x2duuid-xxx.swap ユニットを生成する仕組みを持っています。/etc/fstab をコメントアウトすればこの generate も止まるはずですが、まれに古い generated unit が残って次回起動時に swap が再有効化される事例があります。確実を期すなら以下の daemon-reload を実行して generated unit を更新し、現在 active な swap unit があれば mask します。実行コマンド:
# systemctl daemon-reload
# systemctl list-unit-files --type=swap --no-pager
# SWAP_UNIT=$(systemctl list-units --type=swap --no-pager --no-legend | awk '{print $1}' | head -1)
# [ -n "$SWAP_UNIT" ] && systemctl mask "$SWAP_UNIT"swap が無効化されたことを確認します。
実行コマンド:
# free -h実行結果(Swap の total が 0 になることを確認):
total used free shared buff/cache available
Mem: 3.6Gi XXXMi XXXMi XXXMi XXXMi XXXGi
Swap: 0B 0B 0BSwap 行の total が 0B であれば無効化成功です。swapoff -a と /etc/fstab の編集はセットで行います。片方だけでは、再起動した瞬間に kubelet が起動しなくなります。この落とし穴は今回の現場ヒヤリハットで詳しく扱います。
カーネルモジュール設定(overlay / br_netfilter)
これが今回 3 つ目の本番ガードレールです。Kubernetes ノードには 2 つのカーネルモジュールが必要です。
overlay— containerd がコンテナイメージのレイヤを重ね合わせる OverlayFS で使用する。これがないとコンテナイメージの展開が不安定になるbr_netfilter— Linux ブリッジを通過するパケットを iptables で処理できるようにする。Kubernetes の Service・NetworkPolicy は iptables(または ipvs)に依存するため、ブリッジ経由の Pod 間トラフィックを iptables で扱えないとネットワークが正しく機能しない
これらのモジュールがロードされていないと、containerd や Pod ネットワークが不安定になります。再起動後も自動でロードされるよう /etc/modules-load.d/k8s.conf に登録します。
実行コマンド:
# cat > /etc/modules-load.d/k8s.conf << 'EOF'
overlay
br_netfilter
EOFこのファイルは再起動時のロード設定です。今この瞬間にもロードするため、modprobe を実行します。
実行コマンド:
# modprobe overlay
# modprobe br_netfilterロードされたことを確認します。
実行コマンド:
# lsmod | grep -E 'overlay|br_netfilter'実行結果:
br_netfilter 36864 0
bridge 417792 1 br_netfilter
overlay 245760 0br_netfilter をロードすると依存モジュールの bridge も自動でロードされます。3 つの行が表示されればモジュールの準備は完了です。
sysctl 設定(iptables・ip_forward)
カーネルモジュールをロードしただけでは不十分で、対応するカーネルパラメータ(sysctl)を有効にする必要があります。3 つのパラメータを設定します。
net.bridge.bridge-nf-call-iptables = 1— ブリッジを通過する IPv4 パケットを iptables で処理する。Service・NetworkPolicy の動作に必須net.bridge.bridge-nf-call-ip6tables = 1— 同じく IPv6 パケット用net.ipv4.ip_forward = 1— ノードを通過する IP パケットの転送を許可する。Pod ネットワークのルーティングに必須
これらを /etc/sysctl.d/k8s.conf に記述します。/etc/sysctl.d/ 配下のファイルは再起動後も自動で読み込まれます。
実行コマンド:
# cat > /etc/sysctl.d/k8s.conf << 'EOF'
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF設定を即座に反映します。sysctl --system は /etc/sysctl.d/ 配下を含むすべての設定ファイルを読み直します。
実行コマンド:
# sysctl --system実行結果(適用確認の抜粋):
* Applying /etc/sysctl.d/k8s.conf ...
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 13 つのパラメータが = 1 で適用されていれば成功です。net.bridge.bridge-nf-call-iptables が表示されない場合は、前のステップで br_netfilter モジュールがロードされていない可能性があります。lsmod | grep br_netfilter で再確認してください。
firewalld ポート開放(Control Plane Node 向け)
本シリーズは firewalld を有効のまま運用します。Control Plane Node が必要とするポートを開放します。各ポートの用途は次のとおりです。
| ポート | 用途 |
|---|---|
| 6443/tcp | kube-apiserver(クラスタ API のエンドポイント) |
| 2379-2380/tcp | etcd(クライアント通信 2379・ピア通信 2380) |
| 10250/tcp | kubelet API |
| 10257/tcp | kube-controller-manager |
| 10259/tcp | kube-scheduler |
実行コマンド:
# firewall-cmd --permanent --add-port=6443/tcp
# firewall-cmd --permanent --add-port=2379-2380/tcp
# firewall-cmd --permanent --add-port=10250/tcp
# firewall-cmd --permanent --add-port=10257/tcp
# firewall-cmd --permanent --add-port=10259/tcp
# firewall-cmd --reload--permanent は再起動後も設定を保持するオプション、--reload は永続設定を実行中の firewalld に反映するコマンドです。開放されたポートを確認します。
実行コマンド:
# firewall-cmd --list-ports実行結果:
2379-2380/tcp 6443/tcp 10250/tcp 10257/tcp 10259/tcpSELinux 確認(Enforcing 維持)
SELinux は Enforcing のまま維持します。kubeadm の古いインストール手順には SELinux を Permissive にする例が登場しますが、本シリーズではセキュリティを保つため Enforcing を維持します。まず現状を確認します。
実行コマンド:
# getenforce実行結果:
EnforcingAlmaLinux 10 + kubeadm v1.35 では、container-selinux パッケージがコンテナランタイム向けの SELinux ポリシーを提供します。このパッケージは containerd のインストール時に依存パッケージとして自動導入されます。containerd インストール後に rpm -q container-selinux で導入を確認できます。container-selinux が入っていれば、SELinux を Enforcing のまま kubeadm init が通ります。SELinux を Permissive に下げる必要はありません。
k8s-lb の名前解決確認
後の kubeadm init では controlPlaneEndpoint: k8s-lb:6443 を指定します。k8s-cp-01 が k8s-lb というホスト名を IP に解決できないと、init がエラーになります。名前解決は alma-proxy 上の dnsmasq(192.168.1.121)が担います。
実行コマンド:
# getent hosts k8s-lbAlmaLinux 10 Minimal Install には nslookup(bind-utils 提供)が含まれません。代わりに glibc 標準の getent hosts を使えば NSS(/etc/nsswitch.conf)の解決順に従って名前解決を確認できます。
実行結果(dnsmasq または /etc/hosts で解決できる場合):
192.168.1.124 k8s-lbk8s-lb が 192.168.1.124 に解決されれば問題ありません。もし dnsmasq に k8s-lb のエントリがなく解決できない場合は、保険として /etc/hosts に直接エントリを追加します。
実行コマンド(名前解決できない場合のみ実施):
# echo '192.168.1.124 k8s-lb' >> /etc/hosts/etc/hosts は DNS より優先して参照されます。dnsmasq で解決できている場合に追記しても、同じ IP を指すため害はありません。kubeadm init の controlPlaneEndpoint が解決できないとクラスタ起動が失敗するため、ここで確実に解決できる状態にしておきます。
これで k8s-cp-01 の OS 前提設定が完了しました。プロキシ・OS バージョン・swap・カーネルモジュール・sysctl・ファイアウォール・名前解決のすべてが整いました。次のセクションでコンテナランタイムである containerd を導入します。
作業端末 k8s-ops 側でも /etc/hosts を整備
後で admin.conf を k8s-ops に転送して kubectl を使う際、k8s-ops 側でも k8s-lb の名前解決が必要になります。k8s-ops の /etc/resolv.conf は外部 DNS(8.8.8.8 等)を参照しているため、内部ホスト名 k8s-lb は解決できません。kubectl 実行時に dial tcp: lookup k8s-lb on 8.8.8.8:53: no such host エラーで止まらないよう、ここで /etc/hosts に内部ホスト名 7 件をまとめて追加します。
実行コマンド(k8s-ops で developer 作業):
$ sudo tee -a /etc/hosts << 'EOF'
192.168.1.124 k8s-lb
192.168.1.125 k8s-cp-01
192.168.1.126 k8s-cp-02
192.168.1.127 k8s-cp-03
192.168.1.128 k8s-wl-01
192.168.1.129 k8s-wl-02
EOF第4回の kubeadm join でも各ノードからホスト名解決が必要なので、第2回時点で全 7 件まとめて追加しておくと後の回が楽になります。
containerd インストールと SystemdCgroup 設定
Kubernetes は Pod を動かすためにコンテナランタイムを必要とします。本シリーズでは containerd を使います。Kubernetes は CRI(Container Runtime Interface)という標準インタフェース経由でコンテナランタイムと通信し、containerd はその CRI を実装しています。このセクションでは containerd を導入し、Kubernetes が正しく動くための設定を行います。作業場所は k8s-cp-01 です。
containerd のインストール
AlmaLinux 10 の標準リポジトリ(BaseOS / AppStream / CRB / Extras)には containerd パッケージが含まれていません。本シリーズでは Docker CE 公式リポジトリ(download.docker.com)から containerd.io を導入します。Docker CE の whitelist は第1巻で alma-proxy に登録済みなので proxy 経由で取得できます。
まず Docker CE のリポジトリ定義ファイルを取得します。
実行コマンド:
# curl -fsSL -o /etc/yum.repos.d/docker-ce.repo https://download.docker.com/linux/rhel/docker-ce.repo続けて containerd.io パッケージをインストールします。
実行コマンド:
# dnf install -y containerd.ioインストール時に container-selinux が依存パッケージとして導入されます。前のセクションで触れたとおり、これにより SELinux を Enforcing のまま運用できます。インストール後にバージョンを確認します。
実行コマンド:
# containerd --version実行結果(バージョンは実機検証で確定):
containerd containerd.io v2.2.4 193637f7ee8ae5f5aa5248f49e7baa3e6164966econtainer-selinux が導入されたことも確認しておきます。
実行コマンド:
# rpm -q container-selinux実行結果(パッケージ名とバージョンが表示されれば導入済み):
container-selinux-4:2.240.0-10.el10_1.noarchcontainerd デフォルト設定の生成
containerd の設定ファイルは /etc/containerd/config.toml です。インストール直後はこのファイルが最小限の内容、または存在しない状態のことがあります。containerd config default でデフォルト設定の全量を出力し、それをファイルに書き込みます。
実行コマンド:
# containerd config default | tee /etc/containerd/config.tomltee は標準入力を画面に表示しつつ、同時にファイルへ書き込むコマンドです。これで /etc/containerd/config.toml に containerd のデフォルト設定が全量書き込まれました。次のステップでこの設定の一部を変更します。
SystemdCgroup = true への変更
これが今回 4 つ目の本番ガードレールであり、フル構築回の中でも特に重要な設定です。containerd のデフォルト設定では cgroup ドライバの設定 SystemdCgroup が false になっています。これを true に変更します。
cgroup(control group)は、Linux がプロセスのリソース(CPU・メモリ)を制限・管理する仕組みです。AlmaLinux 10 は cgroup v2 がデフォルトです。cgroup v2 環境では、systemd 自身が cgroup 階層を管理します。このとき、Kubernetes の kubelet とコンテナランタイムの両方が「同じ cgroup ドライバ」を使う必要があります。
kubelet はデフォルトで systemd cgroup ドライバを期待します。一方、containerd のデフォルト設定(SystemdCgroup = false)は cgroupfs ドライバを使います。両者が食い違うと、Pod 作成時に cgroup の操作が衝突し、kubelet が不安定になります。具体的には、kube-apiserver や etcd の Static Pod が起動しない、あるいは起動してもすぐに落ちるという症状が出ます。kubeadm init がこの食い違いのために途中で失敗することもあります。
したがって、containerd config default で生成した直後の SystemdCgroup = false は必ず true に変更します。sed で一括変更します。
実行コマンド:
# sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml変更されたことを確認します。
実行コマンド:
# grep SystemdCgroup /etc/containerd/config.toml実行結果:
SystemdCgroup = trueこの設定は [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] セクション内にあります。grep の出力が SystemdCgroup = true であれば変更成功です。false のままだと、後の kubeadm init で時間をかけてエラーに突き当たることになります。ここで確実に true を確認しておきます。
registry config_path の有効化(hosts.toml 方式の前提)
もうひとつ重要な設定があります。containerd v2 系はレジストリ個別設定を /etc/containerd/certs.d/<host:port>/hosts.toml から読み込む「hosts.toml 方式」に統一されましたが、これを有効化するには config.toml の config_path をディレクトリパスに変更する必要があります。デフォルトは空文字列(config_path = '')で、空のままだと hosts.toml をいくら書いても読み込まれず、insecure registry 設定(第4回で使用)が効きません。
該当箇所は [plugins.'io.containerd.cri.v1.images'.registry] セクション直下の config_path 行です。sed で一括変更します。なお、containerd 2.2.x ではダブルクォート版 [plugins."io.containerd.cri.v1.images".registry] の場合があり、その際は下記 sed が当たりません。失敗時は vi /etc/containerd/config.toml での手動編集を推奨します。
実行コマンド:
# sed -i "/\[plugins.'io.containerd.cri.v1.images'.registry\]/{n;s|config_path = ''|config_path = '/etc/containerd/certs.d'|}" /etc/containerd/config.toml変更されたことを確認します。
実行コマンド:
# grep -A1 "cri.v1.images'.registry" /etc/containerd/config.toml | head -2実行結果:
[plugins.'io.containerd.cri.v1.images'.registry]
config_path = '/etc/containerd/certs.d'config_path = '/etc/containerd/certs.d' になっていれば成功です。本回では /etc/containerd/certs.d/ 配下にはまだ何も置きませんが、第4回で fanclub-api をデプロイする際にプライベートレジストリ(k8s-registry)への insecure 設定をここに置きます。設定をいま入れておくことで、第4回でその場で気づいて慌てる事態を避けられます。
containerd の再起動と自動起動設定
設定ファイルを変更しただけでは containerd に反映されません。再起動が必要です。同時に、ノード再起動後も containerd が自動で立ち上がるよう enable も設定します。
実行コマンド:
# systemctl restart containerd
# systemctl enable containerdcontainerd が正常に稼働していることを確認します。
実行コマンド:
# systemctl status containerd実行結果(active (running) であることを確認):
● containerd.service - containerd container runtime
Loaded: loaded (/usr/lib/systemd/system/containerd.service; enabled; preset: disabled)
Active: active (running) since Mon 2026-05-19 09:30:00 JSTActive が active (running)、Loaded の行に enabled と表示されていれば、containerd の準備は完了です。SystemdCgroup = true の変更後に再起動を忘れると古い設定のまま稼働し続けるため、設定変更後は必ず systemctl restart containerd を実行します。
kubeadm / kubelet / kubectl のインストール(pkgs.k8s.io・バージョンピン留め)
コンテナランタイムが整ったので、次は Kubernetes 本体のツール群をインストールします。kubeadm(クラスタ構築ツール)・kubelet(ノードエージェント)・kubectl(操作 CLI)の 3 つを pkgs.k8s.io からインストールし、バージョンをピン留めします。作業場所は k8s-cp-01 です。
pkgs.k8s.io リポジトリの設定(v1.35 ピン)
pkgs.k8s.io は Kubernetes コミュニティが運営する公式の RPM / DEB パッケージリポジトリです。2024年3月4日に旧 Google ホストリポジトリ(packages.cloud.google.com)が完全廃止されたため、現在はこの pkgs.k8s.io が唯一の公式 RPM 取得元です。
pkgs.k8s.io はマイナーバージョンごとに専用のリポジトリ URL が用意されています。たとえば v1.35 系は core:/stable:/v1.35、v1.34 系は core:/stable:/v1.34 という具合です。第2巻では K8s v1.35 を使うため、v1.35 専用リポジトリのみを設定します。/etc/yum.repos.d/kubernetes.repo を作成します。
実行コマンド:
# cat > /etc/yum.repos.d/kubernetes.repo << 'EOF'
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF各設定項目の意味を整理します。baseurl がパッケージの取得元、gpgcheck=1 はパッケージの GPG 署名検証を有効にする設定、gpgkey は検証に使う公開鍵の URL です。署名検証を有効にすることで、改ざんされたパッケージのインストールを防げます。リポジトリを設定したらメタデータのキャッシュを更新します。
実行コマンド:
# dnf makecachednf makecache が pkgs.k8s.io からメタデータを取得できれば、whitelist 拡張とプロキシ設定が正しく機能している証拠です。ここでエラーが出る場合は、alma-proxy の whitelist に pkgs.k8s.io が登録されているか、k8s-cp-01 のプロキシ設定が正しいかを確認します。
kubelet / kubeadm / kubectl のインストール
3 つのパッケージをまとめてインストールします。kubernetes.repo に exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni を設定しているため、明示的に --disableexcludes=kubernetes を指定して exclude を一時解除します。第15回・第16回のトラブルシュート演習で crictl を使うため、同時に cri-tools もインストールしておくと後の回が楽になります。
実行コマンド:
# dnf install -y --disableexcludes=kubernetes kubelet kubeadm kubectl cri-toolsインストールされたバージョンを確認します。
実行コマンド(kubeadm のバージョン確認):
# kubeadm version実行結果:
kubeadm version: &version.Info{Major:"1", Minor:"35", EmulationMajor:"", EmulationMinor:"", MinCompatibilityMajor:"", MinCompatibilityMinor:"", GitVersion:"v1.35.5", GitCommit:"6636cbce3bbef91ff61d36658757179426f9e1b2", GitTreeState:"clean", BuildDate:"2026-05-12T09:53:04Z", GoVersion:"go1.25.9", Compiler:"gc", Platform:"linux/amd64"}実行コマンド(kubectl のバージョン確認):
# kubectl version --client実行結果:
Client Version: v1.35.5
Kustomize Version: v5.7.1実行コマンド(kubelet のバージョン確認):
# kubelet --version実行結果:
Kubernetes v1.35.53 つとも v1.35.5(2026-05-19 時点)が表示されれば成功です。pkgs.k8s.io の stable/v1.35 リポジトリは v1.35 系の最新パッチバージョンを提供するため、実際にインストールされる X(パッチ番号)は時間経過とともに進む可能性があります。本記事の動作確認バージョンは v1.35.5 で確定しています。
バージョンピン留め(dnf versionlock)
これが今回 5 つ目の本番ガードレールです。インストールしたばかりの kubeadm / kubelet / kubectl のバージョンを「ピン留め」します。ピン留めとは、これらのパッケージが dnf upgrade で意図せず更新されないよう固定することです。
なぜピン留めが必要かを説明します。Kubernetes には「バージョンスキューポリシー」というルールがあり、kubelet と kube-apiserver のバージョン差は一定範囲内に収める必要があります。OS の定期メンテナンスで dnf upgrade を実行したとき、もし kubelet だけが新しいマイナーバージョンに上がってしまうと、API Server とのバージョン差がポリシー違反になり、ノードが正しく動作しなくなります。
さらに、第6回では kubeadm upgrade によるクラスタのバージョンアップを演習として扱います。このとき「意図したバージョンへ意図したタイミングで上げる」ことが重要です。dnf upgrade で勝手に kubeadm が上がってしまうと、第6回の演習の前提が崩れます。本番運用でも、クラスタのバージョンアップは計画的に実施すべき作業であり、OS パッケージ更新に巻き込まれて勝手に上がるのはアンチパターンです。
dnf でバージョンを固定するには versionlock プラグインを使います。まずプラグインをインストールします。
実行コマンド:
# dnf install -y python3-dnf-plugin-versionlockプラグインのパッケージ名は環境によって python3-dnf-plugin-versionlock または dnf-plugin-versionlock となる場合があります。本記事ではコマンド例として前者を記載しますが、実機検証で確定したパッケージ名に従ってください。プラグインを導入したら、3 つのパッケージをロック対象に追加します。
実行コマンド:
# dnf versionlock add kubelet kubeadm kubectlロックが設定されたことを確認します。
実行コマンド:
# dnf versionlock list実行結果(パッケージ名とバージョンは実機検証で確定):
kubelet-0:1.35.5-150500.1.1.*
kubeadm-0:1.35.5-150500.1.1.*
kubectl-0:1.35.5-150500.1.1.*3 つのパッケージがリストに表示されれば、以降は dnf upgrade を実行してもこれらは更新されません。第6回でクラスタをバージョンアップする際は、dnf versionlock delete でロックを一時解除してから目的のバージョンへ更新し、再度ロックする流れになります。
kubelet の自動起動設定
kubelet をノード再起動後も自動で立ち上がるよう設定します。
実行コマンド:
# systemctl enable kubeletここで systemctl start kubelet はまだ実行しません。kubeadm init を実行する前の時点では、kubelet は起動に必要な設定ファイル(/var/lib/kubelet/config.yaml など)をまだ持っていないためです。この段階で systemctl status kubelet を見ると、kubelet が起動と停止を繰り返している状態が確認できますが、これは正常です。kubeadm init が必要な設定ファイルを配置すると、kubelet は正常に起動するようになります。今は enable だけ済ませておき、起動は kubeadm init に任せます。
これで k8s-cp-01 の準備が完了しました。OS 前提設定・containerd・kubeadm パッケージのすべてが整い、kubeadm init を実行できる状態になりました。次に、init の前提となる k8s-lb の最小設定を行います。
k8s-lb 最小 HAProxy パススルー設定(第2回スコープ確認)
このセクションでは k8s-lb に HAProxy をインストールし、最小限のパススルー設定を入れます。「最小限」という点が重要です。HAProxy の本格的な HA 設計は第3回の専門回で扱います。作業場所は k8s-lb(192.168.1.124)です。k8s-ops から ssh developer@192.168.1.124 で接続します。
第2回と第3回の役割分担
k8s-lb の HAProxy 設定について、第2回と第3回で何をどこまでやるかを明確にします。
| 回 | k8s-lb の HAProxy 設定 |
|---|---|
| 第2回(本回) | 最小パススルー(:6443 → k8s-cp-01:6443 のみ) |
| 第3回 | HA 本格設計(CP×3 backend・stats ページ・ヘルスチェック・gateway frontend 追加) |
この分担にした理由を説明します。kubeadm init では controlPlaneEndpoint: k8s-lb:6443 を指定するため、第2回時点で「k8s-lb:6443 が k8s-cp-01 に転送される」状態が必要です。これがないと init が成功しません。一方、HAProxy の HA 設計(複数 backend の負荷分散・ヘルスチェック・stats ページ)は第3回が専門回として扱います。そこで第2回では「init が通る最小限」だけを入れ、HA 設計は第3回に集中させます。第2回の HAProxy 設定には CP-02/03 の backend や stats ページは含めません。
k8s-lb の前提設定(proxy・dnf update)
k8s-lb の初期状態も AlmaLinux 10.0 Minimal Install で、k8s-cp-01 と同じく proxy 設定と OS 更新が必要です。k8s-cp-01 で実施した手順と同じ流れで設定します。
実行コマンド(k8s-lb で root 作業):
# cat > /etc/profile.d/proxy.sh << 'EOF'
export http_proxy=http://192.168.1.121:3128
export https_proxy=http://192.168.1.121:3128
export no_proxy=localhost,127.0.0.1,192.168.1.0/24,10.0.10.0/24,10.96.0.0/12,10.244.0.0/16,.svc,.cluster.local,k8s-lb,k8s-ops,k8s-registry,k8s-cp-01,k8s-cp-02,k8s-cp-03,k8s-wl-01,k8s-wl-02,alma-proxy
EOF
# source /etc/profile.d/proxy.sh
# echo 'proxy=http://192.168.1.121:3128' >> /etc/dnf/dnf.conf
# dnf update -ydnf update でカーネル更新が含まれる場合は reboot で再起動します。k8s-lb は HAProxy のような軽量サーバのみ稼働するため、ここで一度再起動しても影響は限定的です。
HAProxy のインストール
HAProxy を dnf でインストールします。
実行コマンド:
# dnf install -y haproxyバージョンを確認します。
実行コマンド:
# haproxy -v | head -1実行結果:
HAProxy version 3.0.5-8e879a5 2024/09/19 - https://haproxy.org/最小パススルー設定の記述
HAProxy の設定ファイル /etc/haproxy/haproxy.cfg を、最小パススルー設定で上書きします。
実行コマンド:
# cat > /etc/haproxy/haproxy.cfg << 'EOF'
global
log /dev/log local0
maxconn 4000
defaults
log global
timeout connect 5s
timeout client 10m
timeout server 10m
frontend k8s-api
bind *:6443
mode tcp
default_backend k8s-cp-api
backend k8s-cp-api
mode tcp
server k8s-cp-01 192.168.1.125:6443 check
EOF設定内容を整理します。frontend k8s-api が *:6443(全インタフェースの 6443 ポート)で待ち受け、backend k8s-cp-api へ転送します。backend には k8s-cp-01 の 6443 だけを登録しています。mode tcp は TCP レイヤでそのまま転送する設定で、これにより HAProxy は API Server の TLS 通信を復号せずパススルーします。server 行末尾の check は backend の死活監視を有効にするオプションです。第3回ではこの backend に k8s-cp-02・k8s-cp-03 を追加し、stats ページや Gateway 用 frontend を加えていきます。
HAProxy の起動と確認
設定ファイルを起動前に検証します。haproxy -c は設定ファイルの構文チェックを行うオプションです。
実行コマンド:
# haproxy -c -f /etc/haproxy/haproxy.cfg
# echo exit:$?実行結果(HAProxy 3.0 系は -c 単独だと成功時に出力なしのため exit code で判定):
exit:0続いて SELinux 対応です。本シリーズは SELinux を Enforcing で運用するため、HAProxy が標準外ポート 6443 にバインドするには事前に port label の追加が必要です。これを忘れると HAProxy 起動時に cannot bind socket (Permission denied) でエラーになります。
実行コマンド:
# dnf install -y policycoreutils-python-utils
# semanage port -a -t http_port_t -p tcp 6443
# setsebool -P haproxy_connect_any 1
# semanage port -l | grep http_port_t実行結果(6443 が http_port_t に登録されたことを確認):
http_port_t tcp 6443, 80, 81, 443, 488, 8008, 8009, 8443, 9000
http_port_t udp 80, 443SELinux 対応が済んだら HAProxy を起動します。
実行コマンド:
# systemctl enable --now haproxy
# systemctl is-active haproxy実行結果:
activeactive と表示されれば HAProxy が稼働中です。systemctl status haproxy で詳細ログを確認すれば backend k8s-cp-01 への接続確認も走っていることが分かります(この時点では API Server 未起動のため DOWN 表示で正常)。
firewalld ポート開放(k8s-lb 向け)
k8s-lb でも 6443 ポートを開放します。第2回では 6443 だけ開放します(stats 用 9000・Gateway 用 80/443 は第3回以降)。
実行コマンド:
# firewall-cmd --permanent --add-port=6443/tcp
# firewall-cmd --reloadk8s-cp-01 から k8s-lb:6443 への疎通確認
k8s-cp-01 から k8s-lb の 6443 ポートに接続できるか確認します。AlmaLinux 10 Minimal Install には nc が含まれないため、bash 組み込みの /dev/tcp 疑似デバイスを使います。/dev/tcp/<host>/<port> への書き込みは TCP 接続を試行し、成功すれば exit 0 を返します。このコマンドは k8s-cp-01 で実行します。
実行コマンド(k8s-cp-01 で実行):
# timeout 3 bash -c 'echo > /dev/tcp/192.168.1.124/6443' && echo TCP接続OK || echo TCP接続失敗実行結果:
TCP接続OKここで補足があります。この時点では k8s-cp-01 の API Server がまだ起動していません。HAProxy は 6443 で接続を受け付けますが、転送先の k8s-cp-01:6443 で待ち受けているプロセスがないため、HAProxy 側のログには backend DOWN と記録されます。それは正常な状態です。重要なのは「HAProxy 自体が 6443 で待ち受けている」ことで、TCP接続OK が返れば HAProxy への到達は確認できています。kubeadm init 完了後に API Server が起動すると、この経路が完全に通るようになります。
これで kubeadm init の前提がすべて整いました。k8s-cp-01 の OS・containerd・kubeadm パッケージ、k8s-lb のパススルー設定、そして名前解決とプロキシ。次のセクションでいよいよクラスタを起動します。
やってみよう② — kubeadm init 実行(kubeadm-config.yaml v1beta4・–upload-certs)
第2回の中核となる演習です。k8s-cp-01 で kubeadm init を実行し、シングルノードクラスタを起動します。作業場所は k8s-cp-01 です。
kubeadm-config.yaml の作成
kubeadm init はコマンドラインオプションだけでも実行できますが、本シリーズでは設定ファイル(kubeadm-config.yaml)を使う方式を採用します。設定ファイル方式には、構成内容を Git で管理できる・第4回の HA 構成へ拡張しやすい・設定の意図が明示的に残るという利点があります。CKA でも設定ファイルを扱えることが求められます。
設定ファイルを作成します。kubeadm の設定 API バージョンは v1beta4 を使います。ファイルは 2 つのドキュメント(ClusterConfiguration と InitConfiguration)を --- で区切った構成です。
実行コマンド(k8s-cp-01 で root 作業):
# cat > /root/kubeadm-config.yaml << 'EOF'
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
kubernetesVersion: v1.35.5
controlPlaneEndpoint: "k8s-lb:6443"
networking:
podSubnet: "10.244.0.0/16"
serviceSubnet: "10.96.0.0/12"
---
apiVersion: kubeadm.k8s.io/v1beta4
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: "192.168.1.125"
bindPort: 6443
EOF各フィールドの意味を整理します。
| フィールド | 値 | 意味 |
|---|---|---|
| kubernetesVersion | v1.35.5 | インストールする K8s バージョン(pkgs.k8s.io の stable/v1.35 と整合させる) |
| controlPlaneEndpoint | k8s-lb:6443 | 外部から API Server に接続するエンドポイント(LB 経由・HA 化の前提) |
| podSubnet | 10.244.0.0/16 | Pod に割り当てるネットワーク CIDR(Calico が使用) |
| serviceSubnet | 10.96.0.0/12 | Service の ClusterIP 割り当て範囲 |
| advertiseAddress | 192.168.1.125 | この Control Plane Node の実 IP(API Server がバインドするアドレス) |
| bindPort | 6443 | API Server が待ち受けるポート |
ここで kubernetesVersion について補足します。この値は、前のセクションで実際にインストールした kubeadm のバージョンと一致させる必要があります。pkgs.k8s.io の stable/v1.35 リポジトリは v1.35 系の最新パッチを提供するため、本記事の実機検証時点では v1.35.5 がインストールされました。kubeadm version -o short で確認したバージョンを kubernetesVersion に設定します。両者が食い違うと kubeadm init がコントロールプレーンイメージの取得で不整合を起こすため、必ず一致させます。
コントロールプレーンイメージの事前 pull
kubeadm init は内部でコンテナイメージを pull します。事前に pull しておくと、init コマンド本体の所要時間が短くなり、また「イメージ取得が正しくできるか」を init 前に確認できます。この手順は任意ですが、プロキシ環境では事前確認の意味で実施しておくと安心です。
実行コマンド:
# kubeadm config images pull --config /root/kubeadm-config.yaml実行結果(registry.k8s.io からイメージを pull):
[config/images] Pulled registry.k8s.io/kube-apiserver:v1.35.5
[config/images] Pulled registry.k8s.io/kube-controller-manager:v1.35.5
[config/images] Pulled registry.k8s.io/kube-scheduler:v1.35.5
[config/images] Pulled registry.k8s.io/kube-proxy:v1.35.5
[config/images] Pulled registry.k8s.io/coredns/coredns:v1.13.1
[config/images] Pulled registry.k8s.io/pause:3.10.1
[config/images] Pulled registry.k8s.io/etcd:3.6.6-0イメージはすべて registry.k8s.io から取得されます。このドメインは alma-proxy の whitelist に登録済みのため、プロキシ経由で取得できます。ここでイメージ取得エラーが出る場合は、whitelist と containerd のプロキシ設定(コンテナランタイムのプロキシは別途設定が必要なことがある)を確認します。
kubeadm init の実行
クラスタを起動します。--config で設定ファイルを指定し、--upload-certs オプションを付けます。所要時間は環境にもよりますが 3〜5 分程度です。
--upload-certs は、Control Plane の証明書をクラスタ内(kube-system 名前空間の Secret)に暗号化して保存するオプションです。これにより、第4回で k8s-cp-02/03 を追加するときに、それらのノードが証明書を自動取得できます。--upload-certs を付けないと、第4回で追加 Control Plane Node に手動で証明書をコピーする必要が生じます。HA 構成を前提とする本シリーズでは、第2回の init 時点で付けておきます。なお、アップロードされた証明書を解読するための certificate-key は 2 時間で失効します(第4回では必要に応じて再アップロードします)。
実行コマンド:
# kubeadm init --config /root/kubeadm-config.yaml --upload-certs実行結果(成功時の出力・token / hash はプレースホルダー):
[init] Using Kubernetes version: v1.35.5
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join k8s-lb:6443 --token xxxxxx.xxxxxxxxxxxxxxxx \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
--control-plane --certificate-key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-lb:6443 --token xxxxxx.xxxxxxxxxxxxxxxx \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxYour Kubernetes control-plane has initialized successfully! と表示されればクラスタの初期化が成功しています。出力には 2 種類の kubeadm join コマンドが含まれます。--control-plane が付くものは Control Plane Node 追加用(第4回で k8s-cp-02/03 に使用)、付かないものは Workload Node 追加用(第4回で k8s-wl-01/02 に使用)です。これらの join コマンドは第4回で必要になるため、出力をコピーして保存しておきます。トークンの有効期限は 24 時間ですが、第4回で kubeadm token create により再発行できるため、期限が切れても問題ありません。
本記事の xxxxxxxxxxxx 部分は実機ごとに異なる値です。読者の環境では実際の token・hash・certificate-key が表示されます。
kubeadm init で何が起きたか
kubeadm init が内部で行ったことを処理フローとして整理します。
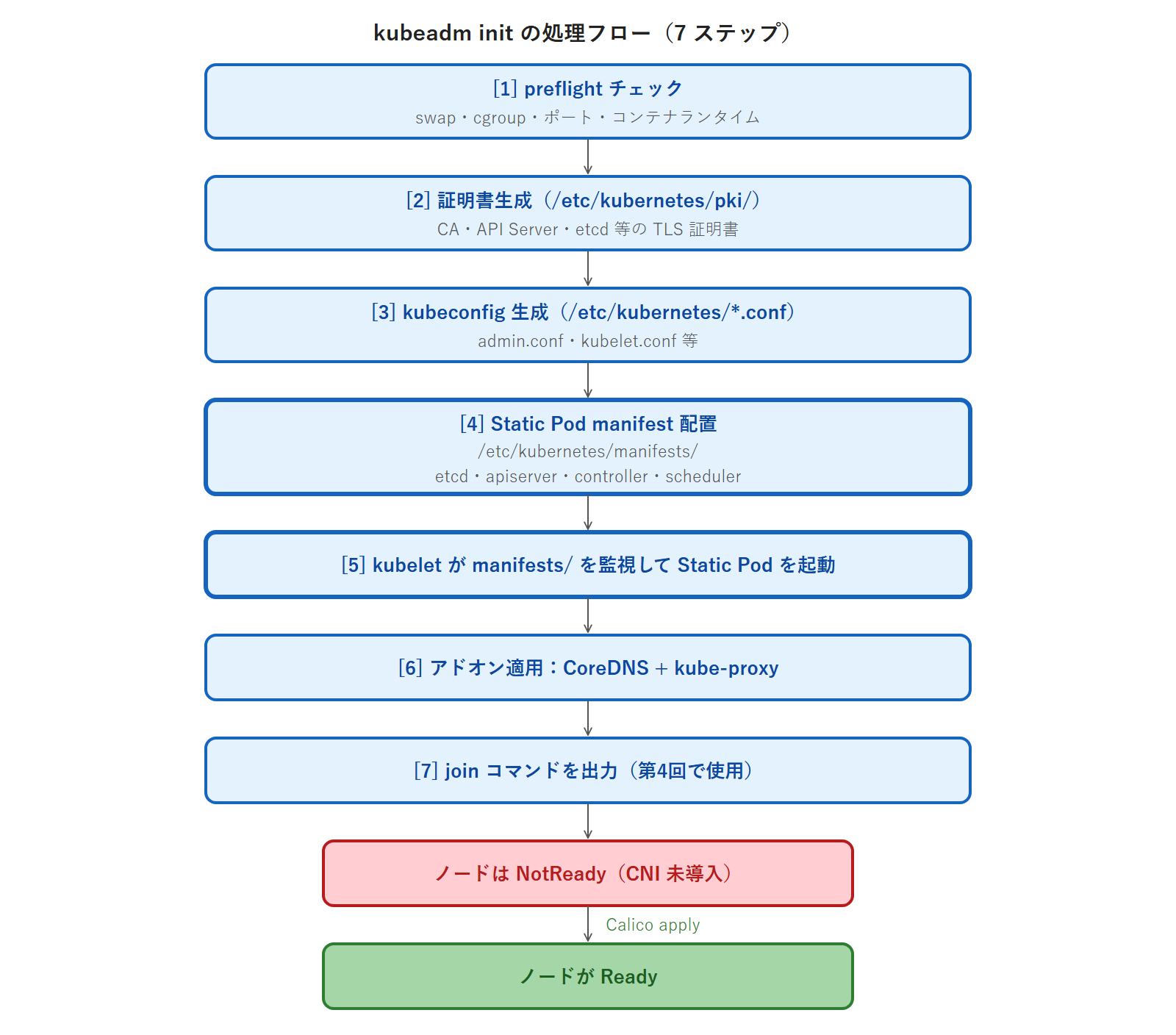
この流れの中で特に重要なのが [4] と [5] です。kubeadm は Control Plane コンポーネントを「Static Pod」として配置します。Static Pod は API Server を介さず、ノード上の kubelet が直接管理する Pod です。
Static Pod の確認
Static Pod の manifest が配置されたディレクトリを確認します。
実行コマンド:
# ls /etc/kubernetes/manifests/実行結果:
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml/etc/kubernetes/manifests/ にある 4 つの YAML が Static Pod です。kubelet はこのディレクトリを常時監視しており、YAML ファイルが存在する限り対応する Pod を起動・再起動します。etcd(クラスタ状態の保存先)・kube-apiserver(API のエンドポイント)・kube-controller-manager(各種コントローラ)・kube-scheduler(Pod の配置決定)という 4 つの Control Plane コンポーネントが、この仕組みで稼働します。
このパスは CKA 試験でも頻出です。たとえば「kube-apiserver が起動しない」という障害では、/etc/kubernetes/manifests/kube-apiserver.yaml の設定ミスが原因のことが多く、このファイルを直接編集して修正します。第15回のトラブルシュート演習でこのパスを直接扱います。今の段階では「Control Plane は Static Pod として動いている」「manifest は /etc/kubernetes/manifests/ にある」という 2 点を覚えておいてください。
やってみよう③ — admin.conf を k8s-ops へ転送・alias k=kubectl 導入
kubeadm init でクラスタは起動しましたが、まだ k8s-cp-01 のローカルでしか操作できません。本シリーズの運用方針では、クラスタ操作は作業端末の k8s-ops から行います。このセクションでは、init が生成した認証情報(admin.conf)を k8s-ops に転送し、k8s-ops から kubectl が使える状態を作ります。
admin.conf とは何か
/etc/kubernetes/admin.conf は kubeadm init が生成する kubeconfig ファイルです。クラスタの API Server エンドポイント・CA 証明書・管理者権限のクライアント証明書が含まれています。kubectl はこのファイル(通常 ~/.kube/config に配置)を読んで、どのクラスタにどの権限で接続するかを決めます。admin.conf はクラスタ管理者の全権限を持つ認証情報のため、取り扱いには注意が必要です。
k8s-cp-01 上で admin.conf を一時コピーする
/etc/kubernetes/admin.conf は root 所有のファイルです。k8s-ops の developer ユーザーが scp で直接取得することはできません。そこで、developer が読める場所に一時コピーし、所有者を developer に変更します。一時的とはいえクラスタ管理者の認証情報を扱うため、全ユーザー可読の chmod 644 ではなく、所有者を developer に変更したうえで chmod 600(所有者のみ読み書き可)にします。
実行コマンド(k8s-cp-01 で root 作業):
# cp /etc/kubernetes/admin.conf /tmp/admin.conf
# chown developer:developer /tmp/admin.conf
# chmod 600 /tmp/admin.confこれで /tmp/admin.conf は developer ユーザーが読めて、かつ他のユーザーからは読めない状態になりました。
k8s-ops へ admin.conf を転送する
k8s-ops に移動して、scp で admin.conf を取得し ~/.kube/config として配置します。この作業は k8s-ops で developer ユーザーとして行います。
実行コマンド(k8s-ops で developer 作業):
$ mkdir -p ~/.kube
$ scp developer@192.168.1.125:/tmp/admin.conf ~/.kube/config
$ chmod 600 ~/.kube/config実行結果(scp 成功時):
admin.conf 100% 5648 5.5MB/s 00:00~/.kube/config も chmod 600 で所有者のみ読めるようにします。kubeconfig のパーミッションが緩いと、kubectl が警告を出すことがあります。
一時ファイルの削除
転送が終わったら、k8s-cp-01 上の一時コピーを削除します。認証情報を不要に残さないためです。
実行コマンド(k8s-cp-01 で root 作業):
# rm -f /tmp/admin.confkubectl get nodes で接続確認
k8s-ops から kubectl でクラスタに接続できるか確認します。
実行コマンド(k8s-ops で developer 作業):
$ kubectl get nodes実行結果(CNI 未インストールの段階では NotReady):
NAME STATUS ROLES AGE VERSION
k8s-cp-01 NotReady control-plane 2m v1.35.5k8s-cp-01 が一覧に表示されました。これは k8s-ops からクラスタへの接続が成功したことを意味します。ただし STATUS は NotReady です。これは異常ではなく、想定どおりの状態です。kubeadm は CNI(Container Network Interface)を含まないため、この時点では Pod ネットワークが確立しておらず、ノードは NotReady になります。次のセクションで Calico CNI を適用すると Ready に変わります。
alias k=kubectl の導入
第1回の次回予告で触れたとおり、第2回で alias k=kubectl を導入します。kubectl は打鍵数が多いコマンドで、クラスタ操作のたびに入力するのは非効率です。k という短縮エイリアスを設定します。
このエイリアスは CKA 試験対策としても重要です。CKA 試験環境にはあらかじめ alias k=kubectl が設定されており、受験者は k get nodes・k apply -f・k describe pod といった短縮形を使えます。日常的に k を使う習慣をつけておくと、試験本番で違和感なく操作でき、限られた試験時間を節約できます。
実行コマンド(k8s-ops で developer 作業):
$ echo 'alias k=kubectl' >> ~/.bashrc
$ source ~/.bashrcエイリアスが効くか確認します。
実行コマンド:
$ k get nodes実行結果:
NAME STATUS ROLES AGE VERSION
k8s-cp-01 NotReady control-plane 2m v1.35.5k get nodes が kubectl get nodes と同じ結果を返せば成功です。以降、本記事のコマンド例は k の短縮形を使います。
kubectl の補完設定
あわせて kubectl の Tab 補完を設定します。これも任意ですが、設定しておくとリソース名やサブコマンドを Tab キーで補完でき、入力が速くなります。
実行コマンド(k8s-ops で developer 作業):
$ kubectl completion bash >> ~/.bashrc
$ echo 'complete -o default -F __start_kubectl k' >> ~/.bashrc
$ source ~/.bashrc1 行目で kubectl の補完スクリプトを ~/.bashrc に追加し、2 行目でその補完をエイリアス k にも適用しています。これで k get no と打って Tab キーを押すと k get nodes に補完されます。CKA 試験環境でも補完は有効なので、普段から使って慣れておくとよいでしょう。
Calico CNI インストールとノード Ready 確認
最後のセクションです。CNI をインストールして、ノードを Ready にします。CNI(Container Network Interface)は Pod 間のネットワークを提供するコンポーネントです。kubeadm は CNI を含まないため、運用者が選んで導入します。本シリーズでは Calico を使います。作業場所は k8s-ops です。
Calico マニフェストのダウンロード
Calico は manifest 方式(calico.yaml を kubectl apply する方式)でインストールします。50 ノード以下の kubeadm 環境ではこの方式が推奨されます。ここで重要なのが「URL から直接 apply せず、いったんダウンロードしてから apply する」という点です。
その理由は Pod CIDR の整合です。calico.yaml には CALICO_IPV4POOL_CIDR という環境変数があり、デフォルト値は 192.168.0.0/16 です。一方、本シリーズの kubeadm の podSubnet は 10.244.0.0/16 です。両者が食い違うと Pod ネットワークの割り当てが意図どおりにならない可能性があります。ダウンロードして設定を確認・必要なら修正してから apply するのが安全です。
実行コマンド(k8s-ops で developer 作業):
$ curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.32.0/manifests/calico.yamlCalico v3.32.0 は 2026-05-19 時点の最新安定版です。raw.githubusercontent.com は whitelist 登録済みのためプロキシ経由で取得できます。
CALICO_IPV4POOL_CIDR の確認
ダウンロードした calico.yaml の中で CALICO_IPV4POOL_CIDR がどう設定されているかを確認します。
実行コマンド:
$ grep -n 'CALICO_IPV4POOL_CIDR' calico.yaml実行結果(多くの場合コメントアウトされている):
# - name: CALICO_IPV4POOL_CIDR
# value: "192.168.0.0/16"多くのバージョンの calico.yaml では CALICO_IPV4POOL_CIDR がコメントアウトされています。コメントアウトされている場合、Calico は kubeadm が設定した Pod CIDR(10.244.0.0/16)を自動検出します。この場合はコメントアウトのまま apply して問題ありません。
もしコメントが外れていて value: "192.168.0.0/16" が有効になっている場合は、kubeadm の podSubnet に合わせて 10.244.0.0/16 に変更します。
実行コマンド(CALICO_IPV4POOL_CIDR が有効かつ値が異なる場合のみ):
$ sed -i 's#192.168.0.0/16#10.244.0.0/16#' calico.yamlIP_AUTODETECTION_METHOD を eth0 に固定する(二枚 NIC 環境の必須設定)
本シリーズの検証 VM は eth0(External Switch・192.168.1.0/24)と eth1(Internal Switch・10.0.10.0/24)の二枚 NIC 構成です。Kubernetes ノードの InternalIP は eth0 側(192.168.1.x)に固定しているため、Calico の IPIP トンネル端点も eth0 側で揃える必要があります。Calico はデフォルトで first-found アルゴリズムによって NIC を自動検出しますが、二枚 NIC では eth1(10.0.10.x)を誤検出することがあります。誤検出すると BGP ピアが他ノードに到達できず Calico-node が 0/1 Ready のまま停滞します。これを防ぐため、Calico の DaemonSet に環境変数 IP_AUTODETECTION_METHOD=interface=eth0 を明示します。
calico.yaml の calico-node DaemonSet の env セクションに以下を追加します。CLUSTER_TYPE の直上に挿入するパターンが kubeadm 環境では一般的です。
実行コマンド:
$ sed -i '/name: CLUSTER_TYPE/i\ - name: IP_AUTODETECTION_METHOD\n value: "interface=eth0"\n - name: IP6_AUTODETECTION_METHOD\n value: "none"' calico.yaml計画的に DaemonSet を直接 apply 後に編集する場合は kubectl set env daemonset/calico-node -n kube-system IP_AUTODETECTION_METHOD=interface=eth0 IP6_AUTODETECTION_METHOD=none でも同等の効果が得られます。本シリーズの第4回以降で追加する Workload Node も同じ NIC 構成のため、この設定 1 回で全ノードに適用されます。
firewalld の BGP / IPIP / Pod CIDR 開放
本シリーズは firewalld を有効のまま運用するため、Calico の BGP(179/tcp)と IPIP トンネル(IP プロトコル番号 4)、それと Pod CIDR 10.244.0.0/16 およびノード間ネットワーク 192.168.1.0/24 をノード間で疎通可能にする必要があります。これらの開放が抜けると BGP ピアが Socket: No route to host で確立できず、calico-node が 0/1 Ready のまま停滞します。第2回時点ではノードは k8s-cp-01 1 台ですが、第4回以降の HA クラスタ化で複数ノードに広がる前提で、ここで設定しておきます。
実行コマンド(k8s-cp-01 上で root):
# firewall-cmd --permanent --add-port=179/tcp
# firewall-cmd --permanent --add-protocol=ipip
# firewall-cmd --permanent --zone=trusted --add-source=10.244.0.0/16
# firewall-cmd --permanent --zone=trusted --add-source=192.168.1.0/24
# firewall-cmd --reloadCalico の経路問題は第2巻全体の前提条件であり、ここで根治しておけば第4回以降の Workload Node 追加でも同じ設定をコピーすれば BGP メッシュが確立します。逆にこの設定が抜けると、第9回以降の MetalLB や cert-manager の admission webhook が「API server から Pod CIDR への到達不能」で context deadline exceeded を出す原因になります。
Calico の apply
calico.yaml をクラスタに適用します。
実行コマンド:
$ k apply -f calico.yaml実行結果(抜粋):
configmap/calico-config created
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org created
daemonset.apps/calico-node created
serviceaccount/calico-node created
deployment.apps/calico-kube-controllers created
serviceaccount/calico-kube-controllers created多数のリソースが created と表示されます。Calico は DaemonSet(calico-node・全ノードで稼働)と Deployment(calico-kube-controllers)として展開されます。
calico-node Pod の起動確認
Calico の中心コンポーネントである calico-node Pod が起動するまで待ちます。イメージの pull を含めて 1〜3 分かかる場合があります。
実行コマンド:
$ k get pods -n kube-system -l k8s-app=calico-node実行結果(Running になることを確認):
NAME READY STATUS RESTARTS AGE
calico-node-xxxxx 1/1 Running 0 XmSTATUS が Running、READY が 1/1 になれば Calico が稼働しています。STATUS が ContainerCreating や Init の間は、イメージ pull か初期化が進行中です。少し待ってから再度確認してください。
ノード Ready 確認 — 第2回のゴール
Calico が稼働すると、Pod ネットワークが確立し、ノードが Ready になります。確認します。
実行コマンド:
$ k get nodes実行結果(Ready になることを確認):
NAME STATUS ROLES AGE VERSION
k8s-cp-01 Ready control-plane 3m v1.35.5STATUS が Ready に変わりました。これが第2回のゴールです。kubeadm によるシングルノードクラスタの起動が完了し、k8s-ops から kubeadm クラスタを操作できる状態になりました。素の VM から始めて、OS 設定・containerd・kubeadm・CNI までを積み上げ、ここまで到達しました。
kube-system の全 Pod 確認
クラスタの基盤コンポーネントがすべて正常に動いているか、kube-system 名前空間の Pod を一覧で確認します。
実行コマンド:
$ k get pods -n kube-system実行結果(全 Pod が Running であることを確認):
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-xxxxxxxxxx-xxxxx 1/1 Running 0 Xm
calico-node-xxxxx 1/1 Running 0 Xm
coredns-xxxxxxxxxx-xxxxx 1/1 Running 0 Xm
coredns-xxxxxxxxxx-xxxxx 1/1 Running 0 Xm
etcd-k8s-cp-01 1/1 Running 0 Xm
kube-apiserver-k8s-cp-01 1/1 Running 0 Xm
kube-controller-manager-k8s-cp-01 1/1 Running 0 Xm
kube-proxy-xxxxx 1/1 Running 0 Xm
kube-scheduler-k8s-cp-01 1/1 Running 0 Xmすべての Pod が Running であれば、クラスタは健全な状態です。ここで etcd-k8s-cp-01・kube-apiserver-k8s-cp-01・kube-controller-manager-k8s-cp-01・kube-scheduler-k8s-cp-01 という 4 つの Pod 名に注目してください。末尾に -k8s-cp-01 というサフィックスが付いています。これは Static Pod の特徴です。Static Pod の Pod 名はノード名から自動付与されます。kubeadm init で /etc/kubernetes/manifests/ に配置された 4 つの YAML が、この 4 つの Pod として動いているわけです。
一方、coredns-...・kube-proxy-...・calico-... はランダムなサフィックスです。これらは通常の Pod(Deployment や DaemonSet で管理される Pod)であり、API Server を介して管理されます。「サフィックスがノード名 = Static Pod」「サフィックスがランダム = 通常の Pod」という見分け方を覚えておくと、第15回のトラブルシュート演習で役立ちます。Static Pod の設定変更は /etc/kubernetes/manifests/ のファイルを直接編集して行います。
まとめ・現場ヒヤリハット・理解度チェック
まとめと次回予告
第2回で学んだことをまとめます。
- alma-proxy の whitelist に
pkgs.k8s.ioとprojectcalico.docs.tigera.ioを追加し、プロキシ環境下での Kubernetes パッケージ取得を可能にした - k8s-cp-01 の swap 無効化・カーネルモジュール(overlay / br_netfilter)・sysctl・containerd(SystemdCgroup=true)の設定が、kubeadm init の前提条件である
- swap は
swapoff -aと/etc/fstabのコメントアウトをセットで実施しないと、再起動後に復活して kubelet が起動しなくなる - containerd の
SystemdCgroupは cgroup v2 環境(AlmaLinux 10)では必ずtrueにする。falseのままだと kubelet と cgroup ドライバが食い違いクラスタが不安定になる pkgs.k8s.ioは 2024年3月に旧 Google ホストリポジトリが廃止された後の唯一の公式 RPM リポジトリ。v1.35 専用リポジトリを設定し、dnf versionlock でバージョンをピン留めする- k8s-lb に最小 HAProxy パススルー設定(6443 → k8s-cp-01:6443)を入れ、
controlPlaneEndpoint: k8s-lb:6443を最初から設定しておくことが HA 構成への必須前提 kubeadm init --config kubeadm-config.yaml --upload-certsで Control Plane が起動し、Static Pod(kube-apiserver / etcd 等)が/etc/kubernetes/manifests/に配置される- Calico CNI インストール後に
kubectl get nodesで Ready 表示が確認でき、k8s-ops から kubeadm クラスタを操作できるようになった。alias k=kubectlを導入し CKA 試験環境と同じ短縮コマンドを使える
第2回で押さえた本番ガードレールを 5 つの観点で振り返ります。これらは「なぜ必要か」まで説明できることが重要です。
| ガードレール | なぜ必要か |
|---|---|
| swap 無効化(fstab 含む) | kubelet はメモリ管理の前提として swap 無効を要求。fstab を直さないと再起動で復活し kubelet が起動不能になる |
| SystemdCgroup = true | cgroup v2 環境では kubelet と containerd の cgroup ドライバを揃える必要がある。食い違うと Control Plane Pod が不安定になる |
| バージョンピン留め | dnf upgrade で kubelet が勝手に上がるとバージョンスキュー違反になる。第6回の計画的アップグレード演習も破綻する |
| controlPlaneEndpoint | init 後に変更すると証明書 SAN の再生成が必要。HA 化(第4回)を見据え最初から LB を指す |
| カーネルモジュール | overlay は containerd、br_netfilter は Pod ネットワークの iptables 連携に必須。未ロードだとネットワークが不安定になる |
次回(第3回)では、k8s-lb の HAProxy 設計を HA 本格仕様に作り込みます。第2回で入れた最小パススルー設定を土台に、Control Plane×3 を backend に登録した負荷分散・ヘルスチェック・stats ページの設定を行います。あわせて第4回の HA クラスタ構築(k8s-cp-02/03 の join、k8s-wl-01/02 の join)に向けて、kubeadm-config.yaml の HA 設計を整えます。第3回を終えると、5 ノード HA クラスタを構築する準備が完了します。
現場ヒヤリハット — swap を無効化しても再起動後に kubelet が起動しないパターン
第2回のヒヤリハットは swap の無効化に関するものです。これは kubeadm クラスタ構築で最も多いつまずきの一つです。
状況を再現します。クラスタ構築時に swapoff -a を実行し、swap を無効化したつもりで kubeadm init を完了させました。クラスタは正常に起動し、kubectl get nodes で Ready も確認できました。ここまでは問題ありません。しかし /etc/fstab の swap 行をコメントアウトしていませんでした。
後日、設定変更の確認や OS メンテナンスのために VM を再起動します。すると、再起動時に /etc/fstab の設定に従って swap が復活します。swap が有効な状態では kubelet が起動できないため、ノードが NotReady になるか、そもそも API Server が応答しなくなります。
このとき systemctl status kubelet や journalctl -u kubelet を見ると、kubelet が activating (auto-restart) の状態で起動と失敗を繰り返しているのが分かります。kubelet はデフォルトで swap が有効なノードでの起動を拒否する設定(failSwapOn)になっているためです。ログには swap が有効である旨のエラーが記録されます。
原因は再起動で復活した swap です。free -h で Swap 行の total が 0B でなくなっていれば、これが原因と確定できます。対処は次のとおりです。
# swapoff -a
# sed -i.bak '/swap/s/^/#/' /etc/fstab
# systemctl restart kubeletswapoff -a で swap を無効化し、/etc/fstab をコメントアウトして再発を防ぎ、systemctl restart kubelet で kubelet を再起動します。これでノードは復旧します。教訓は明快です。swap 無効化は「swapoff -a」と「/etc/fstab のコメントアウト」をセットで実施する、これを鉄則として覚えてください。本記事の H2-4 ではこの 2 手順を必ずセットで実施するよう構成しています。
もう一つ、関連する落とし穴を挙げます。SystemdCgroup = false のまま containerd を起動した状態で kubeadm init を実行すると、Pod の cgroup 操作でエラーが発生し、kube-apiserver や etcd の Static Pod が起動しません。kubeadm init が [kubelet-check] あたりで止まり、タイムアウトに至ります。原因の特定に時間がかかる厄介な症状です。
このパターンの予防策は、containerd の設定変更後に必ず grep SystemdCgroup /etc/containerd/config.toml で true を確認し、systemctl restart containerd で再起動することです。設定ファイルを書き換えただけでは反映されません。再起動を忘れると、ファイル上は true、稼働中の containerd は false という食い違いが起き、kubeadm init で詰まります。「設定変更したら再起動して確認」を習慣にしてください。
理解度チェック(○×形式・7問)
以下の 7 問に○か×で答えてください。答えと解説は下に記載しています。
問1:swapoff -a を実行するだけで、再起動後も swap が無効のままになる
問2:AlmaLinux 10 は cgroup v2 がデフォルトであるため、containerd の SystemdCgroup = true 設定が必須である
問3:pkgs.k8s.io の v1.35 リポジトリの baseurl は https://pkgs.k8s.io/core:/stable:/v1.35/rpm/ である
問4:kubeadm init --upload-certs の --upload-certs は etcd のバックアップを自動取得するオプションである
問5:kubectl get nodes で STATUS が NotReady の場合、常にクラスタに問題がある
問6:/etc/kubernetes/manifests/ に配置された YAML ファイルは、kubelet が自動で Pod として起動・管理する
問7:controlPlaneEndpoint を kubeadm init 後に変更するのは、証明書の SAN を作り直す必要があるため容易ではない
— 答えと解説 —
問1:× — swapoff -a は今この瞬間の swap を無効化するだけで、再起動すると /etc/fstab の設定に従い swap が復活します。再起動後も無効を維持するには /etc/fstab の swap 行をコメントアウトする必要があります。この 2 手順はセットです。
問2:○ — AlmaLinux 10 は cgroup v2 がデフォルトです。cgroup v2 環境では kubelet(systemd cgroup ドライバを期待)と containerd の cgroup ドライバを揃える必要があり、containerd 側は SystemdCgroup = true に設定します。false のままだと Control Plane Pod が不安定になります。
問3:○ — v1.35 用リポジトリの baseurl は https://pkgs.k8s.io/core:/stable:/v1.35/rpm/ です。pkgs.k8s.io はマイナーバージョンごとに専用 URL があり、第2巻は v1.35 専用リポジトリを設定します。
問4:× — --upload-certs は Control Plane の証明書をクラスタ内の Secret に暗号化保存し、追加 Control Plane Node が証明書を自動取得できるようにするオプションです。etcd のバックアップとは関係ありません。etcd のバックアップは第5回で etcdctl を使って扱います。
問5:× — Calico CNI をインストールする前は、Pod ネットワークが未確立のためノードは NotReady になります。これは正常な状態です。CNI を適用すると Ready に変わります。NotReady が常に異常を意味するわけではありません。
問6:○ — /etc/kubernetes/manifests/ は Static Pod のディレクトリです。kubelet がこのディレクトリを常時監視し、YAML ファイルが存在する限り対応する Pod を自動で起動・再起動します。kubeadm init は etcd・kube-apiserver・kube-controller-manager・kube-scheduler の 4 つをここに配置します。
問7:○ — controlPlaneEndpoint を init 後に変更するには、API Server の TLS 証明書に含まれる SAN を作り直す必要があります。本番稼働中のクラスタでは大掛かりな作業になるため、HA 化を見据えて init 時に最初から LB のエンドポイントを指定しておくのが定石です。
シリーズ一覧
第1部:クラスタ構築
- 第1回 第2巻スコープ + CKA 試験形式紹介 + kubeadm 概要 + kubeadm vs RKE2/k0s/OKD 概観
- 第2回 kubeadm シングルノード起動(pkgs.k8s.io + kubeadm init + Calico CNI)+ alma-proxy whitelist 構築 ← 今ここ
- 第3回 kubeadm HA 設計 + HAProxy LB(API Server LB 構成)
- 第4回 kubeadm HA クラスタ構築(CP×3 + WL×2)+ fanclub-api HA 移行
- 第5回 etcd backup/restore(etcdutl)+ ノード drain/uncordon
第2部:ワークロード管理
- 第6回 kubeadm upgrade + ノード drain/cordon + ミニトラブルシュート演習
- 第7回 Pod スケジューリング(taint/toleration/affinity/anti-affinity/PriorityClass)
- 第8回 HPA + ResourceQuota + LimitRange
第3部:ネットワーク
- 第9回 Service 詳細 + MetalLB(LoadBalancer 動作確認)
- 第10回 NetworkPolicy 詳細 + Calico/Cilium 比較 + ミニトラブルシュート演習
- 第11回 Gateway API + Traefik + cert-manager + CoreDNS(HTTPS 公開完成)
第4部:ストレージ
第5部:監視・運用
- 第13回 Prometheus + Grafana + Loki + Fluent Bit + fanclub-api 監視ダッシュボード
- 第14回 Helm + Kustomize でクラスタコンポーネント install + ArgoCD GitOps + Velero backup
