
新卒インフラエンジニア向け Kubernetes 実践教科書(第2巻 CKA 編)の第4回です。動作確認バージョン: AlmaLinux 10.1 / K8s v1.35.5 / kubeadm v1.35.5 / containerd.io v2.2.4 / Calico v3.32.0 / local-path-provisioner v0.0.30 / Helm v4.1.4(2026-05-22 時点・k8s-cp-01〜03 / k8s-wl-01〜02 / k8s-ops 実機検証済)。第2回では k8s-cp-01 に kubeadm v1.35 をインストールしてシングルノードクラスタを起動し、第3回では k8s-lb の HAProxy を HA 本格設計版(CP×3 backend・stats・tcp-check)に作り込みました。いよいよ第4回では「kubeadm HA クラスタ構築」を完遂します。k8s-cp-02/03 に kubeadm join --control-plane を実行して Control Plane を 3 台に増やし、k8s-wl-01/02 を Workload Node として参加させます。さらに第1巻で kind クラスタに構築した fanclub-api を、この kubeadm HA クラスタへ Helm chart を使って移行します。kubectl get nodes で 5 ノード全員 Ready の状態を目にする瞬間が、本回の最大のゴールです。本回は第2巻最大の山場であり、第1部「クラスタ構築」のマイルストーン回でもあります。
- 今ここマップ(第4回 / 全16回 / 第1部)
- 第4回のスコープと設計判断 — HA 完成への最終工程
- 4 ノードのフル準備 — 第2回手順を CP/WL 差分つきで適用する
- 証明書の再アップロードと join コマンド生成
- やってみよう① k8s-cp-02/03 を Control Plane として join する
- やってみよう② k8s-wl-01/02 を Workload Node として join する
- 5 ノード Ready 確認と HAProxy stats の全 backend UP 確認
- containerd の insecure registry 設定(hosts.toml 方式・全 5 ノード)
- local-path-provisioner の導入(kubeadm クラスタの暫定 StorageClass)
- やってみよう③ fanclub-api を Helm で HA クラスタにデプロイする
- やってみよう④ port-forward で fanclub-api の動作を確認する
- まとめと次回予告
- 現場ヒヤリハット
- 理解度チェック
- シリーズ一覧
今ここマップ(第4回 / 全16回 / 第1部)
今ここマップ(第2巻 16 回中の現在位置):
今ここ: 第4回 / 全16回(第1部:クラスタ構築)
▓▓▓▓░░░░░░░░░░░░ 25%
第1部(クラスタ構築): ■■■■□ 4/5 回(進行中)
第2部(ワークロード管理): □□□ 0/3 回
第3部(ネットワーク): □□□ 0/3 回
第4部(ストレージ): □ 0/1 回
第5部(監視・運用): □□ 0/2 回
第6部(トラブルシュート): □□ 0/2 回第4回で学ぶことは次の 6 点です。これがそのまま今回の学習目標になります。
- k8s-cp-02/03・k8s-wl-01/02 の 4 ノードに、kubeadm join 前提の OS フル準備(swap 無効化・カーネルモジュール・firewalld・containerd・kubelet/kubeadm)を実施できる
kubeadm init phase upload-certs --upload-certsで証明書を再アップロードし、新しい certificate-key を取得できるkubeadm join k8s-lb:6443 --control-plane --certificate-keyで追加の Control Plane Node(k8s-cp-02/03)を参加させられるkubeadm join k8s-lb:6443で Workload Node(k8s-wl-01/02)を参加させ、kubectl get nodesで 5 ノード全員 Ready を確認できる- containerd の hosts.toml 方式で insecure registry 設定を全ノードに適用し、
local-path-provisionerを導入して既定 StorageClass を用意できる - 第1巻で作成した fanclub-api Helm chart を kubeadm HA クラスタに再デプロイし、
kubectl port-forwardで動作確認できる(https://fanclub.local完全公開は第11回)
第4回終了時の達成状態を整理します。第5回以降の前提になる状態です。
- k8s-cp-01〜03(Control Plane HA)+ k8s-wl-01〜02(Workload Node)の 5 ノードが全員 Ready になっている
- HAProxy stats ページで全 backend(k8s-cp-01〜03)が UP 表示になっている
- fanclub-api が kubeadm HA クラスタ上の
fanclubNamespace で稼働している kubectl port-forwardで fanclub-backend の API レスポンスを確認済みである- 第5回以降に向けた基盤(3 ノード stacked etcd・kubeadm HA クラスタ)が整っている
第4回のスコープと設計判断 — HA 完成への最終工程
実機作業に入る前に、第3回・第4回の役割分担と、第4回で行う 3 つの設計判断を整理します。本回は実機操作が多く、複合論点が重なる回です。「何をどこまでやるか」「なぜその手段を選ぶか」を先に把握しておくと、各手順の目的が明確になり、作業中に迷いません。
第3回・第4回の役割分担
第2回から第4回は「HA クラスタを作り上げる 3 回連続のシリーズ」です。第2回でシングル CP クラスタを起動し、第3回で LB を HA 設計に育て、第4回で全ノードを参加させて HA クラスタを完成させます。第3回・第4回の役割分担を次の表に整理します。
| 回 | k8s-lb | k8s-cp-01 | k8s-cp-02/03 | k8s-wl-01/02 | fanclub-api |
|---|---|---|---|---|---|
| 第3回(完了) | HAProxy HA 設計版稼働 | init 済み(シングル CP) | VM 稼働中・未 join | VM 稼働中・未 join | — |
| 第4回(本回) | 変更なし | 起点ノード(join コマンド発行) | kubeadm join –control-plane | kubeadm join(WL) | Helm で HA クラスタに移行 |
k8s-cp-01 は第4回でも「起点ノード」として中心的な役割を担います。証明書の再アップロードも join コマンドの生成も、すべて k8s-cp-01 上で行います。k8s-lb の HAProxy 設定は第3回で完成しているため、第4回では一切変更しません。CP-02/03 が join して kube-apiserver が起動すると、HAProxy の tcp-check が自動的に成功に転じ、stats ページの表示が DOWN から UP に変わります。
第4回で「やること」と「やらないこと」
第4回は実機作業が多い回です。スコープを明確にして、今回扱う範囲と後の回に委ねる範囲を切り分けます。
| やること | やらないこと |
|---|---|
| 4 ノード(cp-02/03・wl-01/02)の OS フル準備 | MetalLB / Gateway API / Traefik の設置(→ 第9〜11回) |
| 証明書再アップロード + join コマンド生成 | https://fanclub.local の完全 HTTPS 公開(→ 第11回) |
| kubeadm join –control-plane(CP×2) | Longhorn ストレージの設置(→ 第12回) |
| kubeadm join(WL×2) | HPA・ResourceQuota の設定(→ 第8回) |
| containerd insecure registry 設定(全 5 ノード) | etcd backup/restore の演習(→ 第5回) |
| local-path-provisioner 導入(暫定 SC) | — |
| fanclub-api Helm デプロイ(Gateway/HTTPRoute 無効化) | — |
kubectl port-forward で動作確認 | — |
本回には 3 つの設計判断が含まれます。いずれも「教材としての最適解」を選んだ結果であり、後回しにする部分は明確なロードマップを示します。順に説明します。
設計判断① 暫定ストレージとして local-path-provisioner を導入する
kubeadm でクラスタを構築すると、初期状態には StorageClass が 1 つも存在しません。これは kind クラスタとの大きな違いです。kind は標準で standard という StorageClass を同梱しますが、kubeadm はストレージプロビジョナーを一切インストールしません。StorageClass がないと、fanclub-db(PostgreSQL 18 の StatefulSet)が要求する PersistentVolumeClaim はバインド先の PersistentVolume を見つけられず、永遠に Pending のままになります。
そこで本回では local-path-provisioner v0.0.30 を導入し、local-path という既定 StorageClass を用意します。これはノードのローカルディスクを使うシンプルなプロビジョナーで、kind クラスタが内部で使っているものと同系統です。第1巻を完走した読者には馴染みがあるはずです。データは各ノードの /opt/local-path-provisioner/ 配下に保存されます。
ただし local-path-provisioner には重大な制約があります。データが特定ノードのローカルディスクに固定されるため、そのノードが障害を起こすとデータは失われます。レプリケーション(複製)の仕組みがないからです。本番環境でこの構成を使ってはいけません。本回ではこれを「暫定ストレージ」と明示し、第12回で Longhorn 分散ストレージに移行します。「暫定」と位置づけることで、第12回のストレージ移行演習の動機づけにもなります。
設計判断② 動作確認は port-forward で行う(https://fanclub.local は第11回)
第2巻の curriculum には、第4回の演習内容として「ブラウザから https://fanclub.local アクセス確認」と記載があります。しかし第4回時点では、これをそのまま実現するために必要なコンポーネントがすべて未整備です。具体的には、外部 IP を払い出す MetalLB(第9回)、トラフィックを振り分ける Gateway API + Traefik(第11回)、TLS 証明書を発行する cert-manager(第11回)が、いずれもまだクラスタに入っていません。
そこで本回では、curriculum の到達目標を「HA クラスタ上で fanclub-api の Pod が Running になり、kubectl port-forward で API レスポンスを確認できること」に設定し直します。これは手抜きではありません。第4〜11回のロードマップを誠実に読者へ提示する設計判断です。外部公開の段階的なロードマップを次の表に整理します。
| 回 | 整備するコンポーネント | fanclub-api の外部公開状態 |
|---|---|---|
| 第4回(本回) | local-path-provisioner | kubectl port-forward での HTTP 動作確認のみ |
| 第9回 | MetalLB | LoadBalancer Service に外部 IP が払い出される |
| 第11回 | Gateway API + Traefik + cert-manager | https://fanclub.local での HTTPS 公開完成 |
第4回で「やらないこと」を、どの回で完全解決するかを対応づけた表も示します。読者が「いつ何が完成するのか」を見通せるようにするためのものです。
| 課題 | 第4回での対応 | 完全解決の回 |
|---|---|---|
| LoadBalancer Service の外部 IP | NodePort + port-forward で代替 | 第9回 MetalLB |
| HTTPRoute(Gateway API)でのルーティング | Gateway/HTTPRoute テンプレートを無効化 | 第11回 Gateway API + Traefik |
| HTTPS 証明書 | HTTP での動作確認に留める | 第11回 cert-manager |
設計判断③ fanclub-api Helm chart の Gateway/HTTPRoute を無効化してデプロイする
Step 6 の実機検証で確認した第1巻 chart は最小構成(ServiceAccount / Secret / ConfigMap / Service / Deployment のみ)で、Gateway / HTTPRoute テンプレートを含みません。第4回時点では Gateway API の CRD(カスタムリソース定義)がクラスタにインストールされていないため、もし HTTPRoute テンプレートが含まれていたら apply 時に「unknown kind」エラーで Helm install が失敗します。本回は chart 側にそもそも該当テンプレートが無いため Gateway 無効化指定は不要で、helm install をそのまま実行すれば backend Deployment + Service のみが作成されます。HTTPS 公開(https://fanclub.local)は第9回(MetalLB で LoadBalancer 払い出し)→ 第11回(Gateway API CRD + Traefik + cert-manager)の段階で実現します。
第4回終了時点での各 VM の状態
第4回が終わったとき、各 VM がどういう状態になっているかを先に確認します。この表が本回の「ゴール」です。太字の 4 行が本回で状態が変わるノードです。
| VM | 第4回終了時の状態 |
|---|---|
| k8s-lb(192.168.1.124) | HAProxy HA 設計版稼働中(前回から変更なし) |
| k8s-cp-01(192.168.1.125) | Control Plane Node #1(kubeadm init 済み) |
| k8s-cp-02(192.168.1.126) | Control Plane Node #2(kubeadm join –control-plane 済み) |
| k8s-cp-03(192.168.1.127) | Control Plane Node #3(kubeadm join –control-plane 済み) |
| k8s-wl-01(192.168.1.128) | Workload Node #1(kubeadm join 済み) |
| k8s-wl-02(192.168.1.129) | Workload Node #2(kubeadm join 済み) |
完成形のアーキテクチャをアスキー図で示します。k8s-ops からの kubectl は k8s-lb:6443 を経由し、HAProxy がラウンドロビンで 3 台の Control Plane Node に振り分けます。3 台の CP ノード上には kube-apiserver と etcd が同居し(stacked etcd 構成)、etcd 同士は Raft で同期します。fanclub-api の Pod は 2 台の Workload Node 上で稼働します。
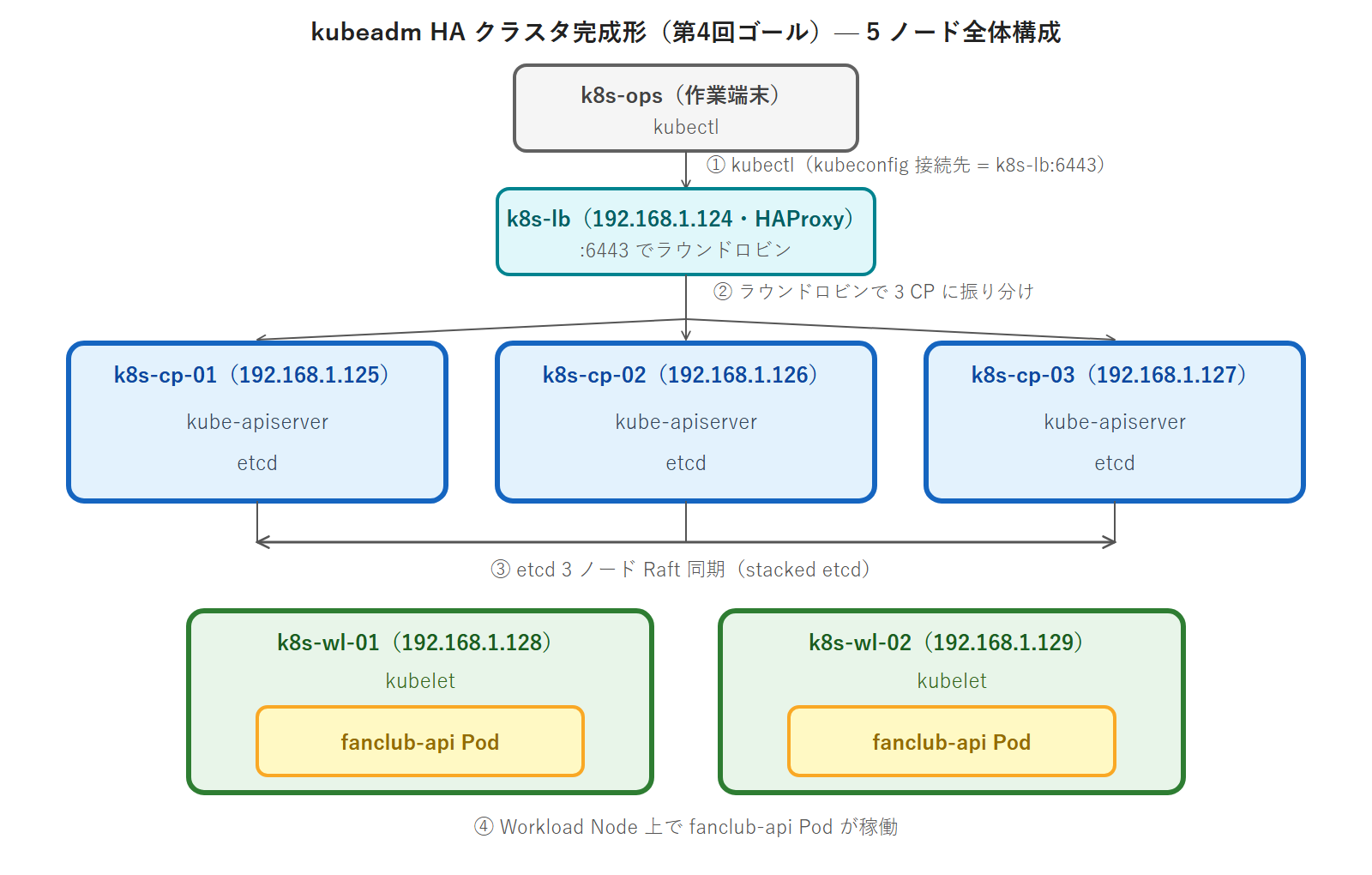
4 ノードのフル準備 — 第2回手順を CP/WL 差分つきで適用する
最初の作業は、k8s-cp-02/03 と k8s-wl-01/02 の 4 ノードを kubeadm join 可能な状態にすることです。この準備手順は、第2回で k8s-cp-01 に実施したものとほぼ同一です。第2回の H2-4〜H2-6 で「kubeadm 前提の OS 準備」「containerd インストール」「kubeadm/kubelet/kubectl インストール」を詳しく解説しました。本回では同じ手順を 4 ノードに繰り返すため、全文を再掲せず要点を簡潔にまとめます。第2回の記事を手元に開きながら作業すると確実です。
第2回と決定的に異なる点が 1 つあります。firewalld の開放ポートが Control Plane Node と Workload Node で異なることです。この差分は本 H2 の後半で表を使って明示します。まずは 4 ノード共通の準備手順を順に見ていきます。各手順は root または sudo 権限で実行します。
準備手順の全体像(第2回からの再掲)
4 ノードに対して行う準備作業は次の 8 ステップです。ステップ 1〜5 と 7〜8 は 4 ノード共通、ステップ 6(firewalld)だけが CP と WL で異なります。
- ステップ 1: プロキシ設定(
/etc/profile.d/proxy.sh・no_proxy はホスト名込みの包括版) - ステップ 2: OS アップデート(AlmaLinux 10.1 化)
- ステップ 3: swap 無効化(kubeadm 必須要件)
- ステップ 4: カーネルモジュール設定(overlay / br_netfilter)
- ステップ 5: sysctl 設定(ブリッジ経由パケットの iptables 処理・IP フォワード)
- ステップ 6: firewalld 設定(CP と WL で開放ポートが異なる)
- ステップ 7: containerd インストール(docker-ce repo + containerd.io + SystemdCgroup=true)
- ステップ 8: kubeadm / kubelet / kubectl インストール(v1.35.5 + versionlock)
ステップ 1: プロキシ設定(4 ノード共通)
本シリーズの検証環境では、外部ネットワークへのアクセスは alma-proxy(Squid・whitelist 方式)を経由します。各ノードに /etc/profile.d/proxy.sh を設置します。ここで最も重要なのは、no_proxy に全ノードのホスト名を必ず含めることです。第2回の実機検証で、no_proxy にホスト名が抜けていると kubeadm join 後にプロキシ経由の通信トラブルが起きることを確認しています。本回でも同じバグを踏まないよう、ホスト名込みの包括版を使います。実行コマンド(4 ノード共通・sudo で実行):
# cat > /etc/profile.d/proxy.sh << 'EOF'
export http_proxy=http://192.168.1.121:3128
export https_proxy=http://192.168.1.121:3128
export no_proxy=localhost,127.0.0.1,192.168.1.0/24,10.0.10.0/24,10.96.0.0/12,10.244.0.0/16,.svc,.cluster.local,k8s-lb,k8s-ops,k8s-registry,k8s-cp-01,k8s-cp-02,k8s-cp-03,k8s-wl-01,k8s-wl-02,alma-proxy
EOF
# source /etc/profile.d/proxy.shno_proxy に含めている値の意味を補足します。192.168.1.0/24 は外部ネットワーク、10.0.10.0/24 は内部ネットワーク、10.96.0.0/12 は Service の ClusterIP レンジ、10.244.0.0/16 は Pod ネットワークの CIDR です。これらに加えて、k8s-lb をはじめとする全 VM のホスト名を列挙しています。kubeadm join はクラスタの接続先を k8s-lb:6443(ホスト名)として扱うため、ここでホスト名が漏れていると、kubelet が Squid プロキシ経由で API Server へ接続しようとして失敗します。
ステップ 2〜5: OS 準備(4 ノード共通)
OS アップデートを実行し、AlmaLinux 10.1 になっていることを確認します。実行コマンド(4 ノード共通):
# dnf update -y
# cat /etc/almalinux-release実行結果(AlmaLinux 10.1 であることを確認):
AlmaLinux release 10.1 (Heliotrope Lion)次に swap を無効化します。kubeadm は swap が有効なノードでは kubeadm join の preflight チェックでエラーを出します。kubelet がメモリ管理を正確に行うためです。実行コマンド:
# swapoff -a
# sed -i.bak '/swap/s/^/#/' /etc/fstab
# free -h | grep Swap実行結果(Swap が 0B になっていることを確認):
Swap: 0B 0B 0Bswapoff -a は実行中のシステムから swap を即座に外しますが、再起動すると /etc/fstab の設定で swap が復活します。sed で /etc/fstab の swap 行をコメントアウトし、再起動後も swap が無効のままになるようにします。
続いてカーネルモジュールを設定します。overlay はコンテナのオーバーレイファイルシステム、br_netfilter はブリッジを通過するパケットを iptables で処理するために必要です。実行コマンド:
# cat > /etc/modules-load.d/k8s.conf << 'EOF'
overlay
br_netfilter
EOF
# modprobe overlay
# modprobe br_netfiltersysctl 設定を追加します。ブリッジ経由のパケットを iptables のルールで処理させ、IP フォワードを有効にします。Pod 間通信と Service の動作に必須の設定です。実行コマンド:
# cat > /etc/sysctl.d/k8s.conf << 'EOF'
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# sysctl --systemステップ 6: firewalld 設定 — CP と WL でポートが異なる
ここが第2回からの最大の差分です。Control Plane Node と Workload Node では、開放すべきポートが異なります。CP ノードは kube-apiserver・etcd・kube-controller-manager・kube-scheduler という Control Plane コンポーネントを動かすため、それぞれのポートを開放します。WL ノードは kubelet と NodePort Service のポートだけで足ります。まず CP ノード(k8s-cp-02/03)の設定です。実行コマンド(k8s-cp-02 / k8s-cp-03 で実行):
# firewall-cmd --permanent --add-port=6443/tcp
# firewall-cmd --permanent --add-port=2379-2380/tcp
# firewall-cmd --permanent --add-port=10250/tcp
# firewall-cmd --permanent --add-port=10257/tcp
# firewall-cmd --permanent --add-port=10259/tcp
# firewall-cmd --reload
# firewall-cmd --list-ports実行結果(CP ノードの開放ポート一覧):
6443/tcp 2379-2380/tcp 10250/tcp 10257/tcp 10259/tcp次に WL ノード(k8s-wl-01/02)の設定です。開放するのは kubelet API の 10250 と、NodePort Service が使う 30000-32767 の 2 つだけです。実行コマンド(k8s-wl-01 / k8s-wl-02 で実行):
# firewall-cmd --permanent --add-port=10250/tcp
# firewall-cmd --permanent --add-port=30000-32767/tcp
# firewall-cmd --reload
# firewall-cmd --list-ports実行結果(WL ノードの開放ポート一覧):
10250/tcp 30000-32767/tcpCP と WL で開放するポートの差分を表に整理します。CKA 試験でも問われる重要な区別です。「どのポートがどのコンポーネント用か」を理解しておくと、ファイアウォール起因の通信トラブルを切り分けられます。
| ポート | Control Plane | Workload Node | 用途 |
|---|---|---|---|
| 6443/tcp | 要 | 不要 | kube-apiserver |
| 2379-2380/tcp | 要 | 不要 | etcd(クライアント通信 + クラスタ間通信) |
| 10250/tcp | 要 | 要 | kubelet API |
| 10257/tcp | 要 | 不要 | kube-controller-manager |
| 10259/tcp | 要 | 不要 | kube-scheduler |
| 30000-32767/tcp | 不要 | 要 | NodePort Service |
kubelet API の 10250 だけは CP / WL の両方で必要です。kubelet はすべてのノード(CP も WL も)で動くため、どのノードでも 10250 を開けます。CP 専用のポート(6443・2379-2380・10257・10259)を WL ノードに開けても join 自体は成功しますが、不要なポートを公開すると攻撃面が増えます。最小権限の原則に従い、役割ごとに必要最小限のポートだけを開放するのが正しい設計です。
ステップ 6b: Calico ネットワーク用 firewalld(4 ノード共通・忘れやすい必須設定)
第2回で k8s-cp-01 に設定した Calico の firewalld 開放(BGP 179/tcp・IPIP プロトコル・Pod CIDR 10.244.0.0/16・ノード間ネットワーク 192.168.1.0/24 を trusted ゾーンに追加)を、本回で追加する 4 ノード(k8s-cp-02/03・k8s-wl-01/02)にも必ず適用します。これが抜けると、ノードは Ready になり Pod も起動しますが、別ノードに跨る Pod への到達(例: API Server から Workload Node 上の metrics-server Pod・MetalLB / cert-manager の admission webhook)が firewalld で遮断されます。症状として、第8回の kubectl top nodes が Metrics API not available(APIService が FailedDiscoveryCheck)になったり、第9回 MetalLB・第11回 cert-manager の webhook が context deadline exceeded で失敗します。実行コマンド(k8s-cp-02 / k8s-cp-03 / k8s-wl-01 / k8s-wl-02 の 4 ノードで実行):
# firewall-cmd --permanent --add-port=179/tcp
# firewall-cmd --permanent --add-protocol=ipip
# firewall-cmd --permanent --zone=trusted --add-source=10.244.0.0/16
# firewall-cmd --permanent --zone=trusted --add-source=192.168.1.0/24
# firewall-cmd --reload
# firewall-cmd --zone=trusted --list-sources実行結果(trusted ゾーンに 2 つの source が登録されていることを確認):
10.244.0.0/16 192.168.1.0/24ステップ 7: containerd インストール(4 ノード共通)
コンテナランタイムの containerd をインストールします。第2回と同様に Docker CE リポジトリから containerd.io パッケージを導入します。実行コマンド(Docker CE リポジトリ追加 + containerd.io インストール):
# dnf config-manager --add-repo https://download.docker.com/linux/rhel/docker-ce.repo
# dnf install -y containerd.io
# systemctl enable --now containerdcontainerd のデフォルト設定を生成し、SystemdCgroup を true に変更します。AlmaLinux 10 は cgroup v2 を採用しているため、kubelet と containerd の両方で cgroup ドライバーを systemd に揃える必要があります。これが揃っていないと kubelet が起動しません。あわせて、本回後半の insecure registry 設定(hosts.toml 方式)が効くよう、第2回で k8s-cp-01 に行ったのと同じく config_path を /etc/containerd/certs.d に変更します。この 4 ノードでも設定しないと、後述の hosts.toml が読み込まれず、fanclub-api のイメージ pull が http: server gave HTTP response to HTTPS client で失敗します。実行コマンド:
# containerd config default | tee /etc/containerd/config.toml
# sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
# sed -i "/\[plugins.'io.containerd.cri.v1.images'.registry\]/{n;s|config_path = ''|config_path = '/etc/containerd/certs.d'|}" /etc/containerd/config.toml
# systemctl restart containerd設定が正しく反映されたことを確認します。実行コマンド:
# grep -E "SystemdCgroup|config_path = '/etc/containerd/certs.d'" /etc/containerd/config.toml実行結果:
SystemdCgroup = true
config_path = '/etc/containerd/certs.d'ステップ 8: kubeadm / kubelet / kubectl インストール(4 ノード共通)
Kubernetes 公式パッケージリポジトリ(pkgs.k8s.io)の v1.35 安定版を登録します。実行コマンド(pkgs.k8s.io リポジトリ追加):
# cat > /etc/yum.repos.d/kubernetes.repo << 'EOF'
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.35/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOFkubelet・kubeadm・kubectl と cri-tools をインストールし、kubelet を有効化します。cri-tools は本 H2 後半の pull テストで使う crictl コマンドを提供します(第2回で k8s-cp-01 に導入したのと同じパッケージで、この 4 ノードでも揃えます)。さらに dnf versionlock でバージョンを固定します。本シリーズではクラスタを K8s v1.35.5 でピン留めしており、dnf update で意図せずバージョンが上がることを防ぎます。本番環境でクラスタのバージョンが勝手に変わるのは重大なアンチパターンです。実行コマンド(インストール + バージョンピン留め):
# dnf install -y --disableexcludes=kubernetes kubelet kubeadm kubectl cri-tools
# systemctl enable kubelet
# dnf versionlock add kubelet kubeadm kubectlバージョンを確認します。実行コマンド:
# kubeadm version -o short実行結果:
v1.35.54 ノードすべてで v1.35.5 が表示されれば、OS 準備は完了です。Workload Node にも kubectl をインストールしていますが、これはトラブルシュート時にノード上で直接診断コマンドを実行するためです。本番環境では作業端末(k8s-ops)からのみ kubectl を使うのが原則です(最小権限の原則・admin kubeconfig が各ノードに残るリスクを限定)。WL ノードに kubectl を入れるのは「学習・障害解析の即応性」を優先した便宜であり、本番では各ノードに kubeconfig を配布しない運用設計が標準です。
第12回で導入する Longhorn は、Workload Node に iscsi-initiator-utils がインストールされていることを要件とします。第12回になってから 4 ノードを再訪するのは手間なので、本回の WL 準備のついでに入れておきます。CP ノードには不要です。実行コマンド(k8s-wl-01 / k8s-wl-02 のみで実行):
# dnf install -y iscsi-initiator-utils
# systemctl enable --now iscsid4 ノードの準備手順を「共通」「CP のみ」「WL のみ」の 3 区分で整理した表を示します。作業の取りこぼしを防ぐチェックリストとして使ってください。
| 作業 | k8s-cp-02/03 | k8s-wl-01/02 |
|---|---|---|
| プロキシ設定(proxy.sh) | 要 | 要 |
| OS アップデート・swap 無効化・カーネルモジュール・sysctl | 要 | 要 |
| firewalld(6443・2379-2380・10257・10259) | 要 | 不要 |
| firewalld(30000-32767) | 不要 | 要 |
| firewalld(10250) | 要 | 要 |
| containerd インストール + SystemdCgroup=true | 要 | 要 |
| kubeadm / kubelet / kubectl + versionlock | 要 | 要 |
| iscsi-initiator-utils(第12回 Longhorn 用) | 不要 | 要 |
証明書の再アップロードと join コマンド生成
4 ノードの準備ができたら、いよいよ join の準備に入ります。join を実行するには、起点ノードである k8s-cp-01 で 2 つの作業を行います。1 つは Control Plane の証明書の再アップロード、もう 1 つは join トークンの再発行です。なぜ「再」アップロード・「再」発行が必要なのかを、有効期限の観点から説明します。
certificate-key の有効期限は 2 時間
第2回で kubeadm init --upload-certs を実行したとき、Control Plane に必要な証明書一式が暗号化されて etcd に保存されました。具体的には kube-system Namespace の kubeadm-certs という Secret に格納されます。この証明書を復号するための鍵が certificate-key です。CP ノードを join するとき、--certificate-key でこの鍵を渡すと、join 先のノードが kubeadm-certs Secret から証明書をダウンロードして展開できます。
重要なのは、この kubeadm-certs Secret の有効期限がわずか 2 時間であることです。第3回で復習したとおり、これはセキュリティ上の配慮です。Control Plane の証明書という極めて機微な情報をいつまでも etcd に置いておくのは危険なため、2 時間で自動削除されます。第2回 init から第3回・第4回を経た今、当時アップロードした証明書はとっくに失効しています。失効した状態で CP join を実行すると kubeadm join はエラーで止まります。そこで join 直前に証明書を再アップロードします。
証明書の再アップロード(k8s-cp-01 で実行)
k8s-cp-01 で証明書を再アップロードします。kubeadm init phase upload-certs は init の一部のフェーズだけを実行するサブコマンドで、クラスタ全体を作り直すわけではありません。証明書を kubeadm-certs Secret に再格納し、新しい certificate-key を出力します。実行コマンド(k8s-cp-01 で root 権限で実行):
# kubeadm init phase upload-certs --upload-certs実行結果(新しい certificate-key が出力される):
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx出力された 64 文字の 16 進数文字列が新しい certificate-key です。この値を控えておき、CP join のコマンドで --certificate-key に渡します。本記事ではプレースホルダーとして xxxx... と表記していますが、実機では毎回異なる値が出力されます。この鍵もまた 2 時間で失効するため、再アップロードから 2 時間以内に CP join を完了させる計画で進めます。
join トークンの再発行(24 時間で失効)
もう 1 つ再発行が必要なのが join トークンです。kubeadm init のときに生成される join トークンのデフォルト有効期限は 24 時間です。certificate-key の 2 時間よりは長いですが、第2回 init から数日経った今は当然失効しています。kubeadm token create --print-join-command を使うと、新しいトークンを生成すると同時に、そのトークンを組み込んだ完全な join コマンドを出力してくれます。実行コマンド(k8s-cp-01 で root 権限で実行):
# kubeadm token create --print-join-command実行結果(Workload Node 向けの join コマンドが出力される):
kubeadm join k8s-lb:6443 --token xxxxxx.xxxxxxxxxxxxxxxx --discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx出力された join コマンドには 2 つの重要な値が含まれます。--token は今発行したトークン、--discovery-token-ca-cert-hash はクラスタの CA 証明書のハッシュです。後者は join するノードが「これは本物のクラスタか」を検証するために使います。このまま実行すれば Workload Node を join できます。接続先が k8s-lb:6443(HAProxy のエンドポイント)になっている点に注目してください。個別の CP ノードの IP ではなく LB を指すことで、CP が増減しても join 手順は変わりません。
CP join が途中で失敗した場合のリカバリ手順
HA join では cp-02 / cp-03 の kubeadm join --control-plane が途中で失敗するケースがあります。代表例は以下のとおりです。
error creating local etcd static pod manifest file: the etcd member XXXX is not started: cp-02 の etcd メンバー追加までは成功したが、etcd Pod の起動が間に合わずタイムアウトtoo many learner members in cluster: 前回失敗した join で追加された learner メンバーが etcd に残っており、次の追加を拒否can only promote a learner member which is in sync with leader: learner が leader と sync する前に promote を試みた
いずれの場合も、再 join の前に「etcd に残った learner メンバーを remove する」「失敗したノードを kubeadm reset でクリーンアップする」「certificate-key を再アップロードする」の 3 ステップが必要です。実行コマンド(k8s-ops で実行・残存メンバーの確認):
$ kubectl exec -n kube-system etcd-k8s-cp-01 -- etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member list末尾列が true のメンバー(learner 状態)または不要な cp-02 / cp-03 メンバーが見つかったら、その 16 進数 ID を控えて remove します。実行コマンド(k8s-ops で実行):
$ kubectl exec -n kube-system etcd-k8s-cp-01 -- etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member remove <learner-id>失敗した cp-02 / cp-03 上で kubeadm reset を実行し、残った Static Pod manifest と etcd データを破棄します。実行コマンド(k8s-cp-02 上・root 権限・cp-03 も同様):
# kubeadm reset -f
# rm -rf /etc/cni/net.d /var/lib/kubelet/pki /var/lib/etcd
# systemctl restart containerdその後 k8s-cp-01 で kubeadm init phase upload-certs --upload-certs を再実行して新しい certificate-key を取得し、再度 CP join に挑みます。本シリーズで cp-02 → cp-03 を順次 join する場合は、cp-02 join 完了 → 約 45 秒待機 → cp-03 join という間隔を空けることで etcd learner promote の競合を避けられます。
CP 向け join コマンドの組み立て
--print-join-command で出力されるのは Workload Node 向けのコマンドです。Control Plane Node を join するには、この WL 向けコマンドに 3 つのオプションを追加します。--control-plane(CP として参加することを指定)、--certificate-key(先ほど再アップロードで取得した鍵)、--apiserver-advertise-address(その CP ノード自身の IP アドレス)の 3 つです。組み立てた CP 向け join コマンドは次のようになります。
kubeadm join k8s-lb:6443 \
--token xxxxxx.xxxxxxxxxxxxxxxx \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
--control-plane \
--certificate-key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
--apiserver-advertise-address 192.168.1.126--apiserver-advertise-address は CP ノードごとに変わります。k8s-cp-02 では 192.168.1.126、k8s-cp-03 では 192.168.1.127 を指定します。このアドレスは「その CP ノード上で起動する kube-apiserver が、自分の所在として他のコンポーネントに知らせる IP」です。各 CP ノードの実 IP を正しく指定しないと、etcd クラスタのメンバー登録がずれて HA 構成が壊れます。次の H2 で実際に join を実行します。
やってみよう① k8s-cp-02/03 を Control Plane として join する
最初の演習です。k8s-cp-02 と k8s-cp-03 を kubeadm join --control-plane で Control Plane Node として参加させます。これにより Control Plane が 3 台になり、HA 構成の根幹が完成します。所要時間の目安は 20〜30 分です。作業場所は k8s-cp-02(192.168.1.126)と k8s-cp-03(192.168.1.127)に、それぞれ root で SSH します。
Step 1: k8s-cp-02 で CP join を実行する
k8s-cp-02 で、前 H2 で組み立てた CP 向け join コマンドを実行します。--apiserver-advertise-address が 192.168.1.126(k8s-cp-02 の IP)になっていることを確認してください。実行コマンド(k8s-cp-02 で root 権限で実行):
# kubeadm join k8s-lb:6443 \
--token xxxxxx.xxxxxxxxxxxxxxxx \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
--control-plane \
--certificate-key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
--apiserver-advertise-address 192.168.1.126実行結果(CP join 成功時の主要な出力行):
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.出力を読み解きます。[download-certs] の行で kubeadm-certs Secret から証明書をダウンロードしています。certificate-key が失効していると、この行でエラーになります。[control-plane] と [etcd] の行で、kube-apiserver・kube-controller-manager・kube-scheduler・etcd の Static Pod マニフェストを /etc/kubernetes/manifests/ に生成しています。最後の This node has joined the cluster and a new control plane instance was created が CP join 成功のメッセージです。WL join とはメッセージが異なる点に後で注目します。
Step 2: k8s-ops から k8s-cp-02 の join を確認する
k8s-ops(作業端末)から kubectl get nodes を実行し、k8s-cp-02 がクラスタに参加したことを確認します。なお本シリーズでは早期に alias k=kubectl を設定済みのため、k で kubectl を呼び出せます。実行コマンド(k8s-ops で developer ユーザーとして実行):
$ k get nodes実行結果(k8s-cp-02 が control-plane ロールで Ready になっている):
NAME STATUS ROLES AGE VERSION
k8s-cp-01 Ready control-plane 3d v1.35.5
k8s-cp-02 Ready control-plane 30s v1.35.5k8s-cp-02 の ROLES が control-plane になっています。WL join の場合はここが <none> になります。join 直後は STATUS が一時的に NotReady になることがありますが、Calico CNI がそのノードに Pod ネットワークを展開すると Ready に変わります。数十秒待っても NotReady が続くときは、後述の確認手順で原因を切り分けます。
Step 3: k8s-cp-03 で CP join を実行する
k8s-cp-03 でも同じ手順で CP join を実行します。コマンドは k8s-cp-02 とほぼ同じですが、--apiserver-advertise-address を 192.168.1.127(k8s-cp-03 の IP)に変える点だけが異なります。実行コマンド(k8s-cp-03 で root 権限で実行):
# kubeadm join k8s-lb:6443 \
--token xxxxxx.xxxxxxxxxxxxxxxx \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
--control-plane \
--certificate-key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
--apiserver-advertise-address 192.168.1.127実行結果(k8s-cp-02 と同様に CP join 成功のメッセージが出る):
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.certificate-key の 2 時間制限を思い出してください。再アップロードから 2 時間以内に k8s-cp-02 と k8s-cp-03 の両方の join を終える必要があります。もし k8s-cp-03 の join に取りかかる時点で 2 時間を超えてしまったら、k8s-cp-01 で kubeadm init phase upload-certs --upload-certs を実行し直し、新しい certificate-key を取得して --certificate-key を差し替えます。
Step 4: etcd クラスタのメンバーを確認する
CP×3 が揃ったので、3 ノードの stacked etcd クラスタが完成したことを確認します。etcdctl member list で etcd のメンバー一覧を表示します。etcdctl は第4回時点では k8s-ops にインストールしていません(第5回で導入予定)。本回では etcd Static Pod 内に同梱された etcdctl を kubectl exec 経由で使います。etcd への接続には TLS クライアント証明書が必要なため、Pod 内の証明書パス(etcd/server.crt 等)を --cacert / --cert / --key で指定します。実行コマンド(k8s-ops で実行):
$ kubectl exec -n kube-system etcd-k8s-cp-01 -- etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
member list実行結果(3 ノードが started 状態でリストされる):
xxxxxxxxxxxxxxxx, started, k8s-cp-01, https://192.168.1.125:2380, https://192.168.1.125:2379, false
xxxxxxxxxxxxxxxx, started, k8s-cp-02, https://192.168.1.126:2380, https://192.168.1.126:2379, false
xxxxxxxxxxxxxxxx, started, k8s-cp-03, https://192.168.1.127:2380, https://192.168.1.127:2379, false3 行とも started と表示されていれば、3 ノードの stacked etcd が正しく構成されています。各行の末尾にある false は「このメンバーは learner ではない(投票権を持つ正規メンバー)」という意味です。第3回で学んだ etcd quorum を思い出してください。3 ノード構成の quorum は 2 で、1 台の etcd が停止しても残り 2 台でクラスタは継続動作します。この耐障害性が、本回で構築した HA 構成の核心です。etcd のバックアップとリストアは第5回で詳しく扱います。
やってみよう② k8s-wl-01/02 を Workload Node として join する
2 つめの演習です。k8s-wl-01 と k8s-wl-02 を Workload Node として参加させます。WL join は CP join より大幅にシンプルで、所要時間も短く済みます。CP join が 2〜5 分かかるのに対し、WL join は 30 秒〜1 分で完了します。etcd への参加や Control Plane の Static Pod 作成がないためです。作業場所は k8s-wl-01(192.168.1.128)と k8s-wl-02(192.168.1.129)に、それぞれ root で SSH します。
Step 1: k8s-wl-01 で WL join を実行する
WL join では --control-plane・--certificate-key・--apiserver-advertise-address の 3 つは不要です。kubeadm token create --print-join-command が出力した WL 向けコマンドをそのまま実行します。実行コマンド(k8s-wl-01 で root 権限で実行):
# kubeadm join k8s-lb:6443 \
--token xxxxxx.xxxxxxxxxxxxxxxx \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx実行結果(WL join 成功):
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.CP join の出力と見比べてください。WL join には [control-plane] や [etcd] の行がありません。Static Pod を作らず、etcd にも参加しないためです。最後のメッセージも This node has joined the cluster(CP join の「a new control plane instance was created」がない短い版)になっています。WL ノードは kubelet を起動してクラスタに登録されるだけで、Control Plane の機能は一切持ちません。
Step 2: k8s-wl-02 で WL join を実行する
k8s-wl-02 でも同じコマンドを実行します。WL join はノードごとの個別パラメータがないため、k8s-wl-01 とまったく同じコマンドで構いません。実行コマンド(k8s-wl-02 で root 権限で実行):
# kubeadm join k8s-lb:6443 \
--token xxxxxx.xxxxxxxxxxxxxxxx \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx実行結果(k8s-wl-01 と同じく WL join 成功のメッセージが出る):
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.CP join と WL join の違いを整理する
ここまでで CP join 2 回と WL join 2 回を実行しました。両者の違いを表で整理します。CKA 試験では「Control Plane を追加する」「Workload Node を追加する」のどちらも出題されるため、必要なフラグの違いを正確に押さえておく必要があります。
| 項目 | Control Plane join | Workload Node join |
|---|---|---|
--control-plane フラグ | 必要 | 不要 |
--certificate-key フラグ | 必要(CP 証明書のダウンロード) | 不要 |
--apiserver-advertise-address | 必要(各 CP の実 IP) | 不要 |
| etcd クラスタへの参加 | あり(stacked etcd に新メンバー追加) | なし |
| Static Pod の作成 | あり(apiserver / controller-manager / scheduler / etcd) | なし |
| 付与されるロール | control-plane | <none> |
| join 所要時間 | 2〜5 分 | 30 秒〜1 分 |
CP join と WL join の処理の流れをアスキー図で対比します。左が CP join、右が WL join です。CP join は証明書ダウンロード・Static Pod 起動・etcd 参加という重い処理が連なるのに対し、WL join は kubelet 登録だけで完結します。

5 ノード Ready 確認と HAProxy stats の全 backend UP 確認
CP×3 と WL×2 の join がすべて完了しました。本 H2 で 5 ノード全員が Ready になっていること、そして HAProxy stats ページで全 CP backend が UP になっていることを確認します。この確認が第4回最大のマイルストーンです。ここをクリアすれば、本回の HA クラスタ構築は完了です。
5 ノードの Ready をまとめて確認する
k8s-ops から kubectl get nodes -o wide を実行します。-o wide を付けると、IP アドレス・OS イメージ・カーネルバージョン・コンテナランタイムまで一覧表示されます。実行コマンド(k8s-ops で実行):
$ kubectl get nodes -o wide実行結果(5 ノード全員が Ready):
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-cp-01 Ready control-plane 3d v1.35.5 192.168.1.125 <none> AlmaLinux 10.1 (Heliotrope Lion) 6.12.0-55.9.1.el10_1.x86_64 containerd://2.2.4
k8s-cp-02 Ready control-plane 10m v1.35.5 192.168.1.126 <none> AlmaLinux 10.1 (Heliotrope Lion) 6.12.0-55.9.1.el10_1.x86_64 containerd://2.2.4
k8s-cp-03 Ready control-plane 8m v1.35.5 192.168.1.127 <none> AlmaLinux 10.1 (Heliotrope Lion) 6.12.0-55.9.1.el10_1.x86_64 containerd://2.2.4
k8s-wl-01 Ready <none> 5m v1.35.5 192.168.1.128 <none> AlmaLinux 10.1 (Heliotrope Lion) 6.12.0-55.9.1.el10_1.x86_64 containerd://2.2.4
k8s-wl-02 Ready <none> 3m v1.35.5 192.168.1.129 <none> AlmaLinux 10.1 (Heliotrope Lion) 6.12.0-55.9.1.el10_1.x86_64 containerd://2.2.45 行すべての STATUS が Ready になっていれば成功です。ROLES 列に注目してください。k8s-cp-01〜03 は control-plane、k8s-wl-01/02 は <none> です。<none> は「特別なロールラベルが付いていない」という意味で、これが Workload Node の正常な状態です。STATUS が Ready になる条件は、kubelet が起動していて、なおかつ Calico CNI が Pod ネットワークを確立していることです。
もし NotReady が続くノードがあったら、そのノードを kubectl describe node で調べます。実行コマンド(k8s-wl-01 が NotReady の場合の例):
$ kubectl describe node k8s-wl-01出力の Conditions 欄を確認します。Ready 条件が False の場合、その Message に理由が書かれています。よくある理由は Calico の初期化待ち(CNI プラグインがまだ展開されていない)と、containerd の cgroup ドライバー設定ミスです。後者の場合は、そのノードの /etc/containerd/config.toml で SystemdCgroup = true になっているかを再確認します。
kube-system の Pod がすべて Running か確認する
ノードが Ready になっても、システム Pod が正常に動いていなければクラスタは健全とは言えません。全 Namespace の Pod を確認し、Running と Completed 以外の Pod がないことを確かめます。実行コマンド(Running 以外の Pod を抽出):
$ kubectl get pods -A | grep -v Running実行結果(ヘッダー行と Completed のみ表示・エラー Pod なし):
NAMESPACE NAME READY STATUS RESTARTS AGE出力にヘッダー行しか出てこなければ、すべての Pod が Running 状態です(grep -v Running で Running 行が除外されるため)。もし CrashLoopBackOff や ImagePullBackOff の Pod が表示されたら、その Pod を kubectl describe pod と kubectl logs で調べます。CP join 直後は各 CP ノード上の kube-apiserver・etcd の Pod が起動中で、一時的に表示されることがありますが、数分待てば落ち着きます。
HAProxy stats ページで全 CP backend が UP になったか確認する
第3回では HAProxy stats ページで「CP-01 が UP、CP-02/03 が DOWN」という状態を確認しました。CP-02/03 が DOWN だったのは、それらのノードで kube-apiserver がまだ起動していなかったためです。本回で CP join を完了し、CP-02/03 でも kube-apiserver が 6443 で LISTEN するようになりました。HAProxy の tcp-check が成功に転じ、stats ページの表示が UP に変わっているはずです。
ホスト OS のブラウザで http://192.168.1.124:9000/stats を開きます。k8s-cp-api バックエンドの行で、k8s-cp-01 / k8s-cp-02 / k8s-cp-03 の 3 つすべてが緑色の UP 表示になっていることを確認します。コマンドラインで確認する場合は k8s-ops から curl で stats ページを取得し、UP の出現回数を数えます。実行コマンド(k8s-ops から curl で確認する場合):
$ curl -s http://192.168.1.124:9000/stats | grep -c "UP"実行結果(UP が 3 件):
33 と表示されれば、3 台の Control Plane Node がすべて HAProxy から正常な backend として認識されています。これで k8s-ops の kubectl は k8s-lb:6443 経由で 3 台の CP にラウンドロビン分散されます。1 台の CP ノードが停止しても、HAProxy が残り 2 台へ自動的に振り分けるため、kubectl の操作は継続できます。第3回で学んだ SPOF(単一障害点)が、これで解消されました。本回の HA クラスタ構築は、ここで完了です。
containerd の insecure registry 設定(hosts.toml 方式・全 5 ノード)
HA クラスタが完成しました。次は fanclub-api をこのクラスタにデプロイする準備です。fanclub-api のコンテナイメージは、本シリーズの検証環境内にある Docker Registry(k8s-registry・192.168.1.123:5000)に保存されています。各ノードの containerd がこの Registry からイメージを pull できるように、insecure registry 設定を追加します。
なぜ insecure registry 設定が必要か
containerd はデフォルトで、レジストリとの通信に HTTPS と有効な TLS 証明書を要求します。これはセキュリティ上正しい挙動です。しかし検証環境の Docker Registry(192.168.1.123:5000)は HTTP で動いており、TLS 証明書を持ちません。この状態でイメージを pull しようとすると、containerd は次のようなエラーを返します。
http: server gave HTTP response to HTTPS client(HTTPS でアクセスしたのに HTTP が返ってきた)certificate signed by unknown authority(証明書が信頼できない認証局のもの)
これを解決するのが insecure registry 設定です。「このレジストリに限っては HTTP で通信し、証明書の検証をスキップしてよい」と containerd に教えます。ここで強調しておきます。insecure registry は社内ネットワーク内のレジストリや検証環境に限定して使うべき設定です。公開レジストリや本番環境では、必ず TLS と有効な証明書を使ってください。検証環境で楽をするための設定だと理解しておきます。
hosts.toml 方式で全 5 ノードに設定する
containerd v2.x では、insecure registry を hosts.toml ファイルで設定する方式が推奨されています。かつては /etc/containerd/config.toml の registry セクションに直接書く方式もありましたが、これは現在では非推奨(deprecated)です。hosts.toml 方式は、レジストリごとに専用のディレクトリとファイルを用意する分かりやすい構成です。この設定は全 5 ノード(k8s-cp-01〜03 + k8s-wl-01/02)で行います。実行コマンド(全 5 ノードで root 権限で実行):
# mkdir -p /etc/containerd/certs.d/192.168.1.123:5000
# tee /etc/containerd/certs.d/192.168.1.123:5000/hosts.toml << 'EOF'
server = "http://192.168.1.123:5000"
[host."http://192.168.1.123:5000"]
capabilities = ["pull", "resolve"]
skip_verify = true
EOFこの hosts.toml の中身を説明します。server はレジストリのエンドポイントを HTTP で指定しています。[host."http://192.168.1.123:5000"] セクションの capabilities = ["pull", "resolve"] は「このホストからイメージの pull と名前解決を許可する」という意味です。skip_verify = true が「TLS 証明書の検証をスキップする」という insecure 設定の核心です。設定を反映するため containerd を再起動します。実行コマンド(containerd 再起動・全 5 ノード):
# systemctl restart containerd
# systemctl is-active containerd実行結果:
activepull テストで設定を検証する
設定が効いているか、実際にイメージを pull してみます。crictl は CRI(Container Runtime Interface)準拠のランタイムを操作する CLI で、containerd と直接対話できます。fanclub-backend のイメージを pull します。実行コマンド(各ノードで pull テスト・k8s-cp-01 での例):
# crictl pull 192.168.1.123:5000/fanclub-backend:0.2.0実行結果(pull 成功):
Image is up to date for 192.168.1.123:5000/fanclub-backend:0.2.0エラーなく pull が完了すれば、insecure registry 設定は成功です。先に挙げた http: server gave HTTP response to HTTPS client エラーが出る場合は、hosts.toml のディレクトリ名がレジストリのアドレスと完全一致しているか、containerd を再起動したかを確認します。なお k8s-cp-01 は第2回から稼働しているノードですが、insecure registry 設定を追加するだけで kubeadm init や Calico CNI には影響しません。5 ノードすべてで pull テストが通れば、fanclub-api のデプロイ準備が整います。
local-path-provisioner の導入(kubeadm クラスタの暫定 StorageClass)
fanclub-api には PostgreSQL 18 のデータベース(fanclub-db)が含まれます。fanclub-db は StatefulSet で動き、データを永続化するために PersistentVolumeClaim を要求します。設計判断①で説明したとおり、kubeadm クラスタには既定 StorageClass が存在しないため、このままでは PVC がバインドできません。本 H2 で local-path-provisioner を導入し、暫定の StorageClass を用意します。
kubeadm クラスタに StorageClass がないことを確認する
まず、現状の StorageClass を確認します。実行コマンド(k8s-ops で実行):
$ kubectl get sc実行結果(StorageClass が 1 つも存在しない):
No resources foundNo resources found が、kubeadm クラスタの初期状態です。kind クラスタには標準で StorageClass がありましたが、kubeadm はストレージプロビジョナーを一切インストールしません。ストレージ周りは管理者が自分で用意する、というのが kubeadm の方針です。
local-path-provisioner をインストールする
local-path-provisioner v0.0.30 を kubectl apply でインストールします。公式リポジトリの配布マニフェストを使います。バージョンを v0.0.30 でピン留めしている点に注目してください。master や latest を指定すると将来の更新で挙動が変わる恐れがあるため、本シリーズでは全コンポーネントをバージョン固定します。実行コマンド:
$ kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/v0.0.30/deploy/local-path-storage.yaml実行結果:
namespace/local-path-storage created
serviceaccount/local-path-provisioner-service-account created
role.rbac.authorization.k8s.io/local-path-provisioner-role created
clusterrole.rbac.authorization.k8s.io/local-path-provisioner-role created
rolebinding.rbac.authorization.k8s.io/local-path-provisioner-bind created
clusterrolebinding.rbac.authorization.k8s.io/local-path-provisioner-bind created
deployment.apps/local-path-provisioner created
storageclass.storage.k8s.io/local-path created
configmap/local-path-config created出力から、local-path-provisioner が local-path-storage という専用 Namespace に展開され、local-path という StorageClass が作られたことが分かります。Deployment(プロビジョナー本体)・ServiceAccount・RBAC リソース(Role / ClusterRole / RoleBinding / ClusterRoleBinding)・ConfigMap も一緒に作られます。
既定 StorageClass として明示する(annotate)
公式マニフェストの内容は upstream の更新で変わることがあり、デプロイした直後に kubectl get sc を見ても (default) が付かないバージョンがあります。本シリーズでは storageclass.kubernetes.io/is-default-class=true アノテーションを明示的に付与して、再現性のある「既定 SC」状態を作ります。実行コマンド:
$ kubectl annotate sc local-path storageclass.kubernetes.io/is-default-class=true --overwrite実行結果:
storageclass.storage.k8s.io/local-path annotated--overwrite を付けているのは、すでに同じアノテーションが付いている場合に冪等で動作させるためです。本シリーズでは「明示的に既定化」する習慣をつけます。これは複数 SC が共存する第12回(Longhorn 導入)に向けた布石でもあります。
StorageClass が既定として登録されたか確認する
StorageClass を再度確認します。実行コマンド:
$ kubectl get sc実行結果(local-path が既定 StorageClass として登録されている):
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
local-path (default) rancher.io/local-path Delete WaitForFirstConsumer false 30s名前の横に (default) と表示されています。これは「StorageClass を明示指定しない PVC は、この StorageClass を使う」という既定指定です。fanclub-db の PVC が StorageClass を指定していなくても、自動的に local-path が使われます。VOLUMEBINDINGMODE が WaitForFirstConsumer になっている点も重要です。これは「PVC を要求した Pod が実際にどのノードへスケジュールされるかが決まってから、そのノード上に PV を作る」という遅延バインドモードです。ノードのローカルディスクを使う local-path-provisioner では、Pod の配置先とディスクの所在を一致させる必要があるため、このモードが採用されています。
local-path と Longhorn の違い
local-path-provisioner の動作と制約をまとめます。データは PVC をバインドした Pod が稼働するノードの /opt/local-path-provisioner/pvc-<uuid>/ に保存されます。レプリケーションがないため、そのノードが障害を起こすとデータは失われます。第12回で導入する Longhorn は、複数ノードにデータのレプリカを分散して冗長性を確保する分散ストレージです。両者の違いをアスキー図で対比します。
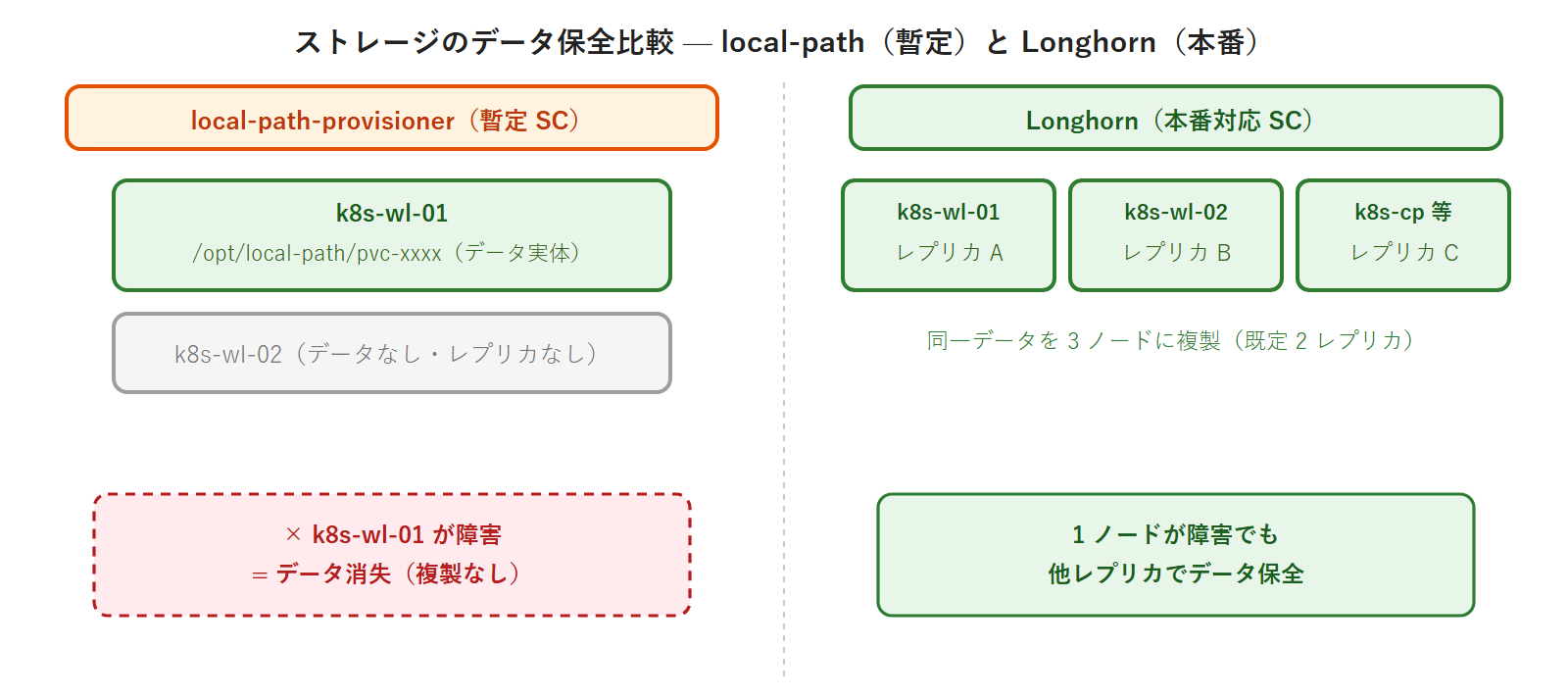
本回で local-path を「暫定ストレージ」と呼ぶ理由が、この図で明確になります。第12回では Longhorn をインストールし、fanclub-db の PVC を local-path から longhorn へ移行します。「暫定ストレージ」から「本番対応の分散ストレージ」へのアップグレードを、実機で体験する演習になります。本回では fanclub-api を確実に動かすための土台として、まず local-path を導入しておきます。
やってみよう③ fanclub-api を Helm で HA クラスタにデプロイする
3 つめの演習です。第1巻で作成した fanclub-api の Helm chart を、本回で構築した kubeadm HA クラスタにデプロイします。第1巻では kind クラスタにデプロイしましたが、kubeadm クラスタはまったく別のクラスタです。Namespace も Secret もゼロから作り直します。所要時間の目安は 25〜35 分です。作業場所は k8s-ops(192.168.1.122)で developer ユーザーとして実行します。
Step 1: Helm chart が k8s-ops 上にあることを確認する
第1巻の Helm 回(第17回・第18回)で作成した fanclub-api の chart が、k8s-ops に保存されていることを確認します。実行コマンド(k8s-ops で実行):
$ ls ~/fanclub-charts/実行結果(第1巻で作成した chart ディレクトリが存在する):
fanclub-api/Step 2: fanclub Namespace を作成する
fanclub-api 専用の Namespace を作ります。Namespace を分けることで、システムコンポーネントとアプリのリソースを論理的に分離できます。実行コマンド:
$ kubectl create namespace fanclub実行結果:
namespace/fanclub createdStep 3: DB 接続用 Secret の取り扱いを確認する
fanclub-api Helm chart には Secret テンプレートが含まれており、helm install 時に values.yaml の secret.DB_USER / secret.DB_PASSWORD から自動生成されます(次の Step 4 で values.yaml の中身を確認します)。そのため手動の kubectl create secret は不要です。本巻では chart 内蔵 Secret テンプレートに任せ、必要に応じて --set で値を上書きする方針で進めます。
動作確認のため、Namespace 作成直後に kubectl get secret -n fanclub で「現時点では Secret が存在しない」ことだけ確認しておきます。実行コマンド:
$ kubectl get secret -n fanclub実行結果:
No resources found in fanclub namespace.本番運用では、平文パスワードをコマンド履歴・values.yaml・Git リポジトリに残さない運用(SealedSecrets・ExternalSecrets Operator など)が必須です。Secret の安全な管理は第3巻(CKS 編)で扱います。
Step 4: 第2巻向け values.yaml を確認する
第1巻で作成した fanclub-api Helm chart の values.yaml 全量を示します。第1巻末(chart 化フェーズ)からの最小構成で、ServiceAccount / Secret / ConfigMap / Service / Deployment の 5 テンプレートのみを含みます。frontend / database / Gateway/HTTPRoute は本 chart には含まれず、それぞれ後続回(第11回 Gateway API・第12回 Longhorn)で別途整備します。
replicaCount: 2
image:
repository: fanclub-backend
tag: "0.1.0"
pullPolicy: IfNotPresent
service:
type: ClusterIP
port: 80
targetPort: 8080
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 1000m
memory: 512Mi
initContainer:
enabled: false
config:
DB_HOST: fanclub-db
DB_PORT: "5432"
DB_NAME: fanclubdb
JAVA_OPTS: "-XX:MaxRAMPercentage=75.0"
secret:
DB_USER: fanclubuser
DB_PASSWORD: fanclubpass第2巻向けに変更するのはイメージ参照のみです。image.repository をプライベートレジストリ参照(192.168.1.123:5000/fanclub-backend)に、image.tag を実機 k8s-registry にある 0.2.0 に切り替えます。これらは --set で渡し、values.yaml 自体は書き換えません。config.DB_HOST: fanclub-db は DB Service の参照先ですが、本 chart は DB を含まないため、DB が未デプロイの状態では backend が起動後すぐに DB への接続を試みて再試行を繰り返します。/health/live(liveness)エンドポイントは DB に依存せず常に {"status":"UP"} を返す設計のため Pod は Ready になります(readinessProbe / livenessProbe は /health/live を見ています)。/api/members 等のエンドポイントはこの backend ビルド(fanclub-backend:0.2.0)では未実装のため、DB の有無に関わらず 404 を返します。本回で確認するのは /health/live による Pod の稼働です。fanclub-db StatefulSet の追加は第12回で扱います。DB と HTTPS 公開の完成は第9〜12回のロードマップで段階的に整備します。
Step 5: helm install を実行する
helm install で fanclub-api をデプロイします。本 chart は最小構成のため、image を k8s-registry のものに切り替えるだけで動作します。実行コマンド:
$ helm install fanclub-api ~/fanclub-charts/fanclub-api \
--set image.repository=192.168.1.123:5000/fanclub-backend \
--set image.tag=0.2.0 \
--namespace fanclub --create-namespace実行結果:
NAME: fanclub-api
LAST DEPLOYED: Thu May 22 12:00:00 2026
NAMESPACE: fanclub
STATUS: deployed
REVISION: 1
TEST SUITE: NoneSTATUS: deployed が出れば、Helm によるリソース作成は成功です。REVISION: 1 は「このリリースの 1 番目のリビジョン」を意味します。今後 helm upgrade するたびにリビジョン番号が増えます。
Step 6: Pod が Running になるまで確認する
fanclub Namespace の Pod を監視します。-w(watch)を付けると、Pod の状態が変わるたびに行が追加表示されます。実行コマンド(Pod が Running になるまで watch):
$ kubectl get pods -n fanclub -w実行結果(全 Pod が Running・Ready 1/1):
NAME READY STATUS RESTARTS AGE
fanclub-api-fanclub-api-bbbfdf9bf-xxxxx 1/1 Running 0 45s
fanclub-api-fanclub-api-bbbfdf9bf-yyyyy 1/1 Running 0 45sbackend の Deployment が作る Pod 2 つ(replicaCount: 2 由来)がともに Running / READY: 1/1 になれば成功です。HA クラスタの 2 つの Workload Node(wl-01 / wl-02)に分散配置されることを後の -o wide で確認します。watch を止めるには Ctrl+C を押します。
Step 7: Helm リリースと PVC のバインドを確認する
Helm のリリース一覧を確認します。実行コマンド:
$ helm list -n fanclub実行結果:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
fanclub-api fanclub 1 2026-05-22 12:00:00 deployed fanclub-api-1.0.0 0.1.0CHART 列の fanclub-api-1.0.0 は Helm chart のリリース版数(第1巻 chart 化フェーズで切ったタグ)、APP VERSION 列の 0.1.0 は chart の Chart.yaml に書かれた appVersion です。一方、Pod イメージは --set image.tag=0.2.0 で指定した fanclub-backend のイメージタグであり、これは別系統のバージョン管理です(chart バージョン = テンプレート版数 / image tag = アプリビルド版数)。第2巻全体を通じて chart バージョン 1.0.0 を維持しつつ、fanclub-backend のイメージタグだけが(DB 接続実装等で)変動する設計です。
続いて PVC を確認します。本 chart は backend Deployment のみで PVC を要求するリソースを含まないため、この時点では fanclub Namespace に PVC は作成されていません。実行コマンド:
$ kubectl get pvc -n fanclub実行結果:
No resources found in fanclub namespace.PVC が 0 件で表示されるのが正常です。fanclub-db の StatefulSet は第12回で別途デプロイし、その時点で初めて data-fanclub-db-0 という PVC が作成され、Longhorn StorageClass を使って Bound 状態になります。本回で導入した local-path-provisioner は、その第12回以前に何らかの PVC を試験的に作るための「暫定の default StorageClass」として待機させておく位置づけです。これで fanclub-api(backend のみ)が kubeadm HA クラスタ上にデプロイされました。
やってみよう④ port-forward で fanclub-api の動作を確認する
最後の演習です。kubectl port-forward を使って fanclub-backend の REST API にアクセスし、HTTP レスポンスが返ることを確認します。これにより、fanclub-api が kubeadm HA クラスタ上で正常に動作していることを実証します。所要時間の目安は 15 分です。作業場所は k8s-ops で、ターミナルを 2 つ使います。
kubectl port-forward のしくみ
kubectl port-forward は、kubectl が kube-apiserver を経由してトンネルを張り、ローカルのポートを Pod や Service のポートへ転送する機能です。本来は開発・デバッグ用途の機能で、本番の外部公開には使いません。port-forward を実行したターミナルは、転送が続いている間はブロックされます(停止は Ctrl+C)。画面を占有するため別ターミナルで作業を続けたい場合は 2 つ目のターミナルを開きます。SSH 経由で k8s-ops に作業している読者は「2 つ目の SSH セッションを開く」「tmux / screen で別ウィンドウを開く」「ターミナルエミュレータの新規タブで再 SSH」のいずれかで対応します。第9回の MetalLB、第11回の Gateway API + Traefik を導入した後は、外部公開に port-forward は不要になります。本回では、MetalLB / Gateway API が未整備の段階で fanclub-api の動作を確認するための暫定手段として使います。
Step 1: ターミナル 1 で port-forward を開始する
まず Service 名を確認します。第1巻 chart の _helpers.tpl は fullname を {{ .Release.Name }}-{{ .Chart.Name }} で組み立てるため、本演習の Service 名は fanclub-api-fanclub-api になります(Release 名 fanclub-api + Chart 名 fanclub-api)。実機で必ず確認してください。実行コマンド:
$ kubectl get svc -n fanclub実行結果:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
fanclub-api-fanclub-api ClusterIP 10.106.109.247 <none> 80/TCP 30s続いてターミナル 1 で、上記の Service の 80 番を k8s-ops のローカル 8080 ポートに転送します(chart の values.yaml で service.port: 80 / targetPort: 8080)。実行コマンド(k8s-ops のターミナル 1 で実行・このターミナルはブロックされる):
$ kubectl port-forward service/fanclub-api-fanclub-api 8080:80 -n fanclub実行結果(port-forward が待機状態になる):
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80この表示が出たら転送は有効です。ターミナル 1 はこのまま開いておきます。Ctrl+C を押すと転送が止まります。
Step 2: ターミナル 2 から API にアクセスする
もう 1 つのターミナル(ターミナル 2)を開き、curl で fanclub-backend の API を叩きます。まずヘルスチェックエンドポイントです。実行コマンド(k8s-ops のターミナル 2 で実行):
$ curl -s http://localhost:8080/health/live実行結果:
{"status":"UP"}{"status":"UP"} が返れば、Payara Micro 上の fanclub-backend が正常に応答しています。/api/members 等のエンドポイントはこの backend ビルドでは未実装のため、DB の有無に関わらず 404 を返します。DB を必要としない /health/live(liveness)は readinessProbe / livenessProbe の対象でもあり、これが正常応答することで「Helm chart のデプロイは成功し、HA クラスタ上で 2 レプリカが正しく稼働している」という第4回マイルストーンの達成を確認できます。fanclub-db StatefulSet のデプロイとデータ永続化の確認は第12回で扱います。
Step 3: 動作確認の結果を整理し、port-forward を終了する
第4回終了時点での fanclub-api の状態を表に整理します。
| 項目 | 第4回終了時の状態 |
|---|---|
| fanclub-backend(Payara Micro) | Deployment 2 レプリカ Running(wl-01 / wl-02 に分散)・port-forward で /health/live 確認済み |
| fanclub-frontend(Nginx) | 未デプロイ(第1巻 chart 範囲外・後続回で別途整備) |
| fanclub-db(PostgreSQL 18) | 未デプロイ(第1巻 chart 範囲外・第12回 Longhorn 導入と合わせて整備) |
| HTTPS 公開(https://fanclub.local) | 未対応(第9回 MetalLB・第11回 Gateway API/Traefik で実現) |
動作確認が終わったら、ターミナル 1 に戻って port-forward を終了します。Ctrl+C を押します。実行コマンド(ターミナル 1 で Ctrl+C):
^Cこれで第4回の全 4 演習が完了しました。kubeadm HA クラスタ(CP×3 + WL×2)を自力で構築し、第1巻で作った fanclub-api をその上に移行して動作確認するところまでを、一通りやり遂げました。第2巻最大の山場を越えました。
まとめと次回予告
第4回では、kubeadm HA クラスタの構築と fanclub-api の移行を完遂しました。本回の要点を 7 点にまとめます。
- kubeadm join には CP 向けと WL 向けの 2 種類がある。CP join には
--control-plane・--certificate-key・--apiserver-advertise-addressが追加で必要で、WL join は token と ca-cert-hash だけで足りる --upload-certsで etcd に保存された証明書(kubeadm-certs Secret)の有効期限は 2 時間。複数日に分けて作業する場合は、join 直前にkubeadm init phase upload-certs --upload-certsで再アップロードする- join トークンの有効期限は 24 時間。
kubeadm token create --print-join-commandで常に新しいトークン込みの join コマンドを生成するのが確実 - firewalld の開放ポートは CP と WL で異なる。CP は 6443・2379-2380・10250・10257・10259、WL は 10250・30000-32767。CP 向けポートを WL に開けても join はできるが、最小権限の原則に反する
- containerd v2.x の insecure registry 設定は hosts.toml 方式を使う。
/etc/containerd/config.tomlの registry セクションでの設定は非推奨 - kubeadm クラスタには既定 StorageClass が存在しない。local-path-provisioner を暫定 SC として導入し、第12回で Longhorn に移行する
kubectl port-forwardはデバッグ・開発確認用途。本番の外部公開には MetalLB(第9回)と Gateway API/Traefik(第11回)を使う
第5回では、本回で構築した 3 ノード stacked etcd クラスタを使って、etcd のバックアップとリストアを実施します。ETCDCTL_API=3 etcdctl snapshot save でスナップショットを保存し、意図的にリソースを削除した後に etcdctl snapshot restore で復旧する体験を行います。あわせて、クラスタへのノードの追加・削除も扱います。「クラスタが壊れても直せる」という自信が、CKA 合格への大きな一歩になります。次回も実機作業中心です。本回で完成させた HA クラスタを土台に、運用スキルを積み上げていきます。
現場ヒヤリハット
本回の作業で実際に起きやすいトラブルを 3 件紹介します。いずれも kubeadm HA クラスタ構築の現場で頻発するもので、対処法とともに頭に入れておくと、同じ落とし穴を避けられます。
ヒヤリハット① 証明書が 2 時間で失効していることに気づかず join が失敗した
状況: 第3回で HAProxy 設定を完成させた翌日、第4回の手順を進めて k8s-cp-02 で kubeadm join --control-plane --certificate-key xxxx... を実行したところ、[download-certs] Failed to download certificate key from kubeadm-certs というエラーで join が失敗しました。
原因: --upload-certs で etcd にアップロードされた certificate-key の有効期限は 2 時間です。第2回 init 時にアップロードした certificate-key は、前日の作業時点ですでに失効していました。エラーメッセージの Failed to download certificate key が「証明書自体の検証エラー」ではなく「証明書のダウンロード失敗(Secret が失効して取得できない)」を意味していることに気づくまで、時間がかかりました。
対処: k8s-cp-01 で kubeadm init phase upload-certs --upload-certs を実行して新しい certificate-key を取得し、join コマンドの --certificate-key 値を差し替えて再実行したところ成功しました。教訓は明快です。CP join コマンドを実行する直前に、必ず certificate-key を再発行する習慣をつけることです。再アップロードから 2 時間以内に CP join をすべて終える、という時間管理も合わせて意識します。
ヒヤリハット② Workload Node に Control Plane 向けの firewalld ポートを開けて混乱した
状況: 「ポートが足りないと join できないのでは」と心配して、Workload Node(k8s-wl-01/02)にも CP 向けポート(6443・2379-2380・10257・10259)をすべて開放しました。WL 自体の join は問題なく完了しましたが、後日のセキュリティ監査で「WL ノードが不要なポートを公開している」と指摘されました。
原因: CP 向けポート(etcd の 2379-2380、kube-controller-manager の 10257、kube-scheduler の 10259)は、Control Plane Node の上でしか使われません。WL ノードにこれらのポートを開けても接続されることはありませんが、開いているポートはそれだけで攻撃面(Attack Surface)になります。「開けても害はないだろう」という油断が、監査指摘につながりました。
対処: WL ノードに必要なポートは 10250/tcp(kubelet API)と 30000-32767/tcp(NodePort Service)の 2 つだけです。本回 H2-3 の CP/WL ポート比較表を見ながら、役割ごとに最小限のポートだけを開放する設計を徹底します。「とりあえず全部開ける」は、検証環境であってもやめておくのが安全です。
ヒヤリハット③ no_proxy にホスト名を含めず kubeadm join が失敗した
状況: k8s-cp-02 の /etc/profile.d/proxy.sh で、no_proxy を localhost,127.0.0.1,192.168.1.0/24,10.96.0.0/12,10.244.0.0/16,.svc,.cluster.local のように IP レンジだけで設定しました。kubeadm join はエラーなく完了したものの、直後から kube-apiserver への kubectl 接続が断続的に失敗するようになりました。
原因: kubeadm join は HTTPS_PROXY 環境変数を Static Pod のマニフェストに伝播させます。API Server への接続先は k8s-lb:6443(ホスト名)ですが、no_proxy にこのホスト名が含まれていないため、kubelet が Squid プロキシ経由で k8s-lb:6443 へ接続しようとしました。Squid の whitelist に k8s-lb が登録されていないため、403 で接続が拒否されたのです。IP レンジを書いていても、接続先がホスト名で表現される場合は no_proxy のマッチ対象になりません。
対処: /etc/profile.d/proxy.sh の no_proxy に、全ノードのホスト名(k8s-lb,k8s-cp-01,k8s-cp-02,k8s-cp-03,k8s-wl-01,k8s-wl-02,k8s-ops,k8s-registry,alma-proxy)を明示的に追加し、kubeadm join をやり直しました。本回の H2-3 ステップ 1 で示した proxy.sh は、最初からホスト名込みの包括版になっています。プロキシ環境で kubeadm を扱うときは、no_proxy にホスト名を必ず含める、と覚えておきます。
理解度チェック
第4回の理解度を ○× 形式の 9 問で確認します。まず問題を読み、自分なりに答えを出してから解説を読んでください。
- 問 1:
kubeadm join --control-planeを実行する際、k8s-cp-02 と k8s-cp-03 はそれぞれ異なる--apiserver-advertise-addressを指定する必要がある - 問 2:
kubeadm join --control-planeの--certificate-keyは有効期限がないため、kubeadm init 時に出力した値を後日そのまま使えば問題ない - 問 3: Workload Node の join コマンドには
--control-planeと--certificate-keyの両方が必要である - 問 4: kubeadm クラスタには kubeadm init 直後から既定 StorageClass が用意されており、PVC はすぐにバインドできる
- 問 5: containerd v2.x で insecure registry を設定するには、
/etc/containerd/config.tomlの registry セクションに設定を記述する方法が推奨される - 問 6:
kubectl port-forward service/fanclub-api-fanclub-api 8080:80 -n fanclubは、k8s-ops の 8080 ポートから fanclub-api Service のポート 80 にトラフィックを転送する - 問 7: HAProxy stats ページで k8s-cp-02 が UP と表示されていれば、k8s-cp-02 上の kube-apiserver が 6443 ポートで LISTEN していることを意味する
- 問 8: kubeadm join が正常に完了すると、k8s-ops の
~/.kube/configを更新して新しいクラスタに接続し直す必要がある - 問 9: local-path-provisioner で作成した PVC のデータは、Pod が配置されたノードのローカルディスクに保存されるため、そのノードが障害を起こすとデータは失われる
問 1: ○ — --apiserver-advertise-address は、その CP ノード上で起動する kube-apiserver が自分の所在として知らせる IP アドレスです。k8s-cp-02 は 192.168.1.126、k8s-cp-03 は 192.168.1.127 と、各ノードの実 IP を指定します。
問 2: × — certificate-key には有効期限があり、わずか 2 時間です。kubeadm-certs Secret が 2 時間で自動削除されるためです。後日 join する場合は kubeadm init phase upload-certs --upload-certs で再アップロードし、新しい certificate-key を取得する必要があります。
問 3: × — --control-plane と --certificate-key は Control Plane join にのみ必要なフラグです。Workload Node join に必要なのは --token と --discovery-token-ca-cert-hash だけです。WL ノードは Control Plane の証明書を持たないため、certificate-key も不要です。
問 4: × — kubeadm クラスタには既定 StorageClass がありません。kind クラスタとの大きな違いです。kubectl get sc を実行すると No resources found が返ります。第4回では local-path-provisioner を導入して暫定の StorageClass を用意しました。
問 5: × — containerd v2.x では hosts.toml 方式が推奨されています。/etc/containerd/config.toml の registry セクションに記述する方式は非推奨(deprecated)です。/etc/containerd/certs.d/<レジストリアドレス>/hosts.toml にレジストリごとの設定を置きます。
問 6: ○ — port-forward service/fanclub-api-fanclub-api 8080:80 は「ローカル 8080 → Service の 80」という転送を作ります(chart の values.yaml で service.port: 80 / targetPort: 8080 を設定)。kubectl が kube-apiserver 経由でトンネルを張るため、k8s-ops のローカル localhost:8080 へのアクセスが Service の 80 番経由で backend Pod の 8080 番に届きます。
問 7: ○ — HAProxy の tcp-check は、backend の 6443 ポートに TCP 接続が確立できるかで UP / DOWN を判定します。k8s-cp-02 が UP なら、k8s-cp-02 上の kube-apiserver が 6443 で LISTEN していることを意味します。第3回で CP-02/03 が DOWN だったのは、kube-apiserver が未起動だったためです。
問 8: × — kubeconfig の接続先は k8s-lb:6443(controlPlaneEndpoint)です。CP ノードが増えても、接続先は LB のエンドポイントのまま変わりません。HAProxy がラウンドロビンで 3 台の CP に振り分けるため、kubeconfig の更新は不要です。LB を介する設計の利点がここに現れます。
問 9: ○ — local-path-provisioner はノードのローカルディスク(/opt/local-path-provisioner/)にデータを保存します。レプリケーションの仕組みがないため、そのノードが障害を起こすとデータは失われます。これが「暫定ストレージ」と呼ぶ理由です。第12回で導入する Longhorn は複数ノードにレプリカを分散するため、ノード障害でもデータを保全できます。
シリーズ一覧
第1部:クラスタ構築
- 第1回 第2巻スコープ + CKA 試験形式紹介 + kubeadm 概要 + kubeadm vs RKE2/k0s/OKD 概観
- 第2回 kubeadm シングルノード起動(pkgs.k8s.io + kubeadm init + Calico CNI)+ alma-proxy whitelist 構築
- 第3回 kubeadm HA 設計 + HAProxy LB(API Server LB 構成)
- 第4回 kubeadm HA クラスタ構築(CP×3 + WL×2)+ fanclub-api HA 移行 ← 今ここ
- 第5回 etcd backup/restore(etcdutl)+ ノード drain/uncordon
第2部:ワークロード管理
- 第6回 kubeadm upgrade + ノード drain/cordon + ミニトラブルシュート演習
- 第7回 Pod スケジューリング(taint/toleration/affinity/anti-affinity/PriorityClass)
- 第8回 HPA + ResourceQuota + LimitRange
第3部:ネットワーク
- 第9回 Service 詳細 + MetalLB(LoadBalancer 動作確認)
- 第10回 NetworkPolicy 詳細 + Calico/Cilium 比較 + ミニトラブルシュート演習
- 第11回 Gateway API + Traefik + cert-manager + CoreDNS(HTTPS 公開完成)
第4部:ストレージ
第5部:監視・運用
- 第13回 Prometheus + Grafana + Loki + Fluent Bit + fanclub-api 監視ダッシュボード
- 第14回 Helm + Kustomize でクラスタコンポーネント install + ArgoCD GitOps + Velero backup
