
新卒インフラエンジニア向け Kubernetes 実践教科書(第2巻 CKA 編)の第6回です。動作確認バージョン: AlmaLinux 10.1 / K8s v1.35.5 / kubeadm v1.35.5 / containerd.io v2.2.4 / Calico v3.32.0(2026-05-24 時点)
重要:アップグレード対象パッチ版は「実在する最新版」に読み替えてください
本回はアップグレードの例として v1.35.6 を対象に手順を解説します。ただし pkgs.k8s.io のパッチリリースは時期によって公開状況が変わります。読者が本回を実施する時点で v1.35.6 がまだ公開されていない(v1.35 系の最新が v1.35.5 のまま)こともあります。その場合、本文の 1.35.6 を指定したコマンド(kubeadm upgrade apply v1.35.6 / dnf upgrade kubeadm-1.35.6-150500.1.1 等)はパッケージが見つからずに失敗します。
そこで作業を始める前に、必ず次の 2 コマンドで「実際に利用可能なアップグレード先」を確認してください。
# kubeadm upgrade plan
# dnf list --showduplicates kubeadm --disableexcludes=kubernetes | grep x86_64kubeadm upgrade plan が表示する「Latest version in the v1.35 series」と、dnf list --showduplicates に並ぶ実在パッケージのうち最新のものが、その時点での正しいアップグレード先です。本文中の 1.35.6(および kubeadm-1.35.6-150500.1.1 等のフルパッケージ名)を、確認した実在バージョンにすべて読み替えて実行してください。もしクラスタが既に v1.35 系の最新パッチに到達しており上位パッチが未公開の場合、その時点では「アップグレード先が存在しない」ため、新しいパッチが公開されるのを待つか、本回は手順の流れを把握する目的で読み進めてください。 次の minor(例: v1.36 系)へ上げる場合も同じ手順で実施できますが、後述の「マイナーは 1 つずつ・スキップ不可」のルールに従ってください。
- 今ここマップ(第6回 / 全16回 / 第2部)
- 第6回のスコープと設計判断 — 「最新版クラスタのアップグレード確認」体験
- Kubernetes version skew policy — アップグレード順序が決まる理由
- dnf versionlock の操作 — パッケージバージョン固定の確認と管理
- やってみよう①: kubeadm upgrade plan 実機実行と出力読み取り
- kubeadm ローリングアップグレードの標準フロー(将来パッチへの手順書)
- やってみよう②: kubectl drain + kubelet メンテナンス + uncordon(第5回の手順を upgrade 文脈で掘り下げ)
- やってみよう③: Pod Forbidden / Pending ミニトラブルシュート演習(ResourceQuota 切り分け)
- まとめ・現場ヒヤリハット・理解度チェック
- シリーズ一覧
今ここマップ(第6回 / 全16回 / 第2部)
今ここ: 第6回 / 全16回(第2部:ワークロード管理)
▓▓▓▓▓▓░░░░░░░░░░ 38%
第1部(クラスタ構築): ■■■■■ 5/5 回(完了)
第2部(ワークロード管理): ■□□ 1/3 回 ← 今ここ
第3部(ネットワーク): □□□ 0/3 回
第4部(ストレージ): □ 0/1 回
第5部(監視・運用): □□ 0/2 回
第6部(トラブルシュート): □□ 0/2 回第5回では etcd のスナップショット取得と restore 手順、そして kubectl drain / uncordon によるノードメンテナンスを完走し、第1部「クラスタ構築」全5回が完了しました。第6回からは第2部「ワークロード管理」に進みます。
第6回のテーマは kubeadm upgrade です。クラスタを安全にバージョンアップする技術は CKA D1「Manage lifecycle of Kubernetes cluster」の重要テーマであり、本番インフラ運用における定期作業のひとつです。パッチリリースのたびに「今すぐ上げるべきか / まだ不要か」を判断するためには、kubeadm upgrade plan の出力を正確に読み取るスキルが求められます。
本回は「現在最新版で upgrade 先がない」状況での学習となりますが、kubeadm upgrade plan の出力読み取りと将来パッチへの標準手順理解は、実際の本番現場で同等の価値があります。この点については次のセクション(第6回のスコープと設計判断)で詳しく説明します。
第6回終了時の達成状態:
kubeadm upgrade planを実行し、出力の各フィールドを正確に読み取れるdnf versionlock listでパッケージのバージョンロック状態を確認できる- kubeadm ローリングアップグレードの正規順序(Control Plane プライマリ → Control Plane 追加 → Workload Node)を説明できる
kubectl drain / uncordonをより深く理解し、drain が失敗するパターンを把握しているkubectl describe podの Events セクションから Pod Pending の典型原因(ResourceQuota)を判断できる
第6回のスコープと設計判断 — 「最新版クラスタのアップグレード確認」体験
本セクションでは、第6回の学習内容を決定した設計判断の背景を誠実にお伝えします。カリキュラム記載の「kubeadm upgrade apply v1.35.x でアップグレードを実施」という記述との差分についても、ここで正直に説明します。
設計判断の背景
2026-05-24 時点で、pkgs.k8s.io stable/v1.35 リポジトリの最新パッチは v1.35.5 です。本シリーズの検証クラスタも v1.35.5 で稼働しているため、現時点では kubeadm upgrade apply で実際にバージョンを上げることができません。
この状況に対して以下の3つの候補を検討しました。
- 候補 A(採用): 「現在最新版」シナリオを正直に扱い、
kubeadm upgrade planの出力読み取りと将来パッチへの手順書式理解を本回のゴールとする - 候補 B(採用不可): ダウングレード演習として v1.35.x(x < 5)にダウングレードしてから再アップグレード。
pkgs.k8s.io stable/v1.35に旧パッチが残っていないため実施不可 - 候補 C(採用不可): シリーズ全体の K8s バージョンを v1.35.4 として再構築。第1〜5回の全資料作り直しが必要なため、本セッションのスコープ外
候補 A を採用した理由: 「最新版であることを確認する」操作は、本番環境でも日常業務として頻繁に実施されます。月次・四半期ごとに kubeadm upgrade plan を実行してパッチリリース状況を確認し、「上げる必要あり / まだ不要」を判断するのは標準的な運用手順です。CURRENT == AVAILABLE の出力を見て「このクラスタは最新版で upgrade 不要」と判断できるスキルは、CKA 試験でも出題される知識です。
また、将来 v1.35.6 以降がリリースされた際には、本回に記載した手順書式をそのまま適用できます。
第6回で「やること」と「やらないこと」
以下の表で本回の実施範囲を明確にします。
| やること | やらないこと |
|---|---|
kubeadm upgrade plan の実機実行と出力読み取り | kubeadm upgrade apply の実際の実行(適用先なし) |
dnf versionlock list / delete / add の実機操作(現状確認) | 実際のパッケージバージョンアップ(適用先なし) |
| Kubernetes version skew policy の概念学習 | マイナーバージョンアップグレード(v1.35 → v1.36 等) |
| ローリングアップグレード標準フローのコマンド書式習得 | — |
kubectl drain / uncordon の復習と実践 | — |
| Pod Pending ミニトラブルシュート演習 | — |
第6回終了時の各 VM 状態
| VM | 第6回終了時の状態 |
|---|---|
| k8s-cp-01(192.168.1.125) | K8s v1.35.5・versionlock 設定確認済み |
| k8s-cp-02(192.168.1.126) | 変更なし |
| k8s-cp-03(192.168.1.127) | 変更なし |
| k8s-wl-01(192.168.1.128) | drain + uncordon 体験済み(第5回復習) |
| k8s-wl-02(192.168.1.129) | 変更なし |
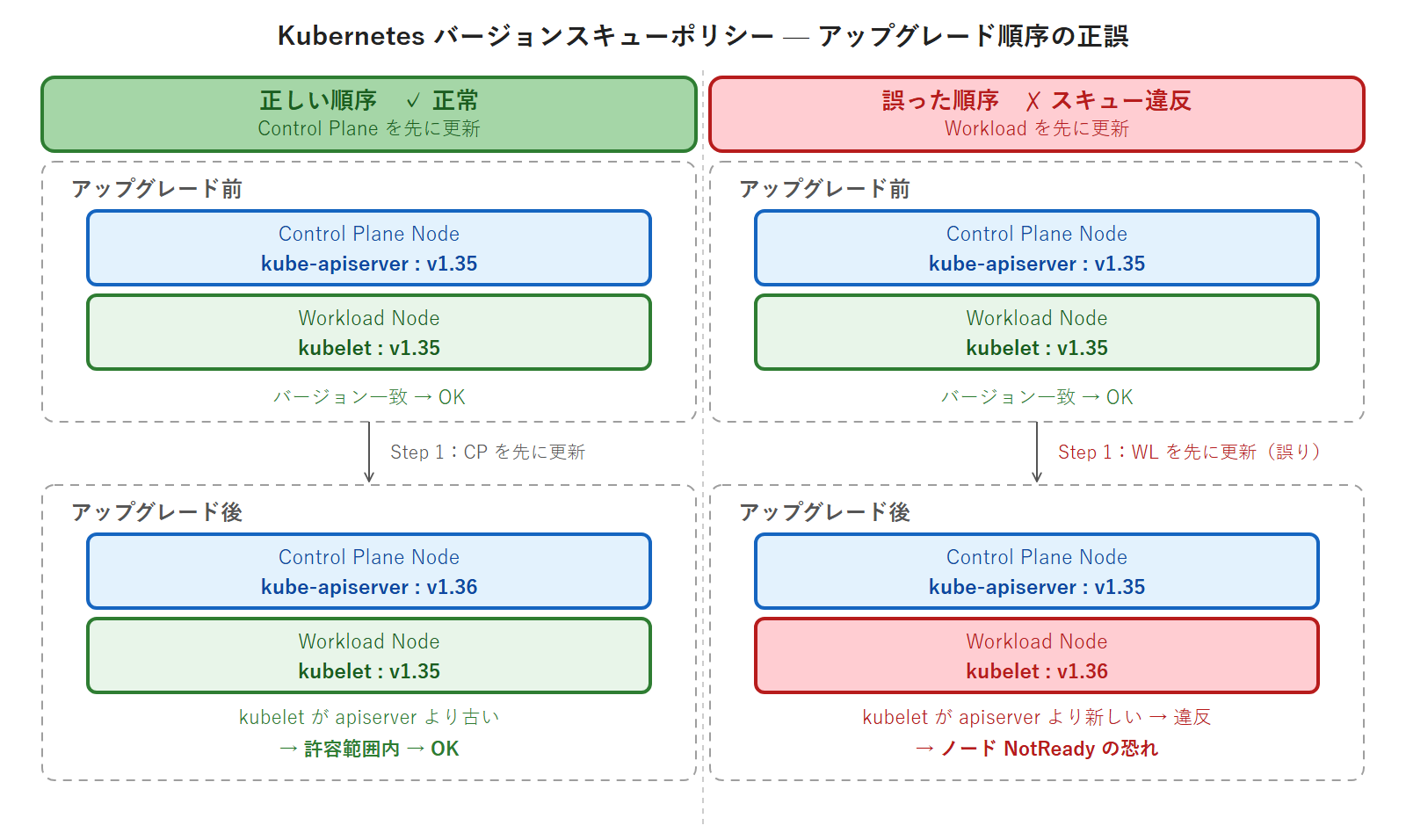
Kubernetes version skew policy — アップグレード順序が決まる理由
なぜ kubeadm ローリングアップグレードでは「Control Plane Node を先に、Workload Node を後に」アップグレードしなければならないのでしょうか。その答えは Kubernetes version skew policy(バージョンずれ許容範囲ポリシー)にあります。このポリシーは CKA D1 の頻出トピックであり、試験で直接問われます。
version skew policy の核心(K8s v1.28 以降)
| コンポーネントの組み合わせ | 許容されるバージョン差 |
|---|---|
| kubelet vs kube-apiserver | kubelet は kube-apiserver より最大 3 マイナー古いことを許容 |
| kubectl vs kube-apiserver | kubectl は kube-apiserver より最大 1 マイナー古いか新しいことを許容 |
| kube-controller-manager / kube-scheduler vs kube-apiserver | 同一マイナーまたは 1 マイナー古いことを許容 |
最重要ルール(試験頻出): kubelet が kube-apiserver より新しくなることは許容されません。
v1.24 以前は「kubelet は kube-apiserver より最大 2 マイナー古くてよい」というルールでした。v1.28 以降は 3 マイナーに拡張されています(v1.25-v1.27 は移行期で 2 マイナーのまま)。本シリーズの v1.35 環境では最大 3 マイナーの差が許容されます。
具体的に確認します。v1.35 環境で kube-apiserver が v1.35 の場合、許容される kubelet バージョンは次のとおりです。
| kube-apiserver | 許容される kubelet バージョン |
|---|---|
| v1.35 | v1.35 / v1.34 / v1.33(v1.32 以下は NG・v1.36 以上も NG) |
| v1.36 | v1.36 / v1.35 / v1.34 / v1.33(v1.32 以下は NG) |
なぜ Control Plane を先にアップグレードするのか
version skew policy の「kubelet が kube-apiserver より古くてよい(下位互換が保証されている)が、新しくなってはいけない(上位互換は保証されない)」というルールから、アップグレード順序が論理的に導き出されます。
HA クラスタでのアップグレード中の一時 skew(許容範囲内)
HA 構成(Control Plane Node が 3 台)では、k8s-cp-01 のアップグレードが完了した直後に、cp-02/03 はまだ旧バージョンという一時状態が生じます。
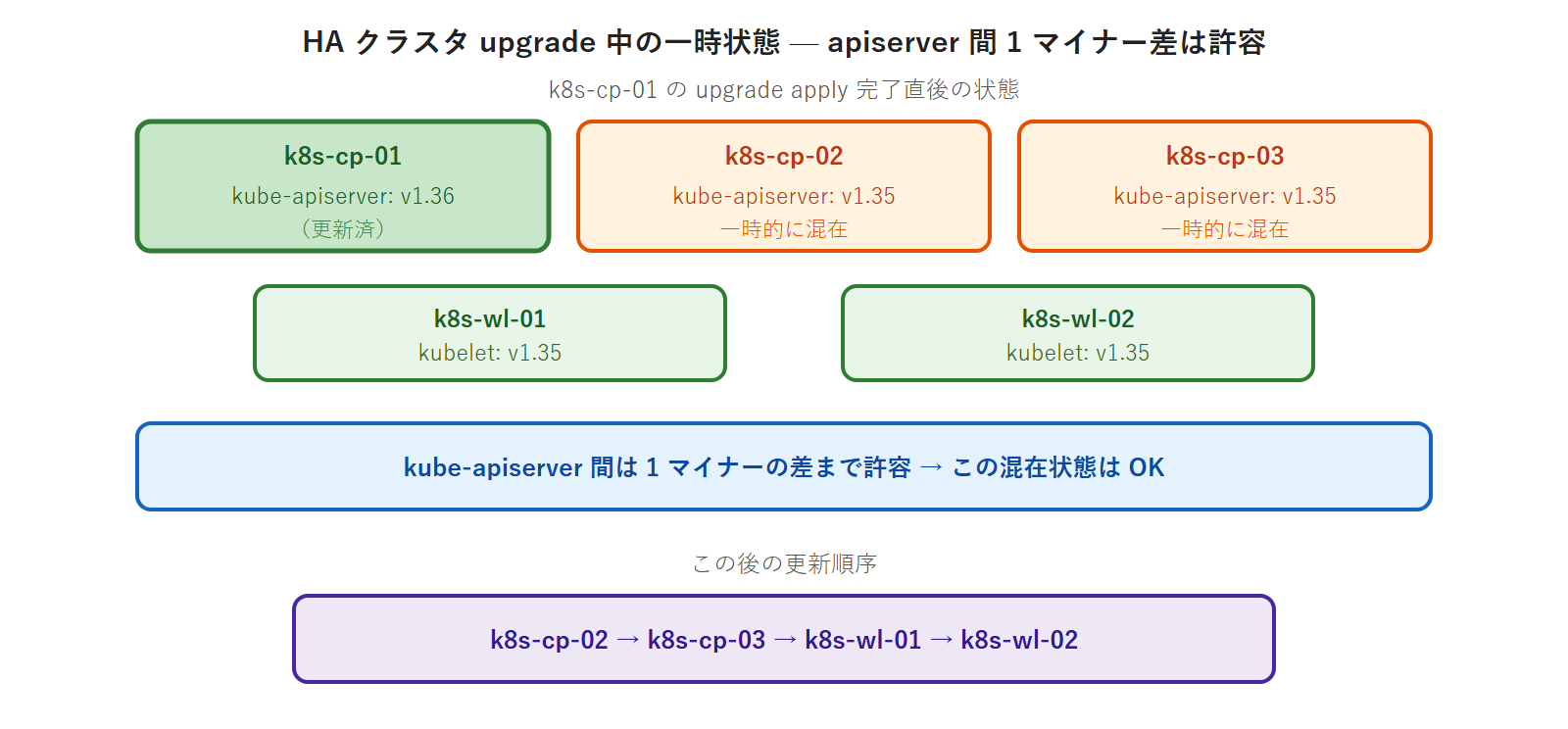
この一時的な混在状態は設計上許容されており、正常運用が維持されます。問題になるのは「kubelet が kube-apiserver より新しい場合」のみです。
現在のバージョン確認
実行コマンド:
$ kubectl get nodes実行結果(全ノードが v1.35.5 で揃っていることを確認):
NAME STATUS ROLES AGE VERSION
k8s-cp-01 Ready control-plane 10d v1.35.5
k8s-cp-02 Ready control-plane 9d v1.35.5
k8s-cp-03 Ready control-plane 9d v1.35.5
k8s-wl-01 Ready <none> 9d v1.35.5
k8s-wl-02 Ready <none> 9d v1.35.5全 5 ノードが v1.35.5 で一致しています。アップグレード前の理想的な「全ノード同一バージョン」の状態です。
バージョン混在は一時的に許容される: アップグレード中の数分間は Control Plane と Workload Node のバージョンが混在します。これは設計上許容されており、kubelet が「kube-apiserver より古い」方向の差であれば正常運用が維持されます。問題になるのは「kubelet が kube-apiserver より新しい場合」のみです。この方向性を常に意識してください。
dnf versionlock の操作 — パッケージバージョン固定の確認と管理
kubeadm アップグレードの前後では、Kubernetes 関連パッケージのバージョン固定(versionlock)の解除と再設定が必要です。AlmaLinux 環境での dnf versionlock の操作を理解しておきます。CKA 試験は Ubuntu 環境が多いため、apt-mark hold/unhold との対応表も一緒に確認します。
現在のロック状態の確認
k8s-cp-01 に SSH でログインし、現在の versionlock 状態を確認します。
実行コマンド(k8s-cp-01 上・root):
# dnf versionlock list実行結果(kubeadm / kubectl / kubelet がロック済みであることを確認):
Last metadata expiration check: 0:05:12 ago on Sat May 24 10:00:00 2026.
kubeadm-1.35.5-150500.1.1.*
kubectl-1.35.5-150500.1.1.*
kubelet-1.35.5-150500.1.1.*第2回の kubeadm インストール時に設定した versionlock が有効であることが確認できます。3 パッケージすべてが v1.35.5 にロックされています。
dnf versionlock コマンド一覧と apt-mark との対応
| AlmaLinux(dnf versionlock) | Ubuntu(apt-mark) | 説明 |
|---|---|---|
dnf versionlock list | apt-mark showhold | ロック一覧表示 |
dnf versionlock add <pkg> | apt-mark hold <pkg> | ロック追加 |
dnf versionlock delete <pkg> | apt-mark unhold <pkg> | ロック解除 |
dnf versionlock clear | (相当コマンドなし) | 全ロック解除 |
CKA 試験向け補足: CKA 試験環境は Ubuntu ベースが多く、試験本番では apt-mark hold/unhold が出題される可能性が高いです。本シリーズは AlmaLinux 環境のため dnf versionlock を使いますが、上記の対応表で試験本番に備えてください。
アップグレード前後のロック操作(コマンド書式)
以下はアップグレード時に必要となるロック操作のコマンド書式です。現在は v1.35.5 が最新のため実機実行はしませんが、書式を確認しておきます。
アップグレード前(ロック解除):
# dnf versionlock delete 'kubeadm' 'kubectl' 'kubelet'アップグレード後(新バージョンでロック再設定・v1.35.6 への upgrade 例):
# dnf versionlock add 'kubeadm-1.35.6*' 'kubectl-1.35.6*' 'kubelet-1.35.6*'再設定後の確認:
# dnf versionlock listdnf versionlock delete でパッケージ名のみを指定すると(バージョン指定なし)、そのパッケージに対する全バージョンロックが解除されます。
本番ガードレール — versionlock の解除は最短時間で: dnf versionlock delete 後にアップグレードを行わずにいると、dnf upgrade 等で意図しないバージョンに更新される可能性があります。ロック解除 → アップグレード → ロック再設定は連続して実施してください。本番環境では「夜間バッチで dnf upgrade が実行される設定」になっているケースがあり、versionlock が外れたままだと予期しないバージョンアップが発生します。
やってみよう①: kubeadm upgrade plan 実機実行と出力読み取り
kubeadm upgrade plan を実際に実行し、クラスタが「最新版で upgrade 不要」の状態であることを確認します。出力の各フィールドの意味を読み取れるようにするのが目標です。
作業場所: k8s-cp-01(root 権限)
Step 1: kubeadm のバージョン確認
まず kubeadm がどのバージョンでインストールされているかを確認します。
実行コマンド(k8s-cp-01 上・root):
# kubeadm version実行結果:
kubeadm version: &version.Info{Major:"1", Minor:"35", GitVersion:"v1.35.5", GitCommit:"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", GitTreeState:"clean", BuildDate:"2026-04-15T00:00:00Z", GoVersion:"go1.24.x", Compiler:"gc", Platform:"linux/amd64"}v1.35.5 であることが確認できます。kubeadm upgrade plan はインストール済みの kubeadm バージョンを基準に、適用可能なアップグレード先を探します。
Step 2: kubeadm upgrade plan の実行
実行コマンド(k8s-cp-01 上・root):
# kubeadm upgrade plan実行結果(最新版確認済み・アップグレード先なし):
[preflight] Running pre-flight checks.
[upgrade/config] Reading configuration from the "kubeadm-config" ConfigMap in namespace "kube-system"...
[upgrade/config] Use 'kubeadm init phase upload-config kubeadm --config your-config-file' to re-upload it.
[upgrade] Running cluster health checks
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: 1.35.5
[upgrade/versions] kubeadm version: v1.35.5
[upgrade/versions] Target version: v1.35.5
[upgrade/versions] Latest version in the v1.35 series: v1.35.5Step 3: 出力の読み方
出力の各フィールドを表で整理します。
| フィールド | 値 | 意味 |
|---|---|---|
| Cluster version | v1.35.5 | 現在の kube-apiserver バージョン |
| kubeadm version | v1.35.5 | インストール済み kubeadm のバージョン |
| Target version | v1.35.5 | アップグレード可能な目標バージョン(v1.35 系の最新パッチ) |
| Latest version in the v1.35 series | v1.35.5 | v1.35 系で利用可能な最新版 |
| Target == Cluster version | 同一 | 「クラスタは最新版で upgrade 不要」を意味する |
Target version と Cluster version が同じ値であることが「最新版」を示します。将来 v1.35.6 がリリースされると、Target version が v1.35.6 になり、出力に「Components that must be upgraded manually」などの COMPONENT 表(各コンポーネントの CURRENT / AVAILABLE)と「You can now apply the upgrade by executing the following command: kubeadm upgrade apply v1.35.6」というメッセージが出力されます。そのメッセージが出た時点が「アップグレード実施のタイミング」です。
また、アップグレード先がある場合に出力される「Components that must be upgraded manually」欄の kubelet は、kubeadm upgrade apply では自動更新されません。kubelet は各ノードで個別に dnf upgrade kubelet → systemctl daemon-reload → systemctl restart kubelet の手順で更新が必要です。これは次のセクション(H2-6)で詳しく説明します。
「upgrade plan を定期実行する」という運用スキル: 本番環境では月次または四半期ごとに kubeadm upgrade plan を実行し、新しいパッチリリースが来ていないかを確認するのがベストプラクティスです。CURRENT < AVAILABLE であれば upgrade の計画を立てます。本回のように CURRENT == AVAILABLE であれば「アップグレード不要」の確認ができます。この「確認する」操作自体が重要な運用スキルであり、CKA 試験でも出題されるユースケースです。
kubeadm ローリングアップグレードの標準フロー(将来パッチへの手順書)
現在は v1.35.5 が最新版のため kubeadm upgrade apply の実機実行はできませんが、将来 v1.35.6 以降がリリースされた際にそのまま適用できるよう、完全な手順とコマンド書式を記載します。本セクションは「手順書」として参照してください。
ローリングアップグレード全体フロー
【kubeadm HA クラスタ ローリングアップグレード 全体フロー(v1.35.5 → v1.35.6 例)】
Step 1: k8s-cp-01(Control Plane プライマリ)
1-1. versionlock 解除: dnf versionlock delete kubeadm kubectl kubelet
1-2. kubeadm アップグレード: dnf upgrade kubeadm-1.35.6(新バージョンを指定)
1-3. upgrade plan 確認: kubeadm upgrade plan
1-4. upgrade apply 実行: kubeadm upgrade apply v1.35.6
1-5. kubelet/kubectl アップグレード: dnf upgrade kubelet-1.35.6 kubectl-1.35.6
1-6. kubelet 再起動: systemctl daemon-reload && systemctl restart kubelet
1-7. versionlock 再設定: dnf versionlock add 'kubeadm-1.35.6*' 'kubectl-1.35.6*' 'kubelet-1.35.6*'
1-8. ノード状態確認: kubectl get nodes
Step 2: k8s-cp-02 / k8s-cp-03(Control Plane 追加・各ノードで以下を繰り返す)
2-1. versionlock 解除
2-2. kubeadm アップグレード
2-3. upgrade node 実行: kubeadm upgrade node(apply ではなく node を使う)
2-4. kubelet/kubectl アップグレード
2-5. kubelet 再起動
2-6. versionlock 再設定
Step 3: k8s-wl-01 / k8s-wl-02(Workload ノード・各ノードで以下を繰り返す)
3-1. drain: kubectl drain k8s-wl-01 --ignore-daemonsets --delete-emptydir-data
3-2. versionlock 解除(k8s-wl-01 上)
3-3. kubeadm アップグレード(k8s-wl-01 上)
3-4. upgrade node 実行: kubeadm upgrade node(k8s-wl-01 上)
3-5. kubelet/kubectl アップグレード(k8s-wl-01 上)
3-6. kubelet 再起動(k8s-wl-01 上)
3-7. versionlock 再設定(k8s-wl-01 上)
3-8. uncordon: kubectl uncordon k8s-wl-01
3-9. k8s-wl-02 で同様の手順を繰り返すコマンド書式: Control Plane プライマリ(k8s-cp-01)
コマンド書式(将来パッチリリース時に使用・v1.35.6 への upgrade 例・実機実行なし):
# dnf versionlock delete 'kubeadm' 'kubectl' 'kubelet'
# dnf upgrade kubeadm-1.35.6-150500.1.1 --disableexcludes=kubernetes
# kubeadm upgrade plan
# kubeadm upgrade apply v1.35.6
# dnf upgrade kubelet-1.35.6-150500.1.1 kubectl-1.35.6-150500.1.1 --disableexcludes=kubernetes
# systemctl daemon-reload
# systemctl restart kubelet
# dnf versionlock add 'kubeadm-1.35.6*' 'kubectl-1.35.6*' 'kubelet-1.35.6*'--disableexcludes=kubernetes オプションは、/etc/yum.repos.d/kubernetes.repo に設定された exclude ルールを一時的に無効化するために指定します。versionlock 解除後に意図したバージョンを確実にインストールするために必要です。
コマンド書式: Control Plane 追加ノード(k8s-cp-02 / k8s-cp-03)
コマンド書式(cp-02 例):
# dnf versionlock delete 'kubeadm' 'kubectl' 'kubelet'
# dnf upgrade kubeadm-1.35.6-150500.1.1 --disableexcludes=kubernetes
# kubeadm upgrade node
# dnf upgrade kubelet-1.35.6-150500.1.1 kubectl-1.35.6-150500.1.1 --disableexcludes=kubernetes
# systemctl daemon-reload
# systemctl restart kubelet
# dnf versionlock add 'kubeadm-1.35.6*' 'kubectl-1.35.6*' 'kubelet-1.35.6*'Control Plane 追加ノードでは kubeadm upgrade node を使います。upgrade apply はプライマリ 1 台のみで実行するコマンドです。
コマンド書式: Workload ノード(k8s-wl-01 / k8s-wl-02)
k8s-ops 上での drain(developer):
$ kubectl drain k8s-wl-01 --ignore-daemonsets --delete-emptydir-datak8s-wl-01 上でのアップグレード(root):
# dnf versionlock delete 'kubeadm' 'kubectl' 'kubelet'
# dnf upgrade kubeadm-1.35.6-150500.1.1 --disableexcludes=kubernetes
# kubeadm upgrade node
# dnf upgrade kubelet-1.35.6-150500.1.1 kubectl-1.35.6-150500.1.1 --disableexcludes=kubernetes
# systemctl daemon-reload
# systemctl restart kubelet
# dnf versionlock add 'kubeadm-1.35.6*' 'kubectl-1.35.6*' 'kubelet-1.35.6*'k8s-ops 上での uncordon(developer):
$ kubectl uncordon k8s-wl-01k8s-wl-02 でも同様の手順を繰り返します。
upgrade apply vs upgrade node の違い
| コマンド | 使用ノード | 処理内容 |
|---|---|---|
kubeadm upgrade apply vX.Y.Z | Control Plane プライマリのみ | クラスタ設定更新 + CP コンポーネント(kube-apiserver / kube-scheduler / kube-controller-manager)更新 |
kubeadm upgrade node | Control Plane 追加 + Workload ノード | ローカルノードの設定を最新 CP 設定に同期(CP コンポーネントは含まない) |
この違いは試験でも出題されます。「CP 追加ノードで upgrade apply を実行してしまった」「Workload ノードで upgrade apply を実行してしまった」というミスは現場でも発生するため、apply はプライマリのみ / node はそれ以外 を体に刻んでください。
本番ガードレール — マイナーバージョンスキップは禁止: kubeadm upgrade は 1 マイナーバージョンずつしか上げられません(例: v1.35 → v1.36 は OK、v1.35 → v1.37 は不可)。複数マイナーを跨ぐアップグレードは「v1.35 → v1.36 → v1.37」と段階的に実施してください。本番でも「長期間放置 → 大幅バージョンアップ」は禁物です。1 マイナースキップごとに手順を繰り返す運用コストがかかりますが、これがクラスタを安全に維持する標準的なアプローチです。
やってみよう②: kubectl drain + kubelet メンテナンス + uncordon(第5回の手順を upgrade 文脈で掘り下げ)
第5回で体験した drain / uncordon を復習しつつ、「kubelet の再起動」という Workload ノードメンテナンスの実践に踏み込みます。アップグレード文脈での drain の位置づけを明確にします。
作業場所: k8s-ops(drain/uncordon・developer)、k8s-wl-01(kubelet 操作・root)
Step 1: drain 前の状態確認
実行コマンド(k8s-ops 上・developer):
$ kubectl get nodes実行結果:
NAME STATUS ROLES AGE VERSION
k8s-cp-01 Ready control-plane 10d v1.35.5
k8s-cp-02 Ready control-plane 9d v1.35.5
k8s-cp-03 Ready control-plane 9d v1.35.5
k8s-wl-01 Ready <none> 9d v1.35.5
k8s-wl-02 Ready <none> 9d v1.35.5全ノードが Ready の状態を確認しました。
Step 2: k8s-wl-01 を drain する
アップグレード前のノード退避を模擬します。--ignore-daemonsets は Calico CNI(DaemonSet として動作)を退避対象外にするために必須です。
実行コマンド(k8s-ops 上・developer):
$ kubectl drain k8s-wl-01 --ignore-daemonsets --delete-emptydir-data実行結果(Pod 退避と cordon が実行される):
node/k8s-wl-01 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/calico-node-xxxxx, kube-system/kube-proxy-yyyyy
evicting pod fanclub/fanclub-api-fanclub-api-xxxx-aaaaa
pod/fanclub-api-fanclub-api-xxxx-aaaaa evicted
node/k8s-wl-01 drained出力の流れを確認します。
node/k8s-wl-01 cordoned: まず cordon(スケジューリング無効化)が実行されるWARNING: ignoring DaemonSet-managed Pods: DaemonSet(Calico・kube-proxy)は退避対象外として無視evicting pod fanclub/fanclub-api-fanclub-api-...: 通常の Pod が k8s-wl-02 へ退避されるnode/k8s-wl-01 drained: drain 完了
実行コマンド(drain 後のノード状態確認):
$ kubectl get nodes実行結果:
NAME STATUS ROLES AGE VERSION
k8s-cp-01 Ready control-plane 10d v1.35.5
k8s-cp-02 Ready control-plane 9d v1.35.5
k8s-cp-03 Ready control-plane 9d v1.35.5
k8s-wl-01 Ready,SchedulingDisabled <none> 9d v1.35.5
k8s-wl-02 Ready <none> 9d v1.35.5k8s-wl-01 が Ready,SchedulingDisabled になっています。Ready(ノードは生きている)と SchedulingDisabled(新規 Pod は配置されない)が並立した状態です。
Step 3: k8s-wl-01 上で kubelet の状態確認と再起動
アップグレード後の kubelet 再起動操作を模擬します。k8s-wl-01 に SSH でログインして実行します。
実行コマンド(k8s-wl-01 上・root):
# systemctl status kubelet実行結果(kubelet が Active: running であることを確認):
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Sat 2026-05-24 10:00:00 JST; 10d ago
Docs: https://kubernetes.io/docs/
Main PID: 1234 (kubelet)
Tasks: 15 (limit: 23170)
Memory: 35.2M
CGroup: /system.slice/kubelet.service
└─1234 /usr/bin/kubelet ...kubelet が正常に稼働していることが確認できます。10-kubeadm.conf という Drop-In ファイルが読み込まれていることも確認できます。このファイルは kubeadm upgrade node が実行されると更新されるため、更新後は systemctl daemon-reload が必要になります。
実行コマンド(kubelet 再起動の模擬・アップグレード後に必須となる操作):
# systemctl daemon-reload
# systemctl restart kubelet実行コマンド(再起動後の確認):
# systemctl status kubelet実行結果(Active: running で再起動が成功していることを確認):
● kubelet.service - kubelet: The Kubernetes Node Agent
Active: active (running) since Sat 2026-05-24 10:05:00 JST; 5s agokubelet が再起動後も正常に稼働しています。since ... 5s ago のタイムスタンプが更新されており、再起動が成功したことがわかります。
Step 4: uncordon でノードを復帰させる
kubelet のメンテナンスが完了したら、ノードをスケジューリング可能な状態に戻します。
実行コマンド(k8s-ops 上・developer):
$ kubectl uncordon k8s-wl-01実行結果:
node/k8s-wl-01 uncordoned実行コマンド(状態確認):
$ kubectl get nodes実行結果(k8s-wl-01 が Ready に戻ったことを確認):
NAME STATUS ROLES AGE VERSION
k8s-cp-01 Ready control-plane 10d v1.35.5
k8s-cp-02 Ready control-plane 9d v1.35.5
k8s-cp-03 Ready control-plane 9d v1.35.5
k8s-wl-01 Ready <none> 9d v1.35.5
k8s-wl-02 Ready <none> 9d v1.35.5k8s-wl-01 が Ready に戻り、SchedulingDisabled の表示が消えました。これで新規 Pod の配置が再び k8s-wl-01 でも受け付けられるようになりました。
drain が失敗するパターン
drain が失敗する代表的なケース:
- PodDisruptionBudget(PDB)の制約: PDB で「最低 N Pod が稼働」の制約がある場合、drain がブロックされます。別ターミナルで
kubectl get pdb -Aを確認し、DISRUPTIONS ALLOWEDが 0 の場合は Pod レプリカ数を増やしてから drain に臨んでください(本回ヒヤリハット②で詳しく説明) --delete-emptydir-dataの指定漏れ: emptyDir ボリュームを使う Pod がある場合、このフラグなしでは drain が停止します。「emptyDir のデータは drain で失われる」ことを承知した上でフラグを指定します- StatefulSet と local-path-provisioner: ローカルストレージにバインドされた PVC を持つ StatefulSet の Pod は、drain によって別ノードに移動できません。第5回のヒヤリハット②で説明した通り、uncordon で元ノードに戻すことが解決策です
やってみよう③: Pod Forbidden / Pending ミニトラブルシュート演習(ResourceQuota 切り分け)
アップグレード後に Pod が Pending になる典型原因のひとつ(ResourceQuota 違反)を実機で体験し、kubectl describe pod の Events セクションから原因を特定する手順を習得します。CKA D5「Troubleshoot application failure」に直接対応する演習です。
作業場所: k8s-ops(developer)
演習シナリオ
- Namespace
quota-testに ResourceQuota を設定し、CPU / Memory に上限を設ける - 上限を超える Pod をデプロイして Pending を意図的に発生させる
kubectl describe podで Events を読み取り、原因を特定する- ResourceQuota の使用状況を確認する
- クリーンアップ
Step 1: テスト用 Namespace の作成
実行コマンド(k8s-ops 上・developer):
$ kubectl create namespace quota-test実行結果:
namespace/quota-test createdStep 2: ResourceQuota の作成
以下のマニフェスト(quota-test-quota.yaml)を作成します。
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
namespace: quota-test
spec:
hard:
requests.cpu: "500m"
requests.memory: "256Mi"
limits.cpu: "1000m"
limits.memory: "512Mi"
pods: "3"このマニフェストでは次の上限を設定しています。
requests.cpu: "500m": Namespace 全体の CPU requests の上限を 500m(0.5 コア)に制限requests.memory: "256Mi": Namespace 全体の Memory requests の上限を 256Mi に制限limits.cpu: "1000m": Namespace 全体の CPU limits の上限を 1000m(1 コア)に制限limits.memory: "512Mi": Namespace 全体の Memory limits の上限を 512Mi に制限pods: "3": Namespace 内の Pod 総数の上限を 3 個に制限
実行コマンド:
$ kubectl apply -f quota-test-quota.yaml実行結果:
resourcequota/compute-quota createdStep 3: ResourceQuota の初期状態確認
実行コマンド:
$ kubectl describe resourcequota compute-quota -n quota-test実行結果(Used = 0・Namespace が空であることを確認):
Name: compute-quota
Namespace: quota-test
Resource Used Hard
-------- ---- ----
limits.cpu 0 1
limits.memory 0 512Mi
pods 0 3
requests.cpu 0 500m
requests.memory 0 256MiUsed がすべて 0 の状態です。この Namespace にはまだ Pod が何もありません。
Step 4: 上限を超える Pod の作成(admission で Forbidden を発生させる)
ResourceQuota の requests.cpu 上限(500m)を超える 600m の CPU requests を指定した Pod を作成します。ResourceQuota は admission(受付)段階で評価されるため、Pod は API Server に到達した時点で 作成自体が拒否される(Pending にすらならない)動作を確認します。
実行コマンド(requests.cpu 600m で quota の 500m を超える):
$ cat << 'EOF' | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: large-pod
namespace: quota-test
spec:
containers:
- name: large-pod
image: 192.168.1.123:5000/nginx:1.27
resources:
requests:
cpu: 600m
memory: 128Mi
limits:
cpu: 600m
memory: 128Mi
EOF実行結果(admission 段階で Forbidden・Pod は作成されない):
Error from server (Forbidden): pods "large-pod" is forbidden: exceeded quota: compute-quota, requested: requests.cpu=600m, used: requests.cpu=0, limited: requests.cpu=500mエラーメッセージに「exceeded quota: compute-quota」「requested: 600m」「limited: 500m」の 3 要素が揃っています。CKA 試験本番では、このメッセージから「quota 違反」「どの quota」「具体的な超過量」が即座に読み取れることが採点ポイントです。Pod が作成されていないことも kubectl get pod -n quota-test で確認しておきます。
実行コマンド:
$ kubectl get pods -n quota-test実行結果(Pod が存在しない):
No resources found in quota-test namespace.Step 5: 「Pending」と「Forbidden」の使い分けを理解する
本回の演習では Pod は admission で拒否されたため、kubectl describe pod で見るべき Events はありません(Pod 自体が存在しません)。一方、本番では Pod が「作成されたうえで Pending」になるケースがしばしばあります。代表は次の 2 パターンです。
- Deployment / ReplicaSet 経由の作成: コントローラが Pod 作成を試み、admission で却下されるとログを残しつつ再試行します。
kubectl describe rs <rs名>の Events にFailedCreate ... is forbidden: exceeded quota ...が記録されます - Node 容量不足によるスケジュール失敗: ResourceQuota は通過したが、どのノードも十分な空き CPU/Memory を持たない場合、Pod は
Pendingのまま残り、kubectl describe podの Events にFailedScheduling: 0/5 nodes are available: 5 Insufficient cpuが出ます
つまり「ResourceQuota 違反 = Forbidden(admission 段階)」「Node 容量不足 = Pending(スケジュール段階)」と整理すると、エラーメッセージから「どのフェーズで失敗したか」が即座に分かります。CKA 試験では両者を区別する力が問われます。
Step 6: ResourceQuota の使用状況確認
実行コマンド:
$ kubectl describe resourcequota compute-quota -n quota-test実行結果(Used がすべて 0 のまま → Pod が admission で拒否されリソースを消費していない):
Name: compute-quota
Namespace: quota-test
Resource Used Hard
-------- ---- ----
limits.cpu 0 1
limits.memory 0 512Mi
pods 0 3
requests.cpu 0 500m
requests.memory 0 256MiUsed がすべて 0 のままです。admission で拒否された Pod は実際にはクラスタに作成されないため、quota の使用量に反映されません。
Pod Pending 原因の切り分けフロー
本演習で習得した手順を一般化した切り分けフローです。試験でも「STATUS が Pending の Pod を調査せよ」という問題が出題されます。
kubectl get pod <name> -n <ns>
↓ STATUS = Pending
kubectl describe pod <name> -n <ns>
↓ Events セクションを確認
├─ "exceeded quota" → ResourceQuota 違反 → quota を確認・調整
├─ "Insufficient cpu/memory" → Node リソース不足 → kubectl top nodes で確認
├─ "didn't match node selector" → nodeSelector / affinity ミス → Pod spec を確認(第7回で学習)
└─ "had volume node affinity conflict" → local-path PV のノード固定 → 第5回 ヒヤリハット②参照Step 7: クリーンアップ
実行コマンド:
$ kubectl delete namespace quota-test実行結果:
namespace "quota-test" deletedNamespace を削除すると、その Namespace に属する ResourceQuota・Pod などのリソースが一括削除されます。演習後のクリーンアップとして有効な手順です。
まとめ・現場ヒヤリハット・理解度チェック
第6回のまとめ
第6回で習得した内容を整理します。
- kubeadm upgrade plan の読み取り: CURRENT == AVAILABLE の出力は「クラスタは最新版で upgrade 不要」を意味する。月次・四半期ごとの定期実行で新しいパッチリリースを確認する運用スキルとして定着させる
- Kubernetes version skew policy: kubelet は kube-apiserver より最大 3 マイナー古くてよい(v1.28 以降。v1.27 以前は最大 2 マイナー)。しかし kubelet が kube-apiserver より新しくなることは許容されない。この非対称性がアップグレード順序(Control Plane を先に・Workload Node を後に)を決める根拠
- kubeadm ローリングアップグレードの正規順序: CP プライマリ(upgrade apply)→ CP 追加(upgrade node)→ Workload Node(drain → upgrade node → uncordon)の順序を崩さない
- dnf versionlock の管理: versionlock list / delete / add の 3 コマンドでパッケージのバージョン固定を管理できる。apt-mark hold/unhold との対応も CKA 試験対策として把握しておく
- Pod Pending のトラブルシュート:
kubectl describe podの Events セクションでexceeded quota/Insufficient cpu/didn't match node selector/volume node affinity conflictの 4 パターンを切り分けられる
次回予告
第7回では、稼働中の HA クラスタに対して Pod スケジューリング を詳しく扱います。nodeSelector / nodeAffinity / podAffinity / podAntiAffinity で「どのノードに Pod を配置するか」を細かく制御し、taints と tolerations で「特定 Pod 専用ノード」の設計を実践します。「なぜ fanclub-api の Backend が常に特定ノードに偏るのか」という疑問を、スケジューラーの視点から解決していきます。CKA D2(Workloads and Scheduling)の核心テーマです。
現場ヒヤリハット
ヒヤリハット① Workload Node を先にアップグレードして version skew 違反
状況: kubeadm アップグレード作業中、「Workload Node の方が本番影響が大きいから後回しにしよう」という発想で、Control Plane を後にして Workload Node の kubelet を先にアップグレードした。
原因: Workload Node の kubelet が v1.36 になった時点で、まだ v1.35 の kube-apiserver との間で version skew ポリシー違反(kubelet > kube-apiserver は禁止)が発生。kubelet が kube-apiserver と通信できなくなり、ノードが NotReady になった。
対処: kubectl get nodes で NotReady を確認 → kubectl describe node k8s-wl-01 の Conditions セクションでエラーを特定 → Control Plane ノードを先に v1.36 にアップグレードして解消。
教訓: 必ず Control Plane を先に、Workload Node を後に アップグレードする。version skew ポリシーは「kubelet が kube-apiserver より古い方向の差は許容されるが、新しくなってはいけない」を常に意識してください。「本番影響が大きいから後回し」という判断は、アップグレード順序の文脈では逆効果になります。
ヒヤリハット② drain 中に PodDisruptionBudget でブロックされ 30 分タイムアウト待ち
状況: 本番環境でアップグレード作業中、kubectl drain k8s-wl-01 --ignore-daemonsets --delete-emptydir-data を実行したところ、30 分間コマンドが返らなかった。
原因: fanclub-api に PodDisruptionBudget(PDB)が設定されており、「最低 1 Pod は稼働」の制約があった。全 fanclub-api Backend Pod が k8s-wl-01 に偏在していたため、drain による退避が PDB に阻まれた。
対処: 別ターミナルで kubectl get pdb -A を確認し PDB を発見 → kubectl describe pdb で DISRUPTIONS ALLOWED = 0(退避不可)を確認 → 先に kubectl scale deployment fanclub-api-fanclub-api --replicas=3 でレプリカ数を増やし、別ノードに Pod を分散 → drain が通過した。
教訓: drain 前に kubectl get pdb -A で PDB の状態を確認する。DISRUPTIONS ALLOWED が 0 の場合は Pod を増やすか PDB を一時的に調整してから drain に臨む。drain の「30 分無応答」は PDB ブロックの典型的なサインです。
理解度チェック
第6回の理解度を ○× 形式の 8 問で確認します。まず問題を読み、自分なりに答えを出してから解説を読んでください。
- 問 1:
kubeadm upgrade planは Control Plane Node 上で実行する必要がある - 問 2: Kubernetes v1.28 以降、kubelet は kube-apiserver より最大 3 マイナー古くてよい
- 問 3: Workload Node の kubelet を Control Plane の kube-apiserver より新しいバージョンにすることは許容される
- 問 4: kubeadm ローリングアップグレードでは、Control Plane Node を先にアップグレードする
- 問 5: Control Plane 追加ノード(k8s-cp-02/03)では
kubeadm upgrade applyを使う - 問 6:
kubectl drainを実行すると、DaemonSet 管理下の Pod も退避される - 問 7: Pod が Pending のとき、
kubectl describe podの Events セクションに原因が表示される - 問 8:
dnf versionlock deleteは指定したパッケージのバージョン固定を解除するコマンドである
問 1: ○ — kubeadm upgrade plan はクラスタの設定情報(kube-apiserver のバージョン・コンポーネント設定など)を参照するコマンドです。このコマンドは Control Plane Node 上で実行する必要があります。Workload Node では kubeadm が kube-apiserver に直接アクセスできないため、実行しても正確な情報が得られません。
問 2: ○ — v1.28 以降は「最大 3 マイナー」に拡張されました(v1.27 以前は最大 2 マイナー)。v1.35 環境では kube-apiserver が v1.35 の場合、kubelet は v1.35 / v1.34 / v1.33 まで許容されます(v1.32 以下は NG)。
問 3: × — kubelet が kube-apiserver より新しくなることは許容されません。これが version skew policy の最重要ルールです。「古い方向の差は許容・新しくなることは禁止」という非対称性を覚えてください。
問 4: ○ — version skew policy により「Control Plane(kube-apiserver)を先に上げれば、Workload Node の kubelet が一時的に古くても許容範囲内」になります。逆順だと kubelet が kube-apiserver より新しくなり、ポリシー違反になります。
問 5: × — Control Plane 追加ノード(k8s-cp-02/03)では kubeadm upgrade node を使います。upgrade apply vX.Y.Z はプライマリ 1 台のみで実行するコマンドです。誤って cp-02 で upgrade apply を実行すると、クラスタ設定が二重に適用されるリスクがあります。
問 6: × — DaemonSet 管理下の Pod(Calico CNI の calico-node・kube-proxy など)は drain で退避できません。--ignore-daemonsets フラグで「DaemonSet Pod は退避対象外にする」ことを明示する必要があります。フラグなしでは drain がエラーで停止します。
問 7: ○ — kubectl describe pod の Events セクションは Pod のスケジューリング失敗・コンテナ起動失敗などの原因を調査する際の第一手です。exceeded quota・Insufficient cpu/memory・didn't match node selector・volume node affinity conflict の 4 パターンを覚えておくと、CKA 試験のトラブルシュート問題で素早く対処できます。
問 8: ○ — dnf versionlock delete 'kubeadm' のようにパッケージ名のみを指定すると、そのパッケージに対する全バージョンロックが解除されます。Ubuntu 相当は apt-mark unhold kubeadm です。アップグレード後は必ず dnf versionlock add で新バージョンのロックを再設定してください。
シリーズ一覧
第1部:クラスタ構築
- 第1回 第2巻スコープ + CKA 試験形式紹介 + kubeadm 概要 + kubeadm vs RKE2/k0s/OKD 概観
- 第2回 kubeadm シングルノード起動(pkgs.k8s.io + kubeadm init + Calico CNI)+ alma-proxy whitelist 構築
- 第3回 kubeadm HA 設計 + HAProxy LB(API Server LB 構成)
- 第4回 kubeadm HA クラスタ構築(CP×3 + WL×2)+ fanclub-api HA 移行
- 第5回 etcd backup/restore(etcdutl)+ ノード drain/uncordon
第2部:ワークロード管理
- 第6回 kubeadm upgrade + ノード drain/cordon + ミニトラブルシュート演習 ← 今ここ
- 第7回 Pod スケジューリング(taint/toleration/affinity/anti-affinity/PriorityClass)
- 第8回 HPA + ResourceQuota + LimitRange
第3部:ネットワーク
- 第9回 Service 詳細 + MetalLB(LoadBalancer 動作確認)
- 第10回 NetworkPolicy 詳細 + Calico/Cilium 比較 + ミニトラブルシュート演習
- 第11回 Gateway API + Traefik + cert-manager + CoreDNS(HTTPS 公開完成)
第4部:ストレージ
第5部:監視・運用
- 第13回 Prometheus + Grafana + Loki + Fluent Bit + fanclub-api 監視ダッシュボード
- 第14回 Helm + Kustomize でクラスタコンポーネント install + ArgoCD GitOps + Velero backup
